
Кратко рассмотрен анализ компании OpenAI относительно основных закономерностей роста вычислительных мощностей в области ИИ.

Современное состояние вычислительных мощностей в ИИ
Три фактора, стимулирующих развитие искусственного интеллекта, это:
- Новые алгоритмы.
- Данные контролируемого обучения или получаемые от среды.
- Доступная для обучения вычислительная производительность.
Инновациям в области алгоритмов и данных трудно сопоставить численный эквивалент, в то время как в оценке вычислительных мощностей нет никаких сложностей. Разумеется, использование емких вычислительных массивов иногда раскрывает недостатки современного инструментария алгоритмов, но в крупных областях сложность вычислений обычно приводит к повышению производительности и дополняет алгоритмические достижения.
Анализ использования крупнейших экспериментов по искусственному интеллекту с 2012 года показывает экспоненциальный рост с удвоением вычислительных мощностей каждые 3.5 месяца. Для сравнения в законе Мура удвоение происходит лишь каждые 18 месяцев. Рост вычислительных мощностей является ключевым компонентом прогресса в области ИИ, и, пока эта тенденция продолжается, стоит приготовиться к появлению систем, выходящих за пределы текущих возможностей.
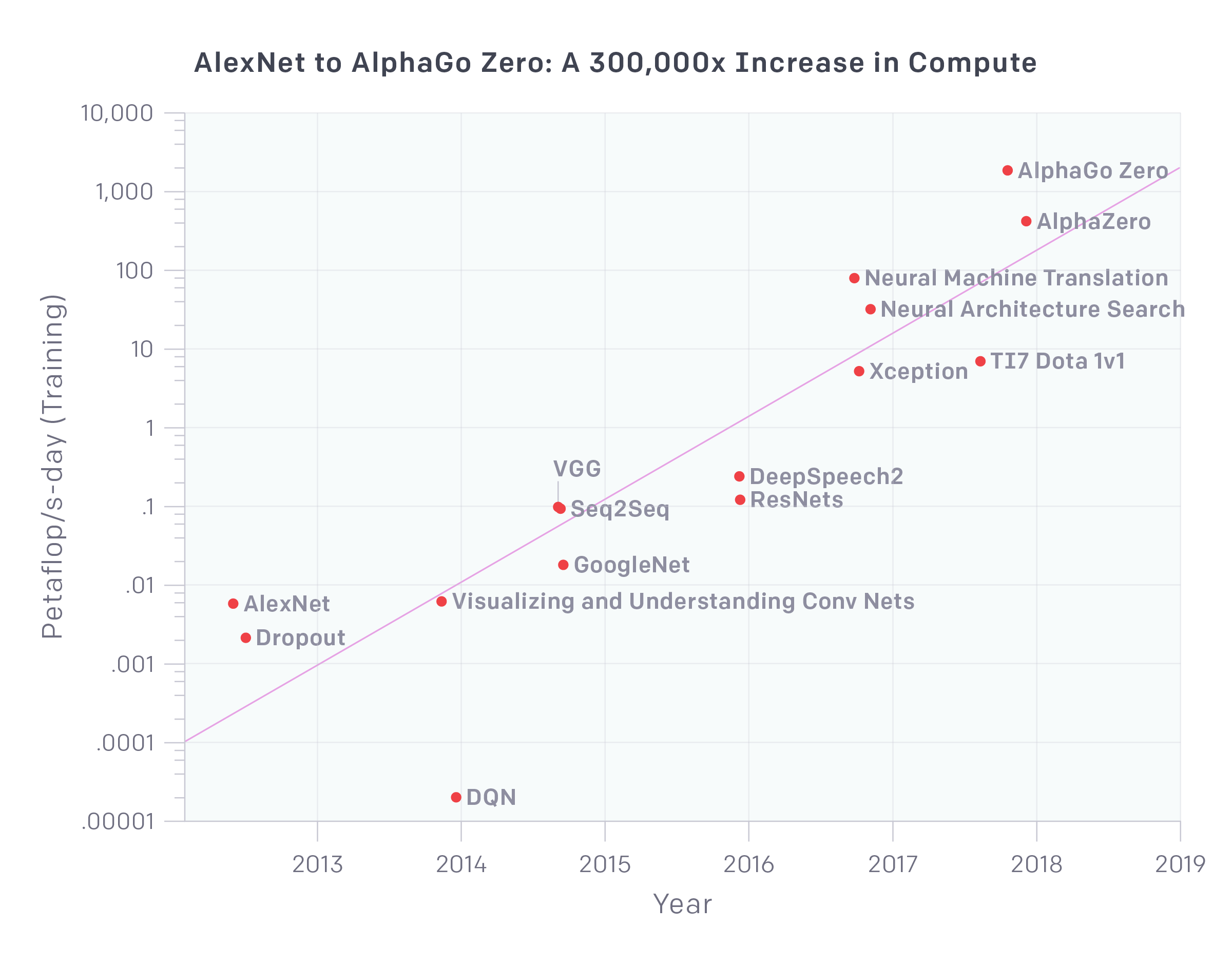
На диаграмме выше, являющейся основным результатом анализа, показано изменение общего объема вычислений в петафлопс-днях (один петафлопс-день соответствует суткам вычислений, совершаемых со скоростью 1015 операций нейронной сети в секунду, то есть порядка 1020 операций). Такого рода единицы информации используются из соображений, аналогичных применению кВт-часов для расчета электроэнергии. Важны не пиковые значения FLOPS аппаратного обеспечения, а количество выполненных операций.
Число операций, приходящиеся на модель, сильно зависит от суммарного объема расчетов, поскольку ограничения на параллелизм (как аппаратные, так и вычислительные) ведут к соответствующим ограничениям, накладываемым на объем успешно обучаемой модели. Безусловно, важные прорывы в области ИИ до сих пор случаются и для моделей с небольшими объемами вычислений, но рассматриваемый анализ посвящен именно вопросу пределов необходимых вычислительных мощностей.
