

Каждый запрос к базе данных проходит через несколько важных этапов обработки. Давайте разберем этот процесс на примере запроса:
SELECT name, age FROM users WHERE city = 'New York';
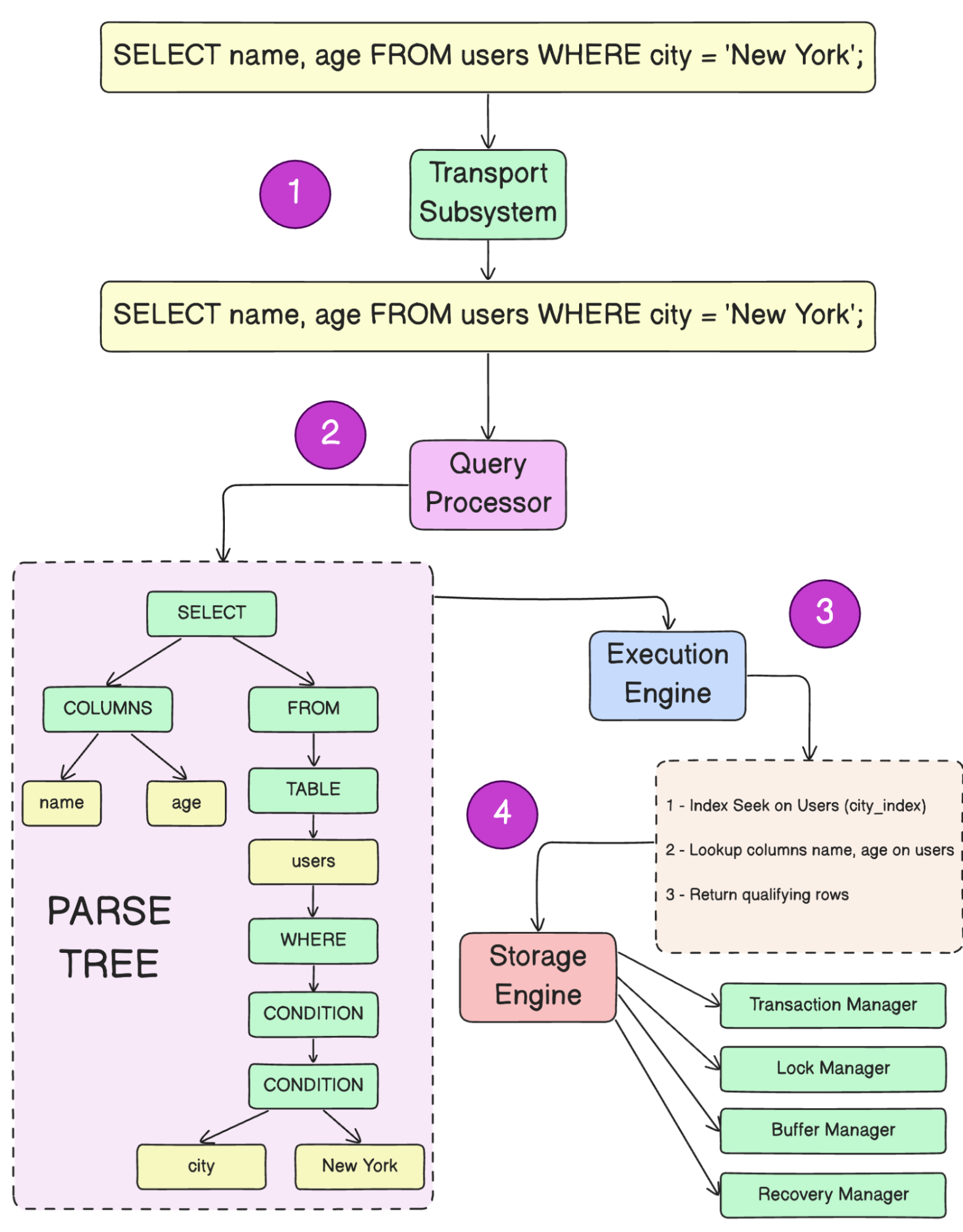
Шаг 1: Транспортная подсистема
Когда вы запускаете запрос, строка запроса сначала попадает в транспортную подсистему базы данных. Эта подсистема отвечает за управление соединением с клиентом и выполняет первоначальные проверки аутентификации и авторизации. Если все в порядке, запрос передается на следующий этап.
Шаг 2: Обработчик запросов
Запрос попадает в обработчик запросов (Query Processor), который состоит из двух основных компонентов:
- Парсер запроса (Query Parser). Он разбивает SQL-запрос на его части
(SELECT,FROM,WHEREи т. д.), проверяет синтаксические ошибки и создает дерево разбора (parse tree). - Оптимизатор запроса (Query Optimizer). После того как запрос разобран, оптимизатор проверяет его на семантические ошибки (например, существует ли таблица
"users"). Он также определяет наиболее эффективный способ выполнения запроса. В результате работы оптимизатора создается план выполнения (execution plan), который описывает, как именно будет выполнен запрос.
Шаг 3: Движок выполнения
План выполнения передается в движок выполнения (Execution Engine). Этот компонент координирует выполнение запроса, используя план, созданный на предыдущем шаге. Он вызывает хранилище данных (Storage Engine), выполняет шаги запроса и собирает результаты, чтобы вернуть их клиенту.
Шаг 4: Хранилище данных
Движок выполнения отправляет низкоуровневые запросы на чтение/запись в хранилище данных в соответствии с планом выполнения. Хранилище данных состоит из нескольких подсистем:
- Менеджер транзакций (Transaction Manager) обеспечивает выполнение запроса в рамках транзакции, чтобы гарантировать согласованность данных.
- Менеджер блокировок (Lock Manager) получает блокировки на таблице
"users", чтобы избежать конфликтов с другими запросами. - Менеджер буферов (Buffer Manager) проверяет, находятся ли нужные данные в памяти. Если их нет, он запрашивает их с диска и загружает в память.
- Менеджер восстановления (Recovery Manager) записывает операции в журнал для возможности отката или восстановления данных.
Когда все эти шаги выполнены, результат запроса (например, имена и возраст пользователей из города Нью-Йорк) передается обратно клиенту. Вот так и происходит обработка вашего SQL-запроса в базе данных 🙂.
Какой этап обработки запроса, по вашему мнению, чаще всего становится узким местом?
Комментарии