
Linux, Windows, Mac OS? Зачем они нужны? Понимание того, как работают операционные системы, поможет создавать качественные приложения.
Есть несколько причин, почему программистам стоит знать, как работают операционные системы. Одна из них – чтобы понимать, как работают программы. Представьте: вы пишете код, который кажется рабочим, но программа тормозит. Что делать? Можно попробовать разобраться с ограничениями операционной системы, но вы ведь не умеете!
Если стремитесь построить карьеру программиста, стоит понять, как работают операционные системы. Например, можно изучить курс «Введение в операционные системы» от Georgia Tech. В нем рассказывается, как работают ОС: механизмы работы, параллельное программирование (потоки и синхронизация), взаимодействие между процессами, распределённые ОС.
Осветим 10 наиболее важных принципов, о которых говорилось в курсе Udacity, и разберемся, как же работают операционные системы.
Что такое операционная система
Это первое, о чем нужно задуматься, если вы решили разобраться, как работают операционные системы. ОС представляют собой набор программного обеспечения. Это ПО управляет компьютерным оборудованием и предоставляет техническую базу для программ. А ещё они управляют вычислительными ресурсами и обеспечивают защиту. Главное, что у них есть, – это доступ к управлению компонентами компьютера.
Файловая система, планировщик и драйверы – всё это основные инструменты работы ОС.
Существует три ключевых элемента операционной системы:
- Абстракции (процессы, потоки, файлы, сокеты, память).
- Механизмы (создание, управление, открытие, запись, распределение).
- Реализации (алгоритмы LRU, EDF).
Кроме того, есть два основных принципа проектирования операционных систем:
- Максимальная гибкость: отделение механизмов от конкретных реализаций.
- Ориентация на пользователей: на каких устройствах будет работать ОС, что нужно пользователю, каковы требования к производительности.
Теперь подробнее разберём глобальные концепции, которые помогут сформировать понимание того, как работают операционные системы.
Процессы и управление
Процесс – не что иное, как исполнение программы. Так как программа записана в виде последовательности действий в текстовый файл, процессом она становится только при запуске.
Загруженная в память программа может быть условно разделена на четыре части: стек, кучу, контекст и данные.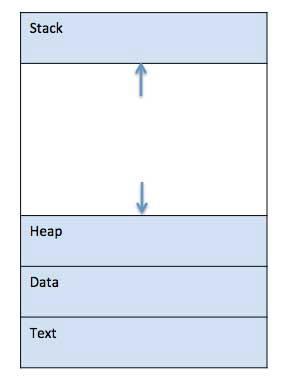
- Stack: стек процесса содержит временные данные, такие как параметры метода, адрес возврата и локальные переменные.
- Heap: это динамически распределяемая память процесса времени его выполнения.
- Text: хранит состояние регистров, состояние программного счетчика, режим работы процессора, незавершенные операции ввода-вывода, информацию о выполненных системных вызовах.
- Data: раздел содержит глобальные и статические переменные.
Когда процесс выполняется, он проходит через разные состояния. Эти этапы могут различаться в разных операционных системах.
Общая картина выглядит так: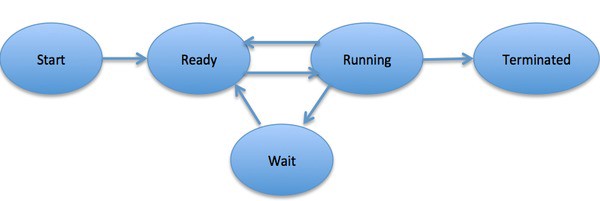
- Start: начальное состояние при создании процесса.
- Ready: процесс ожидает исполнения на процессоре. В течение работы процессор может переключаться между процессами, переводя одни в режим готовности, другие – в режим исполнения.
- Running: выполнение инструкций.
- Wait: процесс переходит в состояние ожидания. Например, ждёт ввода данных или получения доступа к файлу.
- Terminated: как только процесс завершится, он перейдёт в это состояние и будет ожидать удаления.