Приведенная выше тенденция показывает десятикратный рост в течение каждого года. Частично это обусловлено "железом", позволяющим производить все больше вычислительных операций в секунду за те же деньги (GPU и особенно TPU), но в значительной мере результат обусловлен тем, что исследователи используют все большее число параллельно работающих процессов и готовы платить за это.
Исторические этапы
Соотнеся полученный график с историей развития машинного обучения и специализированных архитектурных решений информационных систем последних лет, можно выделить следующие этапы:
- До 2012. В машинном обучении почти не используются вычислительные мощности графических процессоров.
- 2012–2014. Инфраструктура обучения на нескольких графических процессорах еще не общепринята, в среднем используется 1-8 графических процессоров, рассчитанных на 1-2 TFLOPS.
- 2014-2016. Представлены широкомасштабные результаты параллельного использования 10-100 графических процессов.
- 2016-2018. Подходы, связанные с решением трудностей алгоритмического параллелизма, а также создания специализированных тензорных процессоров значительно ослабили прежние ограничения.
Технологии AlphaGoZero / AlphaZero стали наиболее заметными примерами использования массивного алгоритмического параллелизма, однако соответствующая архитектура теперь доступна и для промышленных решений.
Что нас ждет дальше?
Есть несколько причин полагать, что тренд, приведенный на графике, сохранится в дальнейшем. Многие стартапы в области архитектур информационных систем проектируют процессоры специально под задачи ИИ, с повышенными значениями FLOPS на единицу мощности (что коррелирует с FLOPS/$). Кроме того, некоторые алгоритмические новшества в области параллелизма, принципиально могут быть перенесены и на более старые архитектуры массивов вычислительных мощностей.
С другой стороны, предел стоимости вычислений пока далеко не достигнут. Авторы анализа оценивают, что наиболее крупные модели для обучения требуют в настоящий момент аппаратных средств стоимостью в несколько миллионов долларов (хотя их амортизационная стоимость существенно ниже), при этом большинство вычислительных мощностей относительно нейронных сетей до сих пор тратится не на обучение, а на развертывание для конечных пользователей. Таким образом, результат улучшения качества моделей за счет прироста вычислительных мощностей выглядит разумным и экономически оправданным решением.
Подробнее ознакомиться с результатами анализа и методом расчета можно в оригинальном источнике.
Комментарии