

DeepFake – технология синтеза изображения, основанная на искусственном интеллекте и используемая для замены элементов изображения на желаемые образы. Если вы не слышали о дипфейках, посмотрите приведенный ниже видеоролик. В нём актёр Джим Мескимен читает стихотворение «Пожалейте бедного пародиста» в двадцати лицах знаменитостей.
Название технологии – объединение терминов «глубокое обучение» (англ. Deep Learning) и «подделка» (англ. Fake). В большинстве случаев в основе метода лежат генеративно-состязательные нейросети (GAN). Одна часть алгоритма учится на фотографиях объекта и создает изображение, буквально «состязаясь» со второй частью алгоритма, пока та не начнет путать копию с оригиналом.
В следующем видео показаны процессы, происходящие за кулисами обучения нейросети. Как пишет автор проекта Sham00K, на итоговое видео потрачено более 250 часов работы, использовались 1200 часов съемочных материалов и 300 тыс. изображений. Объем сгенерированных данных составил приблизительно 1 Тб.
Области применения технологии
Уже имеются целые YouTube- и Reddit-каналы c дипфейк-роликами. Технология DeepFake может применяться для самых разных целей.
Кинопроизводство. Производство фильмов сегодня – крайне затратный процесс с арендой камер, студий и оплатой работы актёров. Развитие технологии DeepFake позволит сократить затраты на съемочный процесс, монтаж и спецэффекты.
Локализация рекламы. Достаточно записать один рекламный ролик со знаменитостью, после чего записанное лицо можно переносить в видео с местными актерами, произносящими рекламные слоганы на родном языке. То есть можно добиться эффекта, как будто знаменитость говорит на языке страны дистрибуции продукта.
Виртуальная и дополненная реальности. Технология переноса мимики может применяться для создания цифровых двойников в играх, виртуальной и дополненной реальностях. Источниками лица могут также служить знаменитости или участники игры. Это повышает эмоциональное вовлечение.
Очевидно, что технология должна использоваться с особой осторожностью. Злоумышленниками могут преследоваться цели компрометирования личности или создания фейковых новостей. В начале октября 2019 г. члены Комитета по разведке Сената США призвали крупные технологические компании разработать план для борьбы с дипфейками. Ранее, в сентябре этого года, Google создала специальный датасет дипфейков.
Отметим, что данная публикация подготовлена исключительно в исследовательских целях.
Создадим собственный DeepFake
Для синтеза дипфейка мы будем использовать популярную библиотеку DeepFaceLab. Библиотека стремительно развивается, сейчас доступно несколько релизов:
- Windows (magnet-ссылка) – последний релиз, для загрузки требуется торрент-клиент.
- Windows (Mega.nz) – содержит старые и новые релизы. Есть сборки для Nvidia карт размером порядка 3 Гб, а также версия для OpenCl (2020).
- Google Colab (GitHub) – можно использовать удаленные вычислительные мощности.
- DeepFaceLab для Linux (GitHub).
- CentOS Linux (github) – может отставать от основной ветки релизов.
Ниже описан базовый процесс создания дипфейка на примере Windows.
Важно понимать, что на качество результата влияет множество свойств исходных видеофайлов (разрешение и длительность, разнообразность мимики персонажей, освещение и т. д.). За любыми подробностями и деталями настроек перенаправляем к оригинальному репозиторию.
Системные требования для DeepFaceLab
Минимальные системные требования для работы с инструментом:
- ОС Windows 7 или выше (64 бит).
- Процессор с поддержкой SSE-инструкций.
- Оперативная память объемом не менее 2 Гб + файл подкачки.
- OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics).
Рекомендуемые системные требования:
- Процессор с поддержкой AVX-инструкций.
- Оперативная память объемом не менее 8 Гб.
- Видеокарта NVIDIA с объемом видеопамяти не менее 6 Гб.
Алгоритм работы с DeepFaceLab
Предварительно договоримся о терминологии:
src(сокр. от англ. source) – лицо, которое будет использоваться для замены,dst(сокр. от англ. destination) – лицо, которое будет заменяться.
