

Меню
Для объяснения, как работают LLM воспользуемся аналогией с едой. Представим, что мы готовим обед и нам осталось придумать еще одно гарнирное блюдо, которое должно органично вписываться в меню. Если блюдо пряное, наш гарнир тоже должен быть таким. Если в нем уже есть салат, мы не должны делать еще один салат.
Набросаем черновик приложения, которое порекомендует нам, что приготовить. Это приложение должно работать для любого меню, с любой комбинацией блюд, любого количества едоков.

Шаг первый: моделирование меню
Мы начнем с того, что научим компьютер рассматривать блюда как данные: снабдим его большим количеством данных о типах блюд, которые люди сочетали в прошлом.
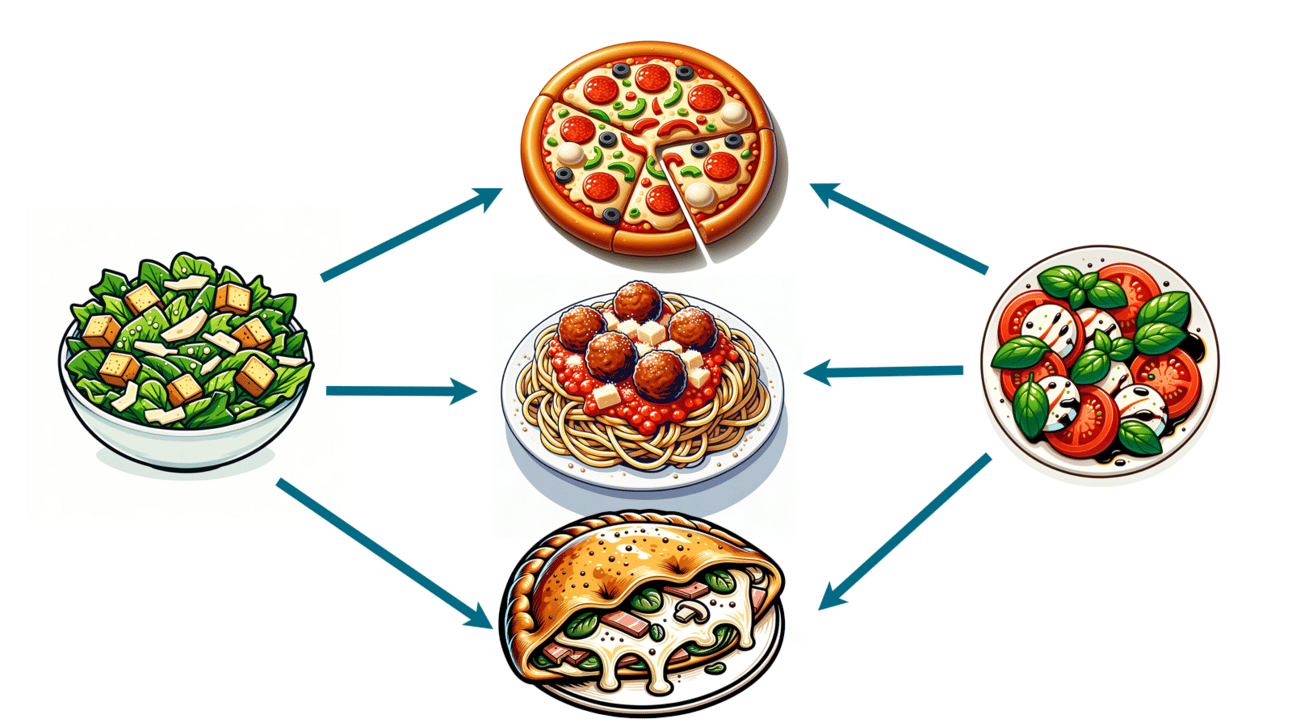
Рассмотрим два типа блюд: салат «Цезарь» и салат «Капрезе». Мы, как люди, знаем, что эти два блюда похожи: они итальянские, являются салатами, содержат овощи и сыры. Но машине не нужно знать ничего из вышеперечисленного, чтобы понять, насколько похожи эти два блюда.

Вероятно, что салат «Цезарь» часто сочетается с другими итальянскими блюдами в нашем наборе данных. И также вероятно, что наличие салата «Цезарь» означает, что в меню не будет другого салата. То же самое можно сказать и о салатах «Капрезе». Они, как правило, не появляются вместе с другими салатами, но появляются с итальянскими блюдами.
