
21 урок, который извлек ведущий аналитик Национального банка Канады из курса по глубокому машинному обучению, от Andrew Ng.
Урок 1: Почему глубокое обучение нейронных сетей сейчас на взлете?
Курс по глубокому машинному обучению начинается с того, что 90% всех данных для обучения сетей были собраны за последние 2 года. Глубокие нейронные сети (Deep neural networks или DNN) способны использовать очень большой объем данных. В результате DNN справляются с работой лучше, чем небольшие нейронные сети и традиционные алгоритмы обучения.
Кроме того, существует ряд алгоритмических нововведений, которые позволили обучать DNN намного быстрее. Например, переход от сигмоиды к функции активации RELU оказал огромное влияние на процедуры оптимизации, такие как градиентный спуск. Благодаря этому, исследователи стали быстрее переходить от идеи к реализации, что привело к еще большему количеству инноваций.
Урок 2: Векторизация в глубоком обучении
Курс отлично объясняет важность векторизованного кода в Python. Домашние задания курса предоставляют шаблонный векторный код, который легко можно перенести в свое приложение.
Урок 3: Понимание DNN
В начале курса вы окунетесь в numpy с нуля. В процессе обучения вы получите понимание внутренней работы каркасов более высокого уровня, таких как TensorFlow и Keras.
Урок 4: Зачем нужны глубокие представления
Курс дает интуитивное понимание аспекта наслаивания DNN. Например, при распознании лиц ранние слои группируют грани в контуры лица, а более поздние слои используют грани для формирования его частей (например, носа, глаз, рта и т. д.). Затем используются дополнительные слои и части лица сходятся вместе, чтобы идентифицировать человека. Также объясняется идея теории схем, которая говорит о том, что существуют функции, которые требуют экспоненциального количества скрытых разделов для соответствия предоставляемым данным в неглубокой сети.
Урок 5: Инструменты для устранения смещения и разницы
Автор курса объясняет шаги, которые необходимо предпринять исследователю для выявления и устранения проблем, связанных со смещением и дисперсией. Он также упоминает о «компромиссных» решениях между смещением и дисперсией: в эпоху современного глубокого обучения существуют инструменты для решения каждой этой проблемы отдельно, поэтому прибегать к компромиссам не требуется.
Урок 6: Понимание упорядоченности
Почему термин «штраф», добавленный в функцию затрат, уменьшает эффекты дисперсии? Первая догадка, которая здесь возникает, заключается в том, что это заставляет весовые матрицы быть ближе к нулю, создавая более «линейную» функцию. В данном курсе дается еще одна интерпретация, включающая функцию активации tanh: меньшие весовые матрицы создают меньшие выходы, которые централизуют выходы вокруг линейного участка tanh-функции.
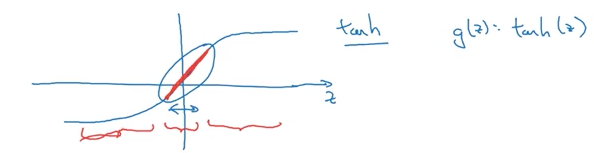
tanh-функция активации
Курс по глубокому машинному обучению также дает интересное интуитивное понимание отсева. Поскольку отсев случайным образом убивает связи, нейрон стимулируется распределять вес более равномерно среди своих родителей. Распределяя вес, он имеет тенденцию к уменьшению квадрата нормы веса.
С точки зрения конкретного нейрона
Это также объясняет, что отсев – это не что иное, как адаптивная форма L2-регуляции, и что оба метода имеют схожие эффекты.
Урок 7: Почему нормализация работает?
Нормализация имеет тенденцию увеличивать производительность процедуры оптимизации путем формирования контурных графиков. Пример такой итерации – градиентный спуск на нормированном и ненормированном контурном графике.
Урок 8: Важность инициализации
Слабая инициализация параметров может привести к исчезновению или разнесению градиентов. Существует несколько методов для борьбы с этими проблемами. Основная идея состоит в том, чтобы гарантировать, что весовые матрицы каждого слоя имеют дисперсию около 1.
Урок 9: Почему используется малый пакетный градиентный спуск?
На применении контурных графиков объясняется компромисс между малыми и большими размерами пакетов. Больший размер пакета влияет на итерацию, уменьшая ее скорость, в то время как меньший размер позволяет быстрее прогрессировать, но не может дать тех же гарантий относительно конвергенции. Лучший подход здесь – это сделать что-то среднее, что позволит прогрессировать достаточно быстро, в сравнении с одновременной обработкой целого набора данных, используя при этом методы векторизации.
Урок 10: Глубокому машинному обучению понимание методов оптимизации
Методы, такие как импульс и RMSprop, позволяют градиентному спуску ослабить его путь к минимуму. В курсе эти методы связываются вместе, чтобы объяснить известную процедуру оптимизации Адама.
Урок 11: Понимание базового бэкенда TensorFlow
В курсе объясняется, как реализовать нейронную сеть с помощью TensorFlow, а также объясняются некоторые методы оптимизации. Одно из домашних заданий – внедрить выпадение и L2-регуляризацию с использованием TensorFlow. Это укрепляет понимание бэкенд-процессов.
Урок 12: Ортогонализация
Курс по глубокому машинному обучению поднимает обсуждение важности ортогонализации. Основная идея здесь в том, что вам может понадобиться реализовать элементы управления таким образом, чтобы они влияли только на один компонент производительности алгоритмов за раз. Например, для устранения проблем смещения можно использовать более крупную сеть или более надежные методы оптимизации. Примером элемента управления, который не имеет ортогонализации, является ранняя остановка оптимизации.
Урок 13: Важность единого показателя оценки качества
Автор подчеркивает важность выбора единого показателя для оценки вашего алгоритма. Менять оценочную метрику в процессе разработки можно только если конечная цель изменится. Как пример приводится определение порнографических фотографий в приложении для классификации кошек.
Урок 14: Наборы данных для тестирования и разработки
Всегда необходимо убедиться, что наборы для разработки и тестирования имеют одинаковое распределение. Это гарантирует, что ваша команда будет правильно направлена во время процесса итерации. Это также означает, что, если вы решите исправить неверно маркированные данные в своем тестовом наборе, вы должны будете исправить помеченные данные и в наборе для разработки.
Урок 15: Работа с различными наборами для обучения, тестирования и разработки
У разработчиков могут быть разные наборы данных для разных целей. Оценочная метрика была должна вычисляться на примерах, которые вам действительно интересны. Например, вы можете использовать данные, которые не имеют отношения к вашей задаче для обучения, но вы не хотите, чтобы оценка работы алгоритма проводилась по этим примерам – это просто позволит настроить ваш алгоритм для работы с гораздо большим количеством данных. Эмпирически доказано, что этот подход дает лучшую производительность во многих случаях.
Урок 16: Размеры наборов
Руководящие принципы для определения размеров наборов данных для тренировки, разработки и тестирования сильно изменились в эпоху DNN. Для очень большого набора данных необходимо использовать разделение на 98/1/1 или даже 99 /0,5 /0,5 (в процентном соотношении). Это связано с тем, что наборы для разработки и тестов просто должны быть достаточно большими, чтобы обеспечить доверительные интервалы, предоставленные вашей командой. Поэтому, если вы работаете с выборкой их 10 миллионов учебных примеров, то, возможно, 100 тысяч из них (1% данных) как раз и есть достаточная выборка для этой цели.
Урок 17: Приближение оптимальной ошибки Байеса
Производительность человеческого уровня может использоваться для замещения ошибки Байеса в некоторых приложениях. Например, для таких задач, как распознавание видеопотока и звука, ошибка уровня человека будет очень близка к Байесовской оценке решения. Это позволит количественно оценить недопустимые смещения в вашей модели. Без эталонных тестов, таких как ошибка Байеса, трудно понять дисперсию и избежать проблем смещения в вашей нейронной сети.
Урок 18: Анализ ошибок
Основная идея заключается в том, чтобы вручную отметить ошибочные примеры и сосредоточить свои усилия на поиске ошибки, которая вносит наибольший вклад в ваши неверно отмеченные данные.
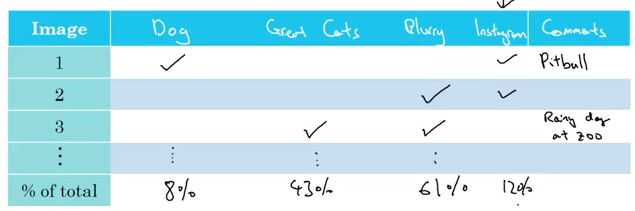
Анализ ошибок в приложении для распознания кошек
Например, в распознавании кошки размытые изображения вносят наибольший вклад в ошибки. Такой анализ чувствительности позволяет увидеть, сколько понадобится усилий для уменьшения общих ошибок. Исправление размытых изображений является чрезвычайно сложной задачей, в то время как другие ошибки очевидны и их легко исправить. Как чувствительность, так и приблизительная работа будут учитываться в процессе принятия решений сетью.
Урок 19: Когда использовать передачу обучения?
Передача обучения позволяет передавать знания из одной модели в другую. Например, вы можете перенести знания в области распознавания образов из приложения для распознавания кошек в рентгенологию. Реализация передачи обучения включает в себя переобучение последних нескольких слоев сети, которые используются для похожей области применения с гораздо большим количеством данных. Таким образом, передача обучения работает, когда обе задачи имеют одни и те же функции ввода и когда задача, которой вы пытаетесь обучить сеть, имеет гораздо больше данных, чем задача, на которой вы ее тренировали.
Урок 20: Когда использовать многозадачное обучение?
Многозадачное обучение подразумевает, что нейронная сеть одновременно изучает несколько задач (в отличие привычного подхода «одна сеть – одна задача»). Этот подход работает хорошо, когда набор задач выгодно совмещать с использованием низкоуровневых функций и когда объем данных для каждой задачи одинаков по величине.
Урок 21: Когда использовать сквозное глубокое обучение?
Курс по глубокому машинному обучению заканчивается этим уроком. Сквозное глубокое обучение требует нескольких этапов обработки и объединяет их в одной нейронной сети. Это позволяет данным говорить самим за себя, без отклонений, которые демонстрируют люди в процедурах оптимизации. Таким образом, этот подход оптимален, когда имеется достаточно данных и необходимо исключить ручную выборку с участием человека.
Комментарии