

В этой статье мы совершим увлекательное путешествие вглубь архитектуры трансформеров, чтобы понять, как они «думают» и как им удается так виртуозно манипулировать языком и генерировать осмысленный текст. Мы последуем за потоком данных, который проходит через эту сложную нейронную сеть, и рассмотрим каждый шаг подробно, от разбиения входного текста на токены до предсказания следующего слова.
Что такое GPT
Аббревиатура GPT расшифровывается как Generative Pretrained Transformer, что означает «генеративный предварительно обученный трансформер». Давайте разберем, что скрывается за этими словами.
Первое, что они нам говорят, – это то, что такие модели генерируют новый текст. То есть они не просто классифицируют или анализируют данные, а создают оригинальные тексты. Это очень мощная способность, которая лежит в основе инструментов вроде ChatGPT, Claude и Gemini, способных порождать связные и осмысленные тексты на основе небольших промптов.

Вторая часть, «предварительно обученный», означает, что эти модели прошли процесс предварительного обучения на огромных массивах данных, прежде чем применяться к конкретным задачам. Этот предварительный этап тренировки позволяет модели впитать обширные знания о языке, мире и многих других областях, которые потом используются при решении новых задач.
И, наконец, слово «трансформер» указывает на особый тип архитектуры нейронной сети, лежащей в основе этих моделей. Трансформер – это специальный вид машинного обучения, который был разработан в 2017 году и стал отправной точкой современного бума в области ИИ.
Так что же делает эти трансформеры такими особенными? Ключевая их особенность – это способность «понимать» и эффективно обрабатывать логически связанные последовательности данных, в первую очередь – текст. В отличие от более ранних подходов, основанных на рекуррентных нейронных сетях, трансформеры могут захватывать контекстуальные зависимости между элементами последовательности без необходимости обрабатывать их строго последовательно. Это позволяет им глубже проникать в смысл текста и генерировать более осмысленные и связные выходные данные.
Чтобы понять, как устроены трансформеры, мы последуем за потоком данных, и посмотрим, что происходит под капотом.
От слов к векторам: как трансформеры кодируют язык

Первый шаг в обработке текста трансформерами – разбиение входного текста на небольшие фрагменты, называемые токенами. Эти токены могут быть отдельными словами, частями слов или другими устойчивыми сочетаниями символов, типичными для данного языка.

Каждый такой токен затем ассоциируется с числовым вектором – списком чисел, который призван определенным образом закодировать значение этого фрагмента. Представьте себе эти векторы как координаты в многомерном пространстве – чем больше схожи значения слов, тем ближе расположены их векторы.
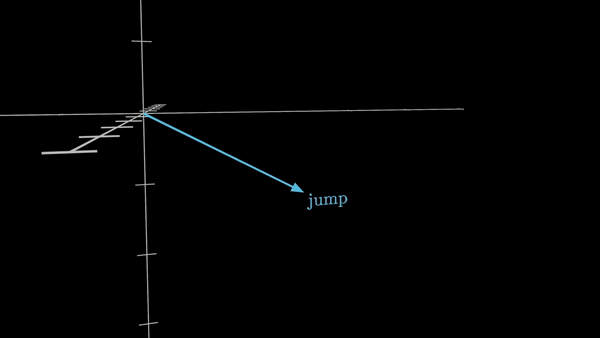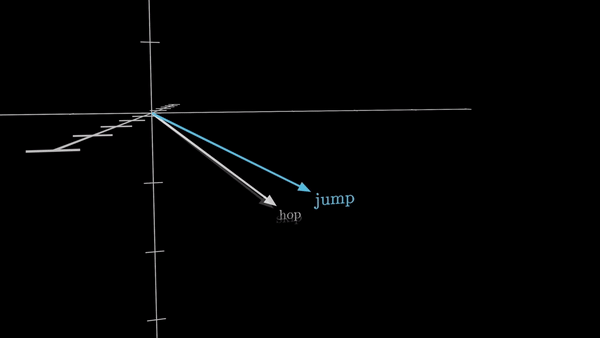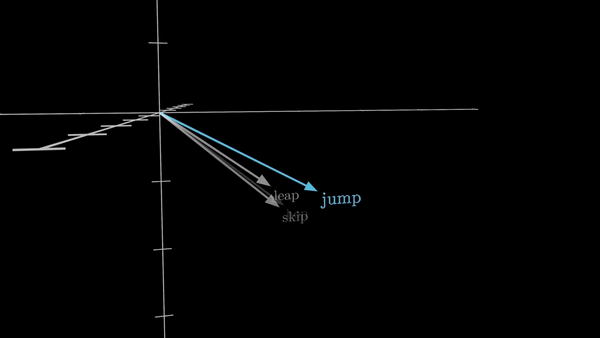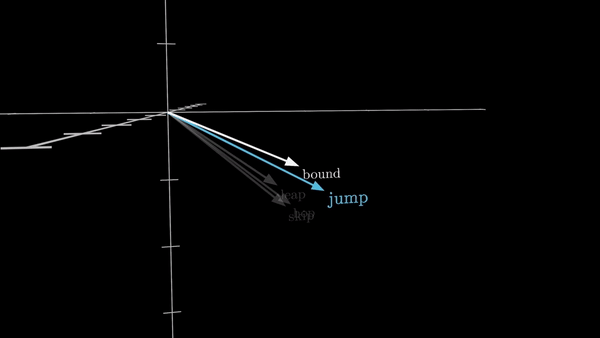
Этот процесс преобразования слов в векторные представления известен как создание эмбеддингов (word embedding) и был широко распространен в машинном обучении еще до появления трансформеров. Но трансформеры используют его как фундаментальный строительный блок, закладывая основу для всех дальнейших операций.
