
Говоря о БД, нельзя не вспомнить о языке SQL, СУБД и запросах, непонятных на первый взгляд. После нашей статьи вы освоите основы SQL.
В нашей работе мы будем использовать:
- СУБД (SQLite, MySQL и PostgreSQL)
- Терминал (может быть любой: cmd, conemu, git-bash)
- Notepad++
- Любая IDE
Notepad++ нам понадобится только для удобного ввода и хранения необходимых данных, а IDE – для понимания работы с SQL через другие языки программирования (в примерах используется Java). Основная часть работы будет выполняться через терминал.
Пара слов о языке SQL
Это не тот язык, который придется осваивать годами. В SQL используются довольно простые читабельные запросы, которые легко выучить и понять. К базам данных можно обращаться как посредством программного кода, так и через терминал.
Вот пример работы с БД в Java:
public class DbManager {
public static Connection connection;
public static PreparedStatement ps;
public static ResultSet resultSet;
/** Подключение к БД */
public static Connection getConnection() throws ClassNotFoundException, SQLException {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/location",
"root", "root");
System.out.println("Установлено соединение с БД.");
return connection;
}
/** Создание таблицы */
public static void createTable() throws Exception {
try {
connection = getConnection();
ps = connection.prepareStatement("CREATE TABLE IF NOT EXISTS" +
"chatbot(id INT PRIMARY KEY AUTO_INCREMENT," +
"our_key VARCHAR(255), our_value VARCHAR(255))");
ps.executeUpdate();
} catch (Exception e){
System.out.println(e);
}
finally {
System.out.println("Создание таблицы завершено.");
}
}
/** Добавление в таблицу информации */
public static void postTable() throws Exception {
String hello_key = "привет";
String hello_value = "hello";
try {
connection = getConnection();
ps = connection.prepareStatement("INSERT INTO chatbot(our_key, our_value)" +
"VALUES ('"+hello_key+"','"+hello_value+"')");
ps.executeUpdate();
} catch (Exception e){
System.out.println(e);
} finally {
System.out.println("Таблица заполнена.");
}
}
/** Выбор и вывод данных */
public static ArrayList<String> get() throws Exception {
try {
connection = getConnection();
ps = connection.prepareStatement("SELECT our_key, our_value FROM chatbot");
resultSet = ps.executeQuery();
ArrayList<String> array = new ArrayList<>();
while (resultSet.next()) {
System.out.print(resultSet.getString("our_key"));
System.out.print(" ");
System.out.println(resultSet.getString("our_value"));
array.add(resultSet.getString("our_key"));
array.add(resultSet.getString("our_value"));
}
System.out.println("Все записи выбраны!");
return array;
} catch (Exception e){
System.out.println(e);
}
return null;
}
}
Запросы, которые «обрамлены» двойными кавычками после .prepareStatement, – это и есть SQL. А вот как аналогичные запросы будут выглядеть в терминале:
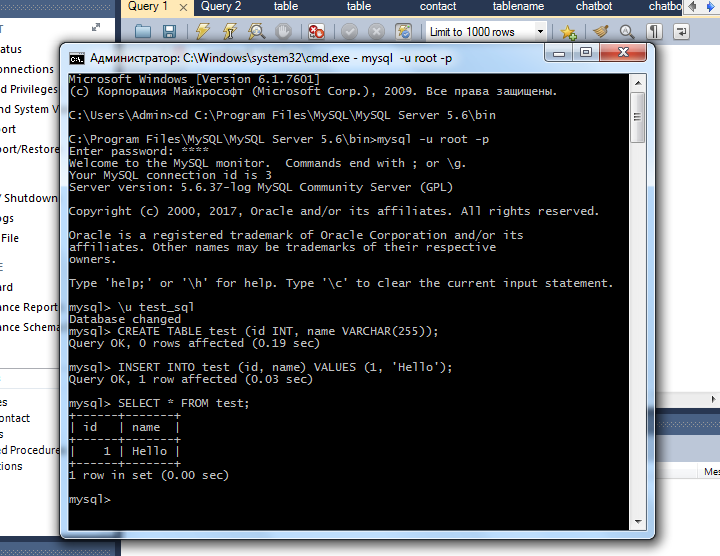
На первый взгляд, слишком сложно, но сейчас мы разберем все по порядку.