Немного терпения: мы уже близки к пониманию того, как работают операционные системы ;)
Блок управления процессов (Process Control Block) – это структура данных, поддерживаемая операционной системой для каждого процесса. PCB имеет идентификатор PID. Именно PCB хранит всю информацию, необходимую для отслеживания процесса.
- Process ID: идентификатор каждого из процессов в ОС.
- State: текущее состояние процесса.
- Privileges: разрешения доступа к системным ресурсам.
- Pointer: указатель на родительский процесс.
- Priority: приоритет процесса и другая информация, которая требуется для планирования процесса.
- Program Counter: указатель на адрес следующей команды, которая должна быть выполнена.
- CPU registers: регистры процессора, необходимые для состояния исполнения.
- Accounting Information: уровень нагрузки на процессор, статистика и другие данные.
- I/O Information: список ресурсов, использующих чтение и запись.
Потоки и параллелизм
Поток (нить, thread) – это ход исполнения программы. Он также имеет свой program counter, переменные, стек.
Потоки одной программы могут работать с одними данными, а взаимодействовать между собой через код.
Поток – это легковесный процесс. Вместе они обеспечивают производительность приложений и ОС за счет параллелизма на уровне программы.
Каждый поток относится к какому-то процессу и не может существовать без него. Сегодня потоки широко применяются в работе серверов и многопроцессорных устройств с общей памятью.
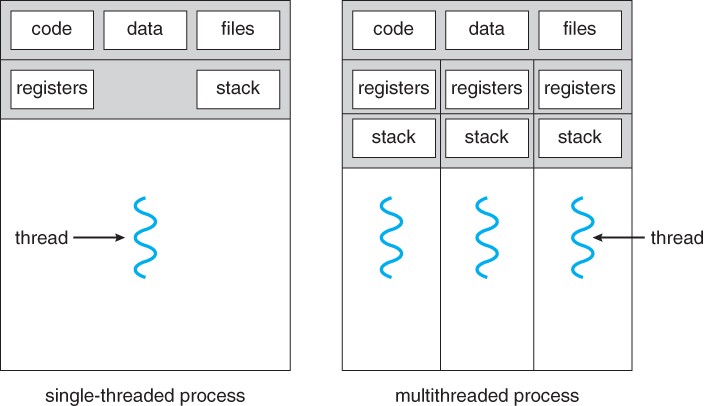
Чем хороши потоки:
- Они минимизируют время переключения контекста (процессора).
- Их использование обеспечивает параллелизм процесса.
- Они эффективно общаются между собой.
- Потоки позволяют использовать многопроцессорные архитектуры в большем масштабе.
Потоки имеют два уровня реализации:
- Пользовательский уровень, то есть потоки, управляемые приложениями;
- Уровень ядра, то есть потоки, управляемые ядром операционной системы.
В первом случае ядро управления потоками ничего не знает о существовании потоков вообще. А библиотека потоков просто содержит код для создания и уничтожения потоков, а также передачи сообщений и данных между ними для планирования выполнения потоков и сохранения (восстановления) контекстов потоков.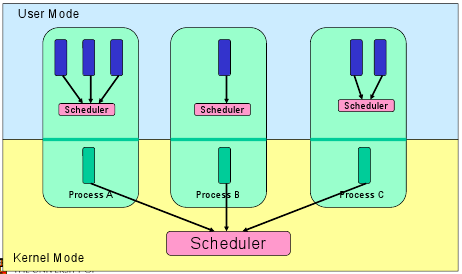
Во втором случае ядро выполняет создание потоков, а ещё планирование и управление в пространстве ядра. Заметим, что потоки ядра обычно медленнее, чем потоки пользователей.
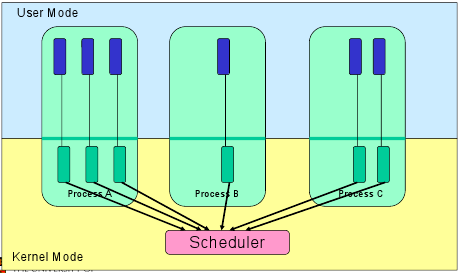
Планирование
Планировщик – это часть менеджера процессов, которая ответственна за переключение между процессами и выбор очереди по какой-либо стратегии.