Поскольку эти два блюда часто встречаются вместе с одними и теми же типами блюд, мы можем классифицировать их как похожие. Они, как правило, встречаются в одних и тех же меню. Можно сказать, что они имеют похожие «векторы меню».
Добавим математики: отобразим все блюда на прямоугольной (декартовой) системе координат:
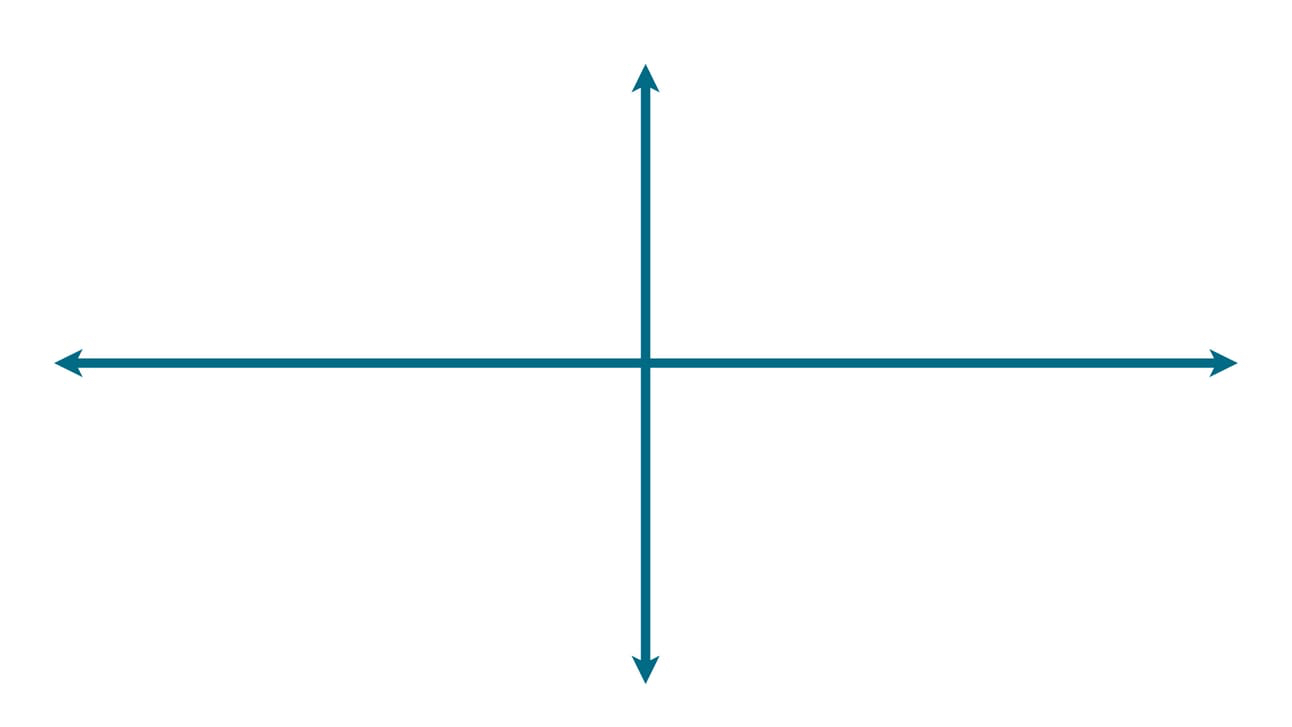
Расположим все возможные блюда, которые нашли в наших данных, случайным образом:
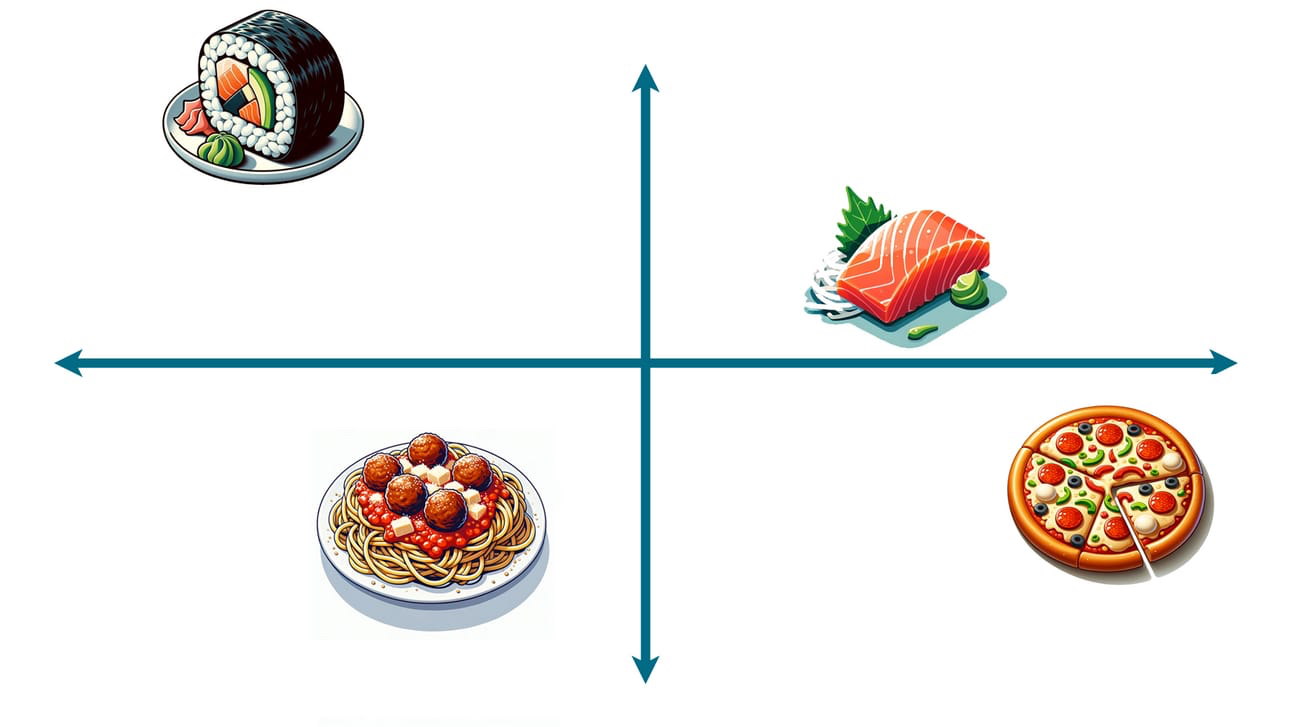
Каждый раз, когда мы находим два блюда, которые встречаются вместе с другими блюдами, мы можем сдвигать их ближе друг к другу. Когда мы видим, что разные виды суши сочетаются с одним и тем же мисо-супом, мы будем постепенно сдвигать суши друг к другу. Когда мы видим, что пицца и спагетти появляются вместе с чесночным хлебом, мы тоже позволим им сблизиться:
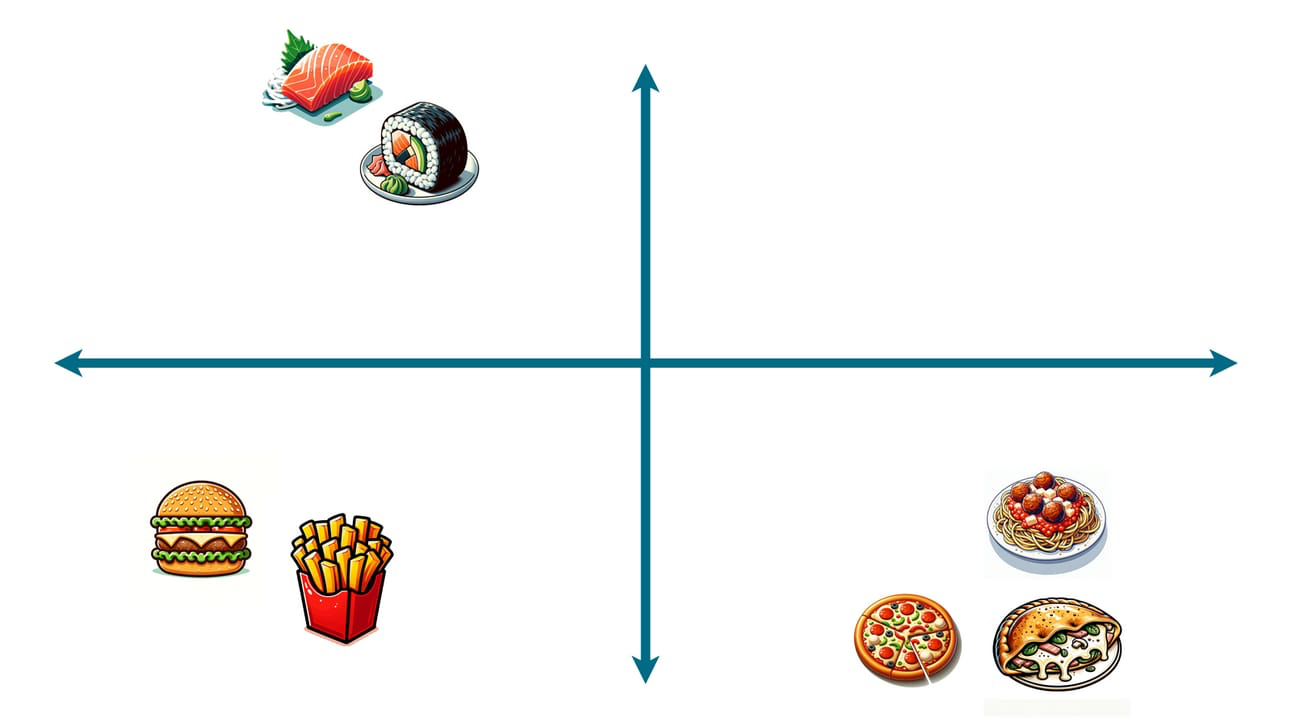
После многократного повторения взаимозаменяемые блюда будут очень тесно сгруппированы. Блюда, которые в некоторой степени взаимозаменяемы (скажем, тако и буррито), будут расположены ближе друг к другу. А блюда, которые слабо взаимозаменяемы (скажем, бургеры и суши), будут расположены далеко друг от друга.