Архив сборки нужно распаковать как можно ближе к корню системного диска. После распаковки в каталоге DeepFaceLab вы найдете множество bat-файлов.
Местом хранения модели служит внутренняя директория workspace. В ней будут содержаться видео, фотографии и файлы самой программы. Вы можете копировать переименовывать каталог для сохранения резервных копий.
Папка _internal используется алгоритмом.
Сразу после распаковки в workspace уже могут содержаться примеры видеороликов для теста. В соответствии с описанной терминологией вы можете заменить их видеофайлами с теми же названиями data_src.mp4 и data_dst.mp4. Максимально поддерживаемое разрешение – 1080p. Приведенные в документации примеры расширений файлов: mp4, avi, mkv.
data_dst – это папка, в которой будут храниться кадры, извлеченные из файла data_dst.mp4 – целевого видео, в котором мы меняем местами лица. Папка также будет содержать две подпапки, которые создаются после запуска «извлечения» лиц:
aligned– изображения лиц (со встроенными данными лицевых ориентиров)align_debug– исходные кадры с наложенными на лица ориентирами, которые используются чтобы идентифицировать корректно или некорректно распознанные лица.
data_src – это папка, в которой будут храниться кадры, извлеченные из файла data_src.mp4, или другие кадры-картинки в формте jpg, на которых изображен хозяин нового лица. Как и в случае с data_dst, после извлечения лиц создаются две подпапки:
aligned– извлеченные изображения лицalign_debugвыполняет ту же функцию, что и дляdst, однако для извлечения набора данных src папка не создается по умолчанию. При желании нужно выбратьyes (y)при запуске извлечения, чтобы её сгенерировать.
Как вы могли заметить, bat-файлы в корне распакованного каталога имеют в начале имени номер. Каждый номер соответствует определенному шагу выполнения алгоритма. Некоторые пункты опциональны. Пройдемся по этой последовательности.
1. Очистка рабочего каталога
На первом шаге запуском 1) clear workspace.bat и нажатием пробела очищаем лишнее содержимое папки workspace. Одновременно создаются необходимые директории.
2. Извлечение кадров из видеофайла источника (data_src.mp4)
На втором шаге извлекаем изображения (кадры) из src-файла (2) extract images from video data_src.bat). Для этого запускаем bat-файл, получаем приглашение для указания кадровой частоты:
Enter FPS ( ?:help skip:fullfps ) :
Пропускаем пункт, нажав Enter, чтобы извлечь все кадры.
Output image format? ( jpg png ?:help skip:png ) : ?
В формат png файлы извлекаются без потерь качества, но на порядок медленнее и с большим объемом, чем в jpg. После задания настроек кадры извлекаются в каталог data_src.
3. Извлечение кадров сцены для переноса лица (опционально)
При необходимости обрезаем видео с помощью 3.1) cut video (drop video on me).bat. Этот пункт удобен, если вы никогда не пользовались программным обеспечением для редактирования видео. Перетаскиваем файл data_dst поверх bat-файла. Указываем временные метки, номер аудиодорожки (если их несколько) и при необходимости битрейт выходного файла. Появляется дополнительный файл с суффиксом _cut.
Запускаем 3.2) extract images from video data_dst FULL FPS.bat для извлечения кадров dst-сцены. Файлы автоматически переносятся в каталог data_dst. Как и для src, есть опция с выбором jpg/png.
4. Составление выборки лиц источника
На этом этапе начинается глубокое обучение. Нам необходимо детектировать лица на src-кадрах. Получаемая выборка будет храниться по адресу workspace\data_src\aligned. Этому пункту соответствует множество bat-файлов, начинающихся с 4) data_src faceset extract. При стандартном подходе используется SF3D-алгоритм детекции лица. Есть следующие опции:
- Выбор зоны, которую мы хотим извлечь: площадь увеличивается от full face (
FF) к whole face (WF) и head (HEAD). - Вариант использования
GPU: ALL(задействовать все видеокарты),Best(использовать лучшую). Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях. - Записывать или нет результат работы детекторов. Каждый кадр с выделенными контурами лиц записывается по адресу
workspace\data_src\aligned_debug.
