

Исследователи DeepSeek обнаружили, что модель R1-Zero во время обучения с подкреплением неожиданно достигла «момента озарения»: самостоятельно начала переоценивать свои первоначальные ответы, не получая при этом прямых указаний от человека. Этот эффект возник благодаря алгоритму Group Relative Policy Optimization (GRPO), который позволяет модели эффективно оптимизировать ответы без использования функции ценности (в отличие от Proximal Policy Optimization, PPO).
GRPO работает следующим образом:
- Модель создает несколько вариантов ответов.
- Каждый ответ оценивается по определенным критериям.
- Вычисляется средний балл для группы ответов.
- Ответы сравниваются со средним баллом.
- Модель учится предпочитать более качественные ответы.
GRPO может заставить модель не просто выдавать ответы, но автоматически строить логический ход рассуждений, даже если исходные обучающие данные содержат только вопрос и ответ, но не сам процесс размышления.
Пример: представим, что мы хотим научить модель решать простые задачки:
- «Сколько будет 1 + 1?» → [Ход рассуждений] → «Ответ: 2»
- «Сколько будет 2 + 2?» → [Ход рассуждений] → «Ответ: 4»

Раньше, чтобы модель научилась показывать ход своих рассуждений, нужно было:
- Собрать огромное количество примеров, где подробно расписан каждый шаг решения.
- Обучить модель на этих примерах.
Подход с GRPO гораздо проще – не нужно собирать примеры с расписанным ходом рассуждений, вместо этого создаются функции награды, которые оценивают ответы модели, например:
- За правильный ответ: +1 балл
- За ошибку: -0.1 балла
И так далее. В результате модель сама учится выстраивать логические цепочки рассуждений, потому что она:
- Получает больше «наград» за качественные ответы.
- Постепенно учится показывать ход своих мыслей.
- Делает это без готовых примеров того, как должен выглядеть процесс рассуждения.
Это похоже на то, как мы учим ребенка решать задачи, не просто давая ему готовые решения, а поощряя его за правильные ответы и логичные рассуждения.
Применение и реализация GRPO
Метод GRPO полезен в задачах, где модель должна не просто выдавать ответ, а объяснять свои рассуждения. Например:
- В праве, медицине и любых других областях, где требуется обоснование решений.
- Когда у нас есть входные и выходные данные (например, вопросы и ответы), но нет записанного хода размышлений.
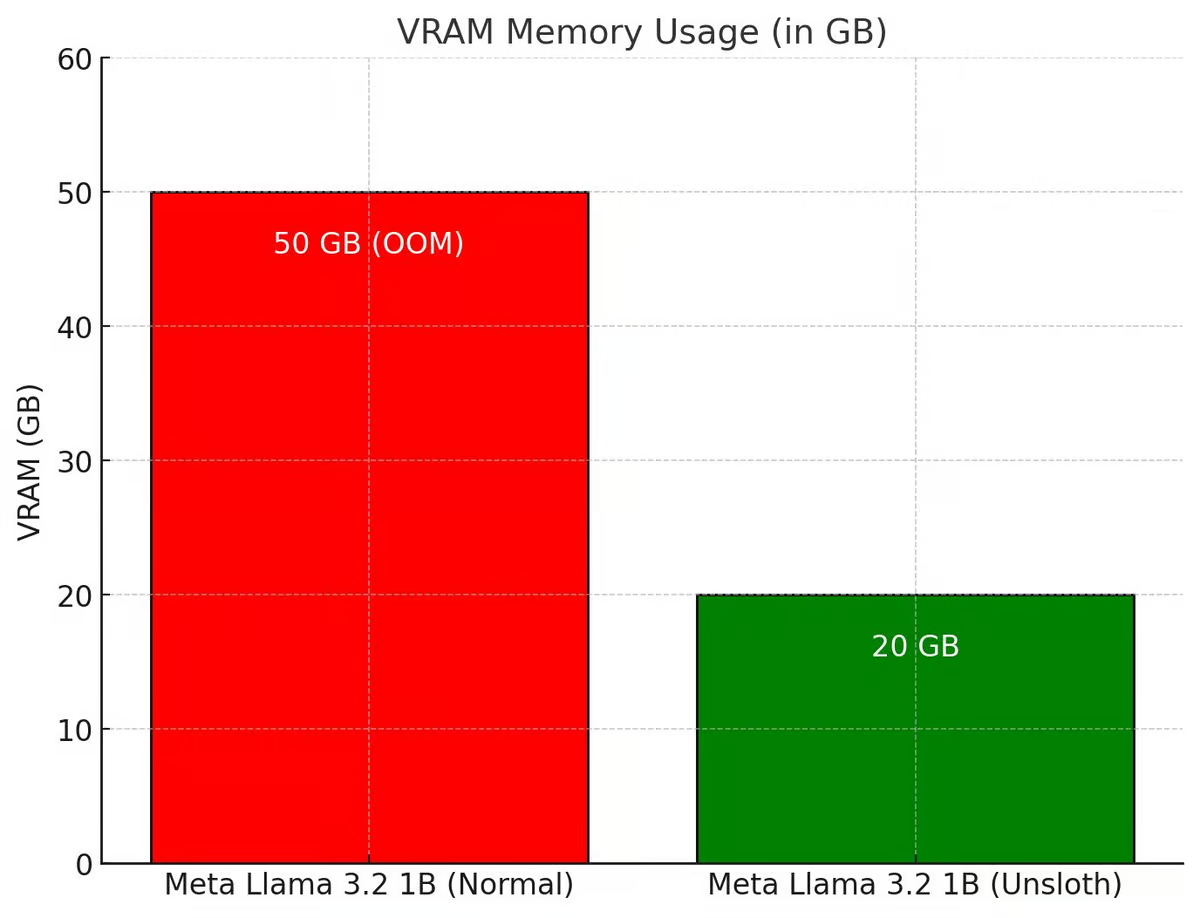
Единственный недостаток GRPO до недавних пор заключался в том, что для использования этого метода требовался внушительный объем видеопамяти.