На практике двух измерений недостаточно. Чтобы по-настоящему правильно сгруппировать каждое блюдо, нам понадобились бы больше осей (сотни, может быть, тысячи). Это невозможно визуализировать, но основная концепция остается той же: мы отдаляем все наши продукты и сближаем их, когда они встречаются вместе с похожими блюдами.
Для краткости я буду называть этот крупное многоосевое представление пространством блюд. Каждое возможное блюдо существует в пространстве блюд, находясь в ближе с взаимозаменяемыми блюдами и далеко от тех, которые сильно отличаются.
На самом деле, не только похожие блюда расположены рядом, но они также имеют логические связи с другими продуктами. Например, все блюда, содержащие хлеб, находятся на одной плоскости.
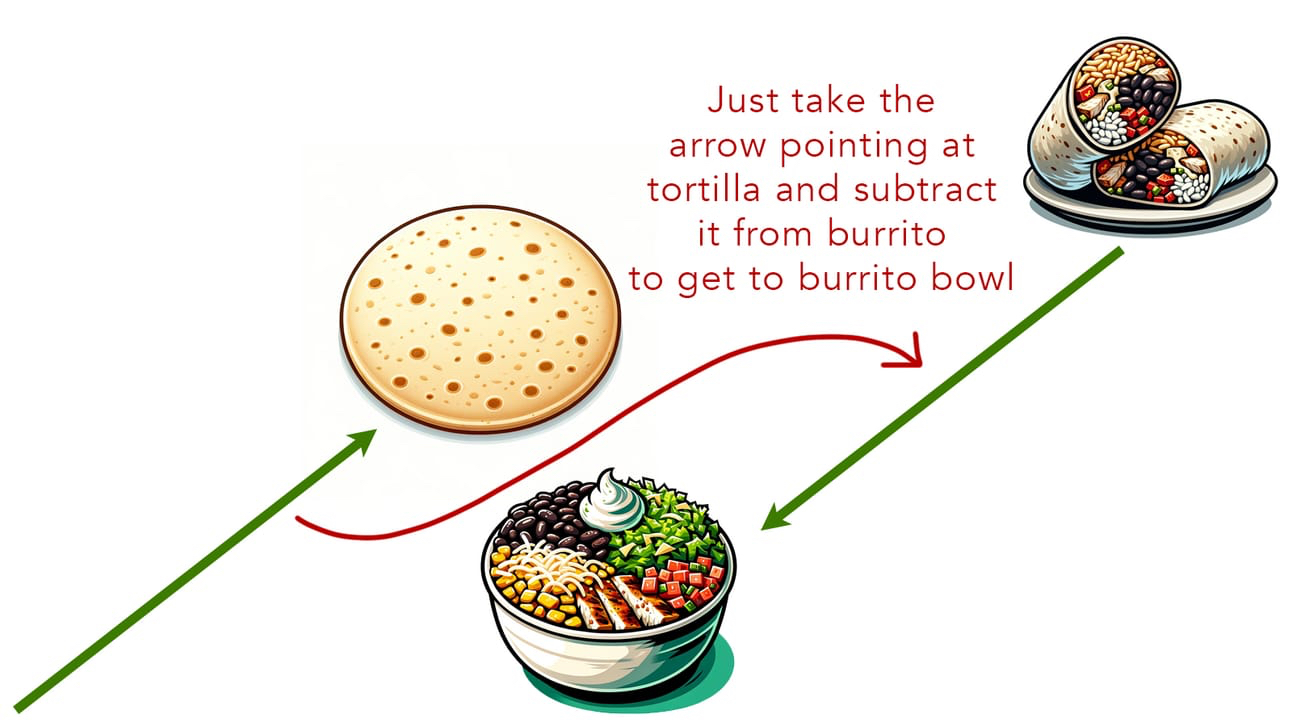
И это позволяет нам делать «пищевую арифметику». Если бы я взял координаты буррито и вычел координаты тортильи, я бы оказался рядом с точкой буррито-боул. Если бы я взял координаты куриного супа с лапшой, вычел координаты лапши и добавил координаты риса, я бы оказался рядом с точкой куриного супа с рисом.
Шаг второй: поиск закономерностей
Мы создали пространство блюд и дали каждому типу блюда некоторые координаты, которые имеют смысл относительно каждого другого блюда. Что теперь?