Например, в GPT-3 – одной из первых моделей на основе трансформеров, получившей широкую известность – размерность этих эмбеддингов составляет 12288 элементов. Это позволяет представить каждое слово в обширном, многомерном пространстве значений, где отдельные направления могут нести различную смысловую нагрузку, скажем, «сандал» и «сандалия», «сардина» и «Сардиния».
Эти векторные представления слов не остаются статичными: по мере того, как текст проходит через все слои трансформера, значения векторов начинают меняться, вбирая в себя все больше контекстуальной информации. Так что к моменту, когда мы получаем предсказание следующего слова, каждый вектор уже несет в себе очень богатое и нюансированное значение, отражающее весь контекст, в котором это слово было использовано. Таким образом, трансформеры буквально учатся «понимать» язык, преобразуя последовательность слов в сложную, многомерную сеть взаимосвязанных векторных представлений. Но как именно они это делают? Давайте углубимся в архитектуру трансформеров и узнаем, что происходит дальше.
Механизм внимания: ключевая особенность трансформеров
После того как входной текст был преобразован в последовательность векторов, эта последовательность поступает в центральный механизм трансформера – блок внимания (attention block). Это одна из ключевых особенностей, которая отличает трансформеры от предыдущих архитектур и во многом определяет их выдающиеся способности.
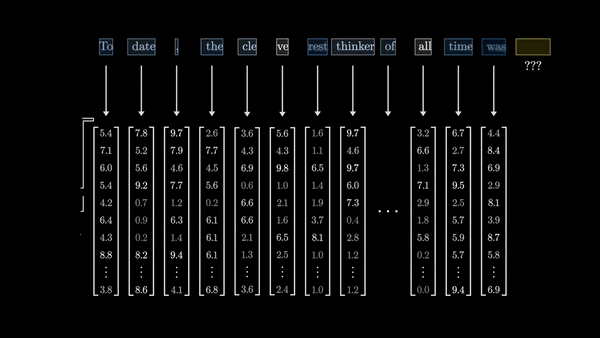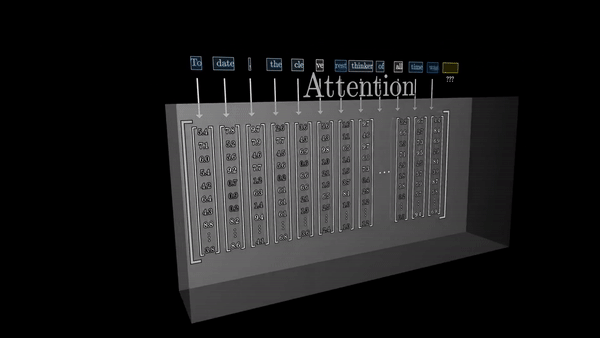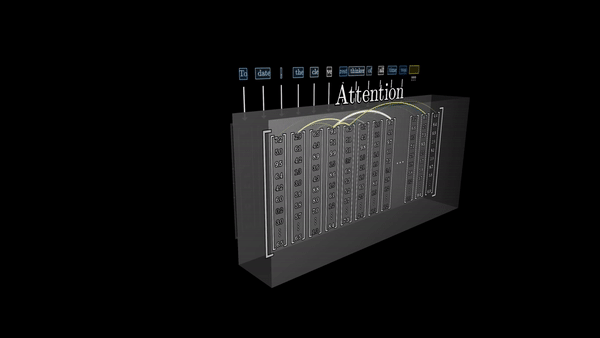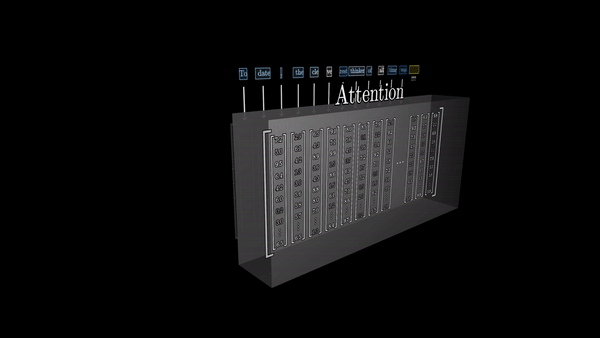
Идея внимания заключается в том, что векторы, представляющие отдельные фрагменты текста, должны иметь возможность «общаться» друг с другом и обмениваться информацией. Это позволяет им обновлять свои значения с учетом контекста, в котором они встречаются.
