

SQL – декларативный язык программирования. Вы объявляете базе данных о своих намерениях, а способ получения результата она выбирает сама. Это решения об использовании индексов, порядке объединения таблиц или проверки условий. PostgreSQL в стандартном виде не предусматривает вмешательства извне в этот процесс, но показывает последователь выполнения любого запроса.
На практике разработчик часто недоумевает, почему запрос обрабатывается так медленно. Вот четыре причины этого:
- алгоритмически неэффективный запрос, когда придётся переписывать саму структуру;
- сборщик статистики не успел отследить актуальную информацию по количеству записей в таблице, вставках и очистках, поэтому база данных выполняет запрос не так, как вы ожидали;
- загруженность привела к нехватке ресурсов процессора, мощности дисковой подсистемы ввода-вывода, объёма кеша или даже пропускной способности памяти;
- блокировка.
Поскольку последний пункт встречается редко при разработке приложения, рассмотрим решение для первых трёх проблем – анализ плана запроса.
Получение плана запроса
План запроса – последовательность шагов в виде дерева для получения результата SQL-запроса. Каждый шаг – операция: извлечение или обработка данных, сканирование индекса, пересечение или объединение множеств, построение битовых карт или другая.
Для получения плана запроса используют команду EXPLAIN. Добавьте параметры ANALYZE и BUFFERS, и, помимо действительной отработки запроса, получите время выполнения, статистическую информацию, количество попаданий, блоков и прочих данных буфера. Эта команда подходит только для локальной отладки вручную, потому что при большой нагрузке системы данные быстро меняются, и план теряет актуальность во время выполнения.
Для крупных приложений применяют модуль auto_explain. Главная прелесть auto_explain в том, что вы задаёте «медленное» время выполнения запроса. Он анализирует и записывает план в лог сервера только тогда, когда оператор отрабатывает дольше указанного числа.
Смотрите, как выглядит получение плана:
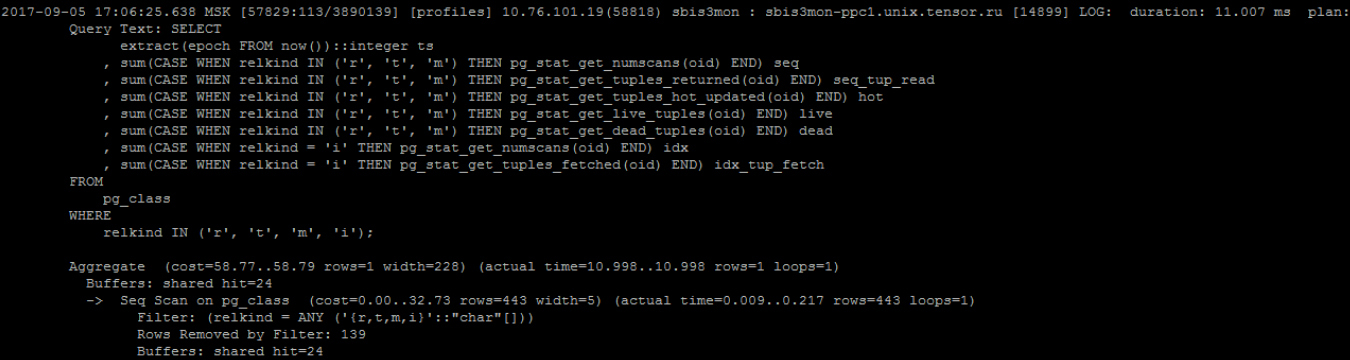
После заголовка вы видите тело запроса, а со слова Aggregate начинается, собственно, план.
Понимаем, что время выполнения хорошее, а в остальном такое представление недостаточно информативное. Поскольку каждый элемент плана отображает сумму по ресурсам поддерева, для получения количества страниц конкретного узла приходится выполнять вычисления в уме. Чтобы проанализировать время, вы умножаете оценку времени каждого узла на количество циклов выполнения. Вдобавок нелегко будет определить узкое место в плане.
Визуализация плана запроса
Что поможет визуализировать необходимую информацию?
Сайт на базе текстового представления плана отрисовывает таблицу с такими данными:
- время для каждого узла отдельно;
- отклонение от статистики, например, несовпадение планового и результирующего количества записей;
- число повторений конкретного узла;
- архив планов для передачи ссылки сотруднику.
Из минусов этого ресурса отметим:
- копирование и вставка планов из лога;
- отсутствие данных буфера;
- медленный выпуск новых версий;
- некорректный анализ общих табличных выражений (CTE) и
InitPlan.
Обратите внимание, что результирующее время плана совпадает со временем отдельного узла CTE Scan:

Это ошибка, ведь Seq Scan отработал 1,389 мс, и для получения времени CTE Scan выполняется вычитание.
Усовершенствование представления плана
Чтобы качественнее анализировать планы запросов, компания «Тензор» реализовала собственный сервис для внутреннего использования, но позднее появилась публичная версия. Разработчики сделали парсер планов, добавили правильный анализ CTE-ресурсов и буфера, а также наглядную визуализацию.
Слева на полном плане отображаются показатели, как и у предыдущего сервиса, а справа – потреблённые данные. Для большей наглядности тело плана сократили и добавили диаграмму распределения времени по операциям.
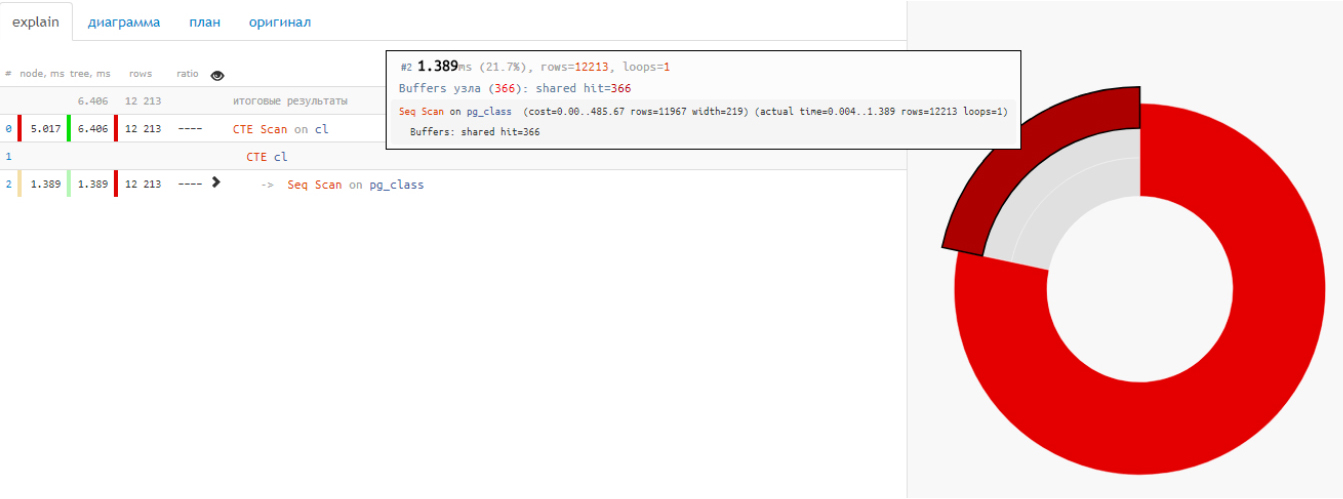
В таком представлении отчётливо видно, что извлечение 12 тысяч записей заняло только четверть времени, а остальное ушло на CTE.
С маленькими планами проще, а когда план включает десяток операций, то диаграмма облегчает жизнь в несколько раз. Благодаря ей вы видите, что больше половины общего времени заняло последовательное сканирование таблицы, хотя вернулось 57 тысяч строк:
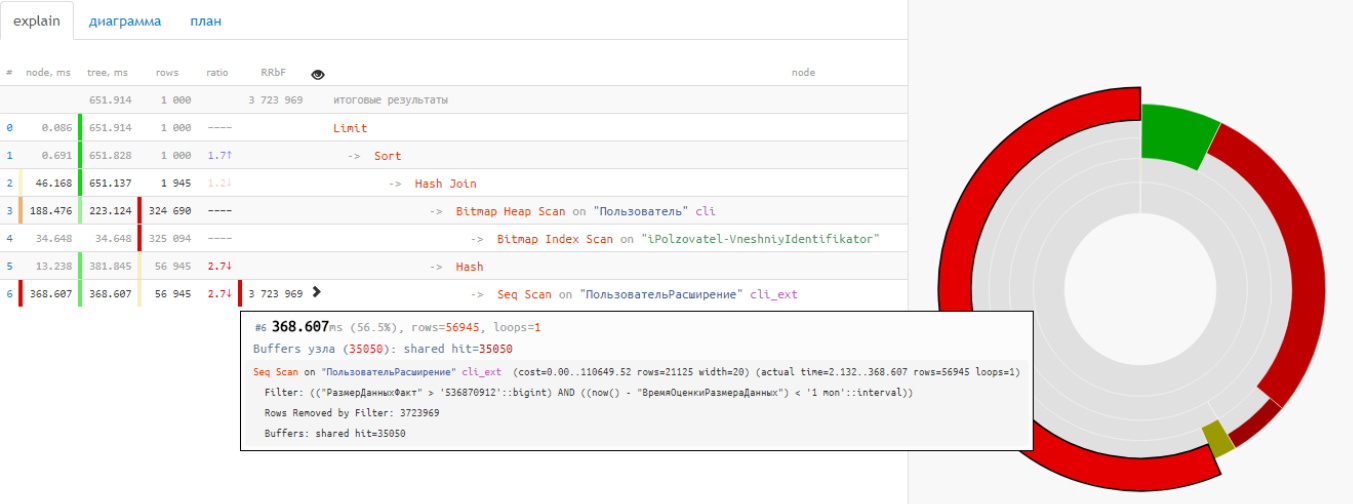
Проблема кроется в фильтрации более 3 миллионов записей по пути. Рассматривая время выполнения отдельных узлов, вы делаете выводы, где допустили ошибку при прогнозировании.
При разборе распределения ресурсов CTE возникли сложности. Для иллюстрации рассмотрим пример:

Создали таблицу, прочитали оттуда две записи: первую и со смещением на 100. План запроса выглядит так:
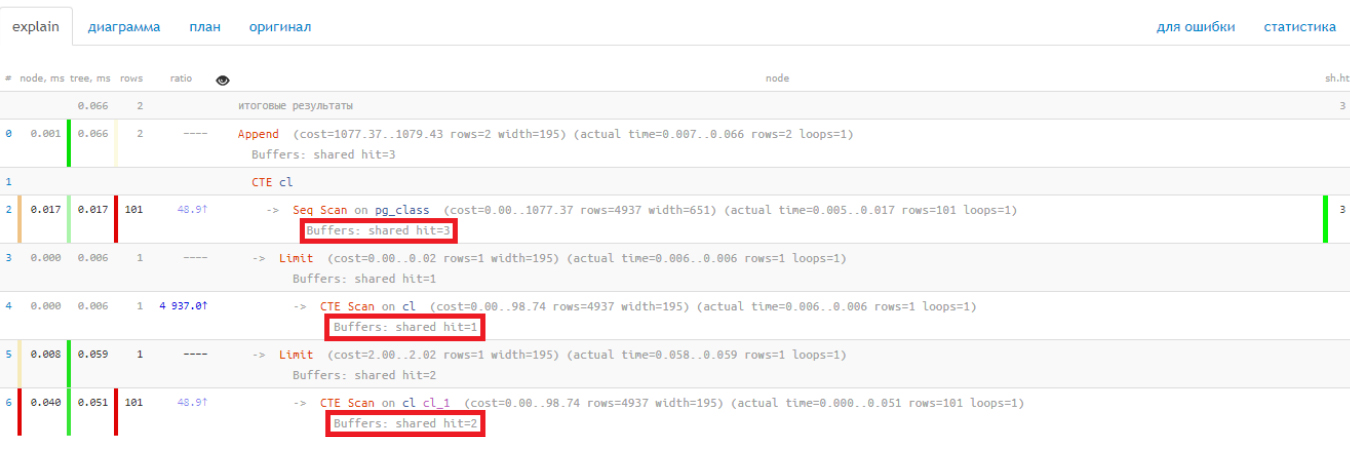
Посмотрите на количество потреблённых данных. На последовательное сканирование ушло 3 страницы, первый CTE scan занял 1, а второй – 2. Покажется, будто потребление составило 6 страниц, но в действительности это те же 3 страницы, что и в Seq scan.
Получается, распределение ресурсов в плане вовсе не дерево – ациклический направленный граф. Для понимания взгляните на схему выполнения предыдущего запроса, где видно, что ресурсы расходятся на 2 потребителя:
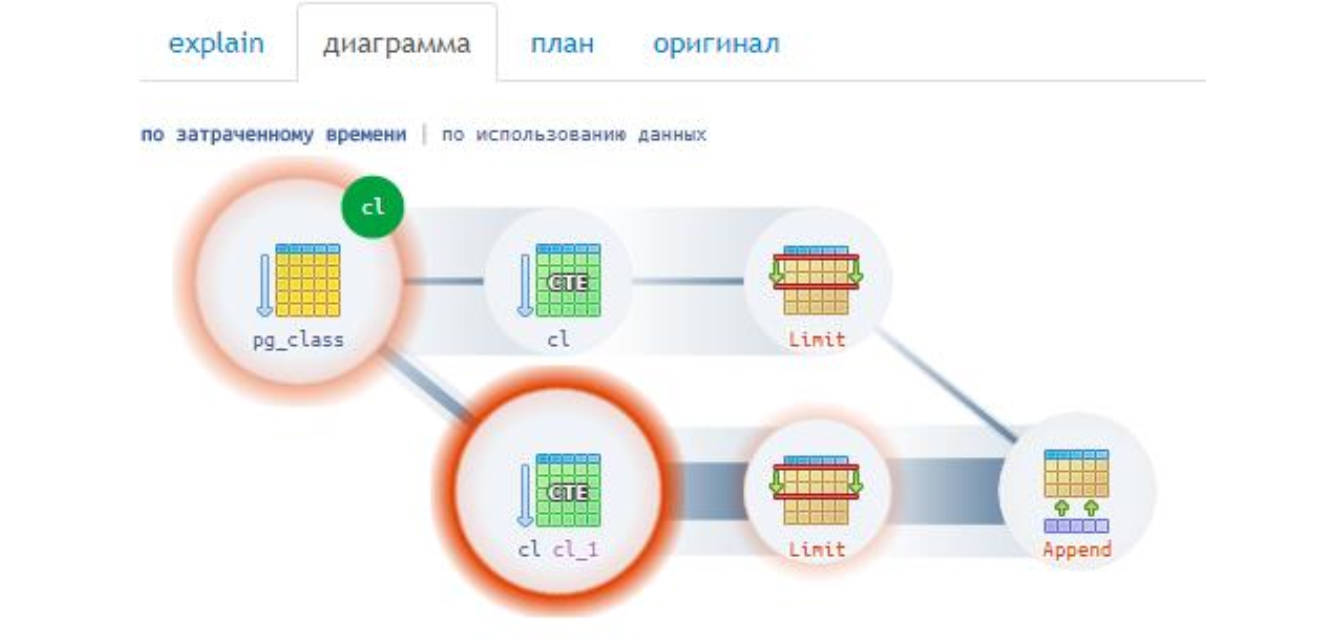
В реальности запросы и схемы посложнее. Главное, что благодаря красной подсветке разработчик видит узкое место без изучения плана полностью:
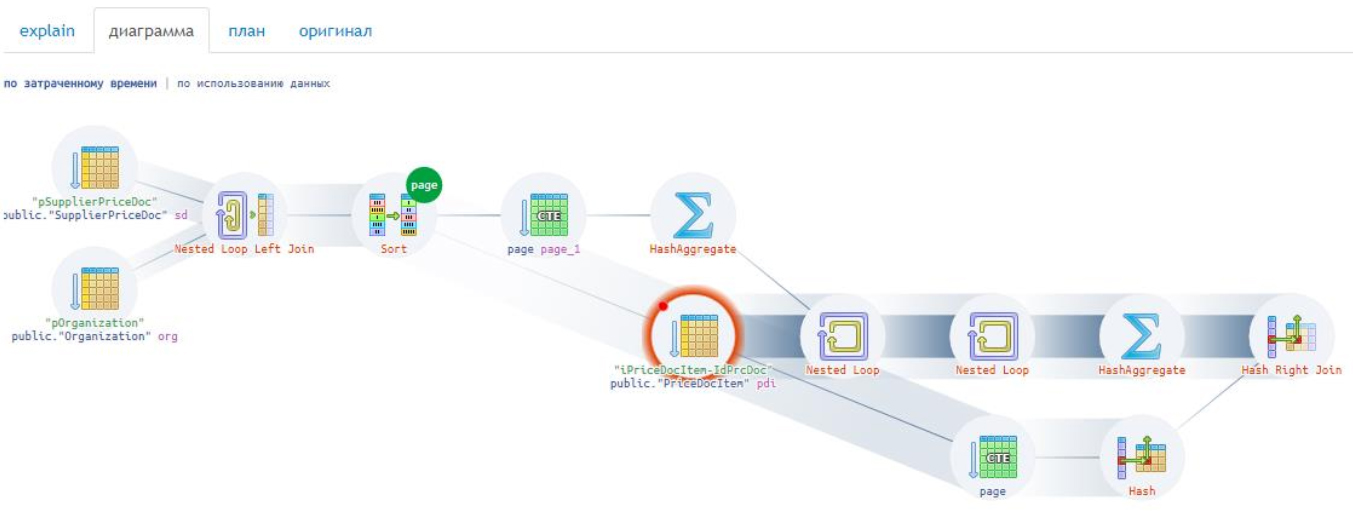
Чаще вы встречаетесь с подобными случаями:
