

Анализ тональности текста (sentiment analysis) – одна из классических задач обработки естественного языка (Natural Language Processing, NLP). Люди оставляют отзывы на какие-либо продукты или события, а наша модель должна определить, положительный это отзыв или отрицательный. Иногда набор данных содержит не только бинарную классификацию (положительный или отрицательный), но и числовые оценки, проставленные авторами отзывов.
Мы исследуем анализ тональности текста на классическом примере – большом наборе отзывов на фильмы из базы IMDb. Скачайте базу и распакуйте ее так, чтобы корневая папка acImdb находилась в той же папке, в которую вы поместите код. В этой папке находятся подпапки train и test, в каждой из которых – папки pos и neg (по 12500 примеров в каждой). Имена файлов содержат оценки, поставленные зрителями, но мы ограничимся распознаванием позитивности и негативности.
Стоит сразу же отметить, что в данной формулировке задача анализа тональности текста явно не имеет практического применения. Клиенту намного проще поставить числовую оценку, чем написать отзыв. Даже если предположить, что это не так, модель, предсказывающая оценку по тексту отзыва, вряд ли найдет коммерческое применение. Эта задача – "игрушечная", отлично подходящая для демонстрации различных методов NLP, и при этом позволяющая добиться довольно высокого результата даже устаревшими методами.

Далекое прошлое
Самый простой способ анализа тональности – присвоить вес каждому слову и получить результирующую оценку простым суммированием весов. Вы можете создать словарь весов вручную по собственному разумению, и этого будет достаточно для получения довольно высокой точности предсказания без всякого обучения.
Несколько более сложный способ – реализовать простейшее обучение следующим образом. Сначала надо присвоить каждому слову какой-нибудь случайный вес. После этого проходим по всей базе и повышаем веса всех слов отзыва, если сумма весов отрицательна, а оценка должна быть положительной. Если же сумма весов всех слов отзыва положительна, а оценка должна быть отрицательной, тогда веса всех слов отзыва нужно уменьшать. Это уже самое настоящее машинное обучение, которое вы можете реализовать, не зная никаких библиотек Data Science и даже не на Python или R. Продолжайте этот процесс до тех пор, пока он повышает точность предсказаний модели.
Я не буду приводить примеров кода, поскольку они тривиальны, и сейчас представляют лишь исторический интерес. Полагаю, что на датасете IMDb таким образом можно получить точность предсказания не ниже 70%.
Прошлое
Мир машинного обучения и ИИ развивается настолько стремительно, что методы, повсеместно применяемые всего пару лет назад, сегодня уже считаются устаревшими. Многие компании до сих пор используют такие устаревшие методы, и даже требуют их знания от соискателей вакансий. Реализация анализа тональности устаревшими методами подробно рассмотрено в первой и второй статьях Аарона Куба (Aaron Kub), откуда я заимствую только основные идеи и финальное решение.
Любая модель анализа тональности (даже самая современная) состоит из трех шагов: очистка и предварительная обработка текста, векторизация и моделирование.

Очистка и обработка текста
Сырой текст всегда содержит лишние символы, которые только мешают его интерпретировать: табуляцию, переводы строки и так далее. Чаще всего удаляют и большинство знаков препинания: если мы собираемся загружать в нашу модель текст по одному предложению, нам якобы достаточно разделить текст на предложения. Если же мы загружаем текст по абзацам или сразу весь целиком, никакие знаки препинания вообще не нужны. Каким образом анализ тональности текста может игнорировать, например, восклицательные знаки? Таких вопросов почему-то никто не задает. На этом этапе часто производится удаление так называемых "стоп-слов" – предлогов, которые якобы не могут влиять на тональность текста, и только мешают его анализировать. При этом даже в английском языке "get up" – совсем не то же самое, что "get out", и удаление "лишних" коротких слов может привести к потере критически важной информации.
Давайте начнем создание нашей устаревшей модели. Кода будет совсем немного, но если вам лень копировать даже его, можно взять код Аарона Куба в GitHub'е. Для начала импортируем необходимые модули:
import numpy as np
import pandas as pd
import os
import re
import warnings
from sklearn.metrics import accuracy_score
warnings.filterwarnings('ignore')
После этого можно загрузить текстовую информацию с диска в память:
import glob
reviews_train = []
for file_name in glob.glob("aclImdb/train/pos/*.txt"):
with open(file_name, 'r', encoding='utf8') as f:
reviews_train.append(f.read().strip())
for file_name in glob.glob("aclImdb/train/neg/*.txt"):
with open(file_name, 'r', encoding='utf8') as f:
reviews_train.append(f.read().strip())
reviews_test = []
for file_name in glob.glob("aclImdb/test/pos/*.txt"):
with open(file_name, 'r', encoding='utf8') as f:
reviews_test.append(f.read().strip())
for file_name in glob.glob("aclImdb/test/neg/*.txt"):
with open(file_name, 'r', encoding='utf8') as f:
reviews_test.append(f.read().strip())
Теперь настало время для очистки и предварительной обработки текста. Так выглядит пример исходного текста:
This isn't the comedic Robin Williams, nor is it the quirky/insane Robin Williams of recent thriller fame. This is a hybrid of the classic drama without over-dramatization, mixed with Robin's new love of the thriller. But this isn't a thriller, per se. This is more a mystery/suspense vehicle through which Williams attempts to locate a sick boy and his keeper.Also starring Sandra Oh and Rory Culkin, this Suspense Drama plays pretty much like a news report, until William's character gets close to achieving his goal.I must say that I was highly entertained, though this movie fails to teach, guide, inspect, or amuse. It felt more like I was watching a guy (Williams), as he was actually performing the actions, from a third person perspective. In other words, it felt real, and I was able to subscribe to the premise of the story.All in all, it's worth a watch, though it's definitely not Friday/Saturday night fare.It rates a 7.7/10 from...the Fiend :.
Очистка производится с помощью регулярных выражений (regex). Если вы не знаете, что это такое, с ними можно познакомиться здесь. Мы удаляем знаки препинания, цифры и теги HTML, а также приводим текст к нижнему регистру:
# Удаляем знаки препинания и цифры
REPLACE_NO_SPACE = re.compile("(\.)|(\;)|(\:)|(\!)|(\')|(\?)|(\,)|(\")|(\()|(\))|(\[)|(\])|(\d+)")
# Заменяем последовательности <br/>, а также / и - пробелами
REPLACE_WITH_SPACE = re.compile("(<br\s*/><br\s*/>)|(\-)|(\/)")
NO_SPACE = ""
SPACE = " "
def preprocess_reviews(reviews):
reviews = [REPLACE_NO_SPACE.sub(NO_SPACE, line.lower()) for line in reviews]
reviews = [REPLACE_WITH_SPACE.sub(SPACE, line) for line in reviews]
return reviews
reviews_train_clean = preprocess_reviews(reviews_train)
reviews_test_clean = preprocess_reviews(reviews_test)
Приведенный выше пример после очистки выглядит вот так:
this isnt the comedic robin williams nor is it the quirky insane robin williams of recent thriller fame this is a hybrid of the classic drama without over dramatization mixed with robins new love of the thriller but this isnt a thriller per se this is more a mystery suspense vehicle through which williams attempts to locate a sick boy and his keeper also starring sandra oh and rory culkin this suspense drama plays pretty much like a news report until williams character gets close to achieving his goal i must say that i was highly entertained though this movie fails to teach guide inspect or amuse it felt more like i was watching a guy williams as he was actually performing the actions from a third person perspective in other words it felt real and i was able to subscribe to the premise of the story all in all its worth a watch though its definitely not friday saturday night fare it rates a from the fiend
Векторизация
Модели машинного обучения (за небольшим исключением в виде деревьев и случайных лесов) не могут работать с текстовыми данными, поэтому тексты нужно преобразовать в числа. Как правило, в результате получаются одномерные массивы чисел – векторы. От того, как вы получаете эти векторы, во многом зависит максимальная точность модели. Практически все устаревшие подходы кодируют слова без учета контекста, то есть слово "bank" в выражениях "river bank" и "bank of Canada" кодируется одинаково. Методики векторизации включают:
- Кодирование TF-IDF. Важность каждого слова определяется частотой его использования во всех текстах тренировочного набора. Эту методику не стоит применять для анализа тональности, поскольку значимость слова для определения тональности никак не зависит от частоты его использования.
- Стемминг. Это обрезание слов, чтобы привести их к единым общим формам. Например, слова "люблю", "любил", "любит", "любить" можно привести к единой форме "люб", и при этом не потерять информацию. С другой стороны, слова "любимый" и "любимчик" несут совершенно разную эмоциональную окраску, и здесь обрезание до единой формы непременно приведет к потере информации.
- Лемматизацию. Каждое слово приводится к его словарной основе, называемой леммой. Очевидно, что при правильно составленном словаре лемматизация способна добиться намного лучшей унификации слов, чем стемминг, с гораздо меньшим риском потери информации. Например, слово "шла" имеет в качестве леммы глагол "идти", и никакая обрезка слова не позволяет ее получить. Разумеется, для лемматизации требуется огромный словарь, в котором должны присутствовать все слова анализируемого языка.
- CountVectorizer. Один из самых простых способов векторизации текста – это сбор всех возможных слов и создание для текста единственного вектора, в котором для каждого слова будет указано количество его вхождений в текст (обычный режим) или факт наличия в тексте (двоичный режим). Очевидно, что при этом мы теряем всю информацию о порядке следования слов, но, как мы увидим ниже, оставшейся информации достаточно для получения достаточно высокой точности предсказания.
- N-граммы. Если кодировать не только наличие слов, а еще и наличие последовательностей из двух и трех слов (биграмм и триграмм), это позволит частично компенсировать отсутствие информации о порядке их следования. Словарь при этом получается просто огромный, но поскольку большая часть кода каждого текста будет заполнена нулями, его можно представить в виде разреженной матрицы, с которыми отлично работает Python.
Мы используем двоичный CountVectorizer с биграммами и триграммами, удаляющий пять стоп-слов. Четверть тренировочного набора данных отрезается и будет использована для валидации в процессе подбора оптимальных гиперпараметров модели.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
stop_words = ['in', 'of', 'at', 'a', 'the']
ngram_vectorizer = CountVectorizer(binary=True, ngram_range=(1, 3), stop_words=stop_words)
ngram_vectorizer.fit(reviews_train_clean)
X = ngram_vectorizer.transform(reviews_train_clean)
X_test = ngram_vectorizer.transform(reviews_test_clean)
X_train, X_val, y_train, y_val = train_test_split( X, target, train_size = 0.75)
Моделирование
Можно использовать любую модель машинного обучения, начиная с простейшей линейной регрессии. Поскольку наши данные сильно разрежены, применим линейный метод опорных векторов, который отлично справляется с такими данными.
from sklearn.metrics import accuracy_score
from sklearn.svm import LinearSVC
for c in [0.001, 0.005, 0.01, 0.05, 0.1]:
svm = LinearSVC(C=c)
svm.fit(X_train, y_train)
print ("Accuracy for C=%s: %s" % (c, accuracy_score(y_val, svm.predict(X_val))))
final = LinearSVC(C=0.01)
final.fit(X, target)
print ("Final Accuracy: %s" % accuracy_score(target, final.predict(X_test)))
Accuracy for C=0.001: 0.88336
Accuracy for C=0.005: 0.8896
Accuracy for C=0.01: 0.89088
Accuracy for C=0.05: 0.8896
Accuracy for C=0.1: 0.88912
Final Accuracy: 0.9
Мы добились точности 90% очень простыми средствами! Фактически наша модель всего лишь присвоила оптимальные веса всем комбинациям из одного, двух и трех слов, встречающимся в наших текстах
Интерпретация результатов и размышления

Чтобы понять, как именно предсказывает наша модель, давайте выведем список самых позитивных и самых негативных комбинаций слов.
feature_to_coef = { word: coef for word, coef in zip(ngram_vectorizer.get_feature_names(), final.coef_[0]) }
for best_positive in sorted( feature_to_coef.items(), key=lambda x: x[1], reverse=True)[:30]:
print (best_positive)
print("\n\n")
for best_negative in sorted( feature_to_coef.items(), key=lambda x: x[1])[:30]:
print (best_negative)
('excellent', 0.2304771384408031)
('perfect', 0.18507025403127336)
('great', 0.17881801385386237)
('wonderful', 0.1607892578415082)
('amazing', 0.1522695033939524)
('superb', 0.1469592250797414)
('enjoyable', 0.1443147342881976)
('best', 0.13064243531024478)
('enjoyed', 0.12732761468660905)
('fun', 0.12671723863644624)
('today', 0.12183576138878806)
('brilliant', 0.12065189281303865)
('must see', 0.11754736841763254)
('fantastic', 0.11538150792001459)
('loved', 0.11334100478792107)
('liked', 0.1120056345033787)
('funniest', 0.11168721465694686)
('incredible', 0.1086310023776505)
('wonderfully', 0.10755457584821745)
('better than', 0.10678237215285466)
('rare', 0.10401813549409697)
('beautiful', 0.10363770375592474)
('bit', 0.10192527354469774)
('love', 0.10181871928579253)
('well worth', 0.10117934642913716)
('highly', 0.10095355976123757)
('job', 0.10068803599089889)
('watch it', 0.09981111740351185)
('recommended', 0.09814962326635371)
('moving', 0.09695428281825534)
('worst', -0.3595863580038929)
('awful', -0.25540099226328966)
('boring', -0.24045424661934411)
('waste', -0.23777958511405578)
('bad', -0.22229431752398504)
('poor', -0.20207930198349183)
('terrible', -0.19911693144858356)
('dull', -0.18248451183118236)
('disappointment', -0.17575626539613495)
('poorly', -0.17370341213920307)
('disappointing', -0.16780672219139375)
('unfortunately', -0.15749774958555066)
('stupid', -0.15416425001189243)
('horrible', -0.15405101621568124)
('worse', -0.1530418029462235)
('mess', -0.14794757332891825)
('nothing', -0.14007349875633826)
('lame', -0.13806269565344811)
('save', -0.13592458133307603)
('lacks', -0.13560833588335394)
('oh', -0.13244139301509864)
('avoid', -0.131782242803332)
('ridiculous', -0.13161464051063154)
('weak', -0.12800395819730007)
('annoying', -0.12648218010297776)
('fails', -0.12462870513833782)
('badly', -0.12273300745443444)
('script', -0.12270962568114398)
('not good', -0.12008064261879525)
('not worth', -0.11956611283710153)
Этот список должен навести вас на мысль, что искусственным интеллектом здесь и не пахнет. Хотя большинство слов, как и ожидалось, непосредственно описывающие отношение зрителя прилагательные, некоторые из них просто удивляют. Слово "today" ("сегодня") не несет совершенно никакой эмоциональной окраски, как и "bit" ("немного"), "job" (работа), "moving" ("двигаясь"), "oh" ("о!"), "avoid" ("избегать") и "script" ("сценарий"). Они попали в список просто потому, что случайно присутствовали во многих обзорах одного класса. Можно легко изобрести ругательный отзыв, который наша модель посчитает очень позитивным:
I have watched the love comedy today, and I highly disagree that it was a true comedy. No fun at all! Don't watch it!
Даже трехлетний ребенок не посчитает такой отзыв положительным, а вот наша модель посчитает. Потому что слова "love", "today", "highly", "fun" и "watch it" у нее ассоциируются с положительными оценками, а отрицательную окраску тут несут только слова "disagree" и "don't".
Профессионал машинного обучения скажет, что наша модель обучалась не тем признакам (features), которые нужны для уверенного распознавания смысла или хотя бы тональности текста. Наличие в тексте определенного слова (или даже последовательности слов) само по себе не является верным признаком, поскольку смысл каждого слова зависит от контекста. В нашем простом примере слово "love" использовалось не для обозначения отношения зрителя к фильму, а просто для описания жанра фильма ("любовная комедия"). Причастие "highly" само по себе не несет никакого смысла, а просто усиливает оценку следующих слов. Наконец, существуют отрицание и сарказм, способные перевернуть смысл даже самых позитивных слов.
Удивительно, что практически ни один исследователь не придавал последним словам обзора больше веса, чем первым. Пытаясь продемонстрировать свою беспристрастность, многие зрители сначала описывают те особенности фильма, которые противоречат их финальной оценке, и только в конце выносят итоговый вердикт. Например, "у этого фильма потрясающий состав актеров, актриса X, как всегда, прекрасно справилась с ролью, но сценарий настолько ужасен, что даже это не спасает фильм". (Кажется, я начинаю понимать, почему наша модель посчитала слово "сценарий" негативным! Зрители вспоминают о сценарии только для того, чтобы обругать его).
Нельзя забывать и о том, что далеко не все оценки зрителя имеют отношение к фильму! Для демонстрации предлагаю прочитать следующий отзыв:
Bromwell High is a cartoon comedy. It ran at the same time as some other programs about school life, such as "Teachers". My 35 years in the teaching profession lead me to believe that Bromwell High's satire is much closer to reality than is "Teachers". The scramble to survive financially, the insightful students who can see right through their pathetic teachers' pomp, the pettiness of the whole situation, all remind me of the schools I knew and their students. When I saw the episode in which a student repeatedly tried to burn down the school, I immediately recalled ......... at .......... High. A classic line: INSPECTOR: I'm here to sack one of your teachers. STUDENT: Welcome to Bromwell High. I expect that many adults of my age think that Bromwell High is far fetched. What a pity that it isn't!
Очевидно, что этот отзыв положительный, хотя на сегодняшний день я не знаю ни одной модели анализа тональности текста, способной это определить. Отзыв переполнен отрицательными эмоциями, которые относятся не к фильму, а к тяжелому положению американских учителей. Фильм же зрителю понравился именно потому, что верно показывает это тяжелое положение.
Многие устаревшие модели анализа тональности используют нейронные сети, а вместо n-грамм применяют несколько сверточных слоев, выделяющих из текста наиболее значимые комбинации слов, но это не приводит к существенному улучшению результата. Если вы изучаете не те признаки, которые реально определяют результат, ничего хорошего от такой модели ожидать не приходится.
Чтобы получить представление о признаках, выделяемых человеческим мозгом при анализе текста, достаточно вспомнить знаменитое предложение профессора Щербы: "Глокая куздра штеко кудланула бокра и курдячит бокрёнка". Если вы ни разу его не слышали, вспомните хотя бы стишок про Бармаглота из "Алисы в Зазеркалье":
Варкалось! Хливкие шорьки пырялись по наве,
И хрюкотали зелюки, как мюмзики в мове.

Человеческий мозг воспринимает "глокую куздру" примерно как: "ловкая пантера сильно толкнула кабана и терзает поросенка". Почему возникает именно такая ассоциация? Да потому, что мозг выделяет из текста огромное количество признаков и использует их все! Среди этих признаков:
- Морфологические. Строение фразы однозначно указывает, что <какое-то><существо><как-то воздействовало> на <взрослое существо другого вида> и <делает что-то> с <детенышем того же вида>.
- Фонетические. Фраза ни в коем случае не воспринимается как "добрая Лошадка поприветствовала Ежика и поздравляет Ежонка" именно потому, что глагол "кудланула" фонетически воспринимается как совершенное физическое воздействие, а глагол "курдячит" – как жестокое физическое воздействие, производимое в данный момент.
- Эмоциональные. Суффикс "-онок" ("-ёнок") в русском языке не зря называется уменьшительно-ласкательным. Мы сразу же проникаемся жалостью к несчастному бокренку, которого курдячат. С другой стороны, слово "куздра" – женского рода, а женский род в русском языке имеют только симпатичные виды существ (лиса, белка, выдра, рысь и т.д.)
- Жизненный опыт. Мы запоминаем огромное количество типовых языковых конструкций, с которыми сопоставляем новые тексты. Морфологические, фонетические и эмоциональные признаки заставляют нас выбрать из всего нашего жизненного опыта суровую картинку мира животных, на которой хищник убивает добычу.
Настоящее
2019 год не зря назвали годом NLP. Именно тогда появились модели на основе Трансформеров, которые навсегда вытеснили из обработки естественного языка модели, базирующиеся на RNN, простых нейронных сетях и тем более простые модели без нейронных сетей, вроде той, которую мы продемонстрировали. Описание принципов работы Трансформеров выходит за рамки статьи, поэтому я отправляю вас к публикации Джея Аламмара "Transformer в картинках" (оригинал и перевод на Хабре).

Инженеры Google создали BERT (Bidirectional Encoder Representations from Transformers) – модель, состоящую из большого количества слоев кодировщиков и декодировщиков на основе Трансформеров. Она была обучена на огромном массиве текста, содержащем практически все, что было когда-либо напечатано на английском языке. В результате BERT содержит практически полную модель языка, и, что наиболее важно, модели BERT выложены в открытый доступ. Каждый может встроить их в свои модели, не тратя огромных средств на обучение. Описание принципов работы BERT также выходит за рамки моей статьи, так что рекомендую прочитать статью Джея Аламмара "BERT, ELMo и прочие в картинках" (оригинал и перевод на Хабре).
Предварительно тренированные модели BERT можно использовать одним из трех способов:
- Без обучения. Вы добавляете к обученной модели BERT несколько дополнительных слоев, и обучаете только их. При этом время обучения редко превышает несколько минут, но точность модели оставляет желать лучшего.
- Дообучение (fine-tuning). Вы также добавляете несколько дополнительных слоев, но включаете слои BERT в обучаемые. Время дообучения обычно составляет несколько часов, и такие модели существенно превосходят модели без обучения.
- Переобучение (pre-training). Вы полностью переобучаете BERT на своих данных. Процесс переобучения займет несколько суток, а подготовка данных для него – намного больше. Как правило, переобучение производится для нового языка или набора языков.
Что дает использование BERT для нашей задачи анализа тональности текста? Во-первых, полная модель языка уже не кодирует каждое слово отдельно от остальных, а только в контексте всего предложения или абзаца. Это значит, что слово "bank" в контексте "river bank" будет иметь совсем не ту кодировку, которую получит это же слово в контексте "bank of Canada". Во-вторых, модель уже может распознать простейшие отрицания вроде "don't watch it". В-третьих, BERT при кодировании не удаляет ни стоп-слова, ни знаки препинания, то есть не теряет важную информацию – наоборот, некоторые слова при кодировании разбиваются на несколько частей!
Следующий пример использования BERT для нашей задачи анализа тональности взят из библиотеки ktrain – это ссылка на GitHub с полным кодом. Пример требует установленной библиотеки Tensorflow не ниже 2-й версии. Я запускал его в Jupyter Notebook и увеличил количество эпох обучения, поскольку предложенной по умолчанию одной эпохи было недостаточно.
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID";
os.environ["CUDA_VISIBLE_DEVICES"]="0";
import ktrain
from ktrain import text
# -- using Keras version: 2.2.4-tf
Теперь загрузим данные. Набор данных IMDb широко известен, так что его наверняка можно найти в каком-нибудь Интернет-репозитории, но вам будет полезно увидеть, как загрузить данные из произвольных папок на диске:
(x_train, y_train), (x_test, y_test), preproc = text.texts_from_folder('aclImdb',
maxlen=500,
preprocess_mode='bert',
train_test_names=['train', 'test'],
classes=['pos', 'neg'])
# -- detected encoding: utf-8
# -- preprocessing train...
# -- language: en
#
# -- done.
#
# -- preprocessing test...
# -- language: en
#
# -- done.
Теперь создадим нашу модель – текстовый классификатор на базе BERT. Для этого достаточно всего одной строки:
model = text.text_classifier('bert', (x_train, y_train) , preproc=preproc)
# -- Is Multi-Label? False
# -- maxlen is 500
# -- done.
ktrain предоставляет класс learner, в котором собраны все методы, необходимые для тренировки моделей. Один из основных методов – это поиск оптимальной скорости обучения (learning rate).
learner = ktrain.get_learner(model,
train_data=(x_train, y_train),
val_data=(x_test, y_test),
batch_size=6)
learner.lr_find()
# ...
# -- Please invoke the Learner.lr_plot() method to visually inspect the loss plot to
# -- help identify the maximal learning rate associated with falling loss.
learner.lr_plot()
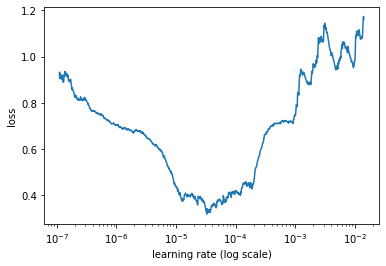
Осталось обучить нашу модель с найденной скоростью.
learner.fit_onecycle(2e-5, 5)
# -- begin training using onecycle policy with max lr of 2e-05...
# -- Train on 25000 samples, validate on 25000 samples
# -- Epoch 1/5
# -- 25000/25000 [==============================] - 2619s 105ms/sample - loss: 0.2612 - accuracy: 0.8880 - val_loss: 0.2205 - val_accuracy: 0.9132
# -- Epoch 2/5
# -- 25000/25000 [==============================] - 2614s 105ms/sample - loss: 0.1596 - accuracy: 0.9403 - val_loss: 0.1769 - val_accuracy: 0.9334
# -- Epoch 3/5
# -- 25000/25000 [==============================] - 2646s 106ms/sample - loss: 0.1057 - accuracy: 0.9631 - val_loss: 0.1772 - val_accuracy: 0.9335
# -- Epoch 4/5
# -- 25000/25000 [==============================] - 2607s 104ms/sample - loss: 0.0444 - accuracy: 0.9862 - val_loss: 0.2576 - val_accuracy: 0.9366
# -- Epoch 5/5
# -- 25000/25000 [==============================] - 2610s 104ms/sample - loss: 0.0117 - accuracy: 0.9966 - val_loss: 0.2565 - val_accuracy: 0.9419
Как видно из отчета, каждая эпоха обучения на моей 2080 Ti заняла около 45 минут, а все пять эпох – почти четыре часа. Это значит, что ktrain дообучает BERT, что и обеспечивает гораздо более высокую точность предсказания: 94.2%. Если вам кажется, что это ненамного больше, чем 90%, попробуйте взглянуть на результаты с другой стороны: устаревшая модель ошибается в 10% случаев, а современная – только в 5.8%. Почти вдвое реже!
Будущее

Как мы уже говорили, в будущем модели анализа тональности текста научатся выдавать не просто рейтинг всего текста (который на практике клиенту всегда легче поставить самому, чем писать отзыв), а полный отчет обо всех высказанных эмоциях клиента по отношению к объектам и понятиям, интересующим заказчика. Если речь все еще идет об отзывах на фильмы, заказчика может интересовать отношение зрителя к сценарию, режиссеру, оператору и актерам.
Как же это изменит мир? Ответом послужат всего два слова: рекомендательные системы. Именно там крутятся огромные деньги (поскольку практически все товары и услуги очень важно рекомендовать именно тем, кто потенциально может их купить), и именно там любая информация о предпочтениях каждого человека чрезвычайно ценна. В ближайшем будущем каждого из нас будут подстерегать сложнейшие системы, которые точно рассчитают, что если нам понравились книга X, фильм Y и актриса Z – то нам, скорее всего, понравится и новая коллекция костюмов от Q, которая сильно на любителя.
Уверен, что все технологии, необходимые для наступления этого будущего, есть уже сегодня. Ничто не мешает именно вам сделать его реальностью. Удачи!
Комментарии