Возьмем, например, слово «модель». В различных контекстах, скажем, «машинное обучение» и «мода», его значение будет совершенно разным. Блок внимания как раз и отвечает за то, чтобы определить, какие другие слова в окружении данного слова указывают на необходимость обновления его значения, и как именно это значение должно быть изменено.
Математически это реализуется через операцию, которая напоминает вычисление скалярного произведения векторов. Если два вектора расположены неподалеку друг от друга, их скалярное произведение будет высоким – это означает, что эти элементы текста тесно связаны в данном контексте. И наоборот, если векторы почти ортогональны, их скалярное произведение будет близко к нулю, указывая на слабую связь между соответствующими фрагментами текста.
Таким образом, блок внимания позволяет каждому вектору-представлению слова «общаться» со всеми остальными, чтобы адаптировать свое значение с учетом контекста. Это дает трансформерам невероятную способность улавливать тонкие семантические взаимосвязи в тексте, которые ускользали от более ранних ИИ-моделей.
Но на этом процесс обработки текста трансформерами не заканчивается. После блока внимания векторы поступают в другой важный компонент – многослойный персептрон.
Многослойный персептрон: второй важнейший элемент в архитектуре трансформеров

Следующий слой в архитектуре трансформера – многослойный персептрон (multi-layer perceptron, или MLP). В отличие от блока внимания, где векторы «общались» друг с другом, здесь все векторы обрабатываются независимо, параллельно.
В упрощенном виде этот этап можно рассматривать как серию вопросов, которые задаются каждому вектору, и обновление векторов на основе ответов на эти вопросы. По сути, это еще один способ обогащения значений векторов-представлений, дополняющий механизм внимания.

Важно отметить, что и блок внимания, и многослойный персептрон реализуются в виде умножения огромных матриц: большинство вычислений в современных нейронных сетях, в том числе в трансформерах, сводится именно к матричным операциям.
Чередование блоков внимания и многослойных перспетронов

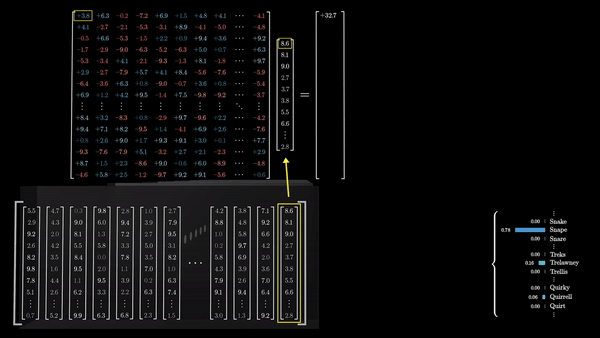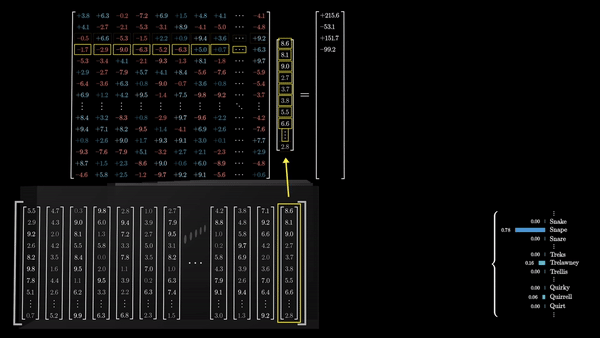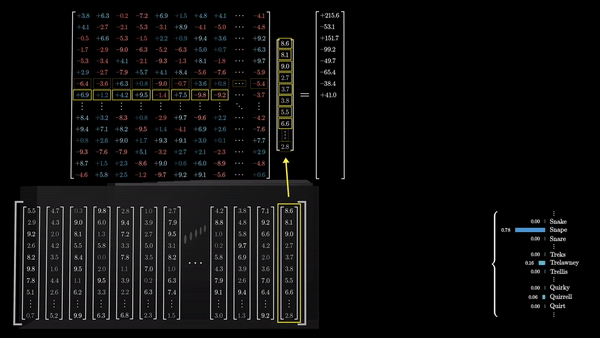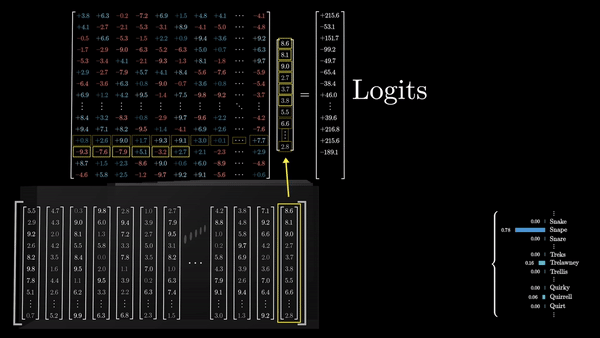
Блоки внимания помогают сети фокусироваться на наиболее важных частях входного текста, а многослойные персептроны обрабатывают эту информацию. Эти слои в GPT чередуются несколько раз, чтобы сеть могла глубоко проанализировать и извлечь ключевую информацию из промпта. На последнем этапе сеть формирует итоговый вектор, который аккумулирует в себе наиболее существенное значение, содержащееся в промпте.