Что ж, давайте снова обучим нашу модель. Только на этот раз мы будем подавать ей меню, состоящие из блюд – мы говорим о каждом блюде, которое мы когда-либо видели, – и попросим ее найти закономерности. В частности, мы хотим обучить нашу программу отвечать на следующий вопрос: если меню содержит A, B, C и неизвестный D, то какое блюдо, скорее всего, будет D?
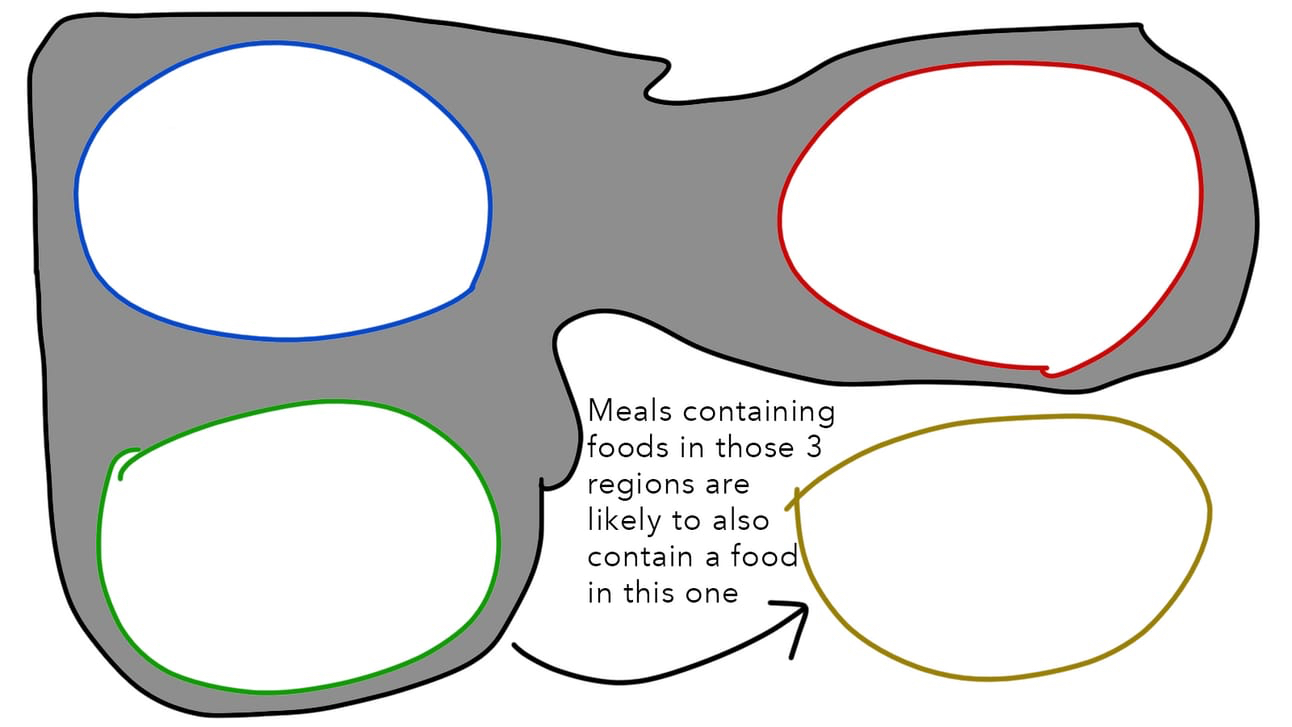
И для этого все, что нам нужно сделать, это спросить: как выглядят A, B, C и неизвестный D в пространстве блюд? Например, предположим, что мы видим много блюд, которые имеют общие блюда в этих четырех областях.

Теперь мы можем обобщить и думать исключительно о координатах в пространстве блюд, игнорируя исходные блюда, которые создали эти закономерности. Мы можем сделать вывод, что если меню уже содержит блюда в этих трех областях, то подходящее четвертое блюдо будет найдено в последней области.
Слова вместо меню и блюд
Чтобы понять, как работают LLM (языковые модели), замените концепцию меню на предложения. А концепцию блюд замените на слова. Эта простая замена с той же формулировкой и подходом, по сути, дает вам представление о том, как работают генеративные текстовые инструменты ИИ.
