

Часть 1. Связность
Говоря о том, что метод обладает высокой связностью (high cohesion), мы имеем в виду, что он работает как одна (и только одна) логическая составляющая. Другими словами, каждая единица кода (класс, метод и так далее) должна иметь единственное назначение, которое легко понять с первого взгляда. Это давний принцип программной инженерии (Принцип Единственной Ответственности). Методы с низкой связностью выполняют несколько процедур и, можно сказать, имеют несколько назначений.
Если класс является высоко связным, то он тоже инкапсулирует одну (и только одну) составляющую бизнес-логики. Например, приложение среднего уровня с высокой связностью будет иметь классы, которые чётко разделяют абстрактные классы передачи данных, их инстанцирование, функционал базы данных и бизнес-логику. Если всё делает один-единственный класс, то, скорее всего, у него очень низкая связность.
Мы также можем говорить о связности пакетов (или сборок в среде CLR). Каждая сборка должна инкапсулировать один (и только один) бизнес-домен. Если наша сборка отправляет письма о подтверждении заказа, производит вычисления и моет нашу посуду, то речь идёт о не очень связной сборке, которую будет очень сложно поддерживать.
Взглянем на пример большого метода с очень низкой связностью, который совершает серию логических подшагов в общем процессе извлечения данных из базы данных и построения нескольких объектов передачи данных. Моё собственное правило заключается в том, что если метод не помещается на экране, то он слишком длинный и нуждается в перепроектировании.
Вот эти подшаги:
- инстанцирование подключения к базе данных;
- инстанцирование команды к базе данных;
- открытие подключения;
- выполнение команды;
- чтение результатов;
- извлечение данных из DataReader;
- получение записей и инстанцирование нового экземпляра объекта.
Просматривая код ниже, обратите внимание на то, как сложно понять суть этого метода с первого раза. Если сдадитесь — прокрутите до конца этого блока кода, где мы начнём перепроектирование.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
// инстанцирование подключения
using(SqlConnection connection = newSqlConnection(ConfigurationManager.ConnectionStrings[CONNECTION_STRING_KEY].ConnectionString))
using(SqlCommand command = new SqlCommand("spGetEmployee", connection)) // инстанцирование команды
{
command.CommandType = CommandType.StoredProcedure;
// попытка открыть подключение
try
{
connection.Open();
}
catch (InvalidOperationException ex)
{
// логирование исключения
throw;
}
catch (SqlException ex)
{
// логирование исключения
throw;
}
catch (Exception ex)
{
// логирование исключения
throw;
}
// выполнение метода ExecuteReader() и чтение результатов
using(SqlDataReader reader = command.ExecuteReader())
{
Int32 m_NameOrdinal, m_DeptOrdinal;
// получение порядковых номеров
try
{
m_NameOrdinal = reader.GetOrdinal(NAME);
m_DeptOrdinal = reader.GetOrdinal(DEPARTMENT);
}
catch(System.IndexOutOfRangeException ex)
{
// логирование исключения
throw;
}
Collection<Employee> result = new Collection<Employee>();
// чтение результатов
while(reader.Read())
{
try
{
Employee emp =new Employee();
emp.Name = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_NameOrdinal);
emp.Department = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_DeptOrdinal);
result.Add(emp);
}
catch (IndexOutOfRangeException ex)
{
// логирование исключения
throw;// перебросить или обработать здесь
}
catch (Exception ex)
{
// логирование общего исключения
throw;// перебросить или обработать здесь
}
}
return result;
}
}
}
Всё, что нам надо — это быстро понять, что делает код, и иметь возможность по необходимости заглянуть поглубже. Было бы сложно протестировать какой-то один шаг процесса, так как всё свалено в одну кучу.
