

Инженеры и тимлиды должны больше задумываться над быстрым и надежным способом отправки кода в продакшн. Команды и компании, которые одновременно соблюдают два условия, имеют большое преимущество перед конкурентами.
В этой статье мы рассмотрим:
- Крайние случаи при отправке кода в продакшн.
- Типовые процессы в разных компаниях.
- Принципы и инструменты отправки кода в продакшн.
- Дополнительные слои проверки и расширенные инструменты.
- Прагматичные риски для ускорения работы
1. Крайние случаи отправки в продакшн
Когда дело доходит до отправки кода, полезно понимать две крайности того, как код может дойти до пользователей. В таблице ниже показаны thorough-способ и способ YOLO.
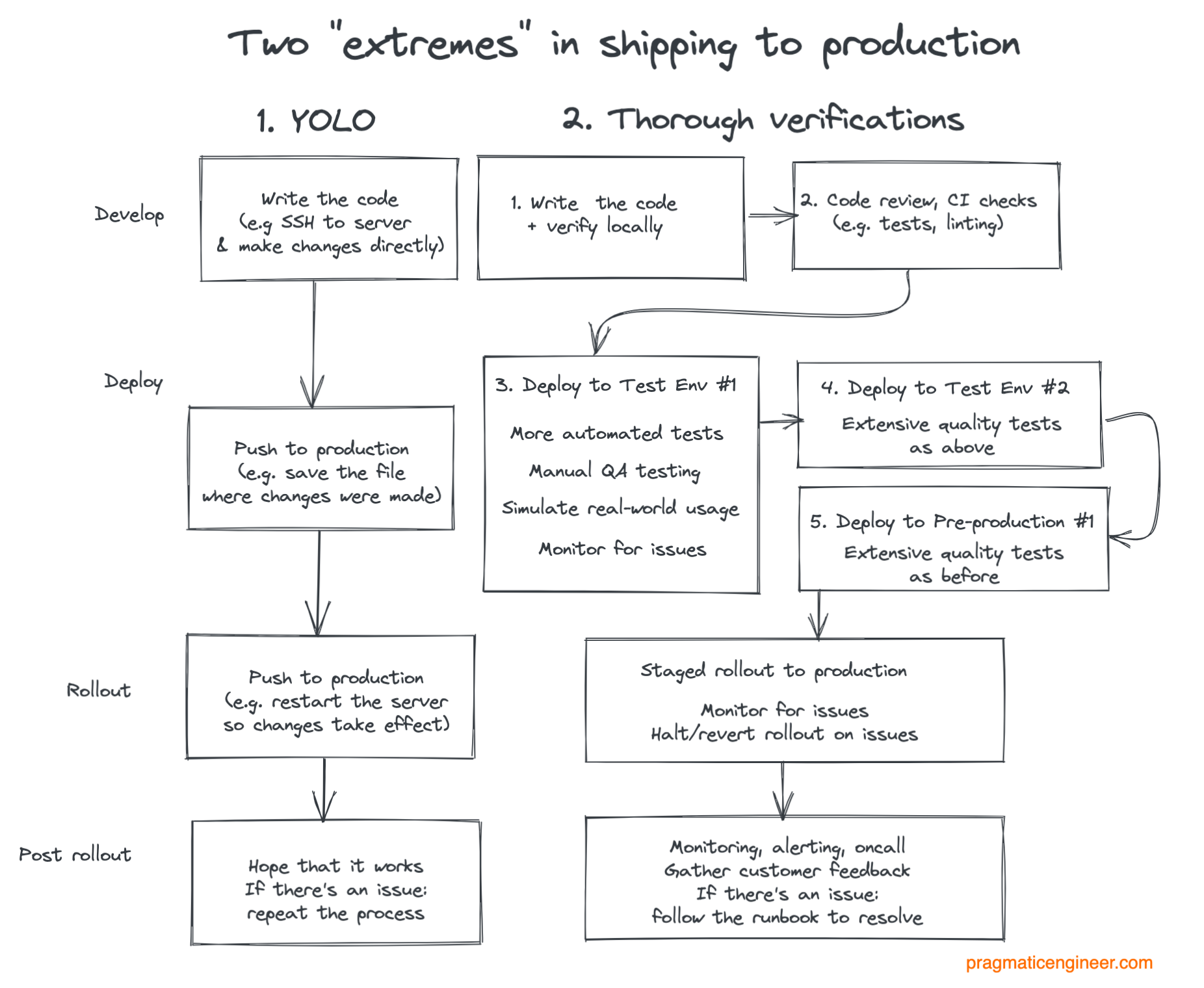
1. Отправка YOLO. YOLO означает: «вы живете только один раз». Этот подход используют при работе с прототипами, сторонними проектами и нестабильными продуктами, такими как альфа- или бета-версии. В некоторых случаях это также влияет на то, как срочные изменения попадают в продакшн.