ОС поддерживает все блоки управления процессом (PCB) в очередях планирования процесса:
- Очередь задач (job queue) поддерживает все процессы в системе.
- Очередь ожидания (ready queue) хранит информацию обо всех процессах, находящихся в основной памяти в состоянии ожидания. В эту очередь попадают и новые процессы.
- Очереди из устройств (device queue) – это процессы, заблокированные из-за недоступности устройств ввода-вывода.
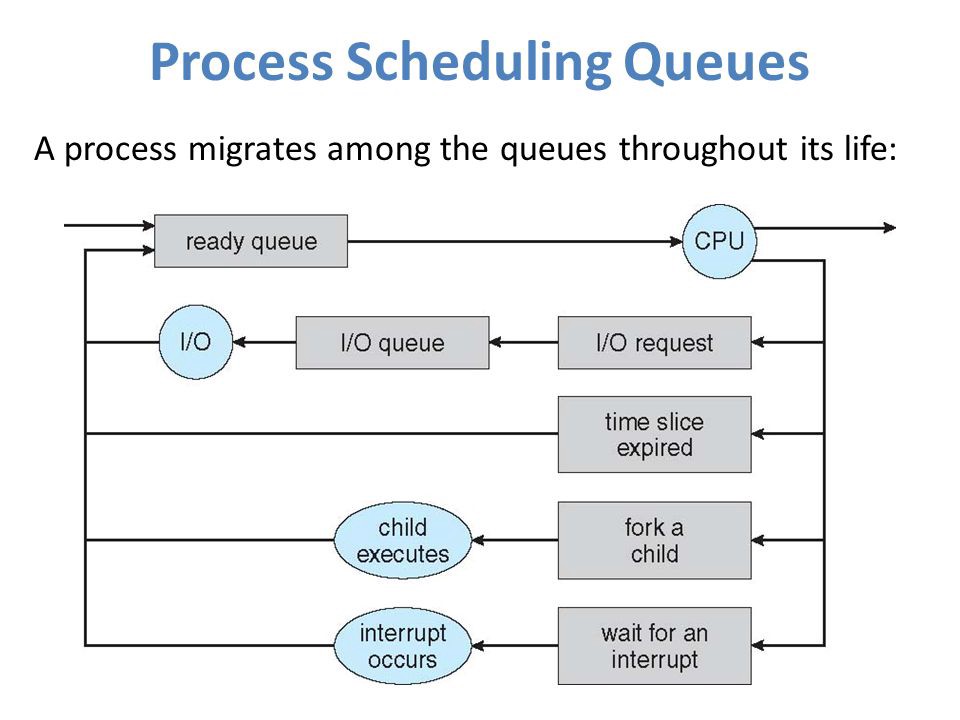
ОС может использовать разные методы реализации для управления очередями (FIFO, Round Robin, Priority). Планировщик ОС определяет, когда и как перемещать процессы между готовыми и запущенными очередями (могут иметь только одну запись на ядро процессора в системе). На приведенной выше диаграмме он был объединен с процессором.
Модели состояния делятся на активные и неактивные:
- Активные: при создании нового процесса он переходит в класс активных.
- Неактивные: процессы, которые не выполняются, а ждут завершения других процессов. Каждая запись в очереди является указателем на конкретный процесс. Очередь реализуется с использованием связанного списка. Использование диспетчера заключается в следующем: когда процесс прерывается, то переносится в очередь ожидания. Если процесс завершен или отменен – он отменяется вовсе.
Переключение контекста – это механизм сохранения (в PCB) и восстановления контекста процессора с ранее запущенного промежутка времени. При использовании этого метода, коммутатор контекста позволяет использовать один процессор для нескольких действий одновременно. Кстати, контекстное переключение является неотъемлемой частью многозадачной операционной системы.
Когда планировщик переключает процессор с одного процесса на другой, состояние из текущего запущенного процесса сохраняется в блоке управления. Затем состояние для следующего процесса загружается из своего PCB в регистры процессора. Только потом второй процесс может быть запущен.
При переключении следующая информация сохраняется для последующего использования: счетчик программы, информация планировщика, значение регистра базы и лимита, используемый в настоящее время регистр, измененное состояние, информация о состоянии ввода и вывода, учетная информация.