Пример высокой связности
Внизу у нас метод с тем же функционалом, но построенный гораздо более связно, без имплементации логики. Единственное назначение этого метода — это управление вызовами многоразовых методов. В результате в проекте будет меньше повторяющегося кода, потому что в каждом многоразовом подшаге достаточно логики. У этого метода тот же функционал, что и у нашего несвязного кода. Как вы думаете, его легче понять?
public IEnumerable<Employee> GetEmployeesFromDb_HighCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
using (SqlDataReader reader = ExecuteReader(command, connection))
{
return new MapperFactory()
.BuildEmployeeMapper()
.ReadAll(reader);
}
}
Часть 2. Рефакторинг кода из низкой в высокую связность
Первый шаг для рефакторинга кода с низкой связностью — это определение, каковы логические шаги и где они находятся. Для начала взглянем на инстанцирование объекта. Мы можем переорганизовать весь код, ответственный за инстанцирование объектов, в методы-строители, что часто имеет огромное значение.
Первое инстанцирование — это объект SqlConnection. Построим фабрику для наших объектов. Это выгодно в плане повторного использования, потому что мы будем строить новое подключение каждый раз, как нам потребуется база данных.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
// инстанцирование подключения
using(SqlConnection connection = newSqlConnection(ConfigurationManager.ConnectionStrings[CONNECTION_STRING_KEY].ConnectionString))
using(SqlCommand command = new SqlCommand("spGetEmployee", connection)) // инстанцирование команды {
... продолжение кода ...
Мы выбираем код инстанцирования и используем Refactoring tool в Visual Studio (2008) для извлечения метода. После рефакторинга получится очень связный метод, который можно использовать каждый раз, как нам понадобится соединение с базой данных. Как можно заметить, с толикой форматирования этот метод становится очень связным и легко понимаемым. Так что, если наши коллеги-разработчики из главного метода дойдут до него (или если мы просматриваем свой старый код), будет сложно запутаться в том, что этот метод делает.
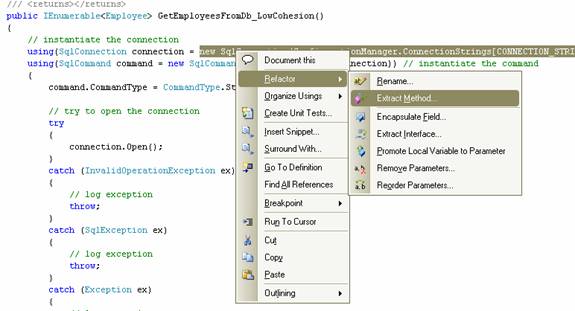
К слову: если у вас нет Studio08, на http://www.jetbrains.com/resharper/ есть очень хороший плагин с рефакторингами на Studio05. Их текущая версия для Studio08 не поддерживает синтакс LINQ и немного неудобна, если вы используете новые фичи 3.5, но в марте будет новый релиз уже с поддержкой LINQ.
Вот как теперь выглядит метод-строитель (на всякий случай с разрывами строк):
private SqlConnection BuildConnection()
{
return newSqlConnection(
ConfigurationManager
.ConnectionStrings[CONNECTION_STRING_KEY]
.ConnectionString);
}
И наш главный метод стал чуточку легче:
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using(SqlConnection connection = BuildConnection())
using(SqlCommand command = new SqlCommand("spGetEmployee", connection)) // инстанцирование команды {
//... продолжение кода ...
В следующий раз мы инстранцируем объект и можем реорганизовать метод-строитель, когда мы строим SqlCommand.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using(SqlCommand command = new SqlCommand("spGetEmployee", connection))
{
command.CommandType = CommandType.StoredProcedure;
//-- продолжение кода --
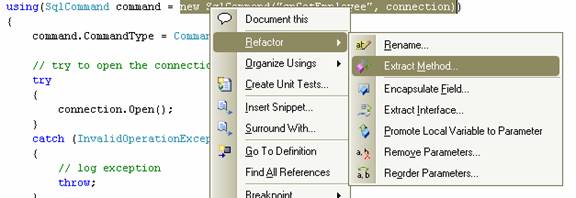
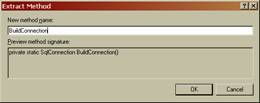
По этому же принципу, выберем строительную часть кода и вынесем её в отдельный метод. Получится вот так:
private static SqlCommand BuildCommand(SqlConnection connection)
{
return newSqlCommand("spGetEmployee", connection);
}
Уже лучше, но можно исправлять и дальше. Мы хотим полностью инкапсулировать повторяемый метод с одним шагом в нашем процессе. Нужно передать хранящееся имя процедуры, чтобы получить более общий метод BuildCommand(), так что преобразуем хранимую процедуру в параметр.