Финальный этап: предсказание следующего слова
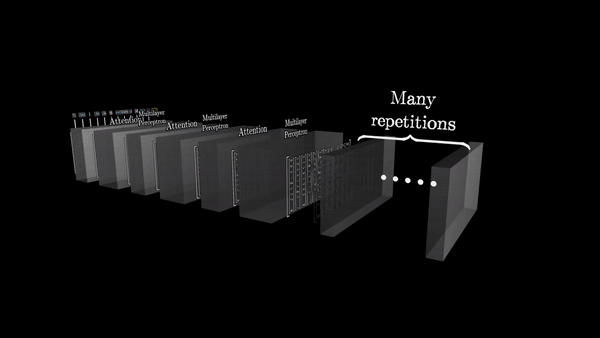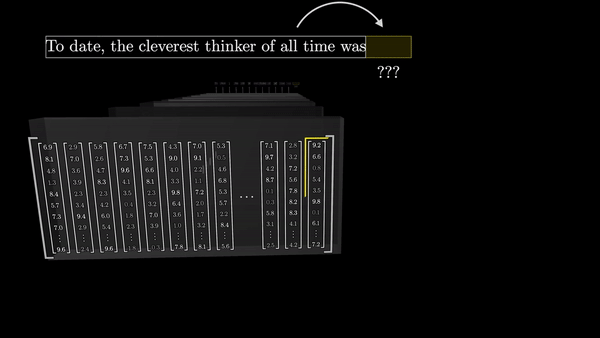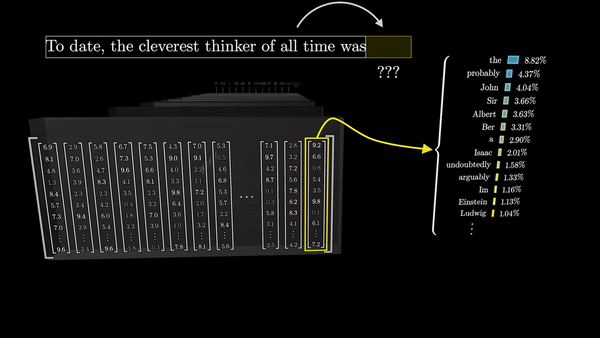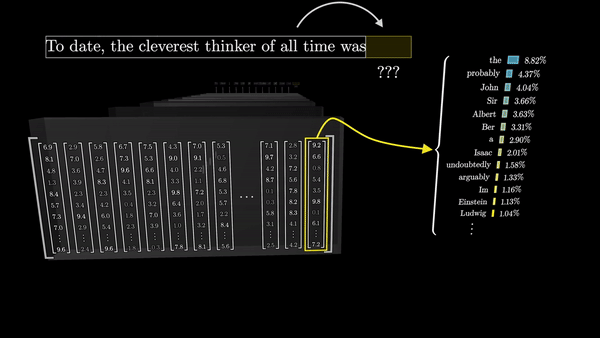
Последний шаг в процессе обработки текста трансформерами – это преобразование итогового вектора в вероятностное распределение по всем возможным следующим токенам. Это достигается с помощью умножения вектора на еще одну матрицу весов – в результате получаются логиты (logits, ненормализованные логарифмические вероятности) для каждого возможного токена.
Каждый логит делится на коэффициент, называемый «температурой». Температура – это гиперпараметр, который влияет на степень случайности выбора следующего слова из распределения. Низкая температура приводит к более предсказуемым, «безопасным» продолжениям, в то время как высокая температура позволяет модели быть более творческой и генерировать неожиданные (а иногда и нелепые) продолжения.
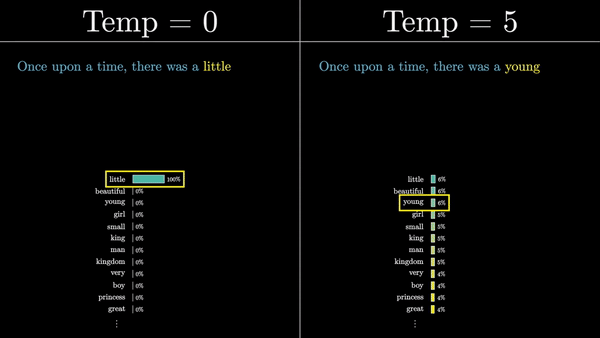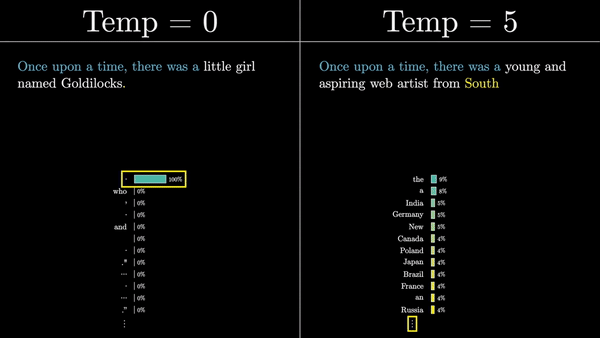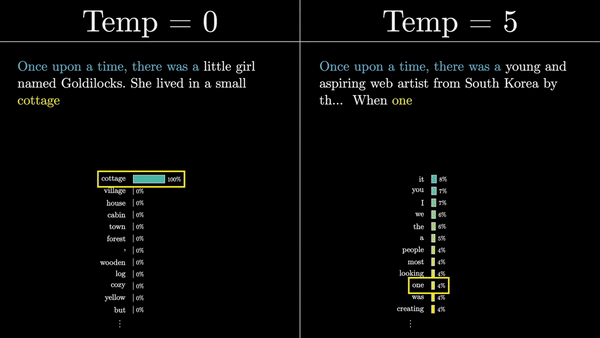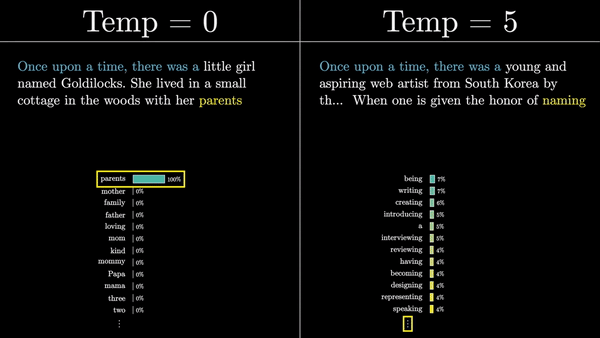
Затем эти логиты нормализуются с помощью функции softmax, чтобы получить вероятностное распределение по всем токенам словаря. Этот вектор представляет собой предсказание модели о том, какой токен с наибольшей вероятностью появится следующим в последовательности.

Собрав все эти элементы воедино – разбиение на токены, создание векторных представлений, блоки внимания, многослойные персептроны и финальное предсказание, – мы получаем полноценную архитектуру трансформера, способную виртуозно манипулировать языком и генерировать осмысленные ответы.
Обучение трансформеров
Для того, чтобы трансформеры смогли приобрести такие впечатляющие способности по генерации текста, их необходимо тщательно обучить на больших объемах данных. Способности готовой модели зависят не только от количества, но и от качества этих данных.
В основе обучения большинства современных нейронных сетей лежит алгоритм обратного распространения ошибки. Этот алгоритм позволяет настраивать огромное количество параметров модели (в GPT-3 их 175 млрд, а в GPT-4, по некоторым оценкам, уже 1,76 трлн) таким образом, чтобы минимизировать ошибку при предсказании следующего слова в тексте.
Для эффективной работы алгоритма обратного распространения нейронные сети должны иметь определенную структуру:
- Ввод и вывод представлены в виде массивов чисел. Независимо от типа данных (текст, изображения, звук), на входе и выходе всегда присутствуют численные массивы – одномерные списки, двумерные массивы (матрицы) или многомерные тензоры.
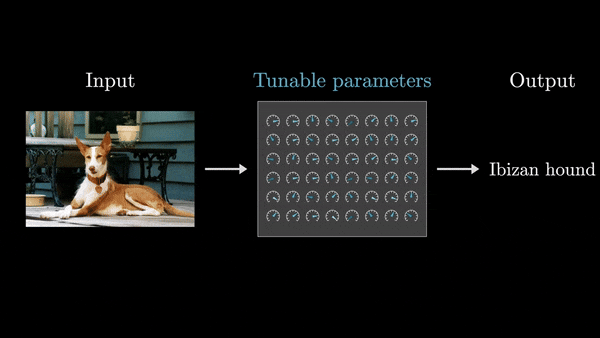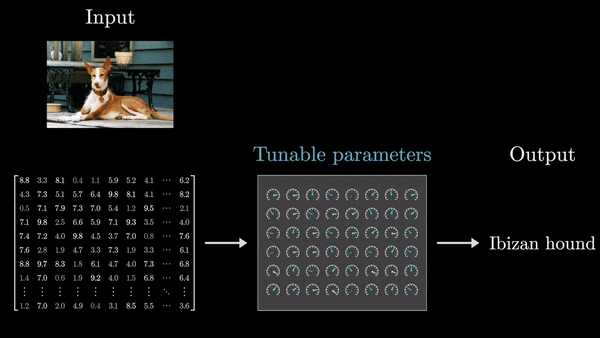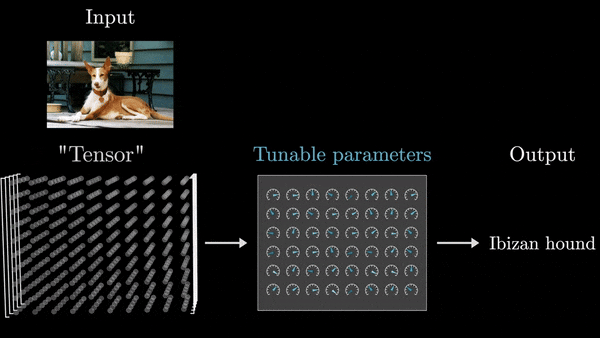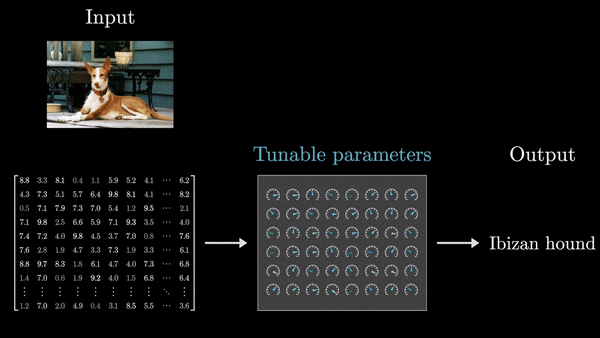
- Модель состоит из последовательных слоев, каждый из которых также представляет собой числовой массив.
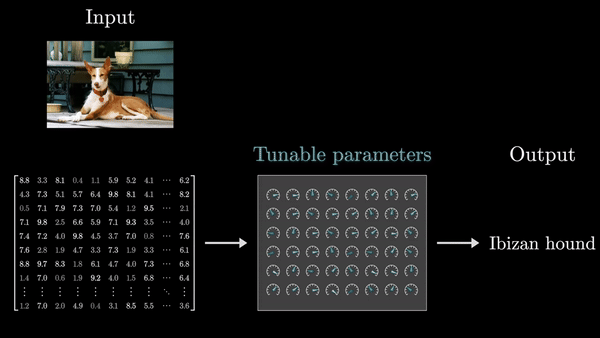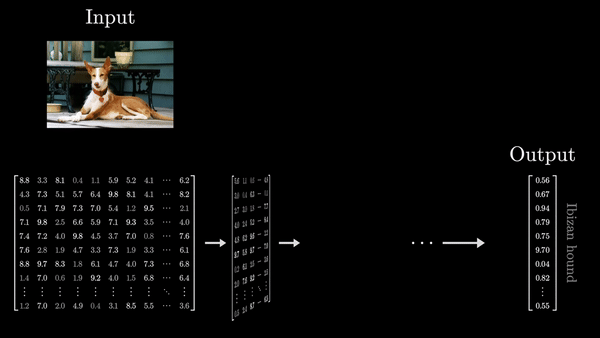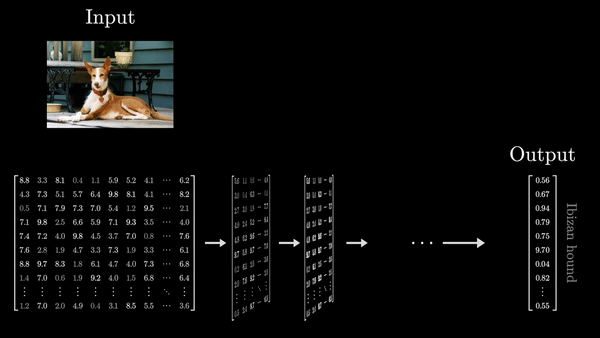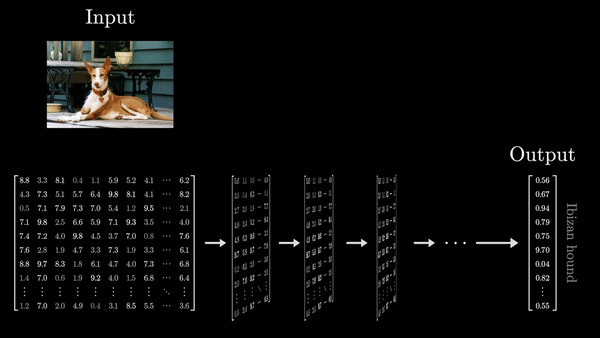
- Входные данные последовательно преобразуются через множество таких слоев. Обучение сети сводится к настройке параметров, называемых весами, которые определяют, как именно будут осуществляться эти преобразования.
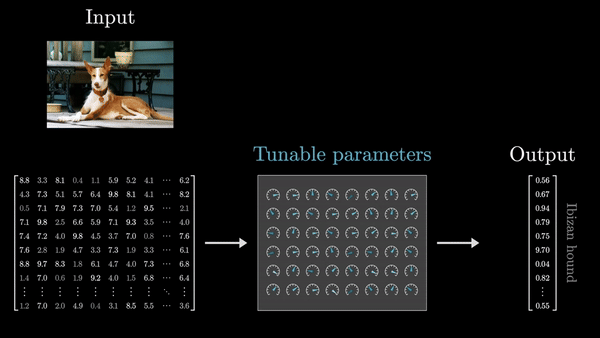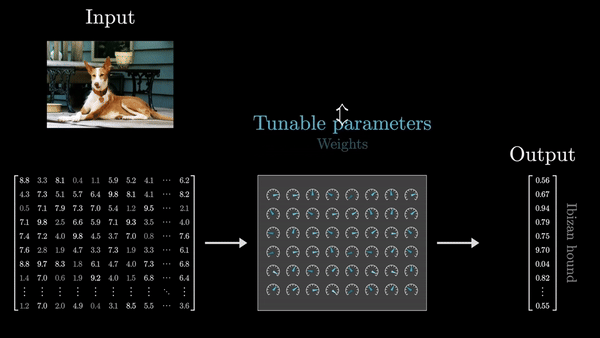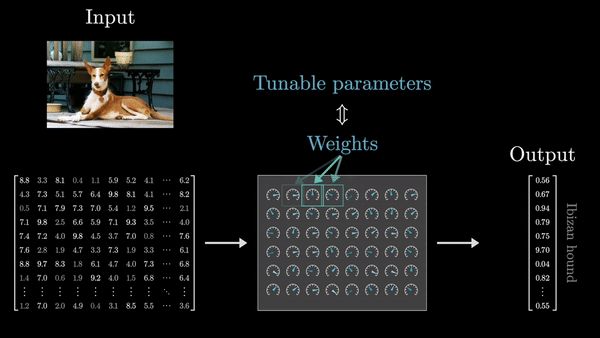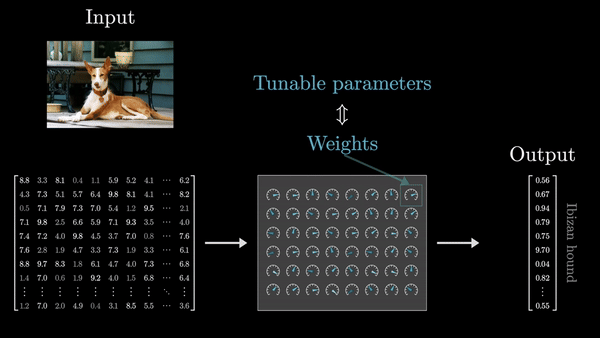
- Веса организованы в матрицы, и вся вычислительная логика сводится к матричным операциям – умножению матриц на векторы. Именно это свойство делает глубокие сети эффективными и масштабируемыми. Важно помнить, что веса – это «мозг» модели, а входные данные – просто сырье, которое преобразуется этим мозгом.
- По мере продвижения по слоям сети, входные данные все больше насыщаются семантическим содержанием, закодированным в весах. Каждый вектор в последовательности одновременно используется для предсказания следующего слова. Это делает обучение более эффективным, позволяя модели максимально использовать всю доступную информацию.
- Наряду с линейными операциями, используются также нелинейные функции активации (например, сигмоида). Они помогают модели захватывать более сложные закономерности в данных.
Масштабирование трансформеров
Архитектура трансформеров, описанная выше, лежит в основе многих современных языковых моделей. Однако с момента появления первых трансформеров в 2017 году, эти модели прошли значительную эволюцию, становясь все более мощными и многофункциональными.
Что же позволяет трансформерам наращивать свои масштабы настолько быстро? Ключевую роль здесь играют несколько факторов:
- Модульная архитектура. Трансформеры состоят из отдельных блоков (внимание, MLP и т.д.), количество которых можно наращивать по мере необходимости. Это упрощает масштабирование.
- Методы сжатия и ускорения. Для уменьшения вычислительных затрат и ускорения работы моделей используются более короткиe представления чисел (например, FP16 вместо FP32) и разреженные матрицы. Эти методы позволяют сократить объем данных, а также уменьшить количество операций, необходимых для выполнения вычислений.
- Эффективное использование вычислительных ресурсов. Трансформеры могут эффективно использовать параллелизм, что позволяет значительно ускорить обучение и вывод модели. Кроме того, современные аппаратные ускорители GPU и TPU оптимизированы для выполнения матричных операций, на которых основана работа трансформеров.
- Предварительное обучение на больших данных. Предварительное обучение трансформеров на огромных корпусах текстов позволяет им приобретать фундаментальные знания о языке, что облегчает последующую адаптацию к конкретным задачам.
- Постоянная оптимизация алгоритмов обучения. Исследователи непрерывно совершенствуют методы тренировки трансформеров – это позволяет им лучше масштабироваться и обобщать знания.
Благодаря этим факторам, модели на основе трансформеров демонстрируют впечатляющую способность наращивать свои возможности при увеличении размера. Причем этот рост происходит не линейно, а по экспоненте – каждое новое поколение трансформеров значительно превосходит предыдущее. Однако, несмотря на впечатляющие успехи, у трансформеров все еще остаются определенные ограничения и проблемы, которые предстоит решить.
Ограничения трансформеров и направления их развития
Хотя трансформеры произвели революцию в области обработки естественного языка, они все еще сталкиваются с рядом проблем и ограничений, которые требуют дальнейших исследований и разработок.
Одна из главных проблем – ограниченный контекст: трансформеры могут одновременно учитывать лишь фиксированное количество предыдущих элементов текста. Этот факт затрудняет их способность поддерживать долгосрочную связность и последовательность в генерируемом тексте, особенно в случае длинных диалогов или многостраничных документов. Исследователи активно работают над решением этой проблемы, разрабатывая архитектуры, которые позволяют трансформерам эффективно использовать больший контекст: благодаря этим усовершенствованиям, средний объем контекста за 2023 год увеличился с 4000 до 1 млн токенов.
Другая сложная проблема – склонность трансформеров к галлюцинациям, особенно при генерации текста по малоизученным темам. Решение этой проблемы требует интеграции трансформеров с другими компонентами, например, RAG-системой.
Еще одна важная задача – обеспечение безопасности и этичности использования трансформеров. Мощные способности GPT открывают широкие возможности для злоупотреблений, например, для генерации мошеннического, непристойного и противозаконного контента.
Над решением всех этих проблем активно работают исследователи, и несмотря на определенные сложности, трансформеры продолжают стремительно развиваться. Мы наблюдаем постоянное увеличение их масштабов, улучшение архитектур, а также расширение областей применения. Все больше задач в сфере обработки естественного языка, синтеза речи, генерации аудио/видео/графики успешно решаются с помощью трансформеров.
Более того, идеи, лежащие в основе трансформеров, начинают проникать и в другие направления ИИ, открывая новые возможности для моделирования сложных систем. С этой точки зрения трансформеры можно назвать ключевым драйвером современного прогресса в области ИИ. И, очевидно, именно развитие трансформеров в ближайшие годы будет расширять границы того, что мы считаем возможным для искусственного интеллекта – пока не будет разработана какая-то принципиально новая архитектура генеративного ИИ.

OMG! Хочу знать всё о моделях машинного обучения
Заглядывай к нам на курс «Базовые модели ML и приложения» на котором ты:
- Познакомишься с основными моделями машинного обучения.
- Научишься выбирать и применять подходящие tree-based модели.
- Получишь основу для дальнейшего изучения более сложных нейронных сетей.
Программа
- Бустинг, Бэггинг и Ансамбли.
- Алгоритмы рекомендаций.
- Архитектуры нейросетей.



Комментарии