
Распределенные системы — основа высоконагруженных веб-приложений. Они обеспечивают работу крупных интернет-сервисов, онлайн-банкинга, мультиплеерных игр и многих других платформ. В таких системах множество узлов работают совместно, чтобы приложение могло:
- Масштабироваться – легко увеличивать мощность, добавляя новые узлы.
- Быть отказоустойчивым – продолжать работу даже при сбоях.
- Работать с максимальной скоростью, распределяя нагрузку между серверами.
Однако разработка и поддержка распределенных систем связаны с рядом сложностей, которые можно разделить на 4 основные категории:
- Сбои в сети – узлы могут терять соединение или выходить из строя.
- Сложности координации – разные узлы должны согласовывать данные между собой.
- Угрозы безопасности – важно защищать передаваемые данные от атак.
- Проблемы масштабирования – нужно автоматически добавлять дополнительные узлы при увеличении нагрузки.
Разберем эти сложности и способы их решения подробнее.
Надежность и безопасность коммуникации
Взаимодействие между узлами в распределeнной системе всегда сопряжено с рисками (возможными сбоями в сети, задержками при передаче данных и угрозами безопасности). Когда несколько серверов работают вместе, важно обеспечить стабильную, безопасную и надeжную связь.
Основные проблемы:
- Потеря пакетов – сообщения могут не дойти до адресата из-за сбоев в сети.
- Нарушение порядка доставки – сообщения могут приходить в разное время и в неверной последовательности.
- Угрозы безопасности – если передавать данные между узлами в незащищенном виде, их могут перехватить злоумышленники.
Способы решения проблем коммуникации:
- Использование TCP. В отличие от UDP, протокол TCP обеспечивает надежность передачи данных. Он управляет повторной отправкой потерянных пакетов и гарантирует правильный порядок их доставки. Это позволяет избежать ситуации, когда сообщения приходят не по порядку или вовсе теряются.
- Защита данных с помощью TLS. Шифрование сообщений с помощью TLS гарантирует безопасную передачу данных между узлами. Это предотвращает перехват информации третьими лицами. TLS используется в HTTPS, онлайн-банкинге и защищенных API.
- Службы обнаружения сервисов через DNS. В динамических средах (облачных приложениях и микросервисax) важно, чтобы сервисы находили друг друга без жесткого прописывания IP-адресов. DNS-сервисы (AWS Route 53, Kubernetes Service Discovery и т.п.) автоматически маршрутизируют запросы к доступным узлам.
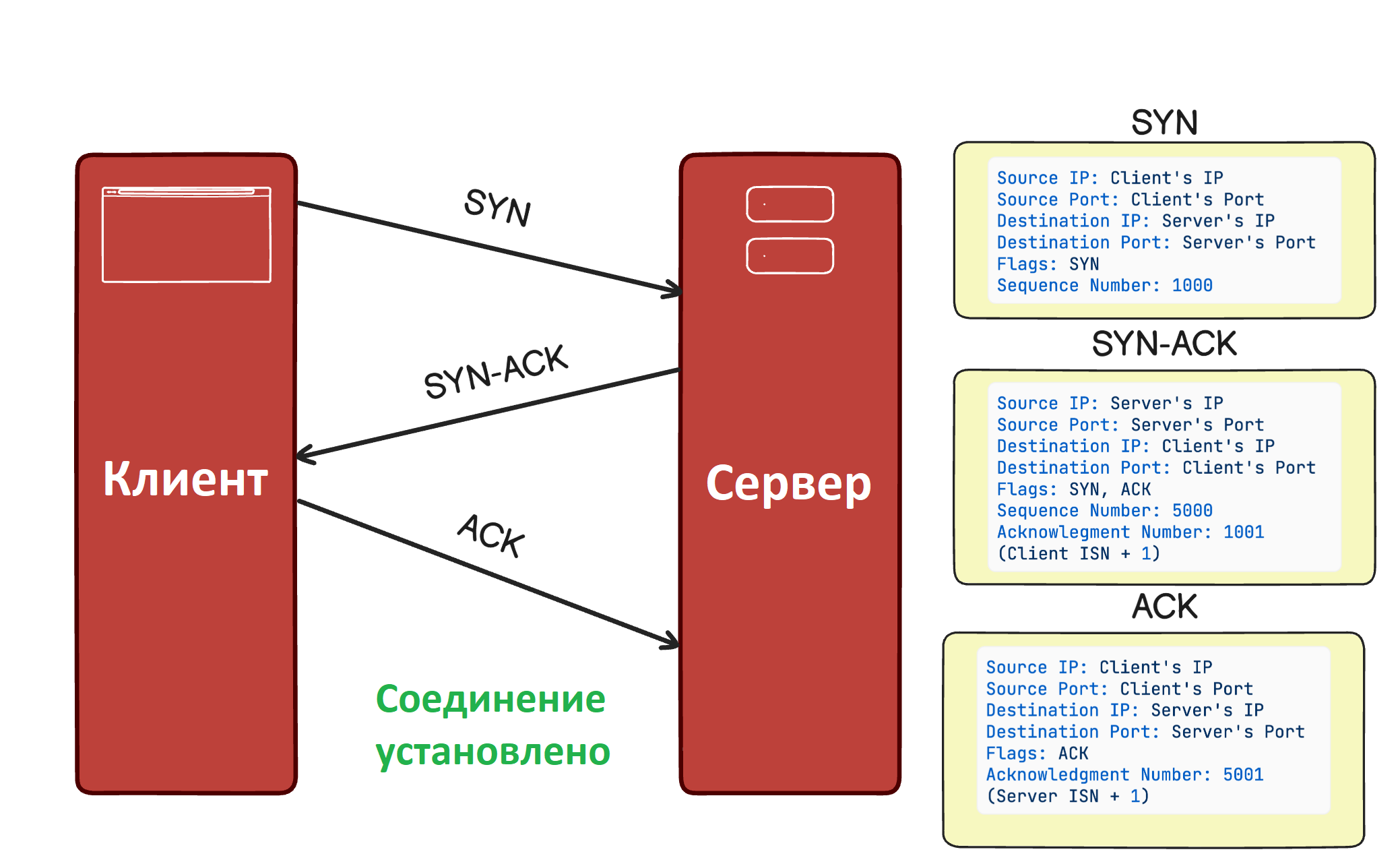
Как работает обнаружение сервисов через DNS
Схема обнаружения и взаимодействия с сервисами через сервисный реестр выглядит так:
- Регистрация сервиса. Сервис сначала регистрируется в сервисном реестре, сообщая о своем существовании, местоположении и других характеристиках.
- Поиск сервиса. Клиентское приложение обращается к сервисному реестру, чтобы найти нужный сервис.
- Получение местоположения сервиса. Сервисный реестр возвращает клиенту информацию о местоположении запрошенного сервиса.
- Вызов сервиса. После получения информации о местоположении сервиса клиент может напрямую вызвать этот сервис.
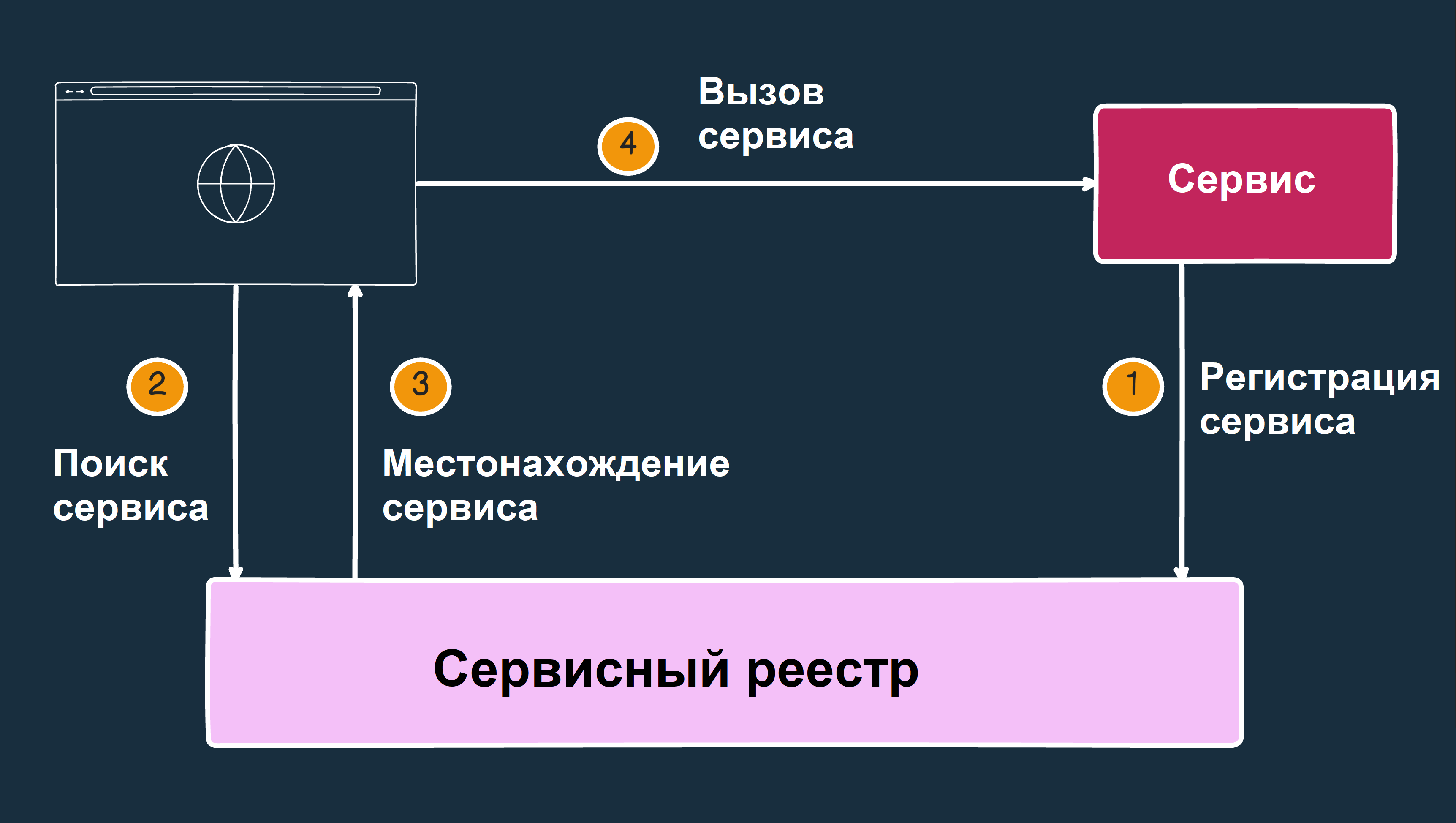
Такая архитектура обеспечивает гибкость и отказоустойчивость, поскольку:
- Клиенты не нуждаются в жестко прописанных адресах сервисов.
- Сервисный реестр может перенаправлять запросы на доступные экземпляры сервисов.
- При изменении местоположения сервиса клиентам не нужно обновлять свою конфигурацию.
- Этот подход широко используется в микросервисных архитектурах для динамического обнаружения служб.
Чтобы связь сервисов была надежной, необходимо использовать все 3 способа решения коммуникационных проблем в комплексе.
Пример: рассмотрим e-commerce платформу, где взаимодействуют три микросервиса:
- Оформление заказов.
- Оплата.
- Складской учет.
Такому приложению нужны:
- TCP – чтобы все сообщения были доставлены в правильном порядке.
- TLS – для защиты передаваемых данных от атак.
- DNS – для автоматического обнаружения сервисов.
Координация сервисов
Координация между узлами в распределенной системе представляет сложность из-за следующих факторов:
- Сбои в сети – некоторые узлы могут внезапно выйти из строя.
- Отсутствие глобального времени – нет единого системного времени для всех серверов.
- Состояние гонки – если несколько узлов одновременно изменяют общий ресурс, это может привести к несогласованности данных.
Способы решения проблем координации:
- Обнаружение сбоев. Для поддержания стабильности системы важно оперативно выявлять неработающие узлы. Обычно для этого используют heartbeat-сообщения (узлы периодически отправляют сигналы «я жив»). В случае выявления сбоя алгоритмы выбора лидера (Raft, реже Paxos) обеспечат назначение ведущего узла для координации системы.
- Логические и векторные часы. Так как у узлов нет общего времени, используются специальные временные метки. Например, логические часы Лэмпорта позволяют определить, какое событие произошло раньше, а векторные часы помогают понять причинно-следственные связи между событиями.
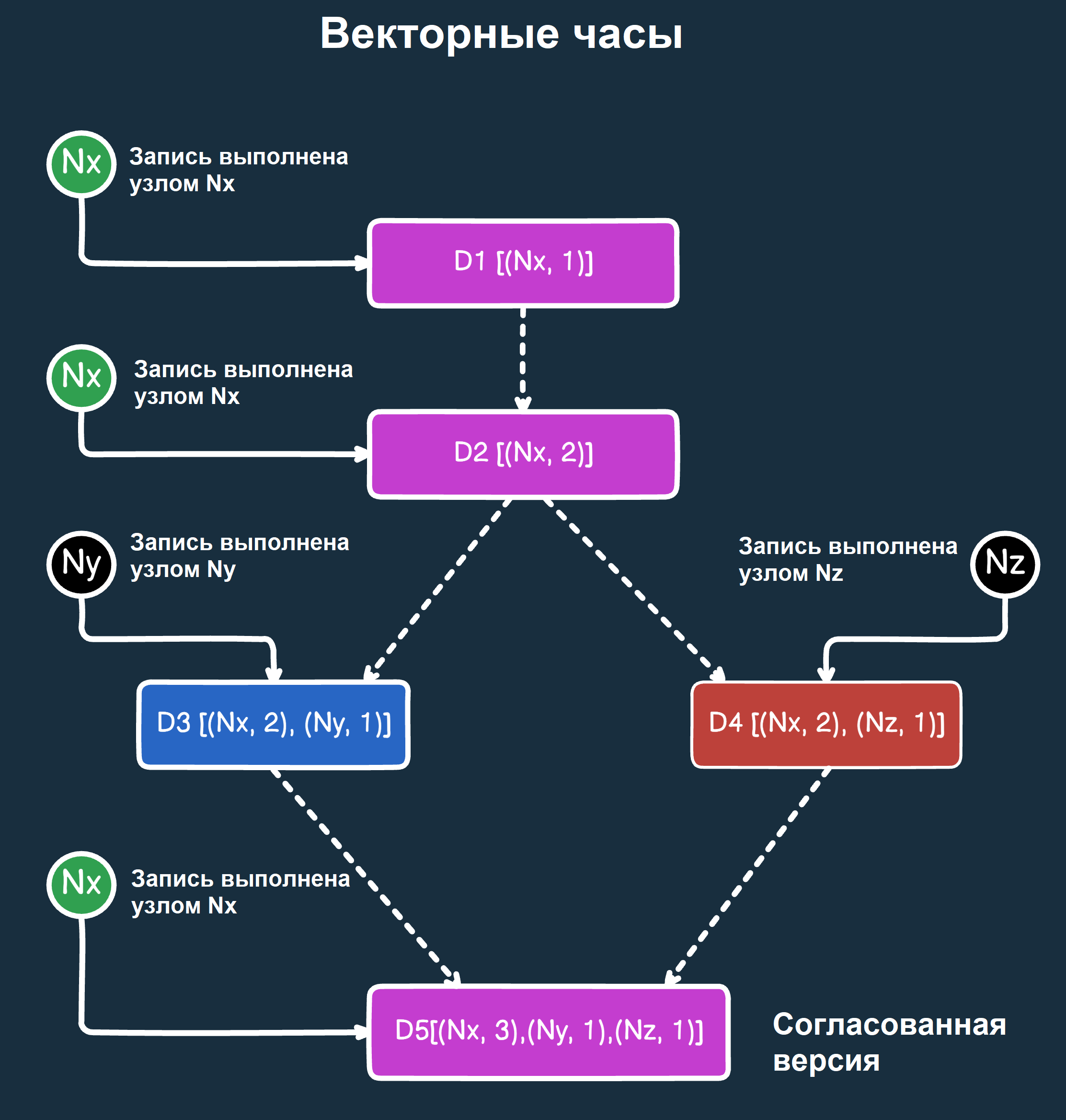
- Алгоритмы консенсуса. Если несколько узлов должны прийти к единому решению (например, запись в базу данных или выбор лидера), применяются уже упомянутые выше алгоритмы консенсуса Paxos и Raft.
- Репликация данных. Чтобы данные оставались актуальными на всех узлах, применяется репликация, при которой записи могут принимать один или несколько ведущих узлов (в зависимости от нагрузки на приложение), а оставшиеся узлы-реплики (копии) обрабатывают чтение.
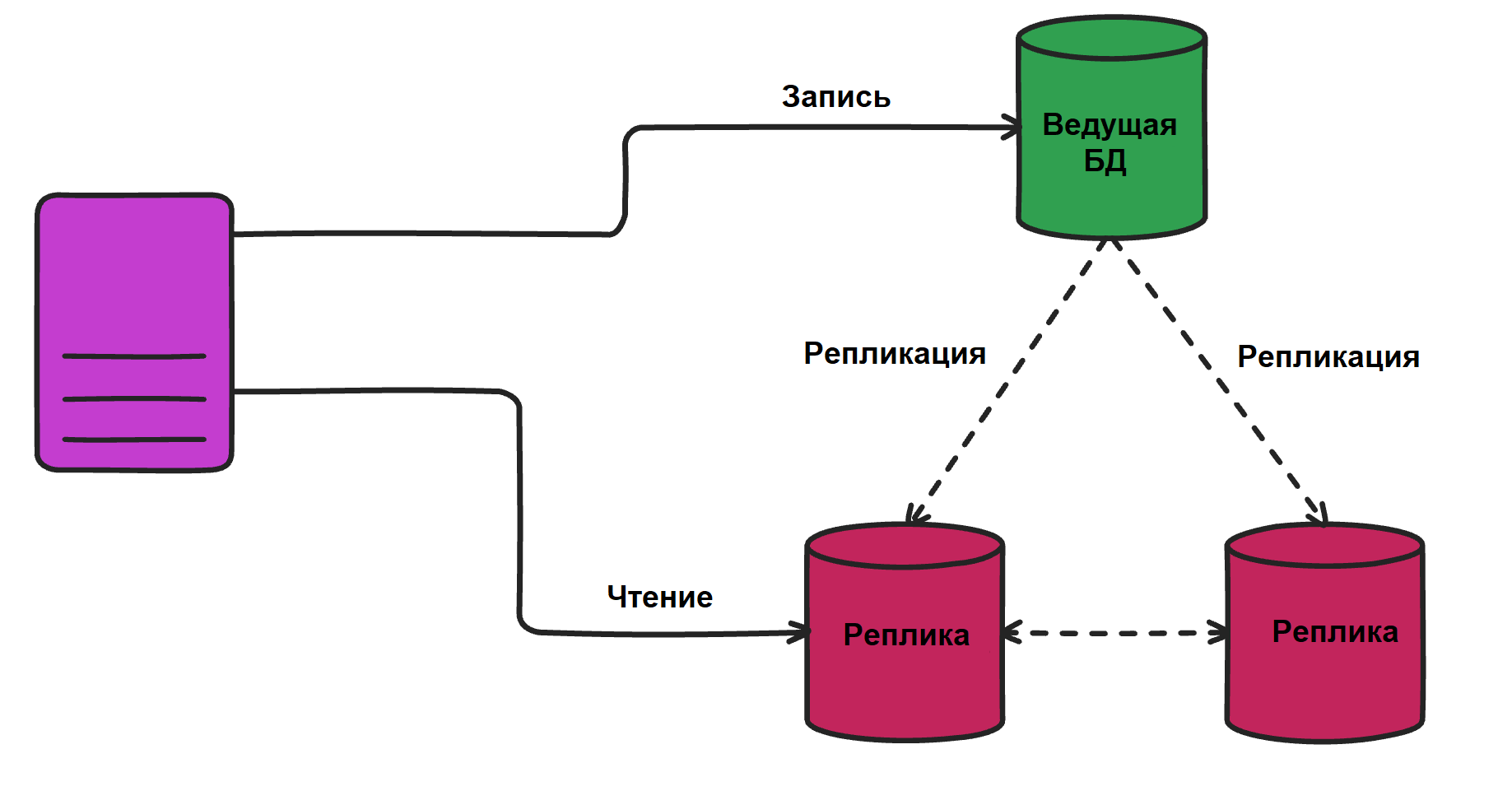
Пример: предположим, нам надо обеспечить координацию распределенной базы данных, работающей в нескольких дата-центрах. Для обеспечения синхронизации транзакций необходимо использовать:
- Механизм обнаружения сбоев – чтобы система автоматически переключалась на рабочие узлы при неполадках.
- Raft – для согласования действий между узлами.
- Векторные часы – для правильного упорядочивания событий.
Масштабирование
Одним из ключевых преимуществ распределeнных систем является масштабируемость – возможность увеличивать нагрузку, добавляя новые узлы. Однако для эффективной работы важно выбрать правильный подход к масштабированию.
Основные шаблоны масштабирования:
- Микросервисы за API-шлюзом. Разделение монолитного приложения на микросервисы позволяет масштабировать отдельные компоненты независимо, при этом запросы к нужному микросервису маршрутизирует API-шлюз.
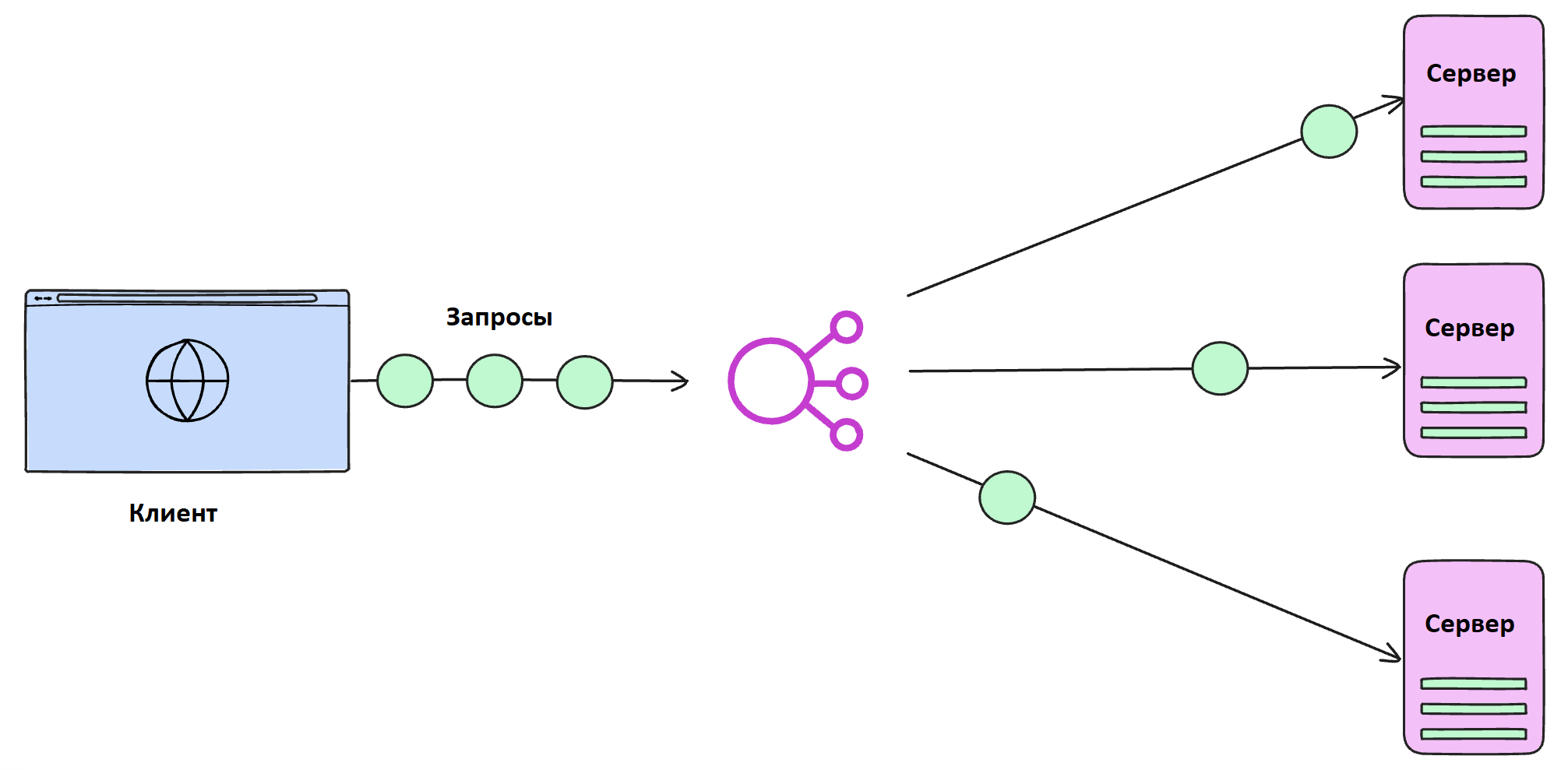
- Балансировщики нагрузки. Распределяют входящие запросы между несколькими серверами, предотвращая перегрузку. В зависимости от используемого алгоритма, запросы распределяются по кругу, или в соответствии с нагрузкой (либо географическим положением) серверов. Подробнее об алгоритмах балансировки мы писали в этой статье.
- Функциональная декомпозиция с CQRS (разделением операций чтения и записи на разные сервисы). Чтение использует денормализованные базы данных для быстрого доступа, запись оптимизируется для согласованности данных.
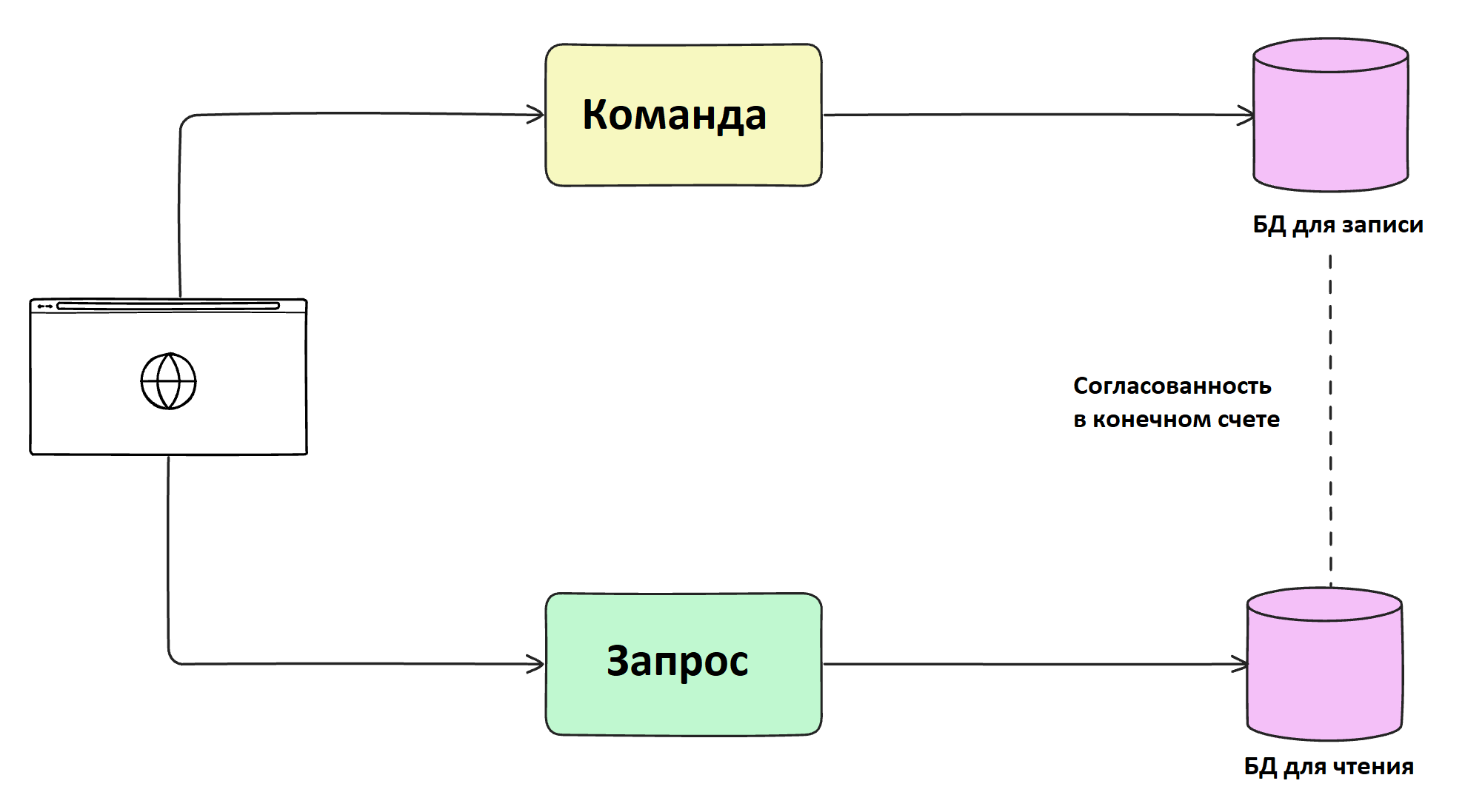
Предположим, нам нужно создать социальную сеть для миллионов пользователей. Чтение профилей на такой платформе происходит гораздо чаще, чем их изменение, а создание постов требует быстрого согласования данных. Чтобы сделать систему быстрой, отказоустойчивой и эффективной при высоких нагрузках, необходимо использовать CQRS: это позволит масштабировать чтение с помощью оптимизированной БД, и обрабатывать записи в отдельной системе.
Отказоустойчивость
Отказоустойчивость – это способность системы восстанавливаться после сбоев и продолжать работу. В распределенных системах сбои неизбежны, поэтому важно проектировать систему так, чтобы в случае необходимости она плавно ограничивала некритичную функциональность, а не полностью выходила из строя. Например, интернет-магазин может временно отключить функцию рекомендаций, но всегда должен позволять пользователям просматривать и покупать товары.
Основные техники отказоустойчивости:
- Тайм-ауты – предотвращают бесконечное ожидание ответа от медленного сервиса: если сервис не отвечает в течение заданного времени, запрос прерывается.
- Повторные попытки – обеспечивают автоматический повтор запроса, если произошел сбой. Чтобы не перегружать систему, обычно используют экспоненциальную задержку.
- Ограничители запросов – отключают запросы к сервису, если он часто дает сбои. После восстановления сервис снова начинает принимать запросы.
- Сброс нагрузки – если система перегружена, низкоприоритетные запросы (например, аналитика) отбрасываются.
- Ограничение количества запросов – позволяет API обрабатывать не более X запросов в секунду. Защищает от перегрузки и DDoS-атак.
- Разделение на зоны – изолирует независимые компоненты (подобно переборкам и отсекам в подлодке). Если один компонент выходит из строя, он не тянет за собой всю систему.
- Проверка состояния – постоянный мониторинг узлов и автоматическое отключение неработающих серверов.
Пример: видеостриминговый сервис должен выдерживать резкий рост трафика во время крупного события. Такому приложению нужны:
- Ограничение количества входящих запросов для предотвращения перегрузки.
- CDN (сети доставки контента) для распределения нагрузки и ускорения доступа к видео.
- Система проверки состояния для автоматического исключения вышедших из строя серверов.
В заключение
Разработка распределенных систем – сложный комплексный процесс, требующий глубокого понимания различных аспектов — от надежной коммуникации между узлами до эффективной координации сервисов, грамотного масштабирования и обеспечения отказоустойчивости.
Как мы увидели, каждая из проблем имеет проверенные временем решения: TCP и TLS для надежной и безопасной передачи данных, службы обнаружения на основе DNS для гибкой маршрутизации, алгоритмы консенсуса вроде Raft для координации, микросервисная архитектура и CQRS для масштабирования, а также комплекс методов отказоустойчивости – от тайм-аутов до разделения на изолированные зоны.
Комбинируя эти подходы, разработчики могут создавать системы, способные выдерживать огромные нагрузки, сохраняя при этом стабильность и производительность.
Какие проблемы в распределенных системах вам приходилось решать? Делитесь своим опытом в комментариях!