private static SqlCommand BuildCommand(String cmdText, SqlConnection connection)
{
return newSqlCommand(cmdText, connection);
}
Также изменим наш исходный метод:
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee", connection))
{
command.CommandType = CommandType.StoredProcedure;
//-- продолжение кода --
Лучше… но недостаточно. CommandType можно воспринимать как часть построения команды, так что его лучше перенести в метод-строитель и сделать доступным в качестве параметра.
private static SqlCommand BuildCommand(String cmdText, CommandType cmdType,SqlConnection connection)
{
SqlCommand cmd =new SqlCommand(cmdText, connection);
cmd.CommandType = cmdType;
return cmd;
}
Теперь наш код вызова гораздо легче прочитать, потому что BuildCommand() делает всё необходимое для построения объекта SqlCommand.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
{
// попытка открыть подключение
try
{
//--продолжение кода---
Пока мы здесь… Если мы знаем, что в какой-то момент нам могут понадобиться параметры, мы можем заранее внести ещё одно изменение в метод.
private static SqlCommand BuildCommand(String pCommandText, CommandType pCommandType,SqlConnection pSqlConnection,params SqlParameter[] pSqlParameters)
{
SqlCommand cmd =new SqlCommand(pCommandText, pSqlConnection);
cmd.CommandType = pCommandType;
if (null != pSqlParameters && pSqlParameters.Length > 0)
cmd.Parameters.AddRange(pSqlParameters);
return cmd;
}
Теперь у нас есть хорошо повторяемый и лёгкий в понимании метод-строитель для любого объекта SqlCommand с параметрами.
Следующий объект, который мы инстанцируем — это SqlReader. Пока что инстанцирование нашего reader состоит из открытия подключения к БД и выполнения команды. Мы извлечём метод, строящий reader, и переместим этот шаг для безопасного открытия подключения в наш новый метод.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
{
// попытка открыть подключение
try
{
connection.Open();
}
catch (InvalidOperationException ex)
{
// логирование исключения
throw;
}
catch (SqlException ex)
{
// логирование исключения
throw;
}
catch (Exception ex)
{
// логирование исключения
throw;
}
// выполнение ридера и чтение результатов
using(SqlDataReader reader = command.ExecuteReader())
{
Int32 m_NameOrdinal, m_DeptOrdinal;
// получение порядковых номеров
try
{
m_NameOrdinal = reader.GetOrdinal(NAME);
//-- продолжение кода --
Мы выбираем код, который инстанцирует наш ридер, как показано ниже.
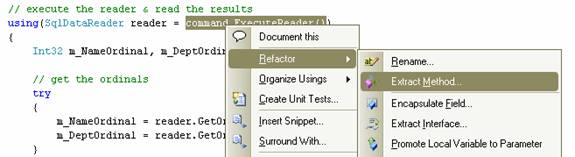
При извлечении метода получаем следующий код:
private static SqlDataReader ExecuteReader(SqlCommand command)
{
return command.ExecuteReader();
}
Но частью выполнения чтения является также открытие соединения, так что добавим подключение в параметры нашего нового метода и перенесём код, открывающий подключение, в новый метод.
Одним из преимуществ такого перепроектирования является то, что теперь мы можем удалить наши вложенные using из кода вызова и сложить их таким образом, что код станет гораздо более читабелен.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
using (SqlDataReader reader = ExecuteReader(command))
{
Int32 m_NameOrdinal, m_DeptOrdinal;
// получение порядковых номеров
try
{
m_NameOrdinal = reader.GetOrdinal(NAME);
m_DeptOrdinal = reader.GetOrdinal(DEPARTMENT);
}
catch (System.IndexOutOfRangeException ex)
{
// логирование исключения
throw;
}
Collection<Employee> result = new Collection<Employee>();
// чтение результатов
while (reader.Read())
{
try
{
Employee emp =new Employee();
emp.Name = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_NameOrdinal);
emp.Department = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_DeptOrdinal);
result.Add(emp);
}
catch (IndexOutOfRangeException ex)
{
// логирование исключения
throw;// перебросить или обработать здесь
}
catch (Exception ex)
{
// логирование общего исключения
throw;// перебросить или обработать здесь
}
}
return result;
}
}
Теперь мы закончили перемещение всего кода инстанцирования в методы-строители, но в коде всё ещё есть путаница, мешающая пониманию. Одним из несоответствий является то, что наш метод содержит код оркестровки и непосредственно выполняет работу, так что на самом деле он совершает больше одного логического шага. Это значит, что у нас всё ещё низкая связность. Оставшийся код в блоке using делает последние три шага нашего процесса из начала статьи:
- чтение результатов;
- получение результирующих порядковых номеров;
- получение значений типа
recordи инстанцирование нового экземпляра объекта.
Сразу видно, что этот процесс, скорее всего, будет повторяться снова и снова. Я уверен, что мы думаем об одном и том же — об инкапсуляции.
Возьмём код из нашего главного метода и перебросим его в отдельный, как мы делали при создании методов-строителей, чтобы код мог считаться связным.
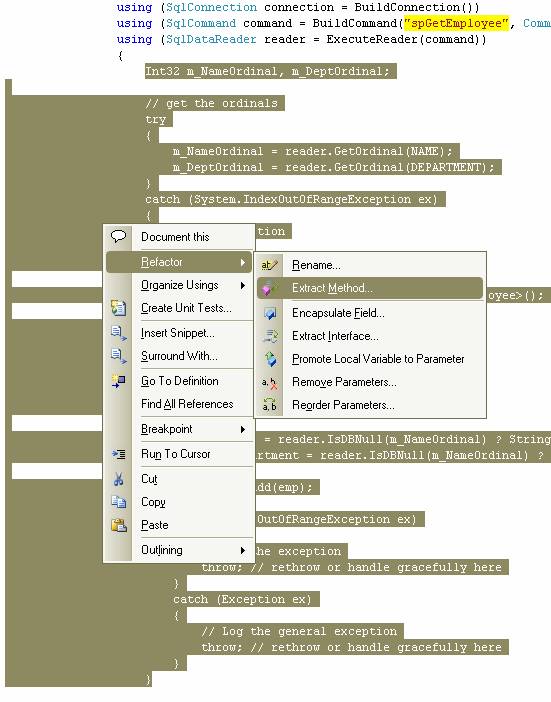
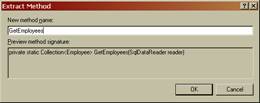
Назовём наш новый метод GetEmployees.
Теперь наш главный метод выглядит прекрасно. Его легко прочесть, и мы или другие разработчики не лишимся зрения в попытках просмотреть его.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
using (SqlDataReader reader = ExecuteReader(command))
{
return GetEmployees(reader);
}
}
Теперь, когда мы убрали небольшой беспорядок, пройдёмся сначала и почистим наш код.
private static Collection<Employee> GetEmployees(SqlDataReader reader)
{
Int32 m_NameOrdinal, m_DeptOrdinal;
// получение порядковых номеров
try
{
m_NameOrdinal = reader.GetOrdinal(NAME);
m_DeptOrdinal = reader.GetOrdinal(DEPARTMENT);
}
catch (System.IndexOutOfRangeException ex)
{
// логирование исключения
throw;
}
Collection<Employee> result = new Collection<Employee>();
// чтение результатов
while (reader.Read())
{
try
{
Employee emp =new Employee();
emp.Name = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_NameOrdinal);
emp.Department = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_DeptOrdinal);
result.Add(emp);
}
catch (IndexOutOfRangeException ex)
{
// логирование исключения
throw;// перебросить или обработать здесь
}
catch (Exception ex)
{
// логирование общего исключения
throw;// перебросить или обработать здесь
}
}
return result;
}
Этот рефакторинг будет чуть сложнее, потому что теперь мы не можем просто выделить части логики в отдельные методы. Взглянем на факторинг нашего кода в объект EmployeeFactory, который будет отвечать за инстанцирование Employees, но теперь используем объект фабрики вместо метода-строителя. Создадим фабричный объект и перенесём весь наш код.