Идея проста: внесите изменение в продакшн, а затем посмотрите, сработает ли оно — все в продакшне. Примеры отправки YOLO включают:
- SSH на рабочий сервер → откройте редактор (например, vim) → внесите изменения в файл → сохраните файл и/или перезапустите сервер → посмотрите, сработало ли изменение.
- Внесите изменения в файл исходного кода → принудительно внедрите это изменение без проверки кода → отправьте новое развертывание службы.
- Войдите в производственную базу данных → выполните производственный запрос, устраняющий проблему с данными (например, изменение записей, в которых есть проблемы) → надеюсь, что это изменение устранило проблему.
Отправка YOLO осуществляется настолько быстро, насколько это возможно с точки зрения отправки изменений в продакшн. Тем не менее данный способ также имеет наибольшую вероятность появления новых проблем в производстве, поскольку не имеет страховочных сетей. Для продуктов, у которых практически нет пользователей в производственной среде, ущерб, наносимый внесением ошибок в производственную среду, может быть небольшим, поэтому такой подход оправдан.
Релизы YOLO связаны с:
- Побочными проектами.
- Стартапами на ранней стадии без клиентов.
- Средними компаниями с плохой инженерной практикой.
- При разрешении срочных инцидентов в местах без четко определенных практик обработки инцидентов.
По мере того как программный продукт растет и все больше клиентов полагаются на него, изменения в коде должны пройти дополнительную проверку перед поступлением в рабочую среду. Давайте впадем в другую крайность: команда, одержимая идеей сделать все возможное, чтобы практически не было ошибок.
2. Тщательная многоэтапная проверка применяется в работе над продуманным готовым продуктом, который имеет много ценных клиентов, где одна ошибка может вызвать серьезные проблемы. Например, если из-за ошибок клиенты теряют деньги или уходят к конкуренту, можно использовать этот строгий подход.
При таком подходе используются несколько уровней проверки с целью еще более точного моделирования реальной среды. Некоторые слои могут быть:
- Локальная проверка. Инструментарий для разработчиков программного обеспечения для выявления очевидных проблем.
- Проверка CI. Автоматические тесты, например, модульные тесты и линтинг, выполняются при каждом запросе на включение.
- Автоматизация перед развертыванием в тестовой среде. Более дорогие тесты, такие как интеграционные тесты или сквозные тесты, выполняются перед развертыванием в следующей среде.
- Тестовая среда №1. Больше автоматизированного тестирования, например, тесты на общую работоспособность (smoke tests). Инженеры службы технического контроля могут вручную протестировать продукт, выполняя как ручное тестирование, так и исследовательское.
- Тестовая среда №2. Среда, в которой подмножество реальных пользователей, таких как внутренние пользователи компании или платные бета-тестеры, тестируют продукт. Среда соединена с мониторингом, и при признаках регрессии развертывание останавливается.
- Предпродакшн среда №3. Среда, в которой выполняется окончательный набор проверок. Часто это означает запуск еще одного набора автоматических и ручных тестов.
- Поэтапное развертывание. Небольшая группа пользователей получает изменения, а команда следит за тем, чтобы ключевые показатели оставались в рабочем состоянии, и проверяет отзывы клиентов. Стратегия поэтапного развертывания организована с учетом степени риска вносимых изменений.
- Полное развертывание. По мере увеличения поэтапного развертывания в какой-то момент изменения передаются всем клиентам.
- После развертывания. Проблемы возникнут в процессе производства, и команда настроила мониторинг и оповещение, а также цикл обратной связи с клиентами. Если возникает проблема, она решается в соответствии со стандартными процессами. После того как сбой устранен, команда изучает инцидент и использует передовые методы анализа, которые мы рассмотрели ранее.
Такой сложный и долгий процесс релиза можно увидеть:
- В строго регулируемых отраслях, например, в здравоохранении.
- У поставщиков телекоммуникационных услуг, у которых нередко есть примерно 6 месяцев тщательного тестирования изменений, прежде чем отправлять серьезные изменения клиентам.
- В банках, где ошибки могут привести к значительным финансовым потерям.
- В традиционных компаниях с устаревшей кодовой базой, у которых мало автоматизированного тестирования. Тем не менее, эти компании хотят поддерживать высокое качество и довольны тем, что замедляют выпуск релизов, добавляя дополнительные этапы проверки.
2. Типичные процессы в разных типах компаний
Каковы «типичные» способы отправки кода в продакшн в разных типах компаний? Вот моя попытка обобщить эти подходы, основанная на наблюдениях. Ниже приводится обобщение, поскольку не каждая практика компании соответствует этим процессам. Тем не менее, я надеюсь, что это проиллюстрирует некоторые различия в том, как отдельные компании отправляют код в продакшн:
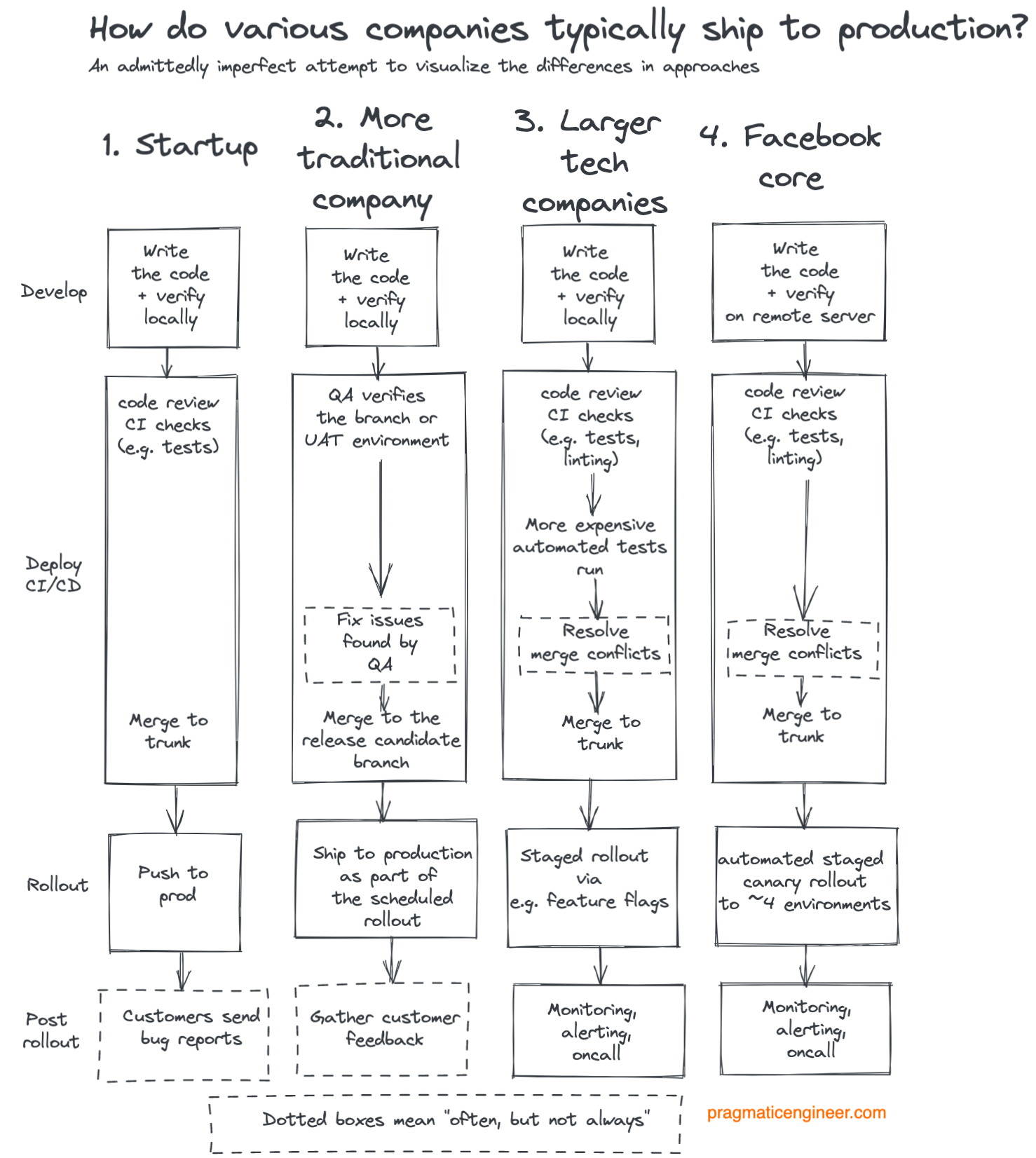
Примечания к этой диаграмме:
1. Стартапы: обычно проводят меньше проверок качества, чем другие компании.
