

В этом туториале вы узнаете, как перейти на новую версию Elasticsearch. В рассматриваемом проекте осуществлялся переход с 1.6 на 6.8, но общие идеи справедливы и для других версий. Конечно, требовалось не просто перейти, но и соблюсти ряд жёстких ограничений: нулевое время простоя, отсутствие ошибок и потерь данных.

1. Зачем понадобился перенос данных?
В рассматриваемом примере проекта были следующие проблемы, повлиявшие на необходимость переноса:
- Проблемы с производительностью и стабильностью – наличие большого количества перебоев с длительным MTTR. Это отражалось в частых задержках и высокой загрузке процессора.
- Отсутствие поддержки для старых версий Elasticsearch.
- Негативное влияние dynamic mapping на работу кластера.
- Нехватка инструментов экспорта и метрик, встроенных в новую версию.
2. Рассмотрим условия
Какие условия нужно было выполнить:
- Миграция с нулевым временем простоя. Поскольку в обновляемой системе имеются активные пользователи, нельзя допустить падения системы.
- План восстановления. Нельзя потерять или испортить данные, независимо от их ценности. Нужно иметь план восстановления на случай, если что-то пойдёт не так.
- Отсутствие ошибок. Для конечных пользователей привычные функции поиска не должны измениться.
3. Обдумаем план
Ошибки. Для удовлетворения требования по отсутствию ошибок необходимо изучить все возможные результаты и запросы, которые получает работающая система, а также обеспечить тестами ответственные куски кода. В качестве проверки результата нужно добавить метрики для отслеживания задержки, пропускной способности и производительности, чтобы проверить динамику.
План восстановления. На данном этапе подготовьтесь к ситуации, когда сервис будет работать не так, как ожидалось. В общих чертах нужно создать копию кластера и перенести на него инфу незаметно для юзеров.
Миграция с нулевым временем простоя. Работающий сервис всегда онлайн и не может быть недоступен более 5-10 минут. Чтобы сделать всё правильно, поступаем так:
- Храним логи всех выполняемых действий (в продакшене используется Kafka).
- Запускаем процесс миграции в офлайне с отслеживанием смещения с момента начала миграции.
- Когда миграция завершится, запускаем новую службу, учитывая логирование и «догоняем» отставание.
- Когда отставание сведено к нулю, изменяем версию фронтенда.
4. План действий
Текущий сервис имеет следующую архитектуру:
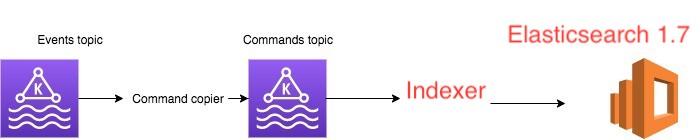
Event topicсодержит события, созданные другими приложениями (например, UserId 3 created);Command topicсодержит трансляцию этих событий в конкретные команды, используемые приложением (например: Add userId 3);Elasticsearch 1.7– хранилище, обслуживаемое индексатором Indexer.
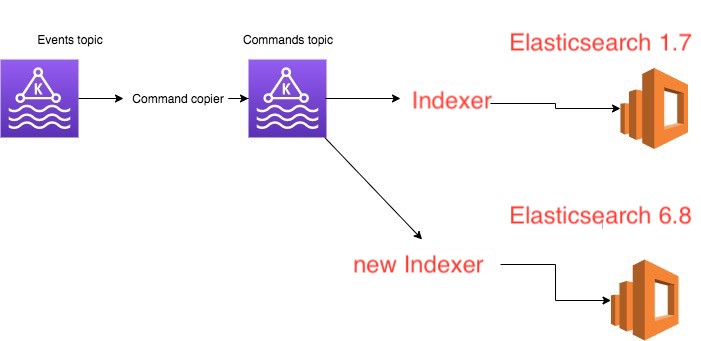
По плану необходимо добавить еще одного клиента (new Indexer) для Command topic, который будет параллельно читать и записывать данные в Elasticsearch 6.8.
С чего начать?
Вот несколько полезныхвещей, которые помогут:
- Документация. Найдите время, чтобы прочитать о Mapping и QueryDsl.
- API. Всё крутится на CAT API. Это очень полезный инструмент для локального дебага и проверки ответа от Elastic.