Синтаксис SQL
Запросы на SQL – это простая линейная последовательность операторов. В запросах используются:
- зарезервированные ключевые слова;
- идентификаторы для столбцов, таблиц, операций и функций;
- строковые, арифметические и логические выражения для создания условий поиска и вычисления значений ячеек.
Любой оператор начинается с ключевого слова-действия вроде SELECT, CREATE, UPDATE и т. д. В конце обязательно ставится точка с запятой. Оператор может свободно занимать как одну, так и несколько строк. Разделителями логических единиц выступают:
- 1 или несколько пробелов;
- 1 или несколько символов новой строки;
- 1 или несколько символов табуляции.
Комментарии могут помечаться такими способами:
- начиная двойным минусом;
- начиная #;
- между /* и */ (комментарии языка Си).
Подключение к базе данных
В SQLite нет таких понятий, как пользователь или пароль. База данных представлена в виде файла, и если у вас есть доступ к файлу – есть доступ и к базе. Для создания БД и подключения к ней нужно выполнить следующее:
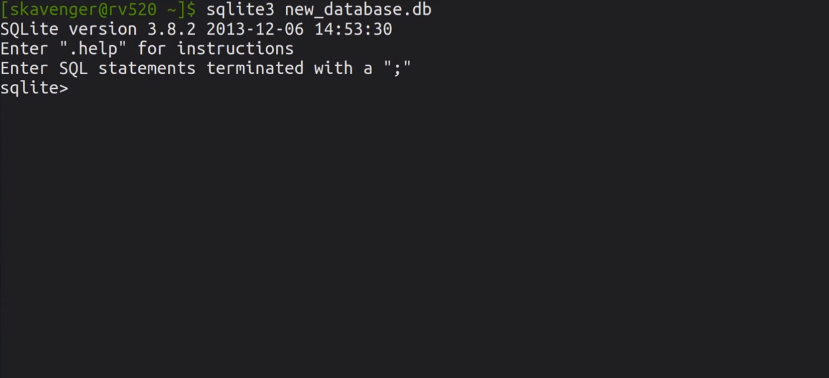
Запомнить абсолютно все команды невозможно, и чтобы просмотреть перечень доступных команд, введите .help.
К MySQL подключиться также несложно, но здесь придется убедиться, что сервер запущен. Для этого перейдите в «Службы» и проверьте состояние:
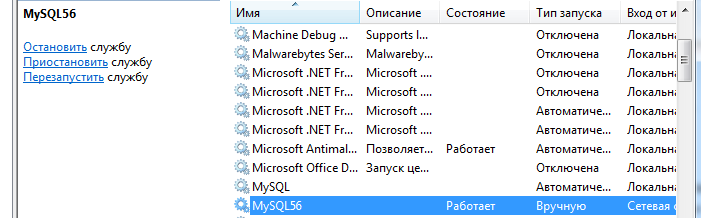
Если сервер запущен, введите mysql -u имя_пользователя -p, где имя_пользователя – это логин, под которым вы зарегистрировались. Пароль можно также написать следом за -p, но после все равно придется вводить его еще раз, а терминал предупредит о том, что пароль нельзя «светить». Зачастую -u и -p – это root и root, но если вы сменили на что-то более сложное, постарайтесь не забыть, так как при работе с MySQL авторизовываться придется часто.
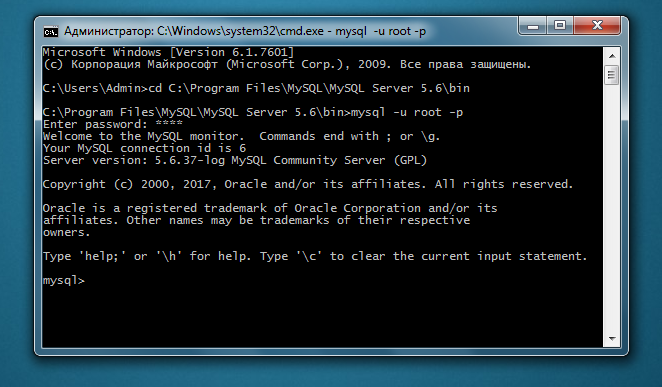
Для вызова списка доступных команд используется help или \h.