Управление памятью
Ещё одна важная часть – та, что отвечает за все операции по управлению первичной памятью. Существует менеджер памяти, который обрабатывает все запросы на получение памяти и высвобождение. Он же следит за каждым участком памяти, независимо от того, занят он или свободен. И он же решает, какой процесс и когда получит этот ресурс.
Адресное пространство процесса – набор логических адресов, к которым программа обращается в коде. Например, если используется 32-битная адресация, то допустимые значения варьируются от 0 до 0x7fffffff, то есть 2 Гб виртуальной памяти.
Операционная система заботится о том, чтобы сопоставить логические адреса с физическими во время выделения памяти программе. Нужно также знать, что существует три типа адресов, используемых в программе до и после выделения памяти:
- Символьные адреса: или по-другому адреса, используемые в исходном коде. Имена переменных, константы и метки инструкций являются основными элементами символического адресного пространства.
- Относительные адреса: компилятор преобразует символические адреса в относительные адреса.
- Физические адреса: загрузчик генерирует эти адреса в момент загрузки программы в основную память.
Виртуальные и физические адреса одинаковы как в процессе загрузки, так и во время компиляции. Но они начинают различаться во время исполнения.
Набор всех логических адресов, которые создала программа, называется логическим адресным пространством. Набор всех физических адресов, соответствующих этим логическим адресам, называется физическим адресным пространством.
Хотите разобраться подробнее в том, как работают операционные системы? Посмотрите соответствующие книги в нашем Телеграм-канале.
Межпроцессорное взаимодействие
Существует два типа процессов: независимые и взаимодействующие. На независимые не оказывается влияние процессов сторонних, в отличие от взаимодействующих.
Можно подумать, что процессы, которые работают независимо, выполняются эффективнее, но зачастую это не так. Использование кооперации может повысить скорость вычислений, удобство и модульность программ.
Межпроцессная коммуникация (IPC) – это механизм, который позволяет процессам взаимодействовать друг с другом и синхронизировать действия. Связь между этими процессами может рассматриваться как сотрудничество.
Процессы могут взаимодействовать двумя способами: через общую память или через передачу сообщений.
Метод использования общей памяти
Допустим, есть два процесса: исполнитель (производитель) и потребитель. Один производит некоторый товар, а второй его потребляет. Эти два процесса имеют общее пространство или ячейку памяти, известную как «буфер». Там хранится элемент, созданный исполнителем, оттуда же потребитель получает этот элемент.
Однако у этих версий есть как минимум две значимые проблемы: первая известна как проблема безграничного буфера: исполнитель может продолжать создавать элементы без ограничений на размер буфера. Вторая заключается в том, что исполнитель, заполнив буфер, переходит в режим ожидания.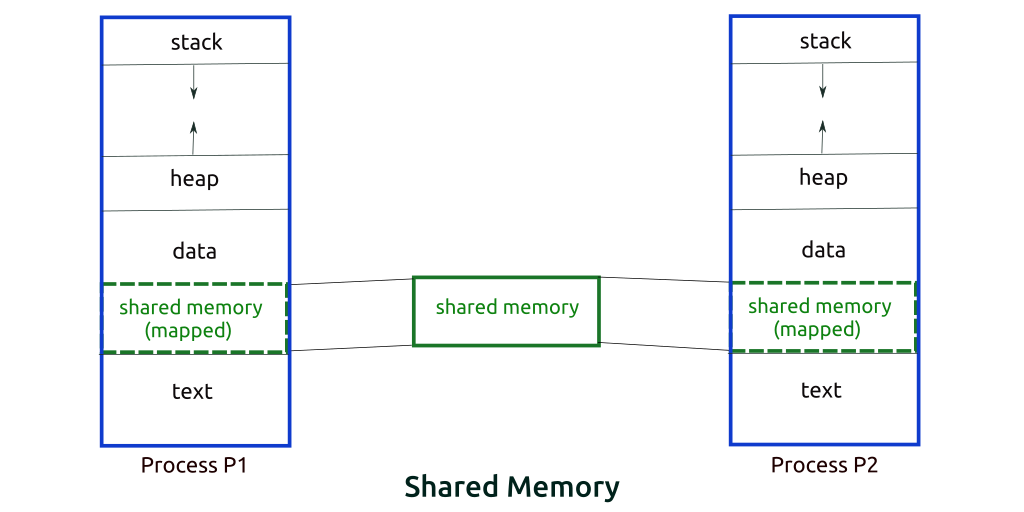
В задаче с ограниченным буфером у исполнителя и потребителя будет общая память. Если общее количество произведенных товаров равно размеру буфера, то исполнитель будет ждать их потребления.
Аналогично потребитель сначала проверит наличие товара, и если ни один элемент не будет доступен, придётся ждать его освобождения.
Метод анализа сообщений
С помощью этого метода процессы взаимодействуют друг с другом без использования общей памяти. Допустим, есть два процесса, p1 и p2, которые хотят взаимодействовать друг с другом. Они работают следующим образом:
- Устанавливается связь (если её ещё не существует).
- Начинается обмен сообщениями с помощью базовых примитивов. Нам нужно как минимум два примитива – отправить (сообщение, пункт назначения) или получить (сообщение).
Размер сообщения может быть фиксированным или переменным. Проектировщикам ОС проще работать с сообщениями фиксированного размера, а программистам – переменного. Стандартное сообщение состоит из двух частей – заголовка и тела.
Управление вводом и выводом
Одной из важнейших задач операционной системы является управление различными устройствами ввода и вывода вроде мыши, клавиатуры, дисководов, etc.
Система ввода и вывода принимает запрос приложения на ввод или вывод данных, а затем отправляет его на соответствующее физическое устройство. После возвращает приложению полученный ответ. Устройства ввода и вывода можно разделить на две категории:
- Блочные: то есть устройства, с которыми драйверы связываются, отправляя целые блоки данных. Например, жесткие диски, USB-камеры, Disk-On-Key.
- Символьные: те устройства, с которыми драйвер связывается, отправляя и получая одиночные символы (байты или октеты). Например, последовательные порты, параллельные порты, звуковые карты и так далее.
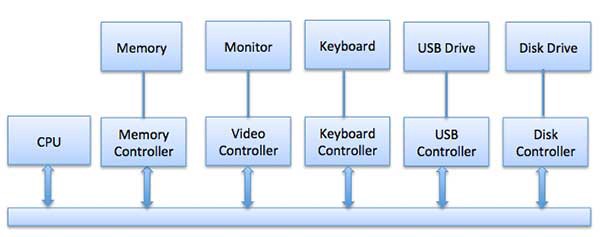
ЦПУ должен иметь способ передачи информации на устройство ввода-вывода и обратно. И есть три способа сделать это:
- Специальные инструкции
Особые, неуниверсальные инструкции процессора, внедренные специально для контроля устройств ввода-вывода. Они позволяют отправлять данные на устройство и считывать их оттуда.
- Входы и выходы с отображением памяти
Когда используется ввод-вывод с отображением памяти, одно и то же адресное пространство разделяется памятью и устройствами ввода-вывода. Устройство подключается непосредственно к ячейкам памяти так, чтобы можно было передавать блок данных без применения ЦПУ.
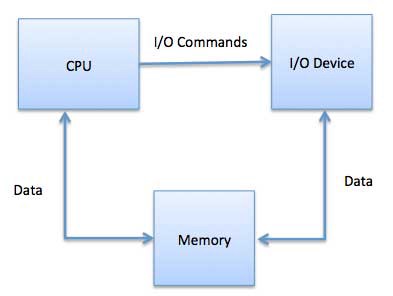
- Прямой доступ к памяти (DMA)
Медленные устройства, такие как клавиатуры, генерируют прерывания ЦПУ после передачи каждого байта. Если бы быстрые устройства работали похожим образом, то ОС бы тратила большую часть времени впустую, на обработку этих прерываний. Поэтому для снижения нагрузки обычно используется прямой доступ к памяти (DMA).
