
Поговорим о том, что такое CUDA, как эта технология связана с NVIDIA и как ускоряет обработку данных вычислительной техникой.
Сложность вычислительных заданий требует резкого увеличения ресурсов и скорости компьютеров. Наиболее перспективным направлением повышения скорости решения задач является внедрение идей параллелизма в работу вычислительных систем.
Сегодня спроектированы и испытаны сотни различных компьютеров, которые используют в своей архитектуре тот или иной вид параллельной обработки данных. Основная сложность при проектировании параллельных программ – обеспечение правильной последовательности взаимодействия между разными вычислительными процессами, а также координация ресурсов, которые разделяются между ними.
Поговорим о CUDA
CUDA – это программно-аппаратная архитектура параллельных вычислений, позволяющая существенно увеличить вычислительную продуктивность благодаря использованию графических процессоров NVIDIA.
При использовании данной технологии необходимо знать следующие понятия:
- устройство (device) – сама видеокарта, графический процессор (GPU) – выполняет команды центрального процессора;
- хост (host) – центральный процессор (CPU) – запускает различные задания, выделяет память, etc.;
- ядро (kernel) – функция (задание), которая будет выполняться на GPU.
CUDA позволяет программистам реализовывать на специальном упрощенном диалекте языка C алгоритмы, которые используются в графических процессорах NVIDIA, и включать специальные функции в текст программы на C.
"Архитектура CUDA позволяет разработчику на свое усмотрение организовывать доступ к набору инструкций GPU и управлять его памятью."
Эта технология поддерживает несколько языков программирования. Среди них Java, Python и некоторые другие.
Этапы запуска программы на GPU или как все происходит
Рассмотрим, как происходит запуск программы на графическом процессоре:
- Хост выделяет необходимое количество памяти на устройстве.
- Хост копирует данные из своей памяти в память устройства.
- Хост запускает ядро на устройстве.
- Устройство исполняет это ядро.
- Хост копирует результаты из памяти устройства в свою память.
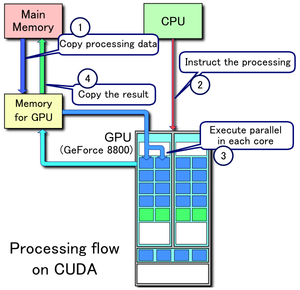
На рисунке изображены все перечисленные шаги запуска программы, кроме первого (источник).
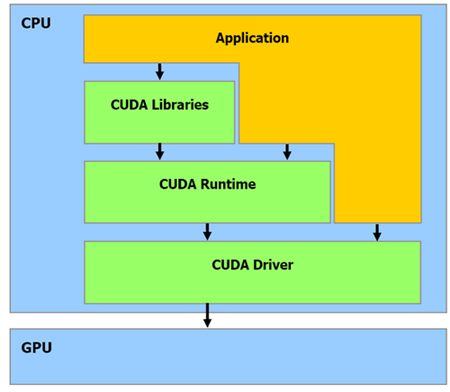
Как видно из рисунка, центральный процессор взаимодействует с графическим через CUDA Runtime API, CUDA Driver API и CUDA Libraries. Runtime и Driver API отличаются уровнем абстракции. Грубо говоря, первый вариант более высокого уровня в плане программирования, более абстрактный, а второй – напротив, более низкого (уровень драйвера).
В целом Runtime API является абстрактной оберткой Driver API. Во время программирования вы можете использовать любой из представленных вариантов. Из личного опыта: при использовании Driver API нужно написать немного «лишнего» кода + данный вариант сложнее.
Также необходимо понять одну важную вещь, которая впоследствии сэкономит вам время и нервы:
"Если отношение времени, потраченного на работу ядер, окажется меньше времени, потраченного на выделение памяти и запуск этих ядер, вы получите нулевую эффективность от использования GPU."
Давайте разберем написанное подробнее. Чтобы запустить некоторые задачи на GPU, необходимо потратить «немного» времени на выделение памяти, копирование результата, etc., поэтому не нужно выполнять на графическом процессоре легкие задания, которые на деле занимают буквально миллисекунды. Зачем выполнять на GPU то, с чем легко, а главное, быстрее справится центральный процессор?