Подключаться к Workbench во время работы необязательно, а вот для более удобного визуального представления таблиц можно использовать:
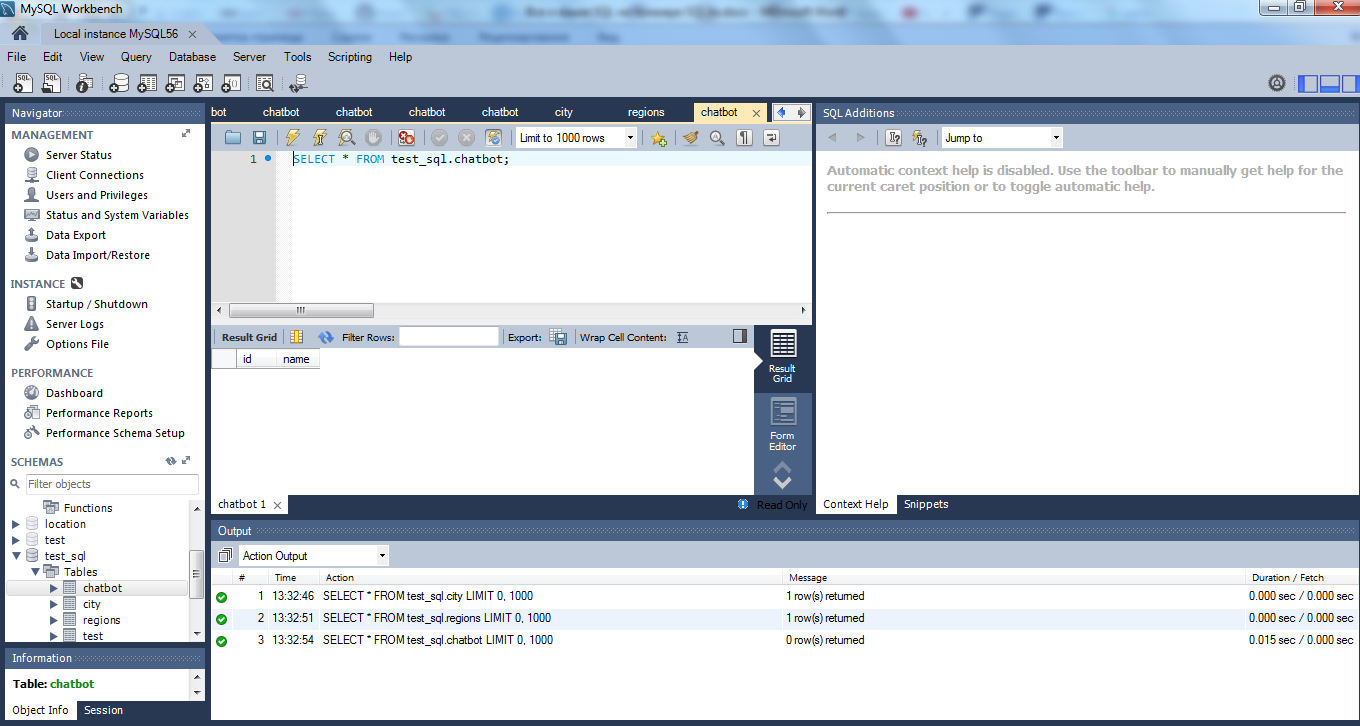
В PostgreSQL все аналогично, только вводится psql -U postgres. Также PostgreSQL можно настроить для быстрой авторизации без пароля:
Список доступных команд выводится по help. В списке содержатся команды программы и SQL-команды (а в языке SQL их немало).
Так подключение к БД выглядит в Java:
/** Подключение к БД */
public static Connection getConnection() throws ClassNotFoundException, SQLException {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/location",
"root", "root");
System.out.println("Установлено соединение с БД.");
return connection;
}
Создание БД и таблицы
К самым распространенным типам данных относятся: INTEGER (он же INT), BIGINT, FLOAT, DOUBLE, BOOLEAN, VARCHAR (до 255 символов), TEXT, LONGTEXT, DATE, DATETIME, TIME, TIMESTAMP. С ними придется столкнуться при создании и редактировании таблиц, так как у каждого столбца будет свой тип данных.