Стартапы, как правило, отдают приоритет быстрому развитию и организации цикла, и часто делают это без особых средств к существованию. Подход имеет место быть, если у них пока нет клиентов. По мере того как компания привлекает пользователей, команда должна начать искать способы, чтобы не вызвать регрессии или ошибки. Затем у них есть выбор: пойти по одному из двух путей: нанять тестировщиков или инвестировать в автоматизацию.
2. Традиционные компании: склонны больше полагаться на команды обеспечения качества.
Хотя автоматизация иногда присутствует в более традиционных компаниях, характерно, что они полагаются на большие группы контроля качества для проверки того, что они создают. Работа на ветках также распространена; в этих средах trunk-based встречается редко.
Код в основном запускается в производство по расписанию, например, еженедельно или даже реже, после того как команда QA проверит функциональность.
Среды Staging и UAT (User Acceptance Testing) более распространены, как и более крупные пакетные изменения, пересылаемые между средами. Для перехода от одного этапа к другому часто требуется одобрение QA-команды, product-менеджера или project-менеджера.
3. Крупные технологические компании: обычно вкладывают значительные средства в инфраструктуру и автоматизацию, связанные с отправкой.
Эти инвестиции часто включают в себя автоматические тесты, которые быстро выполняются и обеспечивают быструю обратную связь, canarying, функциональные флаги и поэтапные развертывания.
Компании стремятся поддерживать планку высокого качества, а также выполнять отправку сразу после завершения проверки качества, работая над главной веткой разработки. Инструменты для разрешения конфликтов слияния становятся важными, учитывая, что некоторые из этих компаний могут видеть более 100 изменений в день в главной ветке.
4. Facebook*: имеет сложный и эффективный подход, которым обладают немногие другие компании.
Основной продукт Facebook интересен. В нем меньше автоматизированных тестов, чем многие могли бы предположить, но, с другой стороны, он обладает исключительным автоматизированным canary, где код разворачивается в 4 средах: среда тестирования с автоматизацией, среда, которую используют все сотрудники, через тестовый рынок меньшего региона и для всех пользователей. На каждом этапе, если метрики выключены, развертывание автоматически останавливается.
В статье «Инженерная культура Facebook», в которой бывший сотрудник Facebook рассказывает, как проблема с рекламой была обнаружена до того, как она вызвала сбой, говорится:
«Я работал в Ads и помню это конкретное неудачное развертывание, которое привело бы к огромным финансовым потерям для компании. Изменение кода нарушило работу определенного типа объявлений.Эта проблема была обнаружена на этапе 2 из 4. На каждом этапе отслеживалось так много показателей работоспособности, что, если что-то пошло не так, эти показатели почти всегда срабатывали — как это сделала первая система безопасности.Все сотрудники Facebook использовали предварительные версии веб-сайта и приложений Facebook. Это означает, что у Facebook есть огромная группа тестирования, состоящая примерно из 75 000 человек, которые тестируют свои продукты, прежде чем они будут запущены в производство, и отмечают любое снижение эффективности».
3. Принципы и инструменты качественной отправки в продакшн
Каким принципам и подходам стоит следовать, если вы хотите разумно отправлять изменения в рабочую среду? Ниже расскажу, что я думаю. Обратите внимание, я не говорю, что вам нужно следовать всем приведенным ниже идеям, но это хорошее упражнение, чтобы задаться вопросом, почему вы не должны выполнять какой-либо из этих шагов.
1. Иметь локальную или изолированную среду разработки. Инженеры должны иметь возможность вносить изменения либо на своем локальном компьютере, либо в уникальной для них изолированной среде. Но чаще разработчики работают в локальной среде. Однако в таких местах, как Meta*, переходят на работу на удаленных серверах, выделенных каждому инженеру. Из статьи «Инженерная культура Facebook»:
«Большинство разработчиков работают с удаленным сервером, а не локально. Примерно с 2019 года вся веб-разработка и бэкенд-разработка выполняются удаленно, без локального копирования кода, и Nuclide облегчает этот рабочий процесс. В фоновом режиме Nuclide сначала использовал виртуальные машины (ВМ), а затем перешел на экземпляры OnDemand — аналогично тому, как сегодня работает GitHub Codespaces — за годы до того, как GitHub запустил Codespaces. Мобильная разработка по-прежнему в основном выполняется на локальных компьютерах, так как при удаленной настройке, а также при работе с веб-интерфейсом и серверной частью, возникают проблемы с инструментами».
2. Проверьте локально. После написания кода выполните локальный тест, чтобы убедиться, что он работает должным образом.