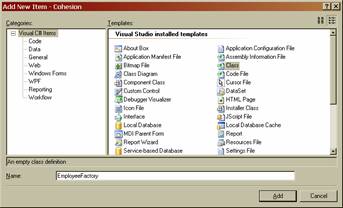
При этом у нас есть возможность изменить наш код до более абстрактной версии SqlDataReader (IDataReader). Когда такие возможности предоставляются, стоит ими воспользоваться, потому что важный фактор, определяющий гибкость кода, — это слабость связанности (loose coupling) классов. Наш код связан слабее, когда мы пользуемся абстракциями, что всегда хорошо, не считая случаев, когда нам нужен определённый функционал конкретного класса.
public class EmployeeFactory
{
private static Collection<Employee> GetEmployees(IDataReader reader)
{
Int32 m_NameOrdinal, m_DeptOrdinal;
// получение порядковых номеров
try
{
m_NameOrdinal = reader.GetOrdinal(NAME);
m_DeptOrdinal = reader.GetOrdinal(DEPARTMENT);
}
catch (System.IndexOutOfRangeException ex)
{
// логирование исключения
throw;
}
Collection<Employee> result = new Collection<Employee>();
// чтение резульатов
while (reader.Read())
{
try
{
Employee emp = new Employee();
emp.Name = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_NameOrdinal);
emp.Department = reader.IsDBNull(m_NameOrdinal) ?String.Empty : reader.GetString(m_DeptOrdinal);
result.Add(emp);
}
catch (IndexOutOfRangeException ex)
{
// логирование исключения
throw;// перебросить или обработать здесь
}
catch (Exception ex)
{
// логирование общего исключения
throw;// перебросить или обработать здесь
}
}
return result;
}
}
Теперь нам надо обновить код вызова, чтобы инстанцировать нашу фабрику и вызвать метод-строитель.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
using (SqlDataReader reader = ExecuteReader(command))
{
return new EmployeeFactory().GetEmployees(reader);
}
}
Здесь я бы хотел заметить, что в конце каждого рефакторинга мы должны убедиться, что наш проект собирается и все наши модульные тесты успешны.
Теперь взглянем на рефакторинг нашей фабрики в более универсальный, повторяемый класс, который будет отвечать за мапирование любого типа объектов передачи данных. Для начала, посмотрим на то, что нам нужно, с менее сфокусированной на реализации точки зрения. Структурирование нашего кода в логические группы и затем реализация каждой из них делает код гораздо более читабельным, что является ключом к сопровождаемости.
class Factory<T>
{
public IEnumerable<T> Map(IDataReader reader)
{
return ReadAll(reader);
}
}
По сути, нам надо выполнить reader и промапировать результаты. Можно ли это сделать в обобщённой манере, которая будет применима ко всем методам? Конечно. Получение порядковых номеров и инстанцирование объекта будут разными для каждого типа, производимого фабрикой, так что напишем для этого заглушки и получим очертание повторно используемого метода-строителя (ниже).
public IEnumerable<T> ReadAll(IDataReader reader)
{
if (null == reader)
return new T[0];
GetOrdinals(reader);
Collection<T> result =new Collection<T>();
while (reader.Read())
{
T item = Build(reader);
if (null != item)
result.Add(item);
}
return result;
}
Сделаем нашу фабрику абстрактной с помощью двух абстрактных методов, которые будут зависимы от типа для каждой фабрики.
abstract class Factory<T>
{
public IEnumerable<T> Map(IDataReader reader)
{
return ReadAll(reader);
}
protected abstract T Build(IDataRecord record);
protected abstract void GetOrdinals(IDataReader reader);
public IEnumerable<T> ReadAll(IDataReader reader)
{
if (null == reader)
returnnew T[0];
GetOrdinals(reader);
Collection<T> result =new Collection<T>();
while (reader.Read())
{
T item = Build(reader);
if (null != item)
result.Add(item);
}
return result;
}
}
Теперь сделаем наш EmployeeFactory суперклассом Factory<T>, который будет заниматься мапированием employee. Заметим, что после нашего рефакторинга каждый объект имеет единственное назначение, то есть получается код с высокой связностью.