Запросы в SQL очень удобны: это просто английские слова, которые отображают желаемое действие.
Например, создание базы данных, переход в нее и создание таблицы будет выглядеть следующим образом:
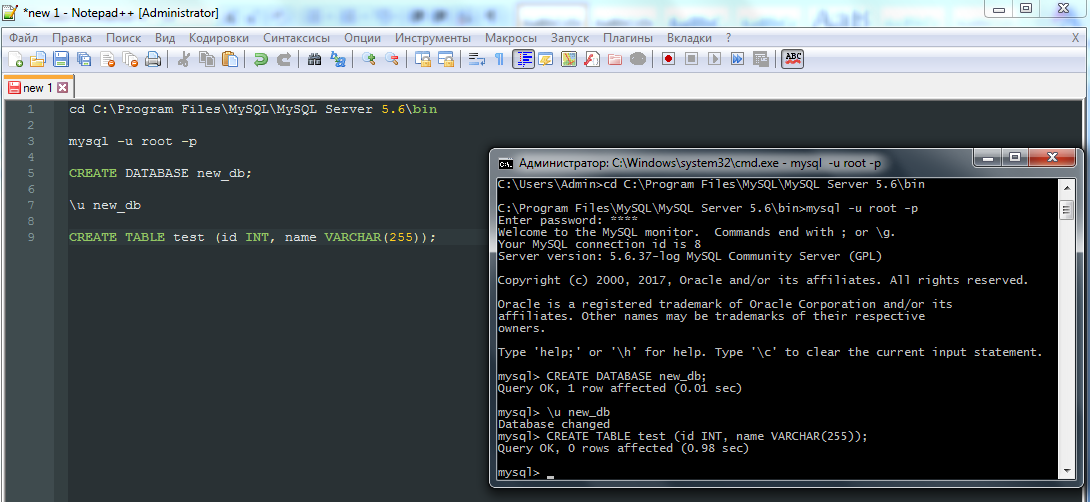
В SQLite просмотреть таблицы можно с помощью команды .tables:

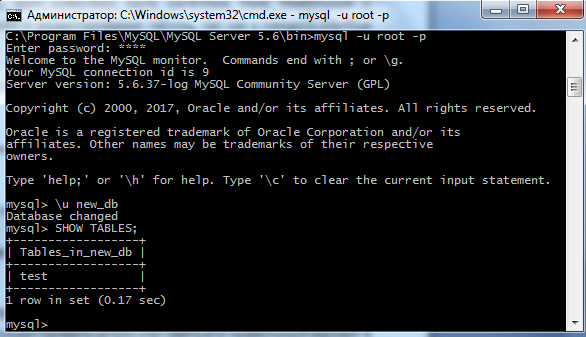
В MySQL это делается при помощи show tables;:
В PostgreSQL – через \d:
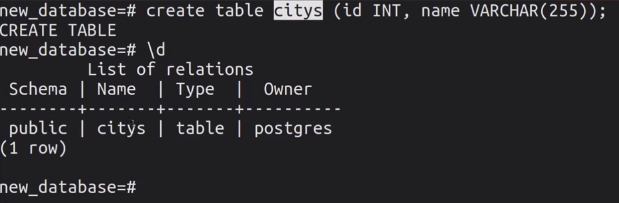
Не поленитесь воспользоваться сперва Notepad++, так как при возникновении ошибки (банальная опечатка) вы сможете своевременно отредактировать запрос и вставить его правильный вариант в терминал.
Вот наши команды в формате кода:
CREATE DATABASE new_db; \u new_db CREATE TABLE test (id INT, name VARCHAR(255));
Так создание таблицы выглядит в Java:
/** Создание таблицы */
public static void createTable() throws Exception {
try {
connection = getConnection();
ps = connection.prepareStatement("CREATE TABLE IF NOT EXISTS" +
"chatbot(id INT PRIMARY KEY AUTO_INCREMENT," +
"our_key VARCHAR(255), our_value VARCHAR(255))");
ps.executeUpdate();
} catch (Exception e){
System.out.println(e);
}
finally {
System.out.println("Создание таблицы завершено.");
}
}
Регистр букв не имеет значения, но если вы работаете с Notepad++ или IDE, для команд лучше использовать прописные буквы: текст будет визуально отделен от остального кода, и вы сможете четко прослеживать начало и конец запросов на языке SQL.
Удаление таблицы и базы данных
В этом случае используются такие команды:
DROP DATABASE databasename; DROP TABLE tabelname;
Если вы запускаете какой-то файл, чтобы не было сбоев, просто напишите проверку на существование таблицы и/или базы данных:
DROP DATABASE IF EXISTS databasename; DROP TABLE IF EXISTS tabelname;
Если вы воспользуетесь командами show databases или show tables, то увидите, что удаление прошло успешно.
Заполнение, редактирование и вывод таблицы
Запросы на языке SQL будут одинаковыми для всех СУБД, поэтому рассмотрим заполнение, редактирование и вывод таблицы на примере MySQL.
Чтобы заполнить таблицу значениями, необходимо помнить типы данных в столбцах, и в соответствии с этими типами заполнять. Допустим, у нас есть таблица test с группами данных id INT PRIMARY KEY (первичный ключ) и name VARCHAR (255) NOT NULL (не нулевое значение: обязательно заполняется). Тогда заполняться эти поля должны следующим образом:
INSERT INTO test (id, name) VALUES (1, 'first_name'); INSERT INTO test (id, name) VALUES (2, 'second_name');
В Java добавление в таблицу информации выглядит так:
/** Добавление в таблицу информации */
public static void postTable() throws Exception {
String hello_key = "привет";
String hello_value = "hello";
try {
connection = getConnection();
ps = connection.prepareStatement("INSERT INTOchatbot(our_key, our_value)" +
"VALUES ('"+hello_key+"','"+hello_value+"')");
ps.executeUpdate();
} catch (Exception e){
System.out.println(e);
} finally {
System.out.println("Таблица заполнена.");
}
}
Если мы установим для id констрейн AUTO_INCREMENT, это поле будет заполняться автоматически, начиная с единицы и далее. В таком случае нам не придется прописывать id: мы просто будем заполнять name.
Для изменения значений используем следующую команду:
UPDATE test SET name = 'New_name';
Так весь столбец name заполнится значениями New_name. Если нам нужно выборочное изменение, оттолкнемся от соседних столбцов и создадим условие:
UPDATE test SET name = 'Another_name' WHERE id = 2;
В данном случае мы поменяем только второе имя.
По тому же принципу мы можем удалять из таблицы данные, как все, так и 1 строку:
DELETE FROM test; DELETE FROM test WHERE id =1;
Выводить данные можно все или какие-то конкретные. В приведенном ниже примере мы выполняем следующие действия:
- Выводим все данные таблицы.
- Выводим только 1 столбец.
- Выводим 1 строку.
- Выводим все строки, идущие после первой.
- Выводим данные по id в возрастающем порядке.
- Выводим данные по id в обратном порядке.
SELECT * FROM test; SELECT name FROM test; SELECT * FROM test WHERE id = 1; SELECT * FROM test WHERE id > 1; SELECT * FROM test ORDER BY id ASC; SELECT * FROM test ORDER BY id DESC;
Чтобы было более наглядно, увеличьте количество данных в таблице и поиграйте с условиями.
Вывод данных в Java выглядит так:
/** Выбор и вывод данных */
public static ArrayList<String> get() throws Exception {
try {
connection = getConnection();
ps = connection.prepareStatement("SELECT our_key, our_value" +
"FROM chatbot");
resultSet = ps.executeQuery();
ArrayList<String> array = new ArrayList<>();
while (resultSet.next()) {
System.out.print(resultSet.getString("our_key"));
System.out.print(" ");
System.out.println(resultSet.getString("our_value"));
array.add(resultSet.getString("our_key"));
array.add(resultSet.getString("our_value"));
}
System.out.println("Все записи выбраны!");
return array;
} catch (Exception e){
System.out.println(e);
}
return null;
}
Мы также можем переименовать поле и сменить его тип:
ALTER TABLE test CHANGE COLUMN name new_name TEXT;
Или просто сменить тип, оставив прежнее имя:
ALTER TABLE test MODIFY name TEXT;
Импорт и экспорт файлов
В языке SQL можно использовать импорт и экспорт (дамп), что значительно упрощает работу. Как это сделать посредством командой строки?
Для SQLite:
.read sqlite.sql
sqlite3 test.sqlite .dump > sqlite_dump.sql
Для MySQL:
mysql -u root -p test < mysql.sql
mysqldump -u root -p test_sql > mysql_dump.sql
Для PostgreSQL:
psql -U postgres -d test -f postgresql.sql
pg_dump -U postgres -d test > postgresql_dump.sql
PRIMARY KEY и FOREIGN KEY
FOREIGN KEY (внешний ключ) необходим для ограничения по ссылкам. Создается прямая связь между значениями двух полей. Поле, которое ссылается на другое, называется внешним ключом, а поле, на которое ссылаются – родительским ключом. Их имена могут быть разными, но тип поля должен соответствовать. Внешний ключ связан с таблицей, на которую он ссылается. Каждое значение внешнего ключа должно ссылаться на одно и то же значение родительского ключа. Если это условие верно, БД пребывает в состоянии ссылочной целостности.
Давайте рассмотрим на примере. Допустим, у нас есть 2 таблицы: регионы и города.
CREATE TABLE regions ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL UNIQUE, active BOOLEAN DEFAULT TRUE ); CREATE TABLE city ( id INTEGER PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL UNIQUE, regions_id INT NOT NULL, active BOOLEAN DEFAULT TRUE, FOREIGN KEY(regions_id) REFERENCES regions(id) );
Примечание: для SQLite вместо AUTO_INCREMENT используется AUTOINCREMENT, а в PostgreSQL – SERIAL.
В regions_id хранится идентификатор региона, и мы делаем его внешним ключом на поле id таблицы regions.
Если таблица регионов пуста, при выполнении следующей команды должна возникнуть ошибка:
INSERT INTO city (name, regions_id) VALUES ('Milano', 1);
Однако запрос успешно выполнится. Это связано с тем, что зачастую в разных СУБД используются специальные команды для включения механизма внешних ключей. Как его включить?
Для SQLite:
PRAGMA FOREIGN_KEYS = ON;
Для MySQL:
ENGINE InnoDB;
В PostgreSQL данный механизм включен по умолчанию.
Чтобы не сталкиваться с ошибками уже существующих таблиц, добавьте в импортируемый файл их удаление:
DROP TABLE IF EXISTS regions; CREATE TABLE regions ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL UNIQUE, active BOOLEAN DEFAULT TRUE ) ENGINE InnoDB; DROP TABLE IF EXISTS city; CREATE TABLE city ( id INTEGER PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL UNIQUE, regions_id INT NOT NULL, active BOOLEAN DEFAULT TRUE, FOREIGN KEY(regions_id) REFERENCES regions(id) ) ENGINE InnoDB;
Наличие родительского ключа будет препятствовать удалению. Для этого используется либо первоочередное удаление таблицы в наследнике, либо такой запрос:
SET FOREIGN_KEY_CHECKS=0;
Вывод нескольких таблиц
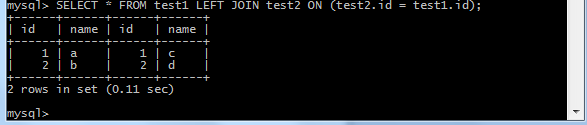
На языке SQL можно вывести сразу несколько таблиц. Создадим в базе данных test две таблицы: test1 и test2. Заполним их значениями, при этом id будут одинаковыми и идти по порядку (можно реализовать с помощью констрейна AUTO_INCREMENT). Чтобы вывести обе таблицы рядом, выполним следующую команду:
SELECT * FROM test1 LEFT JOIN test2 ON (test2.id = test1.id);
Видим:
Итоги
Да, мы затронули лишь базис, но даже с этим базисом вы можете смело вписывать в резюме, что понимаете и умеете работать с БД на языке SQL. Вот только чем более сложные операции необходимо реализовать, тем большим будет различие в реализации для разных СУБД. Так что устраиваясь каким-нибудь Salesforce-разработчиком, просто подтяните знания по каждой из этих систем. Удачи!



Комментарии