Пример вывода программы при запуске на видеокарте NVIDIA GeForce 940MX:
Performing 1st pass...
Running on GeForce 940MX. Recommended to close all programs using this device.
Using TensorFlow backend.
100%|################################################################################| 655/655 [03:32<00:00, 3.08it/s]
Performing 2nd pass...
Running on GeForce 940MX. Recommended to close all programs using this device.
Using TensorFlow backend.
100%|##########################################################################################################################################################| 655/655 [13:28<00:00, 1.23s/it]
Performing 3rd pass...
Running on CPU0.
Running on CPU1.
Running on CPU2.
Running on CPU3.
Running on CPU4.
Running on CPU5.
Running on CPU6.
Running on CPU7.
100%|#########################################################################################################################################################| 655/655 [00:05<00:00, 112.98it/s]
-------------------------
Images found: 655
Faces detected: 654
-------------------------
Done.
Аналогичный bat-файл со словом MANUAL применяется для ручного переизвлечения уже извлеченных лиц в случае ошибок на этапе 4.2) data_src util add landmarks debug images.bat.
4.1. Удаляем большие группы некорректных кадров
Запускаем 4.1) data_src view aligned result.bat. Он запускает обозреватель, в котором можно просмотреть содержимое папки data_src/aligned относительно ложных срабатываний и неправильно определенных лиц, чтобы их можно было удалить.
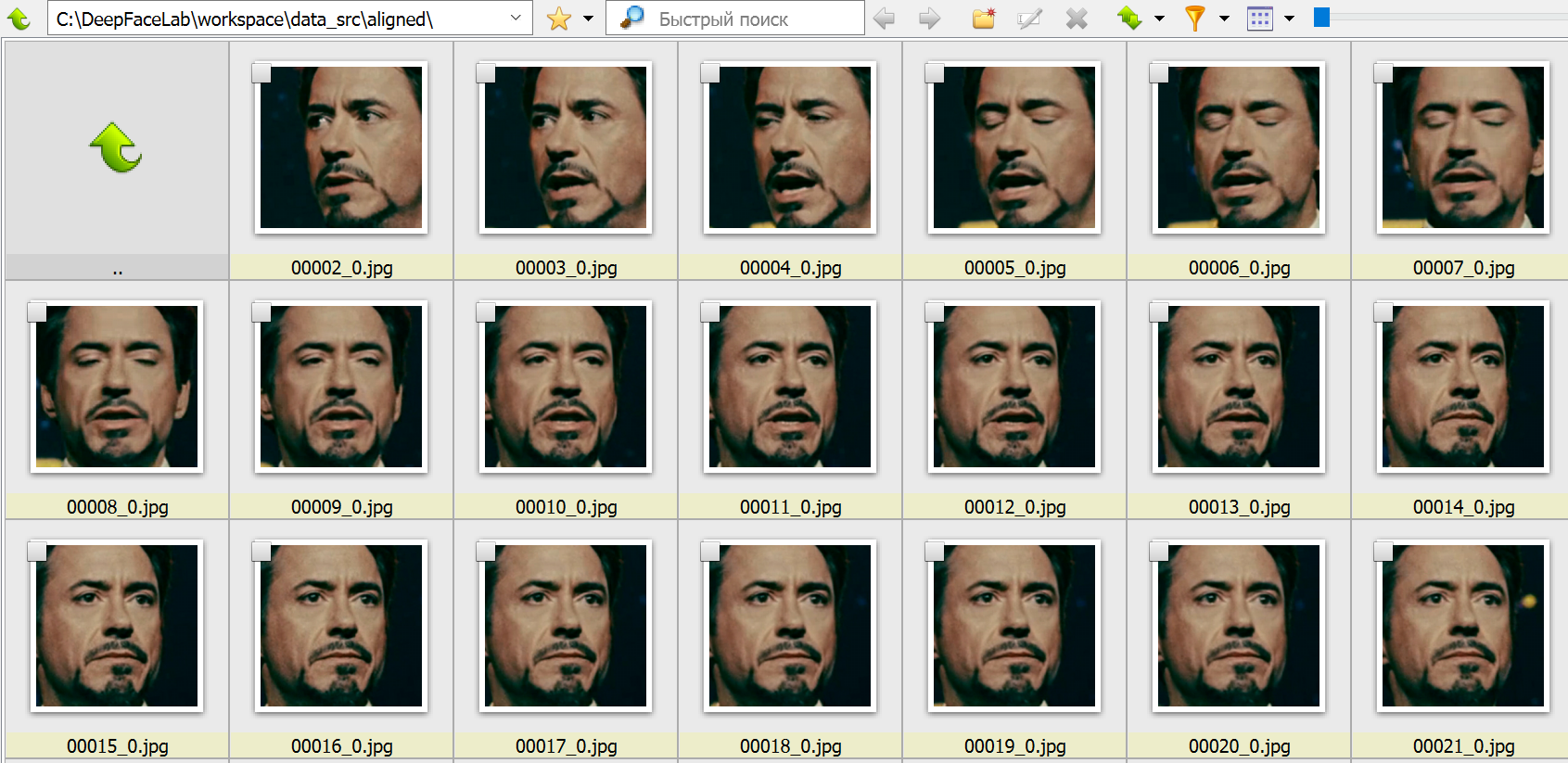
На этом этапе необходимо удалить крупные группы некорректных кадров, чтобы далее не тратить на них вычислительный ресурс. К некорректным кадрам относятся все, что не содержат четко различимого лица. Лицо также не должно быть закрыто предметом, волосами и пр. Не тратьте время на мелкие группы. Мы удалим их на следующем шаге.
4.2. Сортировка и удаление прочих некорректных кадров
