

Puppeteer: не просто очередная библиотека для парсинга
Puppeteer – это библиотека Node.js, поддерживаемая командой Chrome Devtools. Библиотека запускает экземпляр Chrome/Chromium и предоставляет набор высокоуровневых API.
Puppeteer используется для выполнения множества различных задач:
- автоматизация сбора данных с веб-сайтов;
- создание скриншотов и PDF-файлов;
- тестирование расширений Chrome;
- автоматизация тестирования веб-интерфейсов;
- диагностика проблем производительности с помощью таких методов, как захват временной шкалы трассировки веб-сайта.
В сравнении с Selenium библиотека Puppeteer не обладает кросс-браузерностью, но часто выигрывает в скорости, так как не имеет промежуточного звена в виде Selenium server – команды идут напрямую в браузер.
В этой статье мы рассмотрим пример сбора данных с одной из страниц Amazon со списком товаров. Извлечем информацию из страницы списка лучших рубашек, поместим в JSON и посмотрим, как эмулировать действия пользователя (поиск товара). Полный код проекта доступен в репозитории.
Установка Puppeteer и навигация
Puppeteer без проблем устанавливается с помощью npm:
npm install --save puppeteer
Создадим экземпляр браузера и страницы, перейдем к целевому URL-адресу:
const puppeteer = require('puppeteer');
const url = 'https://www.amazon.in/s?k=Shirts&ref=nb_sb_noss_2';
async function fetchProductList(url) {
const browser = await puppeteer.launch({
headless: true, // false: enables one to view the Chrome instance in action
defaultViewport: null, // (optional) useful only in non-headless mode
});
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'networkidle2' });
...
}
fetchProductList(url);
Назначение экземпляров интуитивно понятно:
browser: запускает экземпляр Chrome при вызовеpuppeteer.launch. Простая эмуляция браузера.page: напоминает одну вкладку в браузере Chrome. Предоставляет набор методов, которые можно применить к конкретному экземпляру страницы/ Вызывается при запускеbrowser.newPage. Как в браузере можно создать несколько вкладок, так в Puppeteer можно одновременно обрабатывать несколько экземпляров страниц.
В качестве значения параметра waitUntil используем networkidle2 . Это гарантирует, что состояние загрузки страницы считается
окончательным, если она имеет не более 2 подключений, работающих в течение не
менее 500 мс.
Собираем данные со страницы