3. Рассмотрите крайние случаи и протестируйте их. Какие неочевидные случаи необходимо учитывать при изменении кода? Какие варианты использования существуют в реальном мире, которые вы, возможно, не учли?
Прежде чем завершить работу над изменением, составьте список этих крайних случаев. Рассмотрите возможность написания автоматизированных тестов для них, если это возможно. Хотя бы проведите ручное тестирование.
Составление списка крайних случаев — это сценарий, когда QA-инженеры или тестировщики могут быть очень полезны при разработке нестандартных случаев, если вы работаете с ними.
4. Напишите автоматические тесты для проверки ваших изменений. После того как вы вручную проверите свои изменения, проверьте их с помощью автоматических тестов. Если следовать такой методологии, как TDD, вы можете поступить наоборот, сначала написав автоматические тесты, а затем обеспечив прохождение этих тестов после ваших изменений.
5. Привлеките еще одну пару глаз, чтобы посмотреть на это: код-ревью. Когда все изменения проверены, попросите кого-нибудь еще, у кого есть контекст, посмотреть на ваши изменения в коде. Напишите четкое и краткое описание ваших изменений, объясните, какие пограничные случаи вы тестировали и получите ревью кода. Узнайте больше о том, как делать хороший код-ревью и как лучше проверять код.
6. Все автоматические тесты проходят, что сводит к минимуму вероятность регрессии. Прежде чем отправлять код, запустите все существующие тесты для кодовой базы. Обычно это делается автоматически через систему CI/CD (непрерывная интеграция/непрерывное развертывание).
7. Организуйте мониторинг ключевых характеристик продукта, связанных с вашим изменением. Как вы узнаете, что ваши изменения нарушают то, что автоматические тесты не проверяют? Если у вас нет способов отслеживать индикаторы работоспособности системы, вы этого не сделаете. Поэтому убедитесь, что для изменения написаны индикаторы работоспособности или другие индикаторы, которые вы можете использовать.
Например, в Uber большинство изменений кода внедрялись как эксперименты с определенным набором показателей, на которые они должны были либо не повлиять, либо улучшить. Одним из показателей, который, как ожидается, останется неизменным, был процент людей, успешно совершающих поездки с Uber. Если эта метрика падала при изменении кода, выдавалось предупреждение, и команда, внесшая изменения в код, должна была выяснить, не повлияло ли их изменение на качество взаимодействия с пользователем.
8. Создайте дежурную службу и вооружите ее необходимыми знаниями на случай ЧП, чтобы знать, что делать, если что-то пойдет не так. После того как изменение отправлено в производство, есть большая вероятность, что некоторые дефекты станут видны намного позже. Вот почему хорошо иметь дежурных инженеров, которые могут реагировать либо на предупреждения о состоянии здоровья, либо на входящие сообщения от клиентов, либо в службу поддержки клиентов.
Убедитесь, что дежурство организовано таким образом, чтобы инженеры имели достаточно информации о том, как уменьшить количество отключений. В большинстве случаев у команды есть перечень задач с достаточными сведениями для подтверждения сбоев и их устранения. Во многих командах также проводится дежурное обучение, а некоторые проводят симуляции дежурной ситуации, чтобы подготовить членов команды к дежурству.
9. Развивайте культуру безупречного решения инцидентов, обучение команды в решении проблем. Я подробно освещаю эту тему в статье Обзор инцидентов и лучшие практики по аварийным ситуациям.
4. Дополнительные уровни проверки и подходы
Какие уровни, инструменты и подходы некоторые компании используют в качестве дополнительных способов доставки надежного кода в рабочую среду? Команды обычно используют некоторые из описанных ниже подходов, но редко все сразу. Некоторые подходы компенсируют друг друга; например, нет особых причин иметь несколько сред тестирования, если у вас есть многопользовательская среда и вы уже проводите тестирование в рабочей среде.
Вот 9 подходов, которые обеспечивают дополнительные подстраховки:
1. Отдельные среды развертывания. Настройка отдельных сред для тестирования изменений кода — распространенный способ добавить дополнительную подстраховку к процессу выпуска. Прежде чем код попадает в рабочую среду, он развертывается в одной из этих сред. Эти среды можно назвать тестированием, UAT (приемочное пользовательское тестирование), staging, pre-prod (пре-продакшн) и другими.
В компаниях, где есть команды QA, QA часто проверяет изменения в этой среде и ищет регрессии. Некоторые среды могут быть созданы для выполнения автоматических тестов, таких как сквозные, дымовые или нагрузочные тесты.
