

Исследователи Google недавно опубликовали статью, названную "Big Bird: трансформеры для более длинных последовательностей".
В 2019-м году исследователи Google опубликовали BERT, который оказался одним из самых рациональных и эффективных алгоритмов со времен RankBrain. Судя по начальным результатам, BigBird обещает такой же успех!
В этой статье мы рассмотрим:
- Краткий обзор моделей на основе Трансформеров,
- Ограничения моделей на основе Трансформеров,
- Что такое BigBird и
- Потенциальные приложения BigBird.
Давайте начнем!
Краткий обзор моделей на основе Трансформеров
В обработке естественного языка (NLP) за последние пару лет произошла настоящая революция, и Трансформеры играли в ней основную роль. Здесь есть о чем рассказать.
Трансформеры – модели для обработки естественного языка, запущенные в 2017-м году, известные, в основном, повышением эффективности обработки и понимания последовательных данных вроде перевода и анализа текста.
В отличие от Рекуррентных Нейронных Сетей (RNN), обрабатывающих входные данные с начала до конца, Трансформеры обрабатывают входные данные параллельно, и, следовательно, существенно сокращают сложность вычислений.
BERT – одна из важнейших вех и достижений в NLP – это модель на основе Трансформеров с открытым кодом. Статья, представившая BERT, как и BigBird, была опубликована исследователями Google 11 октября 2018 г.
Bidirectional Encoder Representations from Transformers (BERT) – одна из самых продвинутых моделей на основе Трансформеров. Она предобучена на огромном количестве данных (наборов предварительного обучения) – BERT-Large была обучена более чем на 2500 миллионах слов.
Кроме того, BERT, с его открытым кодом, позволил каждому создать свою собственную систему ответов на вопросы. Это также способствовало ее широкой популярности.
Однако BERT – не единственная модель, предобученная на огромном контексте. Однако, в отличие от других моделей, она "глубоко двунаправленная". Это также одна из причин ее успеха и огромного количества приложений, которые ее используют.
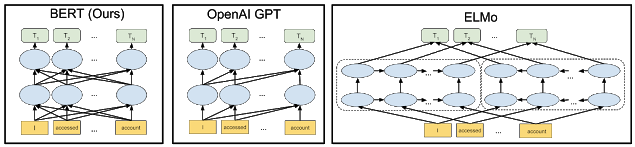
Результаты этой предобученной модели, несомненно, впечатляют. Она успешно применялась во многих задачах обработки последовательностей – обобщения, перевода и т.п. Даже Google использует BERT для понимания поисковых запросов пользователей.
Но, как и все модели на основе Трансформеров, BERT имеет свои ограничения.
Ограничения предыдущих моделей на основе Трансформеров
Несмотря на то, что модели на основе Трансформеров, особенно BERT, намного совершеннее и эффективнее, чем RNN, у них есть несколько ограничений.
BERT работает на основе механизма полного само-внимания (full self-attention). Это приводит к квадратичному росту требуемых вычислительной мощности и памяти при увеличении количества токенов. Максимальный размер входных данных составляет около 512 токенов, то есть эту модель нельзя использовать для длинных входов и задач вроде обобщения больших документов.
Фактически, это означает, что длинную строку придется разбить на несколько сегментов, прежде чем передавать их в модель. Эта фрагментация, разумеется, вызывает потерю контекстных связей, что ограничивает области применения модели.
Итак, что же такое BigBird, и чем она отличается от BERT и всех прочих моделей NLP на основе Трансформеров?
Представляем BigBird – Трансформер для более длинных последовательностей
Как упомянуто выше, одним из основных ограничений BERT и прочих NLP-моделей на основе Трансформеров было использование механизма полного само-внимания.
Это изменилось, когда исследователи Google опубликовали статью под названием "BigBird: Трансформеры для более длинных последовательностей".
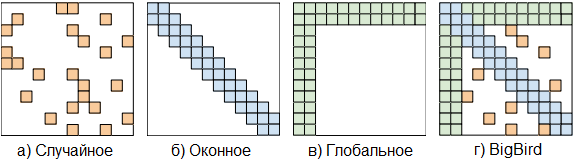
BigBird использует механизм разреженного само-внимания, позволяющий ей избавиться от квадратичной зависимости BERT, сохранив при этом качества моделей с полным само-вниманием. Исследователи также предоставили примеры того, как модели на основе сетей BigBird превосходят производительность прежних NLP-моделей и моделей генетики.
Прежде чем мы перейдем к возможным приложениям BigBird, давайте рассмотрим ее ключевые особенности.
Ключевые особенности BigBird
Вот несколько особенностей BigBird, которые делают ее лучше прежних моделей на основе Трансформеров:
- Механизм разреженного внимания
Предположим, что вам дали картину и попросили придумать для нее подходящее название. Вы начнете с нахождения основного объекта этой картины – например, "человек, бросающий мяч".
Нахождение этого основного объекта легко для нас, людей, но упрощение этого процесса для компьютерных систем – большое достижение в NLP. Механизмы внимания были придуманы как раз для упрощения этого процесса.
BigBird использует механизм разреженного внимания, позволяющий ей обрабатывать последовательности до 8 раз длиннее тех, которые могли обрабатывать модели BERT на компьютере с той же архитектурой.
В вышеупомянутой статье исследователи продемонстрировали, что механизм разреженного внимания, использованный в BigBird, не уступает по мощности механизму полного внимания (используемому в BERT). Кроме этого, они показали, что "разреженные энкодеры-декодеры обладают полнотой по Тьюрингу".
Проще говоря, BigBird использует механизм разреженного внимания, в котором механизм внимания применяется к отдельным токенам, в отличие от BERT, в которой внимание применяется сразу ко всему вводу!
- Может обрабатывать последовательности до 8 раз длиннее
Одна из ключевых особенностей BigBird – это ее способность обрабатывать последовательности до 8 раз длиннее, чем было возможно прежде. Команда ее исследователей разработала BigBird так, чтобы она удовлетворяла всем требованиям, предъявляемым к полным трансформерам вроде BERT.
Используя BigBird и его механизм разреженного внимания, команда исследователей сократила сложность с O(N2) (как было у BERT) до всего лишь O(N). Это значит, что максимальная длина входной последовательности увеличилась с 512 токенов до 4096 токенов (8 * 512).
Филип Фэм (Philip Pham), один из исследователей, создавших BigBird, сказал в Hacker News Discussion: "в большей части нашей статьи мы используем 4096, но могли бы использовать 16 тысяч и больше".
- Предобучена на больших наборах данных
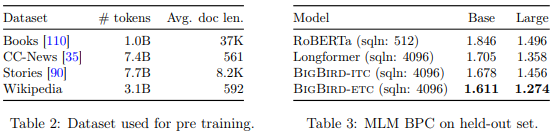
Исследователи Google использовали четыре разных набора данных для предобучения BigBird: Natural Questions, Trivia-QA, HotspotQA-Distractor и Wiki-Hop.
Хотя совокупный размер данных для предобучения BigBird не идет ни в какое сравнение с данными, на которых обучали GPT-3 (175 миллиардов параметров), Таблица 3 из статьи исследователей демонстрирует, что она работает лучше, чем RoBERTa (Robustly Optimized BERT Pretraining Approach) и Longformer – модель, похожая на BERT для длинных документов.
Когда пользователь попросил Филипа Фэма сравнить GPT-3 c BigBird, он сказал: "GPT-3 использует только длину последовательности 2048. BigBird – это просто механизм внимания, и его можно использовать в сочетании с GPT-3".
[Возможные] приложения BigBird
Статья, представившая BigBird, вышла совсем недавно – 28 июля 2020 г. Поэтому полный потенциал BigBird еще предстоит раскрыть.
Но вот несколько областей, в которых она может найти применение. Некоторые из этих применений были предложены создателями BigBird в исходной исследовательской статье.
- Обработка геномов
Использование глубокого обучения для обработки генетических данных постоянно расширяется. Кодировщик принимает фрагменты последовательности ДНК в качестве входных данных для задач вроде анализа метилирования, предсказания функциональных эффектов некодирующих вариантов и многих других.
Создатели BigBird говорят: "мы представляем новую область применения моделей, основанных на внимании, в которой длинные контексты имеют большое значение: выделение представлений контекста генетических последовательностей вроде ДНК".
Статья утверждает, что использование BigBird для предсказания области промотора позволило повысить точность итоговых предсказаний на целых 5%!
- Обобщение длинных документов и ответы на вопросы
Поскольку BigBird может обрабатывать последовательности в 8 раз длиннее, ее можно использовать для обобщения длинных документов и выделения ответов на вопросы. Создатели BigBird протестировали качество ее работы для этих задач и получили "передовые результаты".
- BigBird для поиска в Google
Google начала использовать BERT в октябре 2019-го, чтобы понимать поисковые запросы и изображать более подходящие для пользователя результаты. Конечная цель обновления поисковых алгоритмов Google – улучшенное понимание поисковых запросов.
Поскольку BigBird превосходит BERT в обработке естественного языка (NLP), имеет смысл внедрить эту новую и более эффективную модель, чтобы оптимизировать поисковые запросы Google.
- Разработка сетевых и мобильных приложений
Обработка естественного языка за последнее десятилетие добилась существенного прогресса. Уже предоставив платформу на базе GPT-3, способную превратить ваши простые предложения в функционирующее сетевое приложение (включая код), разработчики AI могут полностью изменить эту отрасль разработки программного обеспечения.
Поскольку BigBird может обрабатывать более длинные последовательности, чем GPT-3, ее можно использовать в комплексе с GPT-3 для быстрого и эффективного создания сетевых и мобильных приложений для вашего бизнеса.
Заключение
Хотя с BigBird связано многое, что еще предстоит исследовать, она, несомненно, способна полностью и навсегда революционизировать обработку естественного языка (NLP). А что вы думаете о BigBird и ее вкладе в будущее NLP?
Ссылки:
[1] Манзил Захир и его команда – "BigBird: Трансформеры для более длинных последовательностей" (2020).
[2] Джейкоб Девлин, Минг-Вей Чанг, Кентон Ли, Кристина Тутанова – "BERT: предварительное обучение глубоко двунаправленных Трансформеров для понимания естественного языка".
Комментарии