Это означает, что ЦПУ предоставляет модулю ввода и вывода полномочия для чтения или записи в память. Сам модуль управляет обменом данными между основной памятью и устройством ввода-вывода. ЦПУ участвует в начале и конце передачи, а прерывается только после полной передачи блока.
Организация прямого доступа к памяти требует специального оборудования, называемого контроллером DMA (DMAC). Он управляет передачей данных и доступом к системной шине. Контроллеры запрограммированы с указателями источника и места назначения, счетчиками для отслеживания количества переданных байтов и прочими настройками.
Виртуализация
Технология, которая позволяет создавать несколько сред или выделенных ресурсов из единой физической аппаратной системы называется виртуализация
Программное обеспечение, гипервизор, напрямую подключается к этой аппаратной системе и позволяет разбить ее на отдельные, безопасные среды – виртуальные машины. По идее, гипервизор должен аппаратные ресурсы между виртуальными машинами так, чтобы процессы выполнялись быстрее.
Физическая машина с гипервизором называется хостом, а виртуальные машины, которые используют ресурсы данного хоста – гостями. Для них ангаром ресурсов являются процессор, память, хранилище. Для получения доступа к этим ресурсам операторы управляют виртуальными экземплярами.
В идеале, все связанные виртуальные машины управляются с помощью единой веб-консоли управления виртуализацией. Она нужна, чтобы ускорять работу. Виртуализация позволяет определить, сколько вычислительной мощности и памяти выделять виртуальным машинам. Кроме того, так как виртуальные машины технически не связаны между собой, это повышает безопасность сред.
Проще говоря, виртуализация создает дополнительные мощности для выполнения процессов.
Типы виртуализации
- Данные: позволяет компаниям обеспечивать вычислительные мощности для объединения данных из нескольких источников, размещения новых источников и преобразования данных в соответствии с потребностями пользователя.
- Рабочий стол: легко спутать с виртуализацией операционной системы. Виртуализация рабочего стола позволяет центральному администратору одновременно развёртывать смоделированные среды на сотнях физических машин. Виртуальные системы позволяют администраторам выполнять массовые конфигурации, обновления и проверки безопасности на всех устройствах сразу.
- Серверы: программная имитация с помощью специального ПО аппаратного обеспечения компьютера: процессор, память, жесткий диск, и т. д. На такой виртуальный компьютер можно установить операционную систему, и она будет на нем работать точно так же, как и на простом, «железном» компьютере. Самое интересное достоинство этой технологии – это возможность запуска нескольких виртуальных компьютеров внутри одного физического. При этом, все виртуальные компьютеры могут работать независимо друг от друга.
Сервер – компьютер, спроектированный под выполнение большого объема специфических задач. Виртуализация сервера позволит ему выполнять больше этих специальных задач, а также разделить функционал на разные компоненты. - ОС: это способ одновременного запуска Linux и Windows-сред. Преимущество в том, что это уменьшает затраты на оборудование, повышает безопасность и экономит время на обслуживании.
- Сетевые функции: разделяет ключевые функции сети (например, службы каталогов, общий доступ к файлам и IP-конфигурацию) для распределения между средами. Виртуальные сети сокращают количество физических компонентов: коммутаторов, маршрутизаторов, серверов, кабелей.
Система файловой дистрибуции
Распределенная файловая система – это клиентское или клиент-серверное приложение, которое позволяет получать и обрабатывать данные. Они хранятся на сервере, как если бы они находились на персональном компьютере. Когда пользователь запрашивает файл, сервер отправляет ему копию запрашиваемого файла, который кэшируется на компьютере пользователя во время обработки данных, а затем возвращается на сервер.
