
Многие начинающие разработчики с пренебрежением относятся к книгам и курсам по алгоритмам и структурам данным: думают, что это теория, с которой вряд ли придется столкнуться на практике. Однако хорошее понимание концепций, на которых основаны «теоретические» структуры данных, помогает правильно реализовать самую сложную логику, используя встроенные, конкретные структуры того или иного инструмента – языка, фреймворка, библиотеки. Автор этой публикации показал, как и для чего можно использовать структуры данных при разработке на React.
Массив
Массивы используются практически везде в React-приложениях:
- Они необходимы для хранения и обработки данных.
- Играют ключевую роль в управлении состоянием приложения.
Для новичков, только приступающих к изучению JavaScript в целом и React конкретно, важно хорошо разобраться в массивах, поскольку структуры на их основе определяют состояние компонентов. Самыми важными методами массивов при работе в React можно назвать .map() и .filter():
.map()используется для преобразования массива данных в список элементов..filter()помогает изменять и фильтровать данные перед их отображением.
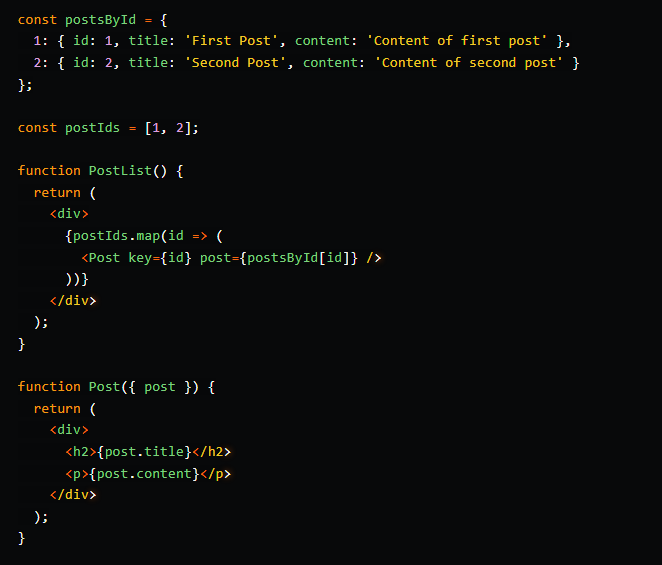
Объект и хэш-таблица
При работе с большими коллекциями сущностей (например, пользователями или товарами), нормализация данных с помощью объектов (хэш-таблиц) помогает повысить эффективность операций чтения и обновления – вместо манипуляций с глубоко вложенной структурой можно обращаться к сущностям по их идентификаторам (id):
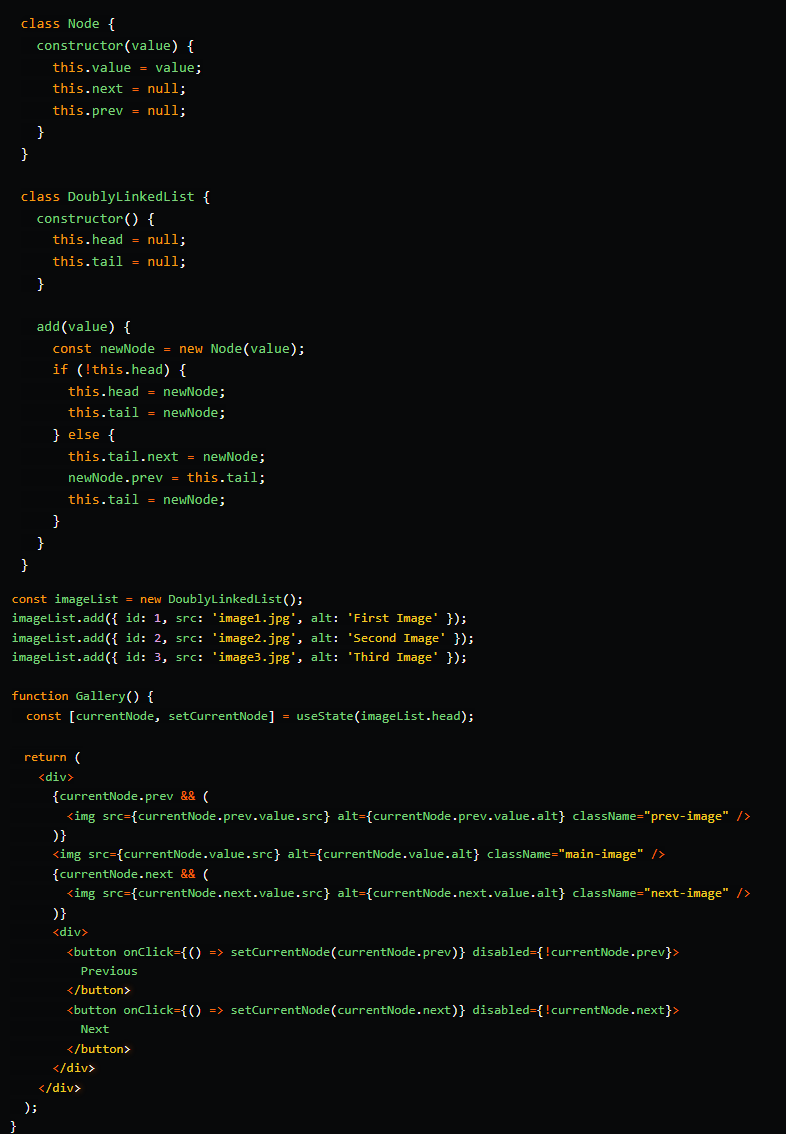
Двусвязный список
Двусвязные списки удобно использовать при реализации навигации по связанным элементам. Предположим, вам нужно создать фотогалерею, где каждое изображение выводится в окружении предыдущего и последующего изображений. Двусвязный список позволяет хранить текущий узел непосредственно в состоянии компонента – вместо использования индекса. В этом примере текущий узел хранится в состоянии компонента, и интерфейс обновляется в зависимости от наличия предыдущего или следующего узла. Кнопки позволяют пользователям перемещаться по списку вперед и назад, и становятся неактивными, если достигнут конец списка. Такую структуру можно использовать в каруселях, медиагалереях или плейлистах:
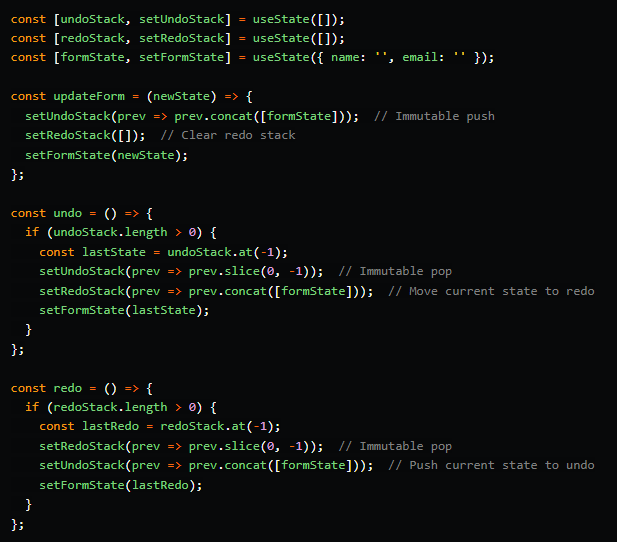
Стек
Стеки позволяют эффективно управлять операциями отмены/повтора, используя логику LIFO (последним пришел – первым ушел). Операции добавления и удаления элементов из стека выполняются за O(1), что делает этот подход максимально быстрым. Применяя неизменяемые методы (concat, slice), можно гарантировать, что состояние останется неизменным:
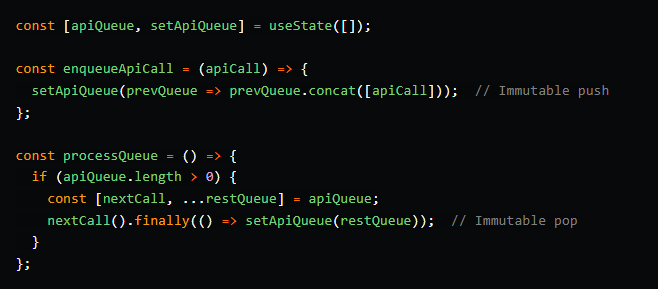
Очередь
Очередь работает по принципу FIFO (первым пришел – первым ушел). Это похоже на обычную очередь в магазине: кто первым встал в очередь, тот первым и обслуживается. Очереди отлично подходят для обеспечения правильного порядка выполнения определенных задач, таких как API-вызовы или отправка уведомлений. Они гарантируют, что задачи будут обработаны в том порядке, в котором они были добавлены:
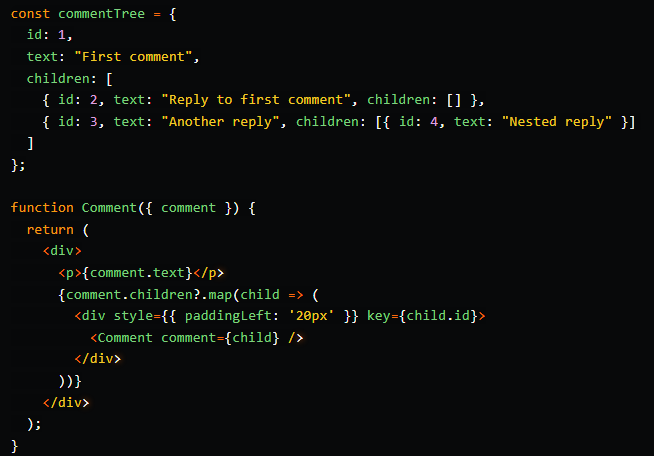
Дерево
Деревья – иерархические структуры данных, которые часто используются в React при работе с вложенными компонентами. С помощью деревьев удобно представлять, например, ветки комментариев, структуру папок, меню с подпунктами и т. д:
Граф
Графы состоят из узлов (вершин) и связей между ними (ребер). Они отлично подходят для моделирования сложных взаимосвязей между объектами.
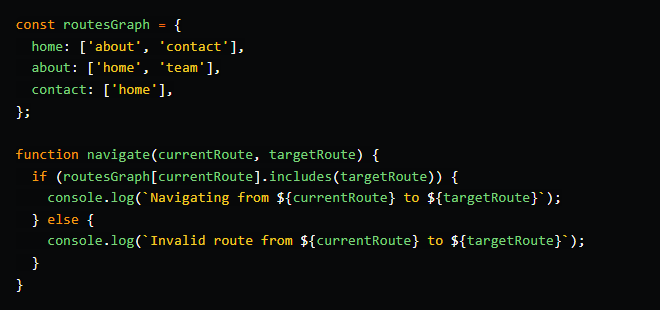
Пример 1: Маршрутизация между несколькими представлениями
В этом примере мы используем граф для представления возможных путей навигации между страницами в одностраничном приложении (SPA):
Пример 2: Моделирование отношений пользователей
Здесь мы используем граф для моделирования социальных связей между пользователями:

Расскажите о случае, когда правильно выбранная структура данных помогла вам решить сложную задачу в React-проекте.
Хочу знать больше
Хотите углубить свои знания в веб-разработке и алгоритмах? Наши курсы «Frontend Basic» и «Алгоритмы и структуры данных» предоставляют практические навыки и фундаментальные знания, необходимые для создания эффективных и оптимизированных веб-приложений.
Комментарии