

Публикация представляет собой незначительно сокращенный перевод статьи Кристиана Иванчича Data Version Control With Python and DVC.
Машинное обучение и наука о данных сопряжены с рядом задач, отличающихся от традиционной разработки программного обеспечения. Так, системы управления версиями помогают разработчикам контролировать изменения исходного кода, однако управление версиями датасетов, изменения в моделях и наборах данных, отлажено не столь хорошо.
В этом руководстве мы рассмотрим следующие вопросы:
- как использовать инструмент под названием DVC для решения некоторых из этих проблем;
- как корректно отслеживать и редактировать наборы данных и модели;
- как совместно использовать одну систему с товарищами по команде;
- как делать воспроизводимые эксперименты с разными моделями ML.
Что такое система управления версиями данных
В традиционной разработке программного обеспечения разработчикам приходится взаимодействовать с несколькими версиями одного и того же кода. Чтобы предотвратить путаницу и ошибки, разработчики используют системы управления версиями, например, Git.
В системе управления версиями есть центральный репозиторий кода, представляющий текущее состояние проекта. Можно сделать копию проекта, внести изменения и запросить их добавление в следующей официальной версии. В результате запроса код проверяется и тестируется, пока не будет выпущен.
В проектах, связанных с разработкой, такие циклы повторяются по многу раз в день. Но в мире Data Science подобные соглашения и стандарты пока не закрепились. Наличие систем, позволяющих людям быстро продолжить с того места, на котором остановились другие, повысило бы скорость и качество получаемых результатов. Это помогло бы прозрачно управлять данными, эффективно проводить эксперименты и сотрудничать с другими людьми и командами.
Инструмент, помогающий исследователям управлять данными и осуществлять воспроизводимые эксперименты – DVC (сокр. от Data Version Control).
Что такое DVC
DVC – это написанный на Python инструмент командной строки, который работает совместно с Git, а также имитирует команды и рабочие процессы Git, перенося аналогичные подходы на работу с данными. Фактически команды git и dvc используются вместе – одна за другой. В то время как Git применяется для хранения версий кода, DVC проводит аналогичную работу с файлами моделей и датасетов.
Git может хранить код как локально, так и на Bitbucket, GitHub или GitLab. Аналогичным образом DVC позволяет использовать для хранения данных и моделей удаленный репозиторий. Можно создать локальную копию удаленного репозитория, изменить файлы, а затем загрузить свои изменения, чтобы поделиться ими с командой.
Удаленный репозиторий может находиться на вашем рабочем компьютере или в облаке, например, в AWS, GCP или Azure.
В процессе работы в удаленном репозитории создается dvc-файл – небольшой текстовый файл с описанием текущего состояния файлов данных. Благодаря небольшому размеру он может храниться вместе с программным кодом, например, на GitHub.
Далее мы на практике изучим наиболее важные особенности DVC.
Настраиваем рабочую среду DVC
В этом руководстве мы рассмотрим, как использовать DVC, попрактиковавшись на примере работы с датасетом фотографий. Мы даже обучим ML-модель распознавания объектов. Для работы с примерами в системе должны быть установлены Python 3 и Git.
DVC – это инструмент командной строки. Если вы пользователь Windows, ознакомьтесь с разделом «Запуск DVC в Windows» (англ.).
Чтобы подготовить рабочую среду, нам нужно выполнить следующее:
- Создать и активировать виртуальное окружение.
- Установить DVC и библиотеки Python.
- Сделать форк и клонировать GitHub-репозиторий с кодом.
- Загрузить набор данных для использования в примерах.
Вы можете использовать любой менеджер пакетов и окружений. В этом руководстве мы используем conda, поскольку он отлично поддерживает инструменты для анализа данных и машинного обучения. Чтобы создать и активировать виртуальную среду, откройте интерфейс командной строки и введите следующую команду:
conda create --name dvc python=3.8.2 -y
Команда create создаст виртуальную среду. Флаг --name дает имя среде – в приведенном примере – dvc. Аргумент python позволяет выбрать версию Python, которую мы хотим установить в среде. Флаг -y автоматически ответит Yes на все вопросы об установке библиотек.
Как только всё установлено, активируем среду:
conda activate dvc
Теперь у нас есть среда Python, независимая от установленных в операционной системе библиотек Python. В нее мы установим внешние библиотеки:
dvc– главный герой;scikit-learn– библиотека для обучения моделей;scikit-image– библиотека обработки изображений, которую мы будем использовать для подготовки данных;pandas– библиотека анализа данных, представляющая данные в виде таблиц;numpy– библиотека, добавляющая поддержку многомерных данных.
Их тоже можно установить с помощью conda:
conda config --add channels conda-forge
conda install dvc scikit-learn scikit-image pandas numpy
В качестве альтернативы можно использовать установщик pip:
python -m pip install dvc scikit-learn scikit-image pandas numpy
Теперь сделаем форк репозитория Data Version Control Tutorial. На странице репозитория нажмите Fork в правом верхнем углу экрана и выберите во всплывающем окне вашу учетную запись.
Далее клонируем форк на компьютер с помощью git clone и переходим в папку репозитория (не забудьте поменять YourUsername на имя вашего аккаунта на GitHub):
git clone https://github.com/YourUsername/data-version-control
cd data-version-control
Структура репозитория выглядит следующим образом:
data-version-control/
|
├── data/
│ ├── prepared/
│ └── raw/
|
├── metrics/
├── model/
└── src/
├── evaluate.py
├── prepare.py
└── train.py
В репозитории шесть каталогов:
src/– для исходного кода;data/– для всех версий датасетов;data/raw/– для данных, полученных из внешнего источника;data/prepare/– для данных, измененных внутри;model/– для моделей машинного обучения;data/metrics/– для отслеживания показателей производительности моделей.
Каталог src/ уже содержит три файла Python:
prepare.py– код подготовки данных для обучения;train.py– код обучения модели;evalueate.py– код оценки результатов обучения модели.
Набор данных для обучения
Последний шаг в подготовке – получить пример набора данных, который мы можем использовать для практики DVC. Пример с изображениями подходит для этого лучше всего: управление множеством крупных файлов – это то, чем отличается DVC. Мы будем использовать набор данных Imagenette компании fastai.
Imagenette – это подмножество датасета ImageNet, используемого в качестве эталонного набора данных в статьях по машинному обучению. ImageNet слишком велик, чтобы использовать его в качестве примера, поэтому мы возьмем его подмножество Imagenette. Перейдите на GitHub-страницу Imagenette и нажмите ссылку для загрузки 160 px download.
Набор данных сохранен в виде tar-архива. Размер файла – порядка 100 Мб. Пользователи Mac могут извлечь файлы, дважды щелкнув архив в Finder. Линуксоиды могут распаковать его с помощью команды tar. Пользователям Windows потребуется установить инструмент для распаковки tar-файлов, например, 7-zip.
Набор данных структурирован определенным образом. В нем есть две основные папки:
train/– изображения для обучения модели.val/– изображения для валидации.
Каждое изображение имеет связанный с ним класс, описывающий, что на нем изображено. Чтобы решить задачу классификации, необходимо обучить модель, которая сможет точно определять класс изображения.
Каталоги train/ и val/ содержат несколько папок. Каждая папка соответствует одному из 10 классов:
- Линь (вид лучеперых рыб)
- Английский спрингер-спаниель (порода собак)
- Кассетный проигрыватель
- Цепная пила
- Церковь
- Валторна
- Мусоровоз
- Топливораздаточная колонка
- Мячик для гольфа
- Парашют
Для простоты и скорости в руководстве мы будем обучать модель, используя лишь два последних класса. После обучения модель должна сообщать, является ли то или иное изображение мячом для гольфа или фотографией парашюта. Такую задачу, когда модель выбирает между двумя типами объектов, называют бинарной (двоичной) классификацией.
Переместим папки train/ и val/ в репозиторий data-version-control в каталог data/raw/. Структура репозитория будет выглядеть так:
data-version-control/
|
├── data/
│ ├── prepared/
│ └── raw/
│ ├── train/
│ │ ├── n01440764/
│ │ ├── n02102040/
│ │ ├── n02979186/
│ │ ├── n03000684/
│ │ ├── n03028079/
│ │ ├── n03394916/
│ │ ├── n03417042/
│ │ ├── n03425413/
│ │ ├── n03445777/
│ │ └── n03888257/
| |
│ └── val/
│ ├── n01440764/
│ ├── n02102040/
│ ├── n02979186/
│ ├── n03000684/
│ ├── n03028079/
│ ├── n03394916/
│ ├── n03417042/
│ ├── n03425413/
│ ├── n03445777/
│ └── n03888257/
|
├── metrics/
├── model/
└── src/
├── evaluate.py
├── prepare.py
└── train.py
Мы завершили настройку и готовы экспериментировать с DVC.
Базовый рабочий процесс DVC
В этом разделе мы увидим, как DVC в тандеме с Git позволяет управлять и кодом, и данными.
Для начала переключимся на ветку нашего первого эксперимента:
git checkout -b "first_experiment"
git checkout изменяет текущую ветку, а переключатель -b сообщает Git, что этой ветки не существовало ранее и ее следует создать.
Далее нужно инициализировать DVC. Предварительно нужно убедиться, что мы находимся в папке верхнего уровня репозитория. Далее запускаем команду dvc init:
dvc init
Эта команда приведет к созданию папки .dvc, в которой хранится информация о конфигурации – аналогично тому, как каталог .git содержит данные Git.
dvc config core.analytics falseТеперь нам нужно создать удаленное хранилище файлов данных и моделей, контролируемых DVC. Пока что для обучения это может быть просто другая папка в вашей системе. Создадим каталог за пределами репозитория data-version-control/ и назовем его dvc_remote.
Вернемся в репозиторий data-version-control/ и укажем DVC, где находится удаленное хранилище:
dvc remote add -d remote_storage путь_к_dvc_remote
Теперь DVC знает, где хранить резервную копию данных и моделей. Команда dvc remote add сохраняет местоположение удаленного хранилища и называет его remote_storage. Ключ -d сообщает DVC, что это удаленное хранилище по умолчанию (default). Потом можно добавить другие удаленные хранилища и переключаться между ними.
Внутри папки .dvc находится файл config, в котором хранится информация о конфигурации репозитория:
[core]
analytics = false
remote = remote_storage
['remote "remote_storage"']
url = /path/to/your/remote_storage
Основное практическое правило, которому мы должны следовать, заключается в том, что небольшие файлы отправляются на GitHub, а большие – в удаленное хранилище DVC.
Отслеживание файлов с DVC и Git
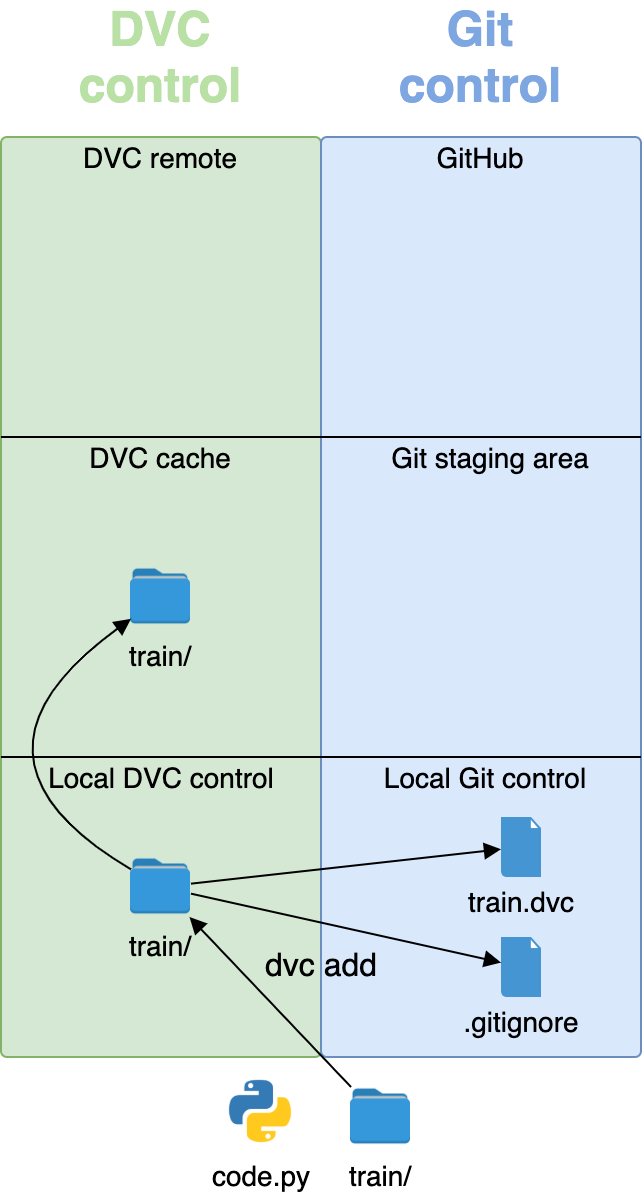
Для запуска отслеживания файлов Git и DVC используют команду add. Добавим папки train/ и val/ под управление DVC:
dvc add data/raw/train
dvc add data/raw/val
Вот что при этом делает DVC:
- Добавляет каталоги
train/иval/в.gitignore. - Создает два dvc-файла:
train.dvcиval.dvc. - Копирует папки
train/иval/в промежуточную область (staging).
.gitignore – это текстовый файл со списком файлов, которые Git не должен отслеживать. Добавляя папки train/ и val/ в .gitignore, DVC гарантирует, что мы случайно не загрузим большие файлы данных на GitHub.
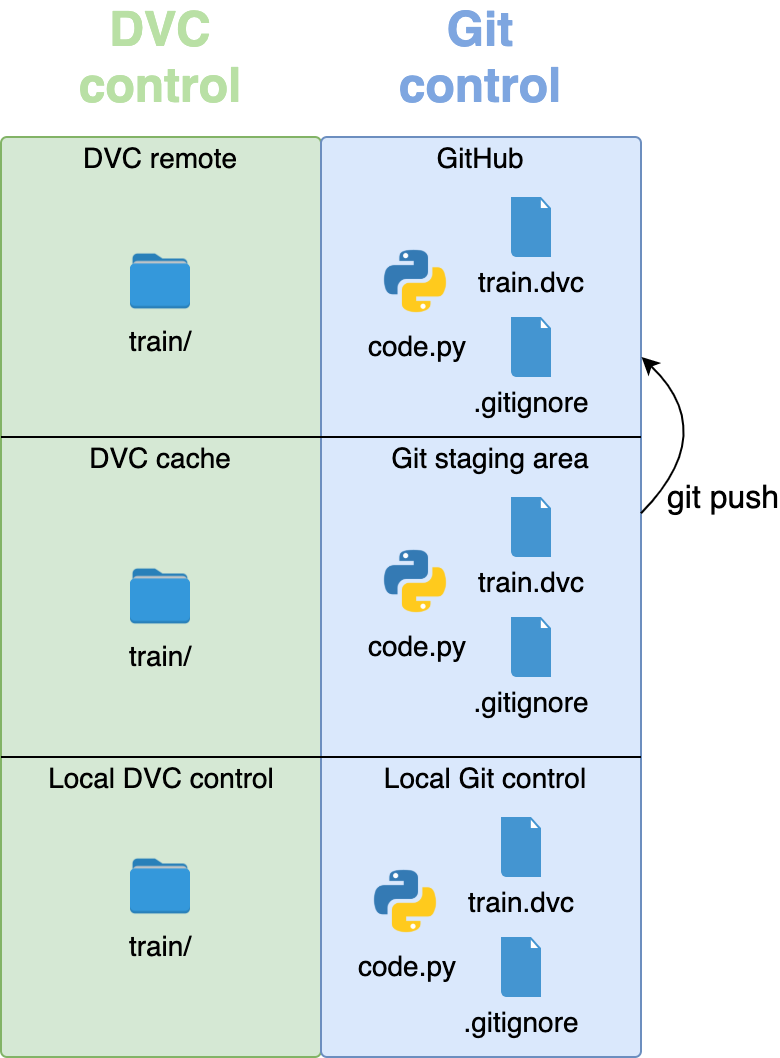
На следующем изображении показано, как выглядел репозиторий до выполнения каких-либо команд.
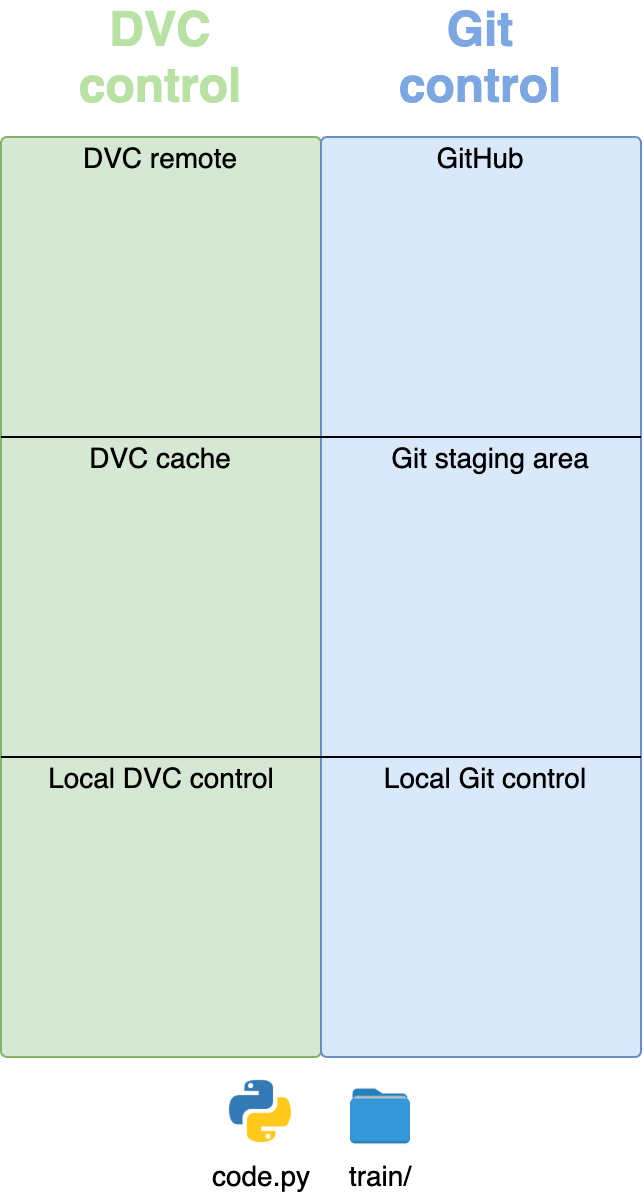
code.py и папку train/.Когда мы запускаем dvc add train/, папка с большими файлами переходит под контроль DVC, а маленькие dvc-файлы и файл .gitignore переходят под контроль Git. Папка train/ попадает в staging-область DVC.
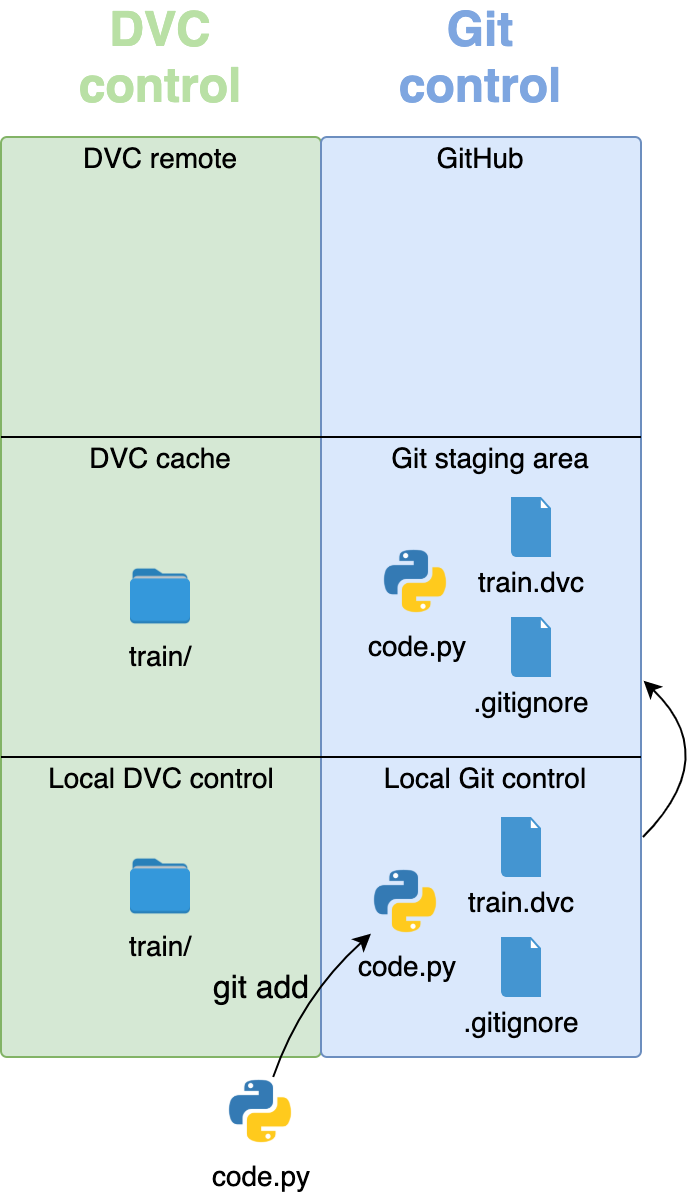
После того как большие файлы изображений помещены под управление DVC, добавим весь код и небольшие файлы в staging-область Git с помощью git add:
git add --all
Если кто-то хочет работать над проектом и использовать данные train/ и val/, им сначала нужно загрузить репозиторий Git, затем использовать dvc-файлы для получения текущей версии данных.
Но сначала нам нужно загрузить файлы в удаленное хранилище.
Перенос файлов на удаленный репозиторий
Чтобы загрузить файлы на GitHub, нужно сначала создать «снимок» текущего состояния репозитория:
git commit -m "Начало работы с DVC: настройка и загрузка DVC-файлов"
Ключ -m означает, что последующий текст в кавычках представляет собой сообщение, объясняющее, что было сделано.
В DVC тоже есть команда commit, но она делает не то же самое, что git commit. DVC не нужен снимок всего репозитория. Инструмент позволяет загружать файлы, как только они начинают отслеживаться с помощью dvc add. Команда dvc commit используется при изменении уже отслеживаемого файла. Внося локальное изменение в данные, мы должны зафиксировать изменение в кэше перед загрузкой на удаленный компьютер. Так как мы пока не меняли данные с момента их добавления, commit для dvc делать не нужно.
Чтобы загрузить файлы из кэша в удаленное хранилище, используем команду push:
dvc push
DVC просмотрит все папки локального репозитория в поисках dvc-файлов. Как уже упоминалось, эти файлы сообщают DVC, какие данные необходимо скопировать, и DVC копирует их из кэша в удаленное хранилище.
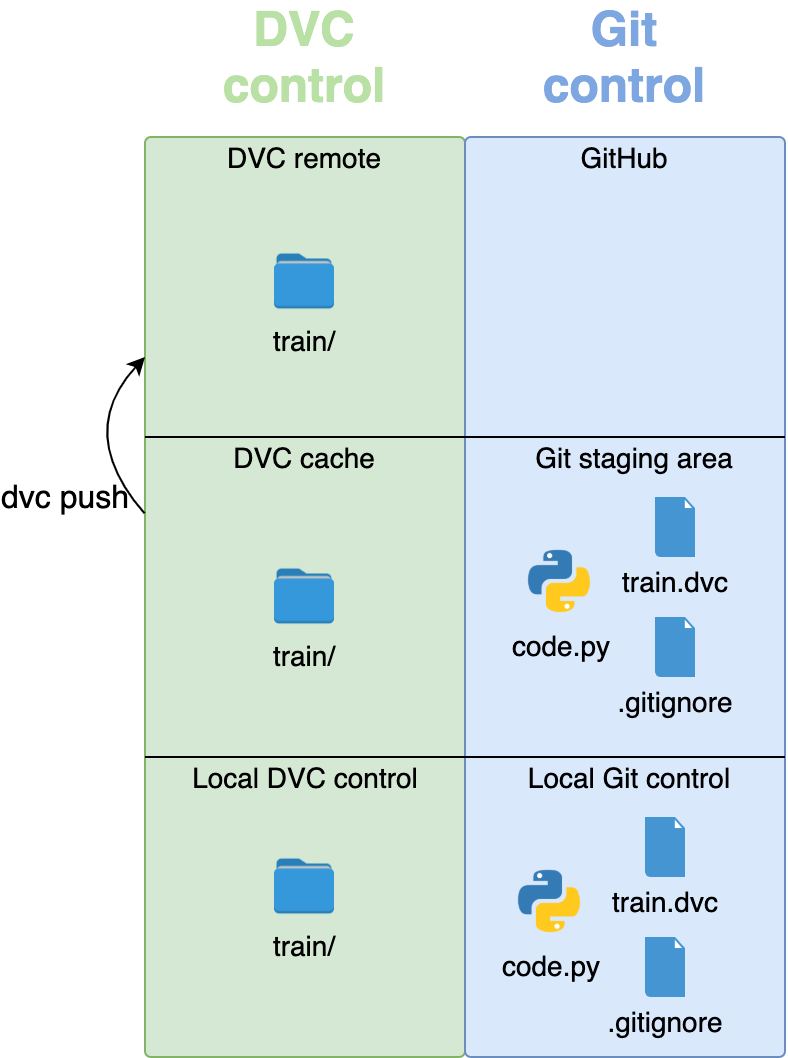
Осталось отправить файлы под управлением Git на GitHub:
git push --set-upstream origin first_experiment
GitHub не знает о новой ветке, которую мы создали локально, поэтому при первом push необходимо использовать параметр --set-upstream.
Скачивание файлов с DVC
Чтобы понять, как загружать файлы, удалим репозитория часть файлов с данными.
Как только мы добавили данные с помощью dvc add и отправили их с dvc push, они сохраняются в резервной копии. Для экономии места можно удалить фактические данные. Пока файлы отслеживаются DVC и dvc-файлы находятся в репозитории, мы можем быстро вернуть данные.
Например, удалим целиком папку val/:
rm -rf data/raw/val
Папка будет удалена из репозитория, но каталог по-прежнему безопасно хранится в кэше и удаленном хранилище. Чтобы вернуть данные из кэша, воспользуемся командой dvc checkout:
dvc checkout data/raw/val.dvc
Папка data/raw/val/ восстановлена. Если хотите, чтобы DVC выполнил поиск по всему репозиторию и проверил, чего не хватает, достаточно запустить dvc checkout без дополнительных аргументов.
Команда fetch загружает содержимое удаленного хранилища в кэш:
dvc fetch data/raw/val.dvc
Как только данные окажутся в кэше, проверьте их в репозитории с помощью dvc checkout. Еще с помощью одной команды dvc pull можно выполнить вместе fetch и checkout. Эта команда копирует данные с удаленного хранилища в кэш и в репозиторий за один проход. Действия команд аналогичны одноименным командам Git.
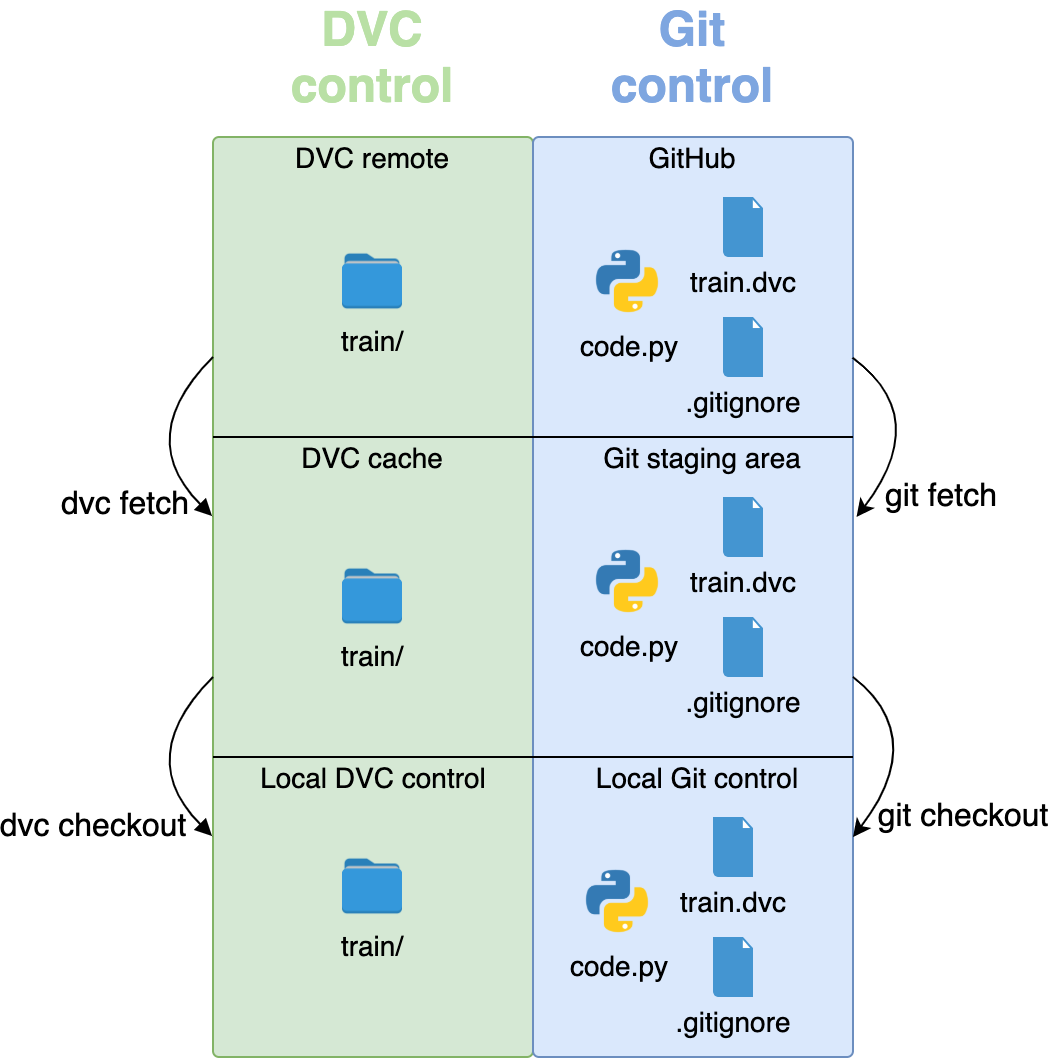
Имейте в виду, что сначала нужно получить dvc-файлы из Git, и только потом вызывать команды DVC. Если dvc-файлов нет в репозитории, DVC просто не знает, какие данные нужно получить.
Итак, мы рассмотрели базовый рабочий процесс взаимодействия DVC и Git. Всякий раз, когда мы добавляем данные или изменяем код, необходимо запускать соответствующие команды add, commit, push, чтобы сохранить текущую версию.
Остальная часть этого руководства посвящена конкретным примерам использования DVC для машинного обучения и Data Science.
Построение модели машинного обучения
Используя набор данных Imagenette, мы научим модель различать изображения мячей для гольфа и парашютов. Для этого мы выполним три шага:
- Подготовим данные для обучения.
- Обучим модель машинного обучения.
- Оценим качество модели.
Эти шаги соответствуют трем файлам Python в папке src/:
prepare.pytrain.pyevaluate.py
В следующих подразделах мы рассмотрим, что делает каждый из файлов.
Подготовка данных
Данные хранятся в нескольких каталогах. Чтобы упростить использование данных, мы создадим csv-файл, содержащий список изображений и их меток. CSV-файл будет содержать два столбца: столбец filename, содержащий полный путь файла конкретного изображения, и столбец label, содержащий строку метки, например "golf ball" или "parachute". Каждая строка в csv файле соответствует одному изображению.
filename, label
full/path/to/data-version-control/raw/n03445777/n03445777_5768.JPEG,golf ball
full/path/to/data-version-control/raw/n03445777/n03445777_5768,golf ball
full/path/to/data-version-control/raw/n03445777/n03445777_11967.JPEG,golf ball
...
Далее понадобится два CSV-файла:
train.csvсо списком изображений для обучения.test.csvсо списком изображений для тестирования.
Мы можем создать CSV-файлы, запустив программу prepare.py, которая сопоставляет имена папок и метки и сохраняет пары список-метка в виде CSV-файла. Вот исходный код этой программы:
from pathlib import Path
import pandas as pd
# имена папок, содержащие изображения мячей для гольфа и парашютов,
# сопоставлены с метками "golf ball" и "parachute"
FOLDERS_TO_LABELS = {
"n03445777": "golf ball",
"n03888257": "parachute"
}
def get_files_and_labels(source_path):
"""Принимает путь, указывающий на папку `data/raw/`.
Функция перебирает все папки и подпапки, чтобы найти файлы
с расширением jpeg. Метки присваиваются тем файлам, папки
которых представлены в виде ключей в FOLDERS_TO_LABELS.
Имена файлов и метки возвращаются в виде списков."""
images = []
labels = []
for image_path in source_path.rglob("*/*.JPEG"):
filename = image_path.absolute()
folder = image_path.parent.name
if folder in FOLDERS_TO_LABELS:
images.append(filename)
label = FOLDERS_TO_LABELS[folder]
labels.append(label)
return images, labels
def save_as_csv(filenames, labels, destination):
"""Принимает список файлов, список меток и путь назначения.
Имена файлов и метки форматируются как датафрейм pandas
и сохраняются в виде csv-файла."""
data_dictionary = {"filename": filenames, "label": labels}
data_frame = pd.DataFrame(data_dictionary)
data_frame.to_csv(destination)
def main(repo_path):
"""Запускает get_files_and_labels(), чтобы найти
все изображения в папках data/raw/train/ и data/raw/val/.
Имена файлов и соответствующие им метки сохраняются
как два csv-файла в папке data/prepare/: train.csv
и test.csv."""
data_path = repo_path / "data"
train_path = data_path / "raw/train"
test_path = data_path / "raw/val"
train_files, train_labels = get_files_and_labels(train_path)
test_files, test_labels = get_files_and_labels(test_path)
prepared = data_path / "prepared"
save_as_csv(train_files, train_labels, prepared / "train.csv")
save_as_csv(test_files, test_labels, prepared / "test.csv")
if __name__ == "__main__":
repo_path = Path(__file__).parent.parent
main(repo_path)
Запустим скрипт prepare.py в командной строке:
python src/prepare.py
Когда скрипт закончит работу, в папке data/prepare/ появятся файлы train.csv и test.csv. Нужно добавить их в DVC, а соответствующие dvc-файлы в GitHub:
dvc add data/prepared/train.csv data/prepared/test.csv
git add --all
git commit -m "Created train and test CSV files"
Теперь у нас есть список файлов, которые можно использовать для обучения и тестирования модели.
Обучение модели машинного обучения
Для обучения модели мы будем использовать один из простейших алгоритмов обучения с учителем – стохастический градиентный спуск. Исходный код, который мы будем использовать на этапе обучения:
from joblib import dump
from pathlib import Path
import numpy as np
import pandas as pd
from skimage.io import imread_collection
from skimage.transform import resize
from sklearn.linear_model import SGDClassifier
def load_images(data_frame, column_name):
filelist = data_frame[column_name].to_list()
image_list = imread_collection(filelist)
return image_list
def load_labels(data_frame, column_name):
label_list = data_frame[column_name].to_list()
return label_list
def preprocess(image):
resized = resize(image, (100, 100, 3))
reshaped = resized.reshape((1, 30000))
return reshape
def load_data(data_path):
df = pd.read_csv(data_path)
labels = load_labels(data_frame=df, column_name="label")
raw_images = load_images(data_frame=df, column_name="filename")
processed_images = [preprocess(image) for image in raw_images]
data = np.concatenate(processed_images, axis=0)
return data, labels
def main(repo_path):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
sgd = SGDClassifier(max_iter=10)
trained_model = sgd.fit(train_data, labels)
dump(trained_model, repo_path / "model/model.joblib")
if __name__ == "__main__":
repo_path = Path(__file__).parent.parent
main(repo_path)
Запустим скрипт train.py:
python src/train.py
Выполнение кода может занять несколько минут, в зависимости от мощности вашего компьютера. При выполнении кода вы можете получить предупреждение :
ConvergenceWarning: Maximum number of iteration reached before convergence.
Consider increasing max_iter to improve the fit.
В этом предупреждении scikit-learn указывает, что мы можем увеличить max_iter и получить лучшие результаты. Мы так и сделаем в одном из следующих разделов.
Когда скрипт завершится, у нас будет обученная модель машинного обучения, сохраненная в папке model/ с именем model.joblib. Это самый важный файл эксперимента. Его необходимо добавить в DVC с привязкой соответствующего файла dvc к GitHub:
dvc add model/model.joblib
git add --all
git commit -m "Trained an SGD classifier"
Мы обучили модель машинного обучения различать два класса изображений. Следующий шаг – определить, насколько точно модель работает на тестовых изображениях, которые модель не видела во время обучения.
Оценка модели машинного обучения
Проверка работы модели служит своего рода наградой – мы видим результат усилий. Вот исходный код, который используется на этапе оценки:
from joblib import load
import json
from pathlib import Path
from sklearn.metrics import accuracy_score
from train import load_data
def main(repo_path):
test_csv_path = repo_path / "data/prepared/test.csv"
test_data, labels = load_data(test_csv_path)
model = load(repo_path / "model/model.joblib")
predictions = model.predict(test_data)
accuracy = accuracy_score(labels, predictions)
metrics = {"accuracy": accuracy}
accuracy_path = repo_path / "metrics/accuracy.json"
accuracy_path.write_text(json.dumps(metrics))
if __name__ == "__main__":
repo_path = Path(__file__).parent.parent
main(repo_path)
Запустиим evaluate.py:
python src/evaluate.py
Оценка будет сохранена в файле metics/accuracy.json. Файл сейчас содержит только один объект, точность (accuracy) модели, например:
{"accuracy": 0.7186311787072244}
Файл небольшой, и его полезно хранить на GitHub, чтобы можно было быстро проверить, насколько хорошо выполняется каждый эксперимент:
git add --all
git commit -m "Evaluate the SGD model accuracy"
Версии датасетов и моделей в DVC
Каждый раз, когда мы запускаем эксперимент, мы хотим точно знать, что было на входе, и что получилось на выходе. В этом разделе мы познакомимся с соответствующим рабочим процессом для контроля версий в наших экспериментах.
Сначала отправим все изменения, внесенные в ветку first_experiment, в удаленные хранилища GitHub и DVC:
git push
dvc push
Обучение модели и завершение эксперимента – веха для проекта. Мы должны научиться оперативно возвращаться к таким точкам.
Добавление тегов к коммитам
Поскольку мы завершили эксперимент и создали новую модель, создадим тег, описывающий готовую модель:
git tag -a sgd-classifier -m "SGDClassifier with accuracy 71.86%"
Ключ -a используется для аннотирования тега. Некоторые команды вводят номера версий, например, v1.0, v1.3. Другие используют даты и инициалы члена команды, обучавшего модель. Ключ -m позволяет добавить в тег строку сообщения.
Используем переключатель --tags, чтобы передать теги из локального репозитория в удаленный:
git push origin --tags
В GitHub теги доступны на вкладке репозитория Releases.
Теги текущего репозитория можно посмотреть так:
git tag
Рабочие процессы DVC в значительной степени зависят от эффективных практик Git. Еще один способ сделать рабочий процесс более упорядоченным и прозрачным – использовать ветвление.
Создание отдельных веток Git для каждого эксперимента
Пока что мы делали всю работу в ветке first_experiment. Сложные задачи и долгосрочные проекты требуют проведения множества экспериментов. Хорошая практика – создавать для каждого эксперимента отдельную ветку.
В первом эксперименте мы установили максимальное количество итераций модели равным 10. Мы можем попробовать увеличить это число, чтобы увидеть, улучшит ли это результат.
git checkout -b "sgd-100-iterations"
Когда мы создаем новую ветку, все dvc-файлы, которые были в предыдущей ветке, будут присутствовать в новой ветке, как и другие файлы и папки.
Обновим код в train.py так, чтобы модель SGDClassifier запускалась с параметром max_iter = 100.
def main(repo_path):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
sgd = SGDClassifier(max_iter=100) # <-- обновим значение
trained_model = sgd.fit(train_data, labels)
dump(trained_model, repo_path / "model/model.joblib")
Это единственное изменение, которое необходимо сделать. Повторим обучение и оценку, запустив train.py и evaluate.py:
python src/train.py
python src/evaluate.py
При этом обновятся файлы model.joblib и precision.json. Зафиксировать результаты в кэше DVC:
dvc commit
DVC выведет вопрос, действительно ли мы хотим внести изменения, отвечаем y.
Помним, что dvc commit работает иначе, чем git commit, и используется для обновления уже отслеживаемого файла. Это не удалит предыдущую модель, а создаст новую.
Добавим и зафиксируем внесенные изменения в Git:
git add --all
git commit -m "Change SGD max_iter to 100"
Добавим тег:
git tag -a sgd-100-iter -m "Trained an SGD Classifier for 100 iterations"
git push origin --tags
Отправим изменения на GitHub и в удаленное хранилище DVC:
git push --set-upstream origin sgd-100-iter
dvc push
Теперь можно переключаться между ветками Git и DVC.
git checkout first_experiment
dvc checkout
Результаты наших экспериментов представлены в виде разных версий кода и моделей, к которым мы быстро можем получить доступ.
Что скрывается внутри DVC-файлов
Откроем текущий dvc-файл модели: data-version-control/model/model.joblib.dvc. Содержимое примерно следующее:
md5: 62bdac455a6574ed68a1744da1505745
outs:
- md5: 96652bd680f9b8bd7c223488ac97f151
path: model.joblib
cache: true
metric: false
persist: false
Файлы DVC – это файлы c YAML-разметкой. Информация хранится в парах ключ-значение и списках. Первый ключ – md5, за которым следует строка, казалось бы, случайных символов.
MD5 – популярный алгоритм хеширования. Хеширование использует содержимое файла, чтобы создать строку символов фиксированной длины. Такая строка называется хешем или контрольной суммой. Длина строки – независимо от размера исходного файла – составляет 32 символа.
Два одинаковых файла имеют одинаковый хеш. Если в одном из файлов изменится хотя бы один бит, хеши перестанут совпадать. DVC использует свойства MD5 для достижения двух важных целей:
- чтобы отслеживать, какие файлы были изменены, просто взглянув на их хеш-значения;
- определять, когда два больших файла совпадают – достаточно хранить только одну копию.
В рассматриваемом примере есть два значения md5. Первый описывает сам dvc-файл, а второй – файл model.joblib.path – путь к файлу модели относительно рабочего каталога. Логическое значение cache определяет, должен ли DVC кэшировать модель.
Совместная работа
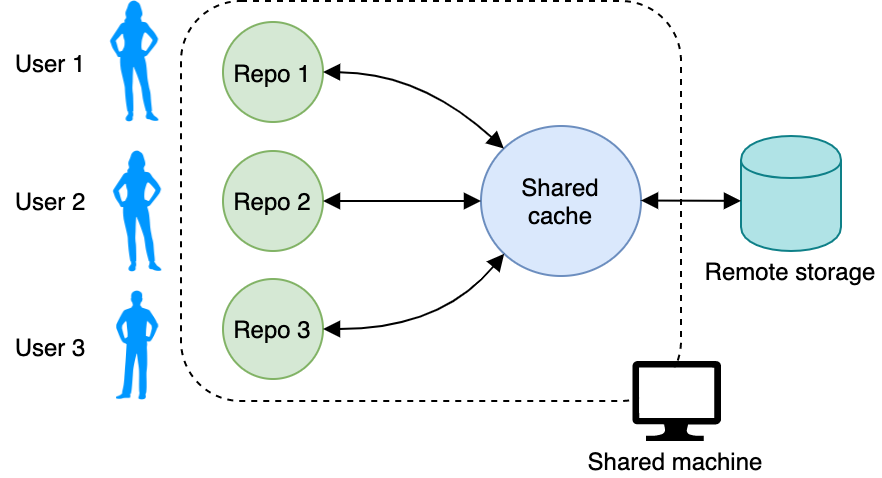
Освоенного рабочего процесса достаточно, если вы единственный, кто использует оборудование, на котором проводятся эксперименты. Однако многим командам для работы приходится совместно использовать мощные машины.
Когда с данными работают несколько пользователей, не хочется плодить множество копий одних и тех же датасетов. Для экономии места DVC позволяет настроить общий кэш. Когда мы инициализируем репозиторий DVC с помощью dvc init, DVC помещает кэш в папку .dvc/cache. Этот путь можно изменить – для наглядности создадим новую папку shared_cache где-нибудь за пределами папки репозитория. Укажем DVC использовать эту папку в качестве кэша:
dvc cache dir путь_к_shared_cache
Каждый раз, когда мы запускаем dvc add или dvc commit, данные будут копироваться в эту папку. Когда мы используем dvc fetch для получения данных из удаленного хранилища, они попадают в общий кэш, а dvc checkout перенесет их в рабочий репозиторий.
Если вы следовали примерам руководства, то все файлы сейчас находятся в папке .dvc/cache. Сейчас логично переместить данные из кэша по умолчанию в новый общий кэш:
mv .dvc/cache/* путь_к_shared_cache
Теперь все пользователи на компьютере могут указать в качестве кэша репозитория общий кэш.
Проверив файл репозитория .dvc/config, мы увидим, что появился новый раздел:
[cache]
dir = путь_к_shared_cache
Но как это помогает сэкономить место? Вместо того чтобы хранить копии одних и тех же данных в локальном репозитории, общем кэше и других репозиториях на машине, DVC позволяет использовать ссылки – типа reflink, symlink (символические) или hardlink (жесткие ссылки). DVC будет пытаться использовать по умолчанию reflink, однако если ОС не поддерживает рефссылки, DVC будет создавать копии. Больше о типах файловых ссылок можно узнать в документации DVC.
Если кратко, то поведение кеша по умолчанию можно изменить, указав параметр конфигурации cache.type, подставив вместо тип_ссылки значение symlink, reflink, hardlink или copies:
dvc config cache.type тип_ссылки
dvc checkout --relink
Создаем воспроизводимый конвейер Data Science
Вот краткий обзор шагов, которые мы сделали к настоящему времени для обучения модели машинного обучения:
- Получение данных.
- Подготовка данных.
- Обучение модели.
- Оценка результатов обучения.
Вы могли заметить, что при изменении параметров некоторые шаги мы повторяли вручную. Процесс можно автоматизировать, объединив последовательность действий в конвейер DVC, запускаемый единственной командой.
Создадим новую ветку и назовем ее sgd-pipeline:
git checkout -b sgd-pipeline
Используем эту ветку, чтобы повторно запустить эксперимент в виде конвейера DVC. Конвейер состоит из нескольких этапов и выполняется с помощью команды dvc run. Каждый этап состоит из трех компонентов:
- Входные объекты,
dependencies - Выходные объекты,
outs - Выполняемая команда,
command
Командой может быть все, что мы обычно запускаем в командной строке, в том числе файлы Python.
Поскольку мы успели уже вручную добавить под управление DVC много файлов, DVC запутается, если мы попытаемся создать те же файлы с помощью конвейера. Чтобы этого избежать, сначала удалим CSV-файлы, модели и показатели с помощью dvc remove:
dvc remove data/prepared/train.csv.dvc \
data/prepared/test.csv.dvc \
model/model.joblib.dvc --outs
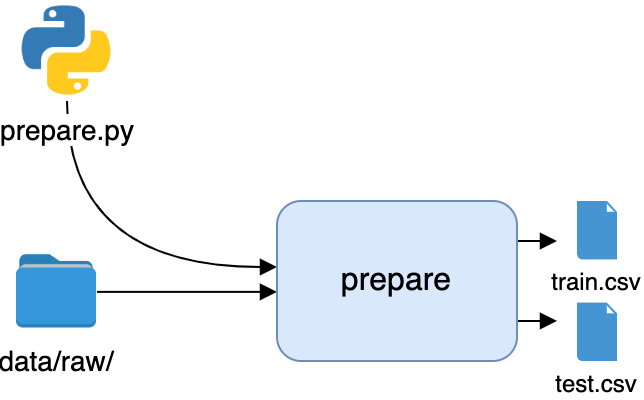
Итак, мы начинаем конвейер с запуска prepare.py. Передаем команде dvc run необходимые данные:
- Dependencies (ключ
-d):prepare.pyи данные вdata/raw - Outs (ключ
-o):train.csvиtest.csv - Command:
python prepare.py
Ключ -n используем для создания имени этапа:
dvc run -n prepare \
-d src/prepare.py -d data/raw \
-o data/prepared/train.csv -o data/prepared/test.csv \
python src/prepare.py
DVC создаст два файла: dvc.yaml и dvc.lock. Что можно увидеть в dvc.yaml:
stages:
prepare:
cmd: python src/prepare.py
deps:
- data/raw
- src/prepare.py
outs:
- data/prepared/test.csv
- data/prepared/train.csv
Элемент верхнего уровня stages имеет вложенные элементы, по одному для каждого этапа. Пока у нас только один этап prepare. По мере того как мы будем наращивать конвейер, в файле будут добавляться элементы. Технически можно не вводить команды dvc run в командной строке, а создавать или варьировать этапы в этом файле.
У каждого dvc.yaml есть соответствующий файл dvc.lock, также в формате YAML:
prepare:
cmd: python src/prepare.py
deps:
- path: data/raw
md5: a8a5252d9b14ab2c1be283822a86981a.dir
- path: src/prepare.py
md5: 0e29f075d51efc6d280851d66f8943fe
outs:
- path: data/prepared/test.csv
md5: d4a8cdf527c2c58d8cc4464c48f2b5c5
- path: data/prepared/train.csv
md5: 50cbdb38dbf0121a6314c4ad9ff786fe
Добавление хэшей MD5 позволяет DVC отслеживать входные и выходные данные и определять, изменяется ли какой-либо из этих файлов. Таким образом, вместо отдельных файлов dvc для train.csv, test.csv и model.joblib, все отслеживается в файле .lock.
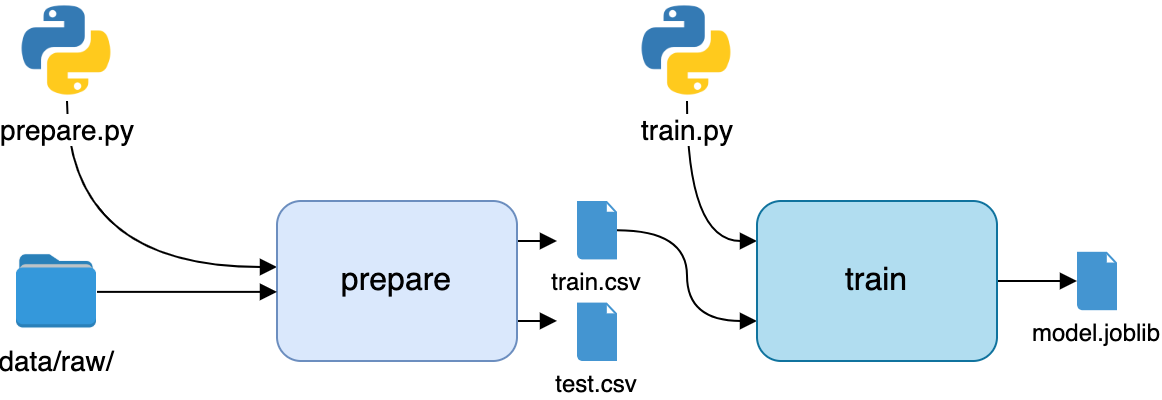
Мы автоматизировали первый этап конвейера. Представим его в виде блок-схемы.
Следующий этап – обучение:
dvc run -n train \
-d src/train.py -d data/prepared/train.csv \
-o model/model.joblib \
python src/train.py
Финальный этап – оценка модели:
dvc run -n evaluate \
-d src/evaluate.py -d model/model.joblib \
-M metrics/accuracy.json \
python src/evaluate.py
Обратите внимание, что вместо ключа -o мы использовали ключ -M. DVC обрабатывает метрики иначе, чем другие выходные данные. DVC будет знать, что в accuracy.json хранится показатель производительности модели:
dvc metrics show
metrics/accuracy.json:
accuracy: 0.6996197718631179
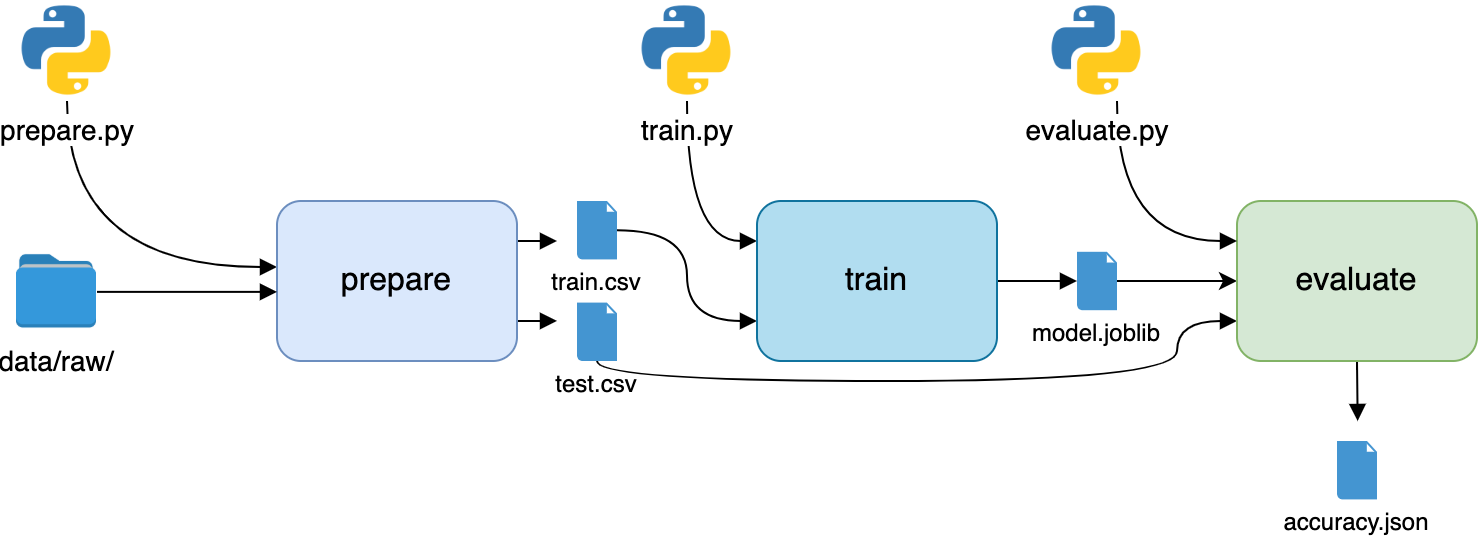
Теперь весь рабочий процесс представлен на одном изображении. Не забудем сделать тег для новой ветки и отправить изменения на GitHub и DVC:
git commit -m "Rerun SGD as pipeline"
dvc commit
git push --set-upstream origin sgd-pipeline
git tag -a sgd-pipeline -m "Trained SGD as DVC pipeline."
git push origin --tags
dvc push
Теперь самое интересное! Воспользуемся для обучения классификатором random forest. Обычно он работает эффективнее, чем SGDClassifier, и потенциально может дать лучшие результаты. Начнем с создания и проверки новой ветки, которую назовем random_forest:
git checkout -b "random_forest"
Изменим src/train.py, чтобы использовать RandomForestClassifier вместо SGDClassifier:
from joblib import dump
from pathlib import Path
import numpy as np
import pandas as pd
from skimage.io import imread_collection
from skimage.transform import resize
from sklearn.ensemble import RandomForestClassifier # <-
# ...
def main(path_to_repo):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
rf = RandomForestClassifier() # <-
trained_model = rf.fit(train_data, labels) # <-
dump(trained_model, repo_path / "model/model.joblib")
Поскольку файл train.py изменился, стал другим и его хеш MD5. DVC поймет, что необходимо воспроизвести одну из стадий конвейера. Поскольку изменение модели повлияет и на метрику, мы хотим воспроизвести всю цепочку. Любой этап конвейера DVC можно воспроизвести с помощью команды dvc repro:
dvc repro evaluate
И всё! Когда мы запускаем команду repro, DVC проверяет все зависимости всего конвейера, чтобы определить, что изменилось и какие команды нужно выполнить снова. Можно перемещаться между ветками и воспроизводить любой эксперимент с помощью одной лишь команды.
Кроме того, теперь проще простого сравнивать метрики. Если запустить dvc metrics show с ключом -T, будут отображаться метрики для всех тегов.
dvc metrics show -T
forest:
metrics/accuracy.json:
accuracy: 0.8098859315589354
sgd-pipeline:
metrics/accuracy.json:
accuracy: 0.6996197718631179
Это позволяет быстро определить, какой эксперимент в репозитории дал наилучший результат. Представим, что вы вернулись к проекту спустя полгода и забыли обо всех подробностях. Как и любому другому человеку, который хочет воспроизвести вашу работу, будет достаточно выполнить три шага:
- Запустить
git cloneилиgit checkout, чтобы получить программный код и dvc-файлы. - Получить данные обучения с помощью
dvc checkout. - Воспроизведите рабочий процесс с помощью команды
dvc repro evaluate.
Заключение
Поздравляем с прохождением туториала!
Итак, мы провели несколько экспериментов, обеспечили безопасное создание версий, резервное копирование данных и моделей. Более того, мы можем быстро воспроизвести каждый эксперимент, выполнив одну команду dvc repro.
Поначалу может показаться несколько сложным запускать в нужные моменты все команды DVC и Git. Положение облегчат хуки Git – при запуске определенных команд Git автоматически выполнятся команды DVC. К тому же DVC имеет Python API, то есть можно настроить необходимую автоматизацию на уровне кода.
Хотя это руководство представляет собой достаточно подробный обзор возможностей DVC, невозможно охватить всё в одной публикации. Для дальнейшего ознакомления с DVC мы рекомендуем обратиться к официальному руководству пользователя, справочнику команд и интерактивному учебнику.
Используете ли вы уже контроль версий для своих данных?