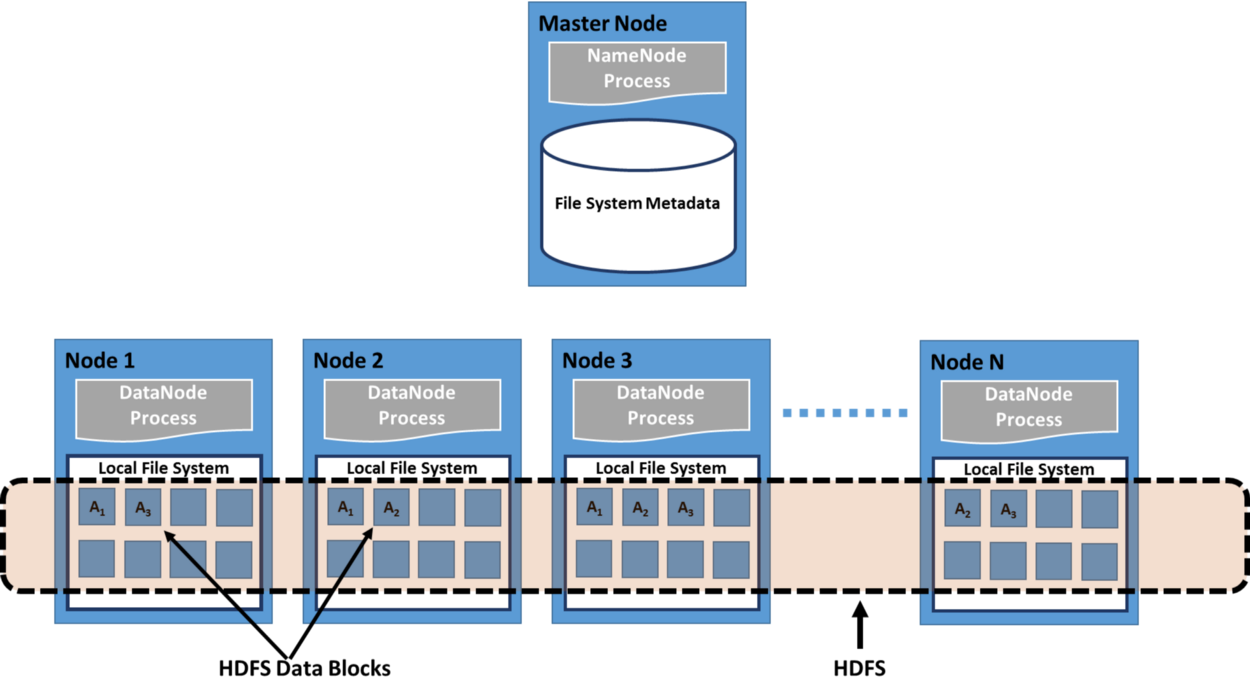
Бывает так, что за одними и теми же данными одновременно обращаются сразу несколько пользователей. Для этих целей сервер должен иметь механизм организации обновлений, чтобы клиент всегда получал самую актуальную версию данных. Распределенные файловые системы обычно используют репликацию файлов или баз данных для защиты от сбоев.
Сетевая файловая система Sun Microsystems (NFS), Novell NetWare, распределенная файловая система Microsoft и DFS от IBM являются примерами распределенных файловых систем.
Распределенная общая память
Распределенная общая память (DSM) – это компонент управления ресурсами распределенной операционной системы. В DSM доступ к данным осуществляется из общего пространства, аналогично способу доступа к виртуальной памяти. Данные перемещаются между дополнительной и основной памятью, а также между разными узлами. Изменения прав собственности происходят, когда данные перемещаются с одного узла на другой.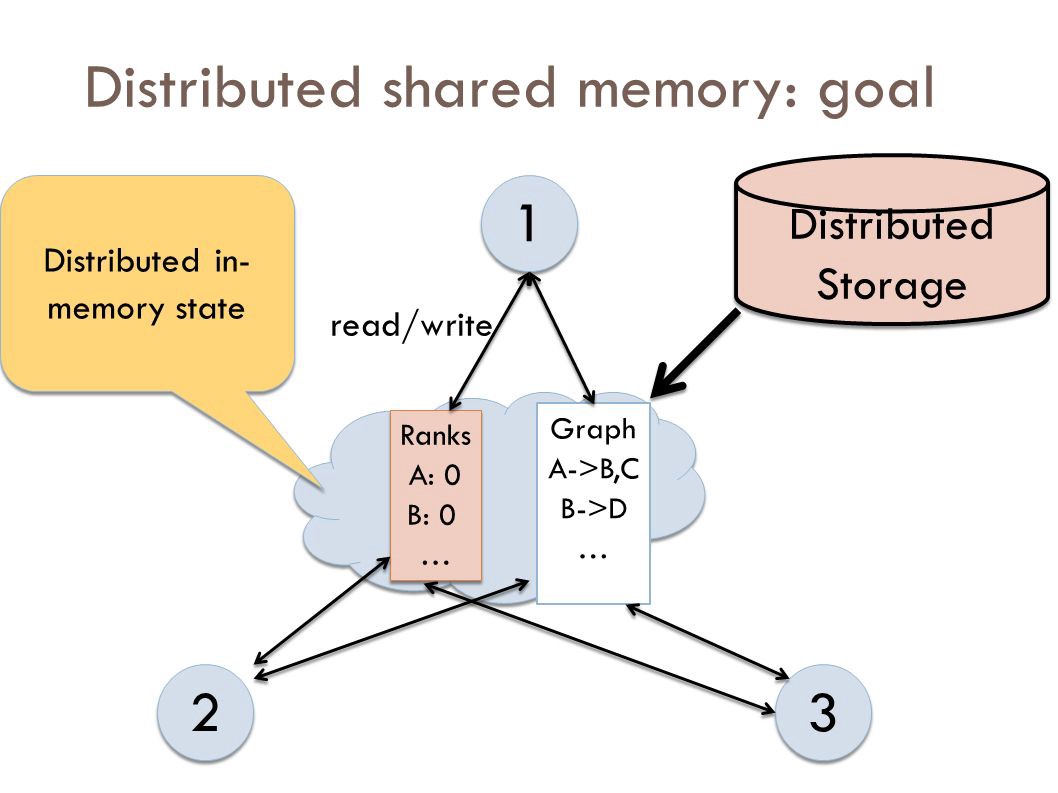
Преимущества распределенной общей памяти:
- Программистам можно не беспокоиться о передаче памяти между машинами, потому что перемещение данных можно скрыть;
- Можно передавать сложные структуры по ссылке, упрощая разработку алгоритмов для распределенных приложений;
- Это дешевле, чем многопроцессорные системы и может быть реализовано с использованием обычного оборудования;
- Можно использовать неограниченное количество узлов;
- Программы, написанные для мультипроцессоров с общей памятью, могут быть запущены в системах DSM.
Облачные вычисления
Всё больше процессов переходит в облако. По сути, облачные вычисления – это своего рода аутсорсинг компьютерных программ. Используя облачные вычисления, пользователи могут получать доступ к программному обеспечению и приложениям из любого места. Это означает, что им не нужно беспокоиться о таких вещах, как хранение данных и питание компьютера.