class EmployeeFactory:Factory<Employee>
{
private static readonlyString
NAME = "Name",
DEPARTMENT = "Dept";
private Int32
m_NameOrdinal,
m_DeptOrdinal;
protected override Employee Build(IDataRecord record)
{
try
{
Employee emp =new Employee();
emp.Name = record.IsDBNull(m_NameOrdinal) ?String.Empty : record.GetString(m_NameOrdinal);
emp.Department = record.IsDBNull(m_NameOrdinal) ?String.Empty : record.GetString(m_DeptOrdinal);
return emp;
}
catch (IndexOutOfRangeException ex)
{
// логирование исключения
throw;// перебросить или обработать здесь
}
catch (Exception ex)
{
// логирование общего исключения
throw;// перебросить или обработать здесь
}
}
protected override void GetOrdinals(IDataReader reader)
{
try
{
m_NameOrdinal = reader.GetOrdinal(NAME);
m_DeptOrdinal = reader.GetOrdinal(DEPARTMENT);
}
catch (System.IndexOutOfRangeException ex)
{
// логирование исключения
throw;
}
}
}
Осталось доделать пару вещей… хотя это и не обязательно, учитывая, что наше решение содержит лишь один объект передачи данных, мы знаем, что в конце концов там будет набор объектов различных типов, которые надо будет промапировать. Лучше будет построить фабрику для всех мапперов, что нам потребуются, и снова подумать о том, чтобы перенести обязанности инстанцирования на методы-строители. Мы можем инкапсулировать всю начинку мапирования наших объектов в фабрику и сделать её скрытой, так что общее число классов, доступных нашему проекту, будет меньше. Это значит, что надо будет копаться в меньшем количестве классов, и проект будет чуть легче поддерживать. Когда появятся новые маппинги, мы просто построим новые методы, строящие мапперы, и сможем для каждого повторно использовать абстрактный класс Mapper<>. Конечно, можно ещё больше уйти в абстракцию (создать абстрактную фабрику), но этого шага пока достаточно. Но стоит помнить, что в будущем может понадобиться дальнейший рефакторинг.
internal class MapperFactory
{
#region Methods
internal Mapper<Employee> BuildEmployeeMapper()
{
return new EmployeeMapper();
}
#endregion
#region Private Members
private class EmployeeMapper :Mapper<Employee>
{
#region Member Variables
privateInt32
m_NameOrdinal,
m_DeptOrdinal;
private const String
NAME = "Name",
DEPARTMENT = "Dept";
#endregion
protected override void GetOrdinals(IDataReader reader)
{
m_NameOrdinal = reader.GetOrdinal(NAME);
m_DeptOrdinal = reader.GetOrdinal(DEPARTMENT);
}
protected override Employee Build(IDataRecord record)
{
try
{
Employee item =new Employee();
item.Name = record.IsDBNull(m_NameOrdinal) ?String.Empty : record.GetString(m_NameOrdinal);
item.Department = record.IsDBNull(m_NameOrdinal) ?String.Empty : record.GetString(m_DeptOrdinal);
return item;
}
catch (IndexOutOfRangeException ex)
{
// логирование исключения
throw;// перебросить или обработать здесь
}
catch (Exception ex)
{
// логирование общего исключения
throw;// перебросить или обработать здесь
}
}
}
#endregion
}
И вот мы, наконец, имеем гораздо более связное решение, а наши методы хорошо читабельны.
public IEnumerable<Employee> GetEmployeesFromDb_LowCohesion()
{
using (SqlConnection connection = BuildConnection())
using (SqlCommand command = BuildCommand("spGetEmployee",CommandType.StoredProcedure, connection))
using (SqlDataReader reader = ExecuteReader(command))
{
return new MapperFactory()
.BuildEmployeeMapper()
.ReadAll(reader);
}
}
Надеюсь, вам понравилось проходить вместе со мной через эти рефакторинги. Конечно, код никогда не идеален, и для почти каждой строки кода можно найти компромисс. Поддержание связности всегда выгодно с точки зрения читабельности, повторного использования, слабой связанности и сопровождаемости (если методы нормально названы), поэтому связность (или Принцип Единственной Ответственности) определённо стоит учитывать при написании нового кода или рефакторинге старого.
Комментарии