У вас возникнет вопрос: «Тогда зачем вообще использовать GPU, если при этом приходится тратить драгоценное время на выделение памяти и другие ненужные вещи?». Это заблуждение, и со временем вы поймете, что CUDA – действительно мощная технология. Дальше разберемся, почему это так.
Аппаратная часть
Архитектура GPU построена несколько иначе, нежели CPU. Поскольку графические процессоры сперва использовались только для графических расчетов, которые допускают независимую параллельную обработку данных, то GPU и предназначены именно для параллельных вычислений. Он спроектирован таким образом, чтобы выполнять огромное количество потоков (элементарных параллельных процессов).
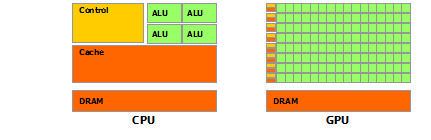
Как видно из картинки – в GPU есть много простых арифметически-логических устройств (АЛП), которые объединены в несколько групп и обладают общей памятью. Это помогает повысить продуктивность в вычислительных заданиях, но немного усложняет программирование.
«Для достижения лучшего ускорения необходимо продумывать стратегии доступа к памяти и учитывать аппаратные особенности.»
GPU ориентирован на выполнение программ с большим объемом данных и расчетов и представляет собой массив потоковых процессоров (Streaming Processor Array), что состоит из кластеров текстурных процессоров (Texture Processor Clusters, TPC). TPC в свою очередь состоит из набора мультипроцессоров (SM – Streaming Multi-processor), в каждом из которых несколько потоковых процессоров (SP – Streaming Processors) или ядер (в современных процессорах количество ядер превышает 1024).
Набор ядер каждого мультипроцессора работает по принципу SIMD (но с некоторым отличием) – реализация, которая позволяет группе процессоров, работающих параллельно, работать с различными данными, но при этом все они в любой момент времени должны выполнять одинаковую команду. Говоря проще, несколько потоков выполняют одно и то же задание.
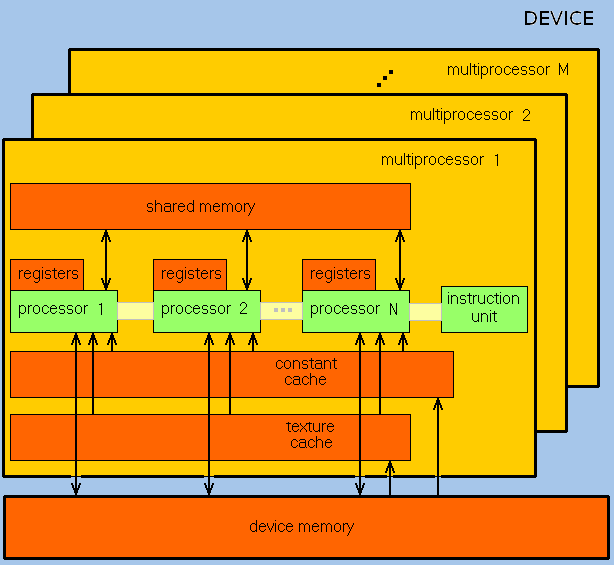
В результате GPU фактически стал устройством, которое реализует потоковую вычислительную модель (stream computing model): есть потоки входящих и исходящих данных, что состоят из одинаковых элементов, которые могут быть обработаны независимо друг от друга.

Вычислительные возможности
Продолжаем разбираться с CUDA. Каждая видеокарта обладает так называемыми compute capabilities – количественными характеристиками скорости выполнения определенных операций на графическом процессоре. Данное число показывает, насколько быстро видеокарта будет выполнять свою работу.
В NVIDIA эту характеристику обозначают Compute Capability Version. В таблице приведены некоторые видеокарты и соответствующие им вычислительные возможности:

Полный перечень можно посмотреть здесь. Compute Capability Version описывает множество параметров, среди которых: количество потоков на блок, максимальное количество блоков и потоков, размер warp, а также многое другое.