Традиционные бизнес-приложения всегда были очень сложными, дорогими в обслуживании – нужна команда экспертов для установки, настройки, тестирования, запуска, защиты и обновления. Это одна из причин, почему стартапы проигрывают корпорациям.
Используя облачные вычисления, вы передаёте ответственность за аппаратное и программное обеспечение опытным специалистам, таким как Salesforce и AWS. Вы платите только за то, что вам нужно, апгрейд платежного плана производится автоматически по мере ваших потребностей, а масштабирование системы протекает без особых сложностей.
Приложения на базе облачных вычислений могут работать эффективнее, дольше и стоить дешевле. Уже сейчас компании используют облачные приложения для множества приложений, таких как управление отношениями с клиентами (CRM), HR, учет и так далее.
Итоги
В заключение хочется ещё раз вернуться к тому, зачем вообще разбираться в том как работают операционные системы. Операционная система – это «мозг», который управляет входными, обрабатываемыми и выходными данными. Все остальные компоненты также взаимодействуют с операционной системой. Понимание того, как работают операционные системы, прояснит некоторые детали и в других компьютерных науках, ведь взаимодействие с ними организуется именно средствами ОС.
Разобрались, как работают операционные системы? Вот ещё несколько интересных статей на тему:
- Курс лекций по операционным системам;
- Компьютерные науки или программная инженерия – что выбрать;
- Что должен знать программист без профильного образования.
Источник: Как работают операционные системы: 10 концептов, которые нужно знать разработчикам on Medium.
Комментарии