Шаг первый
Обучите модель понимать взаимосвязи между словами на основе того, как часто они появляются в похожих контекстах. Загрузите в нее огромное количество данных, написанных человеком (весь интернет), и позвольте ей соответствующим образом перемещать координаты слов.
Результат больше не называется пространством блюд. Он называется векторным пространством. Но принципы те же. Система не имеет представления о том, что означает какое-либо слово (так же, как она не имела представления о том, каково блюдо на вкус). Она понимает только то, как это слово связано с каждым другим словом в векторном пространстве.
Шаг второй
Найдите закономерности. Если предложение содержит слова A, B и C, какое следующее слово, скорее всего, появится? Если оно содержит X и Y, в какой области векторного пространства следует искать то, что будет дальше?
В случае LLM, все, что они на самом деле делают под капотом, называется «предсказанием следующего слова» (так же, как наша первоначальная аналогия выполняла предсказание следующего блюда). Например, предположим, что вы сказали LLM продолжить фразу: Скажи, что любишь меня. LLM «подумает»: какое слово с наибольшей вероятностью последует за этой последовательностью слов? Или, выражаясь иначе: учитывая координаты векторного пространства слов в этом предложении, какие закономерности я видел в других предложениях, чтобы определить, где я могу найти следующее слово?
Ответ, который найдет LLM, – это Я. И определив это, она добавит Я к концу вашей фразы. Теперь, какое слово, скорее всего, будет следующим после Скажи, что любишь меня. Я. Конечно же, люблю. LLM добавит слово люблю в конец. Дальше будет: Скажи, что любишь меня. Я люблю.
Вы поняли идею :)
Конечно, есть немного больше нюансов. Есть некоторая сложная математика и сложные вычисления. Но основы действительно ничем не отличаются от тех, что были в примере с планированием меню.
Хочу разобраться в базовых моделях ML. Где этому учат?
Поднять уровень знаний вы можете на нашем курсе «Базовые модели ML и приложения» со скидкой 35% до 1 апреля. На курсе вы познакомитесь с основными моделями машинного обучения. Научитесь выбирать и применять подходящие tree-based модели. Получите основу для дальнейшего изучения более сложных нейронных сетей.
- 1-й модуль: Бустинг, Бэггинг и Ансамбли
- 2-й модуль: Алгоритмы рекомендаций
- 3-й модуль: Архитектуры нейросетей
Комментарии