Хотя эти среды выглядят хорошо на бумаге, они сопряжены с большими затратами на обслуживание. Это связано как с ресурсами, поскольку машины должны работать так, чтобы эта среда была доступна, так и с поддержанием данных в актуальном состоянии. Эти среды должны быть заполнены данными, которые либо сгенерированы, либо перенесены из рабочей среды.
Подробнее о средах развертывания и подготовки читайте в статье Создание и выпуск сред развертывания, опубликованной командой Harness.
2. Динамическое развертывание сред тестирования/развертывания. Обслуживание сред развертывания, как правило, создает много накладных расходов. Это особенно верно, когда, например, выполнение миграции данных требует обновления данных во всех тестовых средах.
Чтобы повысить качество разработки, инвестируйте в автоматизацию для запуска тестовых сред, включая заполнение содержащихся в них данных. Как только это будет сделано, это откроет возможности для более эффективного автоматизированного тестирования, чтобы люди могли легче проверять свои изменения и создавать автоматизацию, которая лучше соответствует вашим вариантам использования.
3. Выделенная команда QA. Инвестиция, которую делают многие компании, желающие уменьшить количество дефектов, – это наем команды QA. Эта команда обычно отвечает за ручное и исследовательское тестирование продукта.
Я считаю, что если у вас есть команда контроля качества, которая занимается только ручным тестированием, то в этом есть смысл. Однако, если команда выполняет ручные тесты для вещей, которые можно автоматизировать, затраты времени на ручное тестирование замедлят работу команды, а не ускорят ее.
Я наблюдал как в продуктивных командах специалисты по обеспечению качества превращаются в экспертов в предметной области и помогают инженерам предвидеть крайние случаи. Они также проводят исследовательское тестирование и обнаруживают больше крайних случаев и неожиданного поведения.
Однако в этих продуктивных командах QA также становятся QA-инженерами, а не ручными тестировщиками. Они начинают вовлекаться в автоматизацию тестов и имеют право голоса в формировании стратегии автоматизации, что ускоряет процесс внесения изменений в код.
4. Исследовательское тестирование. Большинство инженеров умеют тестировать вносимые ими изменения, проверять, работают ли они должным образом, и рассматривать крайние случаи. Но как насчет тестирования, связанного с тем, как розничные пользователи системы используют продукт?
Здесь на помощь приходит исследовательское тестирование.
Исследовательское тестирование пытается смоделировать то, как клиенты могут использовать продукт, чтобы выявить крайние случаи, на которые они могут наткнуться. Хорошее исследовательское тестирование требует сочувствия к пользователям, понимания продукта и инструментов для моделирования различных вариантов использования.
В компаниях со специальными командами контроля качества обычно проводят исследовательское тестирование. В местах, где нет выделенных групп контроля качества, тестирование должны выполнять либо инженеры, либо поставщики, с которыми компании иногда заключают контракты и которые специализируются на исследовательском тестировании.
5. Canarying. Canarying происходит от фразы «канарейка в угольной шахте». В начале 20 века шахтеры брали с собой в шахту канарейку в клетке. У этой птицы устойчивость к ядовитым газам ниже, чем у людей, поэтому, если птица переставала чирикать или теряла сознание, это было предупреждающим знаком для шахтеров о наличии газа, и они эвакуировались.
Сегодня канареечное тестирование означает развертывание изменений кода для меньшего процента пользователей, а затем отслеживание сигналов работоспособности этого развертывания на наличие признаков того, что что-то не так. Обычный способ реализации переноса canarying — либо перенаправить трафик на новую версию кода с помощью балансировщика нагрузки, либо развернуть новую версию кода на одном узле.
Узнайте больше о canarying в этой статье команды LaunchDarkly.
6. Флаги функций и эксперименты. Еще один способ контролировать развертывание изменения — скрыть его за флагом функции в коде. Затем этот флаг функции можно включить для подмножества пользователей, и эти пользователи будут выполнять новую версию кода.
Флаги функций достаточно легко реализовать в коде, и они могут выглядеть примерно так, как этот флаг для воображаемой функции под названием «Zeno»:
if( featureFlags.isEnabled(“Zeno_Feature_Flag”)) {
// New code to execute
} else {
// Old code to execute
}
Флаги функций — это распространенный способ разрешить проведение экспериментов. Эксперимент означает разделение пользователей на две группы: экспериментальную группу (эксперимент) и контрольную группу (те, кто не участвует в эксперименте). Эти две группы получают два разных опыта, а команда инженеров и специалистов по обработке и анализу данных оценивает и сравнивает результаты.