Как Unsloth улучшил GRPO
Раньше для достижения «момента озарения» на модели Qwen2.5 (1.5B) требовалось две A100 (160 Гб VRAM), но разработчикам Unsloth удалось значительно оптимизировала процесс GRPO, сделав его:
- В 5 раз менее требовательным к видеопамяти (сейчас экономия составляет 80% VRAM по сравнению с HuggingFace + FA2).
- Доступным для локального обучения на видеокартах от 7 Гб VRAM.
- Совместимым с QLoRA и LoRA, а не только с полным дообучением.
Кроме того, разработчики Unsloth добавили поддержку OnlineDPO, PPO и RLOO.
Как использовать GRPO с Unsloth
Прежде всего убедитесь, что у вас установлен пакет diffusers – он необходим для работы GRPO с Unsloth:
pip install diffusers
Нюнсы и продолжительность обучения:
- Ждите как минимум 300 шагов, прежде чем награда начнет увеличиваться.
- Используйте последнюю версию vLLM.
- В примере на Colab модель обучалась всего 1 час, поэтому результаты были не лучшими.
- Чтобы получить хорошие результаты, рекомендуется обучать не менее 12 часов. Однако это не обязательно – можно остановиться в любой момент.
Какие модели подходят для GRPO:
- Рекомендуется применять GRPO к моделям от 1.5B параметров и выше, так как меньшие модели могут не генерировать токены размышления.
- Если используете базовую модель, убедитесь, что у вас есть шаблон диалога.
В Unsloth есть встроенный трекер потерь для GRPO, так что внешние инструменты вроде wandb не нужны.
Интеграция с vLLM
Unsloth поддерживает использование vLLM прямо в процессе дообучения модели – можно одновременно обучать модель и использовать ее для генерации текста. Скорость впечатляет – на видеокарте A100 (40 Гб) вывод достигает 4000 токенов в секунду, а на более слабой Tesla T4 (доступна бесплатно в Google Colab) можно получить 300 токенов в секунду.
Раньше совместное использование vLLM и Unsloth вызывало двойную загрузку памяти. Теперь проблему решили, и это дает существенную экономию:
- Для модели Llama 3.1 8B экономится около 5 Гб видеопамяти, а для Llama 3.2 3B – примерно 3 Гб VRAM.
- Большая модель Llama 3.3 70B требует 40 Гб видеопамяти для весов. Без оптимизации для работы с vLLM потребовалось бы больше 80 Гб, а после оптимизации все работает на видеокарте с 48 Гб памяти.
Как использовать Unsloth с vLLM:
pip install unsloth vllm
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-3B-Instruct",
fast_inference = True,
)
model.fast_generate(["Hello!"])
Особенности:
- vLLM теперь поддерживает динамическое 4-битное квантование в Unsloth. Это похоже на 1.58-битное динамическое квантование (Dynamic R1 GGUF), где одни слои модели используют 4-битное представление, а другие – 16-битное. Такой подход повышает точность, сохраняя компактный размер модели.
- Реализован автоматический подбор параметров для эффективного использования RAM, VRAM и максимальной производительности (например, количества предварительно загружаемых токенов, максимального числа последовательностей и т. д.)
- LoRA-адаптеры загружаются в vLLM без записи на диск, что ускоряет обучение GRPO в 1,5 раза.
- По умолчанию в vLLM включены оптимизация -O3 (повышает скорость выполнения) и кэширование префиксов для быстрого инференса. Flashinfer на старых GPU оказался на 10% медленнее, чем стандартный vLLM. FP8 KV-кэш замедляет работу на 10%, но при этом вдвое увеличивает пропускную способность.
В заключение
GRPO – это мощный метод, позволяющий моделям самостоятельно улучшать свои ответы и строить рассуждения, а Unsloth делает его доступным для маломощных GPU. Бесплатный блокнот для GRPO с Llama 3.1 (8B) есть в Colab, ссылки на блокноты для других моделей (включая Phi-4) можно найти в документации.
🔬 Глубокое погружение в ML: от основ до практики
Погрузитесь в мир машинного обучения с практическим курсом от специалиста Stripe: от базовых алгоритмов до нейросетей, с акцентом на реальные бизнес-задачи и постоянной поддержкой экспертов.
Курс охватывает ключевые направления машинного обучения:
- Ансамблевые методы и древовидные модели
- Системы рекомендаций
- Основы архитектуры нейросетей
Особенности программы:
- Сочетание теории и практики
- Доступное объяснение сложных концепций
- Реальные бизнес-кейсы
- Постоянный доступ к материалам
Комментарии