Файл 4.2) data_src sort.bat служит для для сортировки и выявления групп некорректных кадров. Не закрывая обозреватель, последовательно запускайте bat-файл с нужной опцией и удаляйте группы некорректных кадров (обычно находятся в конце). Доступные опции:
blur, motion blurсортирует кадры по резкости, удаляем кадры с нечеткими лицами.face yawсортирует лица по взгляду слева направо.face pitch directionсортирует лица так, чтобы в начале списка лицо смотрело вниз, а в конце – вверх.histogram similarityгруппирует кадры по содержанию, позволяет удалять ненужные лица группами.histogram dissimilarityоставляет ближе к концу списка те изображения, у которых больше всего схожих (обычно это лица анфас). По усмотрению можно удалить часть конца списка, чтобы не проводить обучение на идентичных лицах.brightness, hue, amount of black pixelsсоответствуют яркости, насыщенности и количеству черных пикселей. Помогает убрать переходные кадры, где лицо трудно различимо.best faces– помогает выделить наиболее хорошо различимые лица.
4.2) data_src util add landmarks debug images.bat сгенерирует после извлечения лиц папку align_debug.
4.2) data_src util faceset enhance.bat использует специальный алгоритм машинного обучения для масштабирования/«улучшения» качества представления лиц в наборе данных. Полезно, если кадры немного размыты и вы хотите сделать их более резкими.
Файлы 4.2) data_src util faceset metadata restore.bat и 4.2) data_src util faceset metadata save.bat позволяют сохранять и восстанавливать данные об извлеченых наборах лиц/данных, чтобы вы могли редактировать изображения лиц после их извлечения без потери данных о выравнивании. Например, так можно увеличивать резкость, редактировать очки, пятна на коже, делать цветокоррекцию.
4.2) data_src util faceset pack.bat и 4.2) data_src util faceset unpack.bat служат для упаковки (распаковки) лиц из папки aligned в один файл. Используется для подготовки настраиваемого набора данных для предварительного обучения, упрощает совместное использование в виде одного файла и значительно сокращает время загрузки набора данных (секунды вместо минут).