- Метрики. Настройте мониторинг с метриками и ресурсами из elasticsearch-exporter-for-Prometheus, которые помогут лучше понимать происходящее.
Часть 5. Проблемы из-за Mapping
Опишем подробнее пример использования, вот наша модель:
class InsertMessageCommand(tags: Map[String,String])
Пример сообщения по вышеописанной схеме:
new InsertMessageCommand(Map("name"->"dor","lastName"->"sever"))
Эта модель поддерживает запросы по значению, а также по тегу со значением. Динамический шаблон вызывал постоянные сбои. Схема выглядела так:
curl -X PUT "localhost:9200/_template/my_template?pretty" -H 'Content-Type: application/json' -d '
{
"index_patterns": [
"your-index-names*"
],
"mappings": {
"_doc": {
"dynamic_templates": [
{
"tags": {
"mapping": {
"type": "text"
},
"path_match": "actions.tags.*"
}
}
]
}
},
"aliases": {}
}'
curl -X PUT "localhost:9200/your-index-names-1/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"actions": {
"tags" : {
"name": "John",
"lname" : "Smith"
}
}
}
'
curl -X PUT "localhost:9200/your-index-names-1/_doc/2?pretty" -H 'Content-Type: application/json' -d'
{
"actions": {
"tags" : {
"name": "Dor",
"lname" : "Sever"
}
}
}
'
curl -X PUT "localhost:9200/your-index-names-1/_doc/3?pretty" -H 'Content-Type: application/json' -d'
{
"actions": {
"tags" : {
"name": "AnotherName",
"lname" : "AnotherLastName"
}
}
}
'
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match" : {
"actions.tags.name" : {
"query" : "John"
}
}
}
}
'
# returns 1 match(doc 1)
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match" : {
"actions.tags.lname" : {
"query" : "John"
}
}
}
}
'
# returns zero matches
# search by value
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d
{
"query": {
"query_string" : {
"fields": ["actions.tags.*" ],
"query" : "Dor"
}
}
}
'
Предположительно, причина сбоев состояла в использовании вложенных документов.
В обновлённой схеме были применены следующие запросы:
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"tags": {
"type": "nested"
}
}
}
}
}
'
curl -X PUT "localhost:9200/my_index/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"tags" : [
{
"key" : "John",
"value" : "Smith"
},
{
"key" : "Alice",
"value" : "White"
}
]
}
'
# Query by tag key and value
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "tags",
"query": {
"bool": {
"must": [
{ "match": { "tags.key": "Alice" }},
{ "match": { "tags.value": "White" }}
]
}
}
}
}
}
'
# Returns 1 document
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "tags",
"query": {
"bool": {
"must": [
{ "match": { "tags.value": "Smith" }}
]
}
}
}
}
}
'
# Query by tag value
# Returns 1 result
Количество документов в кластере составляло около 500 млн, с использованием вложенных документов в новой схеме цифра может вырасти до 250 млрд документов. Этот пост объясняет, что всему виной проблемы с использованием кучи, так как она может вызвать высокую задержку в запросах.
Как уйти от вложенных документов. Создаётся поле, содержащее комбинацию ключа и значения, и всякий раз, когда пользователю требуется совпадение ключа и значения, его запрос транслируется в соответствующий текст.
curl -X PUT "localhost:9200/my_index_2?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"tags": {
"type": "object",
"properties": {
"keyToValue": {
"type": "keyword"
},
"value": {
"type": "keyword"
}
}
}
}
}
}
}
'
curl -X PUT "localhost:9200/my_index_2/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"tags" : [
{
"keyToValue" : "John:Smith",
"value" : "Smith"
},
{
"keyToValue" : "Alice:White",
"value" : "White"
}
]
}
'
# Query by key,value
# User queries for key: Alice, and value : White , we then query elastic with this query:
curl -X GET "localhost:9200/my_index_2/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [ { "match": { "tags.keyToValue": "Alice:White" }}]
}}}
'
# Query by value only
curl -X GET "localhost:9200/my_index_2/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [ { "match": { "tags.value": "White" }}]
}}}
'
6. Миграция
Для миграции потребуется:
- Перенести данные из старого Elastic в новый.
- Закрыть отставание между началом миграции и её окончанием.
С первым всё понятно, а вот решения второго шага:
- Система основана на Kafka, поэтому используем текущее смещение до начала миграции, а после завершения миграции переносим данные из точки смещения. Это решение подразумевает гору ручного труда.