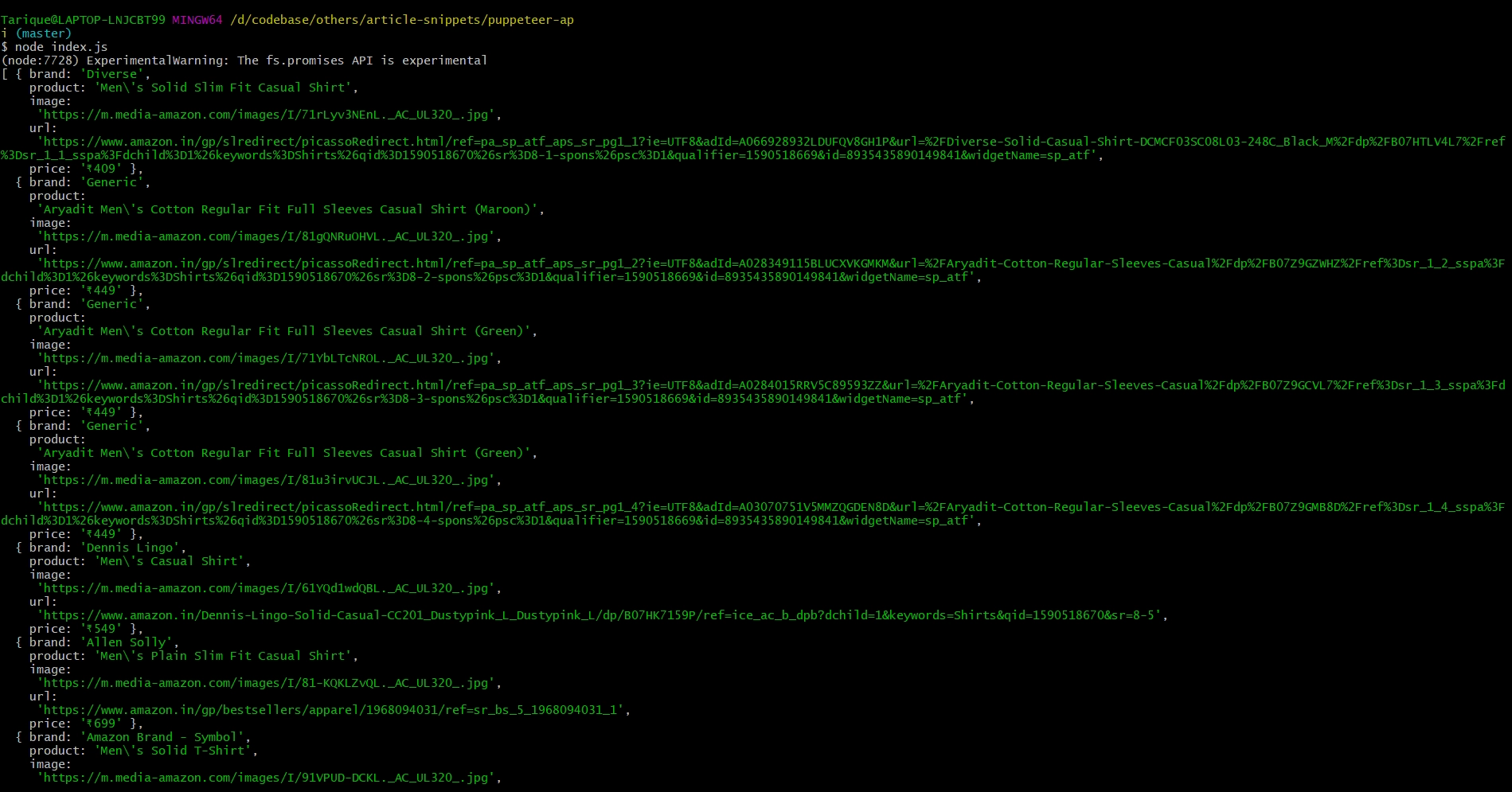
Выясним, какие данные необходимо извлечь. Нас интересует бренд, название продукта, ссылки на продукт и его изображение, и, наконец, стоимость:
{
brand: 'Brand Name',
product: 'Product Name',
url: 'https://www.amazon.in/url.of.product.com/',
image: 'https://www.amazon.in/image.jpg',
price: '₹599',
}
Для запроса DOM используем метод page.evaluate() . Для обхода DOM – обычные методы JavaScript document.querySelector и document.querySelectorAll.
async function fetchProductList(url) {
...
await page.waitFor('div[data-cel-widget^="search_result_"]');
const result = await page.evaluate(() => {
// counts total number of products
let totalSearchResults = Array.from(document.querySelectorAll('div[data-cel-widget^="search_result_"]')).length;
let productsList = [];
for (let i = 1; i < totalSearchResults - 1; i++) {
let product = {
brand: '',
product: '',
};
let onlyProduct = false;
let emptyProductMeta = false;
// traverse for brand and product names
let productNodes = Array.from(document.querySelectorAll(`div[data-cel-widget="search_result_${i}"] .a-size-base-plus.a-color-base`));
if (productNodes.length === 0) {
// traverse for brand and product names
// (in case previous traversal returned empty elements)
productNodes = Array.from(document.querySelectorAll(`div[data-cel-widget="search_result_${i}"] .a-size-medium.a-color-base.a-text-normal`));
productNodes.length > 0 ? onlyProduct = true : emptyProductMeta = true;
}
let productsDetails = productNodes.map(el => el.innerText);
if (!emptyProductMeta) {
product.brand = onlyProduct ? '' : productsDetails[0];
product.product = onlyProduct ? productsDetails[0] : productsDetails[1];
}
// traverse for product image
let rawImage = document.querySelector(`div[data-cel-widget="search_result_${i}"] .s-image`);
product.image =rawImage ? rawImage.src : '';
// traverse for product url
let rawUrl = document.querySelector(`div[data-cel-widget="search_result_${i}"] a[target="_blank"].a-link-normal`);
product.url = rawUrl ? rawUrl.href : '';
// traverse for product price
let rawPrice = document.querySelector(`div[data-cel-widget="search_result_${i}"] span.a-offscreen`);
product.price = rawPrice ? rawPrice.innerText : '';
if (typeof product.product !== 'undefined') {
!product.product.trim() ? null : productsList = productsList.concat(product);
}
}
return productsList;
});
...
}
...
После изучения DOM стало ясно, что каждый
перечисленный элемент выводится с селектором div[data-cel-widget^="search_result_"].
Данный селектор ищет все теги div с атрибутом data-cel-widget, которые имеют
значение, начинающееся с search_result_. Аналогичным образом исключаем
селекторы со следующими параметрами:
- total listed items:
div[data-cel-widget^="search_result_"] - brand:
div[data-cel-widget="search_result_${i}"] .a-size-base-plus.a-color-base(i обозначает номер узла вtotal listed items) - product:
div[data-cel-widget="search_result_${i}"] .a-size-base-plus.a-color-baseилиdiv[data-cel-widget="search_result_${i}"] .a-size-medium.a-color-base.a-text-normal - url:
div[data-cel-widget="search_result_${i}"] a[target="_blank"].a-link-normal - image:
div[data-cel-widget="search_result_${i}"] .s-image - price:
div[data-cel-widget="search_result_${i}"] span.a-offscreen
Примечание:
мы ожидаем доступа к селектору именованных элементов div
[data-cel-widget^="search_result_"] с помощью метода page.waitFor.
При запуске метода page.evaluate мы увидим в логе необходимые данные:
Имитируем поведение пользователя

Теперь мы можем перейти на страницу, извлечь необходимые данные и преобразовать их в понятную для нашего API форму.
Но что если, прежде чем извлечь данные, мы должны перейти по нескольким URL? Puppeteer умеет имитировать поведение юзера. Перейдем на домашнюю страницу amazon.in и найдем рубашки. Это приведет нас к странице списка продуктов, а оттуда мы сможем извлечь необходимые данные из DOM. Взглянем на код:
...
async function fetchProductList(url, searchTerm) {
...
await page.goto(url, { waitUntil: 'networkidle2' });
await page.waitFor('input[name="field-keywords"]');
await page.evaluate(val => document.querySelector('input[name="field-keywords"]').value = val, searchTerm);
await page.click('div.nav-search-submit.nav-sprite');
...
}
fetchProductList('https://amazon.in', 'Shirts');
Ждем, пока поле поиска будет доступно, а затем
добавляем searchTerm, переданный с помощью page.evaluate. Переходим на страницу
списка продуктов, эмулируя щелчок по кнопке поиска – получаем желанное.
Некоторые нюансы в работе
Есть несколько моментов, с которыми вы можете столкнуться во время работы.
- Некоторые ресурсы могут заблокировать доступ, если заподозрят странную активность. Для рандомизации user-agent в браузере используйте пакет
user-agents:
const puppeteer = require('puppeteer');
const userAgent = require('user-agents');
...
const browser = await puppeteer.launch({ headless: true, defaultViewport: null });
const page = await browser.newPage();
await page.setUserAgent(userAgent.toString());
...
- Puppeteer не идеален в вопросе производительности. Повысить эффективность можно за счет троттлинга анимации, ограничения сетевых вызовов и т. д.
- Не забывайте завершать сеанс Puppeteer, закрывая экземпляр браузера с помощью
browser.close. - Некоторые распространенные операции, такие как
console.log()не будут работать внутри методов страницы. Контекст страницы/браузера отличается от контекста ноды, в которой работает приложение.
Собираем всё вместе
Автоматизируем навигацию на странице со списком продуктов.
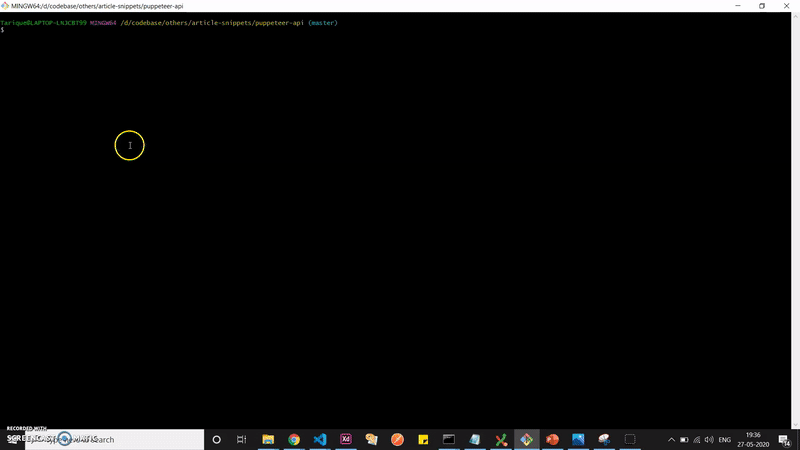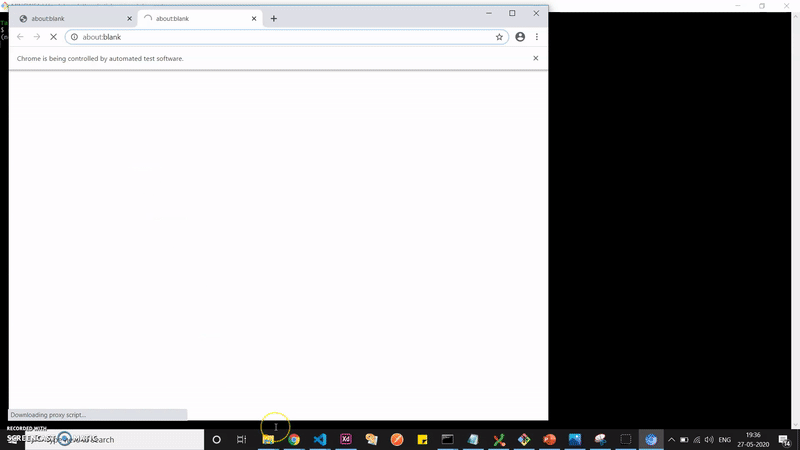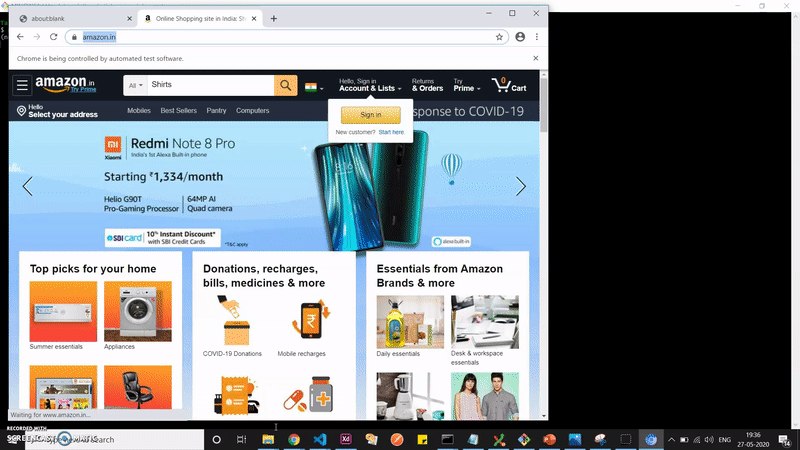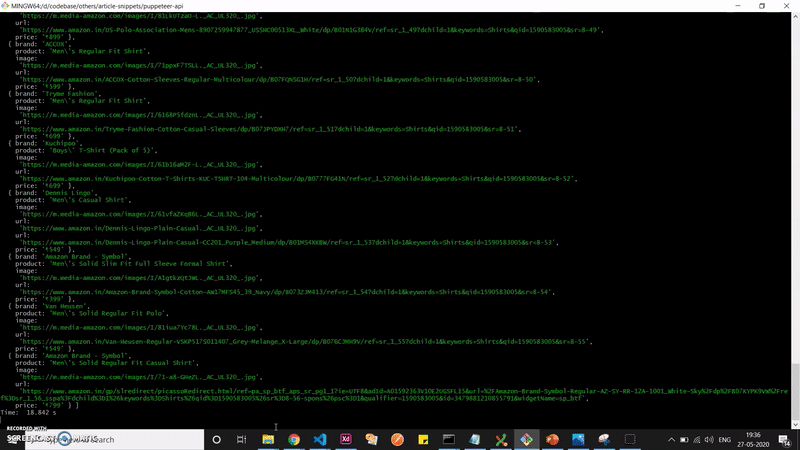
Теперь у вас есть собственный и настраиваемый API для сбора данных. Остается лишь подключить это все к серверной платформе.
Заключение
Мы рассмотрели всего лишь один конкретный случай использования Puppeteer. Для лучшего понимания возможностей инструмента рекомендуем потратить некоторое время на ознакомление с официальной документацией. Многое о библиотеке можно понять из оглавления, содержащего перечень классов и методов.
Комментарии