4.2.other) data_src util recover original filename возвращает имена изображений лиц к исходному порядку/именам файлов. Запускать не обязательно – обучение и слияние будут выполняться независимо от имен файлов источника.
5. Составление выборки лиц принимающей сцены (dst)
Следующие операции с некоторыми отличиями идентичны выборке лиц источника. Главным отличием является то, что для принимающей сцены важно определить dst-лица во всех кадрах, содержащих лицо, даже мутных. Иначе в этих кадрах не будет произведено замены на источник.
5) data_dst faceset extract.bat выполняет автоматическое извлечение с использованием алгоритма S3FD.
5) data_dst faceset extract + manual fix.bat позволяет вручную указать контуры лица на кадрах, где лицо не было определено. При этом в конце извлечения файлов открыто окно ручного исправления контуров. Элементы управления описаны вверху окна (вызываются клавишей H).
5) data_dst faceset extract MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.bat используется для ручного переизвлечения из кадров, удаленных из папки align_debug. Подробнее об этом рассказано далее.

Все экстракторы позволяют выбрать между GPU и CPU, а также указать область, выделяемую для извлечения. Аналогично src это FF, WF или HEAD.
5.1. Извлечение лиц вручную (manual extractor)
После запуска 5) data_dst faceset extract MANUAL.bat откроется окно, в котором вы можете вручную найти лица, которые хотите извлечь или переизвлечь:
- Выделите лицо с помощью мыши.
- С помощью колесика мыши можно менять размер области поиска.
- Убедитесь, что все или хотя бы большинство ориентиров находится на важных точках (глазах, рту, носу, бровях) и правильно следуют контурам лица. В некоторых случаях, в зависимости от угла освещения или имеющихся препятствий, может оказаться невозможным точно выровнять все ориентиры, поэтому просто попытайтесь сделать так, чтобы покрывались все видимые части.
- Чтобы изменить режим точности, используйте клавишу
A. Теперь ориентиры не будут так сильно «прилипать» к обнаруженным лицам, но вы сможете более точно позиционировать ориентиры. - Для перемещения вперед и назад используйте клавиши
<и>. Для редактирования нажмитеEnterиликликнителевой клавишей мыши. - Чтобы пропустить оставшиеся грани и выйти из экстрактора, используйте клавишу
q.
Чтобы посмотреть результаты в папке aligned, можно запустить 5.1) data_dst view aligned results.bat.
Чтобы бегло просмотреть содержимое папки align_debug, найти и удалить любые кадры, на которых лицо целевого человека имеет неправильно выровненные ориентиры или ориентиры вообще не были размещены, используйте 5.1) data_dst view aligned_debug results.bat.
5.2. Очистка данных сцены
После того, как мы определили границы data_dst, нужно их очистить аналогично тому, как мы это делали с исходным набором лиц. Однако очистка целевого набора данных отличается от исходного, потому что мы хотим, чтобы все грани были выровнены для всех кадров, в которых они присутствуют, включая проблемные.
Начните с сортировки с помощью 5.2) data_dst sort.bat и используйте сортировку по similarity. Лица будут отсортированы по сходству, цвету, структуре – так будет проще сгруппировать похожие и удалить изображения, содержащие ложные срабатывания, лица других людей и неправильно определенные границы. Послу удаления неверных границ восстановите имена и порядок файлов с помощью утилиты 5.2) data_dst util recover original filename.
Перейдите в папку data_dst/align и используйте следующую, откройте Powershell и с помощью следующей команды удалите суффиксы _0 из имен файлов с размеченными лицами:
get-childitem *.jpg | foreach {rename-item $_ $_.name.replace("_0","")}
Дождитесь завершение процесса – по окончании снова отобразится адрес папки.
Если в сцене есть кроссфейд-переходы или лицо отражается в зеркалах, найдите файлы с суффиксом _1, переместите их в отдельную папку и снова запустите скрипт, но замените в команде _0 на _1. Скопируйте результат обратно в основную папку и убедитесь, что сохранили все файлы.
Создайте копию папки aligned_debug. После этого выделите все файлы в папке aligned, скопируйте их в свежесозданную копию папки align_debug, дождитесь завершения и, пока все только что замененные файлы еще выделены, удалите их. Просмотрите оставшиеся кадры и удалите все, на которых нет лиц, которые вы хотите извлечь вручную. Скопируйте остальные кадры обратно в исходную папку align_debug, замените, дождитесь завершения и, пока все замененные файлы все еще выделены, удалите их.
После таких манипуляций папка align_debug содержит только кадры, из которых были правильно извлечены лица, а также кадры, из которых экстрактор не смог правильно извлечь лица или не извлек. Теперь вы можете запустить 5) data_dst faceset MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.bat для их извлечения вручную Прежде чем вы это сделаете, можно запустить 5.1) data_dst view align_debug results.bat, чтобы быстро просмотреть оставшиеся хорошие и посмотреть, правильно ли выглядят ориентиры.
Если вы хотите еще больше улучшить качество разметки, используйте альтернативную модель разметки XSeg, работа с которой подробно описана в п. 5.3 официального руководства.
6. Обучение
Обучение нейросети – самая времязатратная часть, которая может длиться часы и сутки. Для тренировки необходимо выбрать одну из моделей. Выбор и качество результата определяются объемом памяти видеокарты. В текущей версии программы доступно две модели:
SAEHD (6GB+). Настраиваемая модель для высокопроизводительных графических процессоров.Quick96 (2-4GB). Простой режим, предназначенный для графических процессоров с 2-4 ГБ видеопамяти.
При первом запуске программа попросит указать параметры, применяемые при последующих запусках (при нажатии Enter используются значения по умолчанию). Большинство параметров понятно интуитивно, прочие – описаны в руководстве.
Обратите внимание, что некоторые параметры не могут быть изменены после начала обучения, например:
- разрешение модели (model resolution)
- архитектура модели (model architecture)
- размерность модели (models dimensions)
- тип лица (face type)
Рассмотрим также некоторые другие параметры модели.
Autobackup every N hour: автоматическое резервное копирование вашей модели каждые N часов. По умолчанию отключено.
Target iteration: модель прекратит обучение после достижения заданного количества итераций, например, если вы хотите обучать модель только 100 тыс. итераций, вы должны ввести значение 100000. Если оставить значение равным 0, модель будет работать до тех пор, пока вы не остановите ее вручную.
Flip faces randomly: полезный вариант в случаях, когда в исходном наборе данных нет всех необходимых углов поворота лица.
Batch_size: параметр влияет на количество лиц, сравниваемых друг с другом на каждой итерации. Наименьшее значение — 2, но вы можете увеличить значение, если с этим справится ваш графический процессор. Чем выше разрешение, размеры и больше особенностей у моделей, тем больше потребуется VRAM, поэтому может потребоваться меньший размер пакета. Рекомендуется не использовать значение ниже 4. Для начальной стадии можно установить более низкое значение, чтобы ускорить начальное обучение, а затем повысить его. Оптимальные значения – от 6 до 12.
AE architecture: можно выбрать тип архитектуры модели. Два основных типа: DF и LIAE. Обе модели обеспечивают высокое качество, но DF лучше срабатывает для лиц анфас, а LIAE качественнее справляется с трансформациями. Дополнительные буквы в названии соответствуют повышению сходства (-U) и увеличению разрешения модели (-D).
Прочие настройки подробно описаны в оригинальном руководстве.
Memory Error, Allocation или OOM, то на вашем GPU модель не запустилась, и ее нужно урезать. Необходимо скорректировать опции моделей.При корректных условиях параллельно с консолью откроется окно Training preview, в котором будет отображаться процесс обучения и кривая ошибки. Снижение кривой отражает прогресс тренировки. Кнопка p (английская раскладка) обновляет предпросмотр.
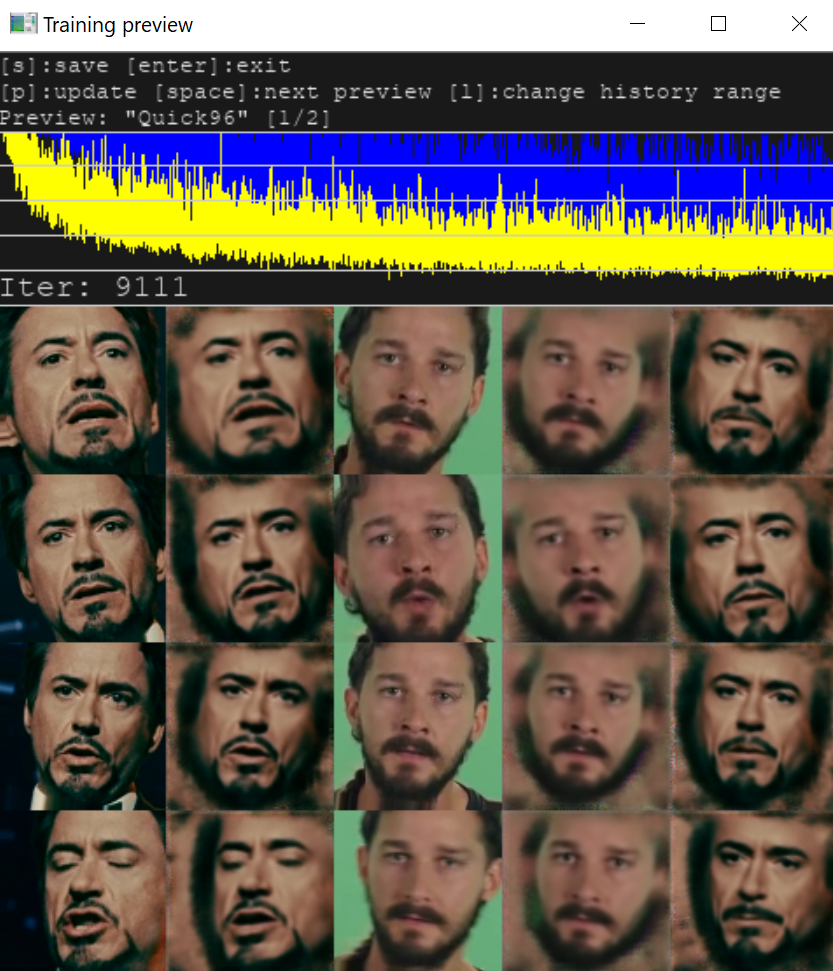
Процесс обучения можно прерывать, нажимая Enter в окне Training preview, и запускать в любое время, модель будет продолжать обучаться с той же точки. Чем дольше длится тренировка, тем лучший результат мы получим.
7. Наложение лиц
Теперь у нас есть результат обучения. Необходимо совместить src-лица и кадры dst-сцены. Из списка bat-файлов выбираем ту модель, на которой происходила тренировка.
В новой версии DeepFaceLab доступно множество режимов наложения с различными масками и дополнительными настройками. В качестве параметров для первой пробы можно использовать параметры по умолчанию (по нажатию Enter) и варьировать их, если вас не устроит результат соединения сцены и нового лица.
8. Склейка кадров в видео
После того, как вы объедините/конвертируете все лица, внутри папки data_dst появится папка с именем merged, содержащая все кадры, а также директория merged_masked, которая содержит кадры масок. Последний шаг – преобразовать их обратно в видео и объединить с исходной звуковой дорожкой из файла data_dst.mp4.
Итоговый файл будет сохранен под именем result. Доступны форматы mp4 и avi. Готово! Ниже представлен пример, полученный для тестовых видео.
Если результат вас не удовлетворил, попробуйте разные опции наложения, либо продолжите тренировку для повышения четкости, используйте другую модель или другие видео с исходным лицом. О неописанных особенностях работы с библиотекой, прочих советах и хитростях читайте в оригинальном руководстве и комментариях к нему.
Комментарии