7. Поэтапное развертывание. Поэтапное развертывание означает пошаговые изменения доставки, оценку результатов на каждом этапе, а затем дальнейшие действия. Поэтапные развертывания обычно определяют либо процент пользовательской базы, получившей измененную функциональность, либо регион, в котором эта функциональность должна быть развернута, либо сочетание того и другого.
Поэтапный план развертывания может выглядеть так:
- Фаза 1: развертывание на 10 % в Новой Зеландии (небольшой рынок для проверки изменений)
- Фаза 2: развертывание 50 % в Новой Зеландии
- Фаза 3: 100% развертывание в Новой Зеландии
- Фаза 4: развертывание на 10 % по всему миру
- Фаза 5: развертывание на 25 % по всему миру
- Фаза 6: развертывание на 50 % по всему миру
- Фаза 7: 100% развертывание по всему миру
Между каждым этапом развертывания устанавливаются критерии, когда развертывание может быть продолжено. Обычно это определяется отсутствием неожиданных регрессий и наблюдаемыми ожидаемыми изменениями (или их отсутствием) бизнес-показателей.
8. Мультиарендность. Подход, популярность которого растет, заключается в использовании рабочей среды в качестве единственной среды для развертывания кода, включая тестирование в рабочей среде.
Хотя тестирование в производственной среде звучит безрассудно, это не так, если оно проводится с использованием многопользовательского подхода. Uber описывает свой путь от промежуточной среды через тестовую песочницу с теневым трафиком до маршрутизации на основе аренды.
Идея аренды заключается в том, что контекст аренды распространяется с запросами. Службы, получающие запрос, могут определить, относится ли этот запрос к рабочему, тестовому, бета-арендному и т.д. Службы имеют встроенную логику для поддержки аренды и могут по-разному обрабатывать или маршрутизировать запросы. Например, платежная система, получающая запрос с тестовой арендой, скорее всего, имитирует платеж вместо фактического запроса платежа.
Подробнее об этом подходе читайте, как Uber реализовал мультиарендный подход, а также как это сделал Doordash.
9. Автоматические откаты. Мощный способ повысить надежность — сделать откат автоматическим для любых изменений кода, которые подозреваются в нарушении чего-либо. Это подход, который использует, среди прочего, Booking.com. Любой эксперимент, в котором обнаружено ухудшение ключевых показателей, закрывается, а изменение откатывается:
Не уверен, что все еще так, но я предполагаю, что да. Инструмент для экспериментов имеет переключатель, который немедленно останавливает эксперимент в производственной среде, если какой-либо показатель работоспособности (например, ошибки) резко возрастает сразу после начала эксперимента.
Заслуженный инженер GitHub, Яана Доган, приводит аналогичный пример автоматического отката в сочетании с поэтапным развертыванием:
Еще одна деталь — какой тип инвестиций идет на автоматический откат в одних компаниях по сравнению с другими. Когда у вас есть надежные многоэтапные автоматические развертывания и автоматические откаты, вы редко опасаетесь прерывания производства.
10. Автоматические развертывания и откаты в нескольких тестовых средах. Продвижение автоматизированных откатов на шаг вперед и их объединение с поэтапными развертываниями и несколькими средами тестирования — это подход, который Facebook уникально применил для своего основного продукта.
5. Идти на прагматичный риск, чтобы двигаться быстрее
Бывают случаи, когда вы хотите двигаться быстрее, чем обычно, и готовы пойти на больший риск. Каковы прагматические практики для этого?
1. Решите, какой процесс или инструмент нельзя проигнорировать. Возможна ли принудительная отправка без проведения тестов? Можете ли вы внести изменения в кодовую базу так, чтобы никто на это не посмотрел? Можно ли изменить производственную базу данных без тестирования?
Каждая команда или компания должны решить, какие процессы нельзя проигнорировать. Для всех приведенных выше примеров, если этот вопрос возникает в устоявшейся компании с большим количеством пользователей, которые зависят от их продуктов, я бы хорошо подумал, прежде чем нарушать правила, поскольку это может принести больше вреда, чем пользы. Если вы решите обойти правила, чтобы двигаться быстрее, я рекомендую получить поддержку от других людей в вашей команде, прежде чем приступать к этому курсу действий.
2. Предупредите соответствующих заинтересованных лиц при отправке «рискованных» изменений. Время от времени вы будете выпускать изменения, которые являются более рискованными и менее проверенными, чем вы хотели бы в идеале. Хорошей практикой будет предупредить тех людей, которые могут сообщить вам, если увидят что-то странное. Заинтересованные стороны, о которых следует уведомить в этих случаях, могут включать:
- Члены вашей команды.
- Команды, которые зависят от вашей, и те, от которых зависите вы.
- Заинтересованные стороны, с которыми контактируют пользователи.
- Служба поддержки.
- Заинтересованные стороны бизнеса, которые имеют доступ к бизнес-показателям и могут уведомить вас, если они увидят тенденцию в неправильном направлении.
3. Составьте план отката, который легко выполнить. Как вы можете отменить изменение, которое вызывает проблему? Даже если вы работаете быстро, убедитесь, что у вас есть план, который достаточно легко выполнить. Это особенно важно для изменений данных и конфигурации.
Планы отката обычно добавлялись к различным версиям в первые дни существования Facebook. Изнутри инженерной культуры Facebook:
4. Воспользуйтесь отзывами клиентов после внесения рискованных изменений. Получите доступ к каналам обратной связи с клиентами, таким как форумы, обзоры клиентов и служба поддержки клиентов, после того, как вы внесете рискованное изменение. Активно просматривайте эти каналы, чтобы узнать, есть ли у клиентов проблемы, связанные с внесенными вами изменениями.
5. Отслеживайте инциденты и измеряйте их влияние. Знаете ли вы, сколько сбоев в работе вашего продукта произошло за последний месяц? Последние три месяца? Что испытали клиенты? Каково было влияние на бизнес?
Если ответ на эти вопросы таков, что вы не знаете, значит, вы работаете вслепую и не знаете, насколько надежны ваши системы. Рассмотрите возможность изменения своего подхода к отслеживанию и измерению простоев и накоплению их последствий. Эти данные нужны вам, чтобы знать, когда нужно настроить процессы для более надежных релизов. Он также понадобится вам, если вы собираетесь использовать бюджет на ошибки.
6. Используйте бюджет на ошибки для принятия решения о том, можете ли вы выполнять «рискованные» развертывания. Начните измерять доступность вашей системы с помощью таких измерений, как SLI (индикаторы уровня обслуживания) и SLO (целевые показатели уровня обслуживания), или измеряя, как долго система находится в плачевном состоянии или не работает.
Затем определите бюджет на ошибки, степень снижения качества обслуживания, которую вы считаете приемлемой для пользователей на время. Пока этот бюджет ошибок не превышен, более рискованные развертывания — те, которые с большей вероятностью могут нарушить работу службы, — могут продолжаться. Однако, как только вы достигнете этой квоты, больше не используйте короткие пути.
Выводы
Я полагаю, что один из самых важных выводов — сосредоточиться не только на том, как вы отправляете продукт в продакшн, но и на том, как вы можете исправить ошибки, когда они случаются. Несколько других заключительных мыслей:
- Быстрая отправка или качественная отправка; вы можете выбрать оба варианта! Некоторые люди ошибочно думают, что отправка проводится либо быстро, либо тщательно, но медленно. Напротив, многие инструменты помогут вам быстро поставлять продукт с высоким качеством, позволяя вам и то и другое. Код-ревью, системы CI/CD, линтинг, автоматически обновляемые среды тестирования или аренда тестов — все это поможет вам быстро и качественно выпускать продукт.
- Знайте инструменты, которые есть в вашем распоряжении. В этой статье перечислены различные подходы, которые можно использовать для более быстрой и надежной отправки.
- Контроль качества — ваш друг, помогающий ускорить процесс выпуска. Хотя некоторым инженерам, работающим с QA-инженерами и тестировщиками, может показаться, что QA замедляет работу, я оспариваю это мнение. Цель QA — выпуск высококачественного программного обеспечения. Их цель также не мешать быстрой отправке. Если вы работаете с QA, сотрудничайте с ними, чтобы улучшить процесс релиза, чтобы ускорить его без снижения качества.
- Труднее добавить в устаревшие кодовые базы инструменты, которые ускорят отправку. Если вы запускаете продукт с нуля, проще настроить методы, обеспечивающие быструю отправку, чем модифицировать их для существующих кодовых баз. Это не означает, что вы не можете модифицировать эти подходы, но это будет дороже.
- Примите, что вы отправите ошибки. Сосредоточьтесь на том, как быстро вы сможете их исправить! Многие команды слишком зациклены на том, как свести к минимуму ошибки в рабочей среде, забывая о том, как быстро выявлять проблемы и оперативно их устранять.
О качестве программного обеспечения: многие команды слишком озабочены тем, как отправить продукт практически без ошибок,но недостаточно о том, как их быстро обнаружить и быстро устранить — делая это либо автоматически, либо с помощью простого шага.Для получения устойчивых продуктов/платфоры нужно и то и другое.
Комментарии