- Другой подход к решению этой проблемы – начать перенос сообщений из Kafka и сделать все действия в Elasticsearch неизменяемыми, то есть если изменение уже было «применено», в Elastic store ничего не изменится.
Второй вариант более предпочтителен, так как не требует ручной работы.
Перенос данных
Среди массы вариантов переноса данных самый подходящий основан на передаче сообщений между старым и новым Elastic. Для этого создаём скрипт на Python, который будет ходить на старый кластер, таскать оттуда инфу и параллельно преобразовывать её под новую схему.
dictor==0.1.2 - to copy and transform our Elasticsearch documents
elasticsearch==1.9.0 - to connect to "old" Elasticsearch
elasticsearch6==6.4.2 - to connect to the "new" Elasticsearch
statsd==3.3.0 - to report metrics
from elasticsearch import Elasticsearch
from elasticsearch6 import Elasticsearch as Elasticsearch6
import sys
from elasticsearch.helpers import scan
from elasticsearch6.helpers import parallel_bulk
import statsd
ES_SOURCE = Elasticsearch(sys.argv[1])
ES_TARGET = Elasticsearch6(sys.argv[2])
INDEX_SOURCE = sys.argv[3]
INDEX_TARGET = sys.argv[4]
QUERY_MATCH_ALL = {"query": {"match_all": {}}}
SCAN_SIZE = 1000
SCAN_REQUEST_TIMEOUT = '3m'
REQUEST_TIMEOUT = 180
MAX_CHUNK_BYTES = 15 * 1024 * 1024
RAISE_ON_ERROR = False
def transform_item(item, index_target):
# implement your logic transformation here
transformed_source_doc = item.get("_source")
return {"_index": index_target,
"_type": "_doc",
"_id": item['_id'],
"_source": transformed_source_doc}
def transformedStream(es_source, match_query, index_source, index_target, transform_logic_func):
for item in scan(es_source, query=match_query, index=index_source, size=SCAN_SIZE,
timeout=SCAN_REQUEST_TIMEOUT):
yield transform_logic_func(item, index_target)
def index_source_to_target(es_source, es_target, match_query, index_source, index_target, bulk_size, statsd_client,
logger, transform_logic_func):
ok_count = 0
fail_count = 0
count_response = es_source.count(index=index_source, body=match_query)
count_result = count_response['count']
statsd_client.gauge(stat='elastic_migration_document_total_count,index={0},type=success'.format(index_target),
value=count_result)
with statsd_client.timer('elastic_migration_time_ms,index={0}'.format(index_target)):
actions_stream = transformedStream(es_source, match_query, index_source, index_target, transform_logic_func)
for (ok, item) in parallel_bulk(es_target,
chunk_size=bulk_size,
max_chunk_bytes=MAX_CHUNK_BYTES,
actions=actions_stream,
request_timeout=REQUEST_TIMEOUT,
raise_on_error=RAISE_ON_ERROR):
if not ok:
logger.error("got error on index {} which is : {}".format(index_target, item))
fail_count += 1
statsd_client.incr('elastic_migration_document_count,index={0},type=failure'.format(index_target),
1)
else:
ok_count += 1
statsd_client.incr('elastic_migration_document_count,index={0},type=success'.format(index_target),
1)
return ok_count, fail_count
statsd_client = statsd.StatsClient(host='localhost', port=8125)
if __name__ == "__main__":
index_source_to_target(ES_SOURCE, ES_TARGET, QUERY_MATCH_ALL, INDEX_SOURCE, INDEX_TARGET, BULK_SIZE,
statsd_client, transform_item)
Заключение
Перенос данных в живом продакшене – сложная задача, требующая большого внимания и тщательного планирования. Мы рекомендуем потратить время, проработать шаги на тестовых машинах и выяснить, что лучше всего подойдёт для вашей конкретной ситуации.
Всегда старайтесь максимально снизить влияющие факторы. Например, требуется ли нулевой простой или можно “тормознуть” некоторый функционал сервиса? Не станет ли потеря данных проблемой?
Обновление любого хранилища с данными обычно является не спринтом, а марафоном, поэтому сделайте глубокий вдох, запаситесь попкорном и наслаждайтесь поездкой.
Комментарии