Потоки, блоки и сетки
CUDA использует большое количество отдельных потоков для расчетов. Все они группируются в иерархию – grid / block / thread.
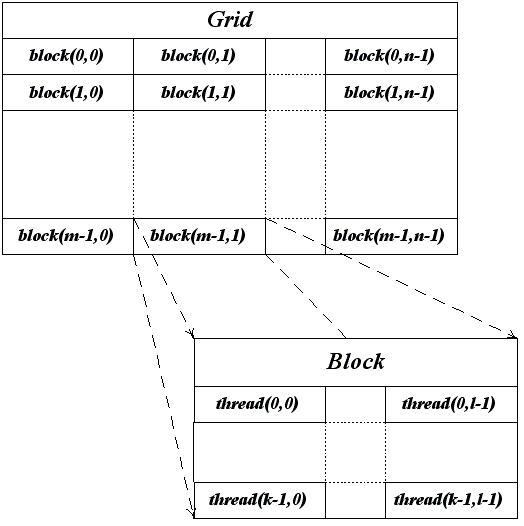
Верхний уровень – grid – отвечает ядру и объединяет все потоки, которые выполняет данное ядро. Grid – одномерный или двумерный массив блоков (block). Каждый блок (block) представляет собой полностью независимый набор скоординированных между собой потоков. Потоки из разных блоков не могут взаимодействовать.
Мы упоминали об отличии от SIMD-архитектуры. Есть такое понятие, как warp – группа из 32 потоков (в зависимости от архитектуры GPU, но почти всегда 32). Только потоки в рамках одной группы (warp) могут физически выполняться одновременно. Потоки разных варпов могут находиться на разных стадиях выполнения программы. Такой метод обработки данных обозначается термином SIMT (Single Instruction – Multiple Theads). Управление работой варпов выполняется на аппаратном уровне.
Почему иногда центральный процессор выполняет задания быстрее графического?
Выше уже было написано, что не стоит выполнять на GPU слишком простые задания. Чтобы понять, следует определить два термина:
- Задержка – это преимущественно время ожидания между запросом на какой-либо ресурс и получением доступа к данному ресурсу.
- Пропускная способность – количество операций, которые выполняются за единицу времени.
Таким образом, главный вопрос состоит в следующем: почему графический процессор иногда «тупит»? Объясняем на простом примере.
У нас есть 2 автомобиля:
- легковой фургон – скорость 120 км/ч, способен вместить 9 человек;
- автобус – скорость 90 км/ч, способен вместить 30 человек.
Если одна операция – это передвижение одного человека на определенное расстояние (пусть будет 1 км), то задержка (время, за которое один человек пройдет 1 км) для первого авто составит 3600/120 = 30 сек, а пропускная способность – 9/30 = 0,3. Для автобуса – 3600/90 = 40 сек и 30/40 = 0,75.
CPU – это фургон, а GPU – автобус: у него большая задержка, но также и большая пропускная способность. Если для вашего задания задержка каждой конкретной операции не так важна, как количество этих самых операций в секунду, то стоит рассмотреть использование GPU.
Выводы
Отличительными чертами GPU в сравнении с CPU являются:
- архитектура, максимально нацеленная на увеличение скорости расчета текстур и сложных графических объектов;
- предельная мощность типичного GPU намного больше, чем у CPU;
- благодаря специализированной конвейерной архитектуре GPU более эффективен в обработке графической информации, нежели центральный процессор.
Главный минус CUDA в том, что данная технология поддерживается только видеокартами NVIDIA без каких-либо альтернатив.
Графический процессор не всегда может дать ускорение при выполнении определенных алгоритмов. Поэтому перед использованием GPU для вычислений стоит хорошо подумать, а нужен ли он в данном случае. Вы можете использовать видеокарту для сложных вычислений: работа с графикой или изображениями, инженерные расчеты, криптографические задачи (майнинг), и т. д., но не используйте GPU для решения простых задач (разумеется, вы можете, но тогда эффективность будет равняться нулю).
Помните о задаче с фургоном и автобусом, а также не забывайте, что использование графического процессора гораздо вероятнее замедлит программу, нежели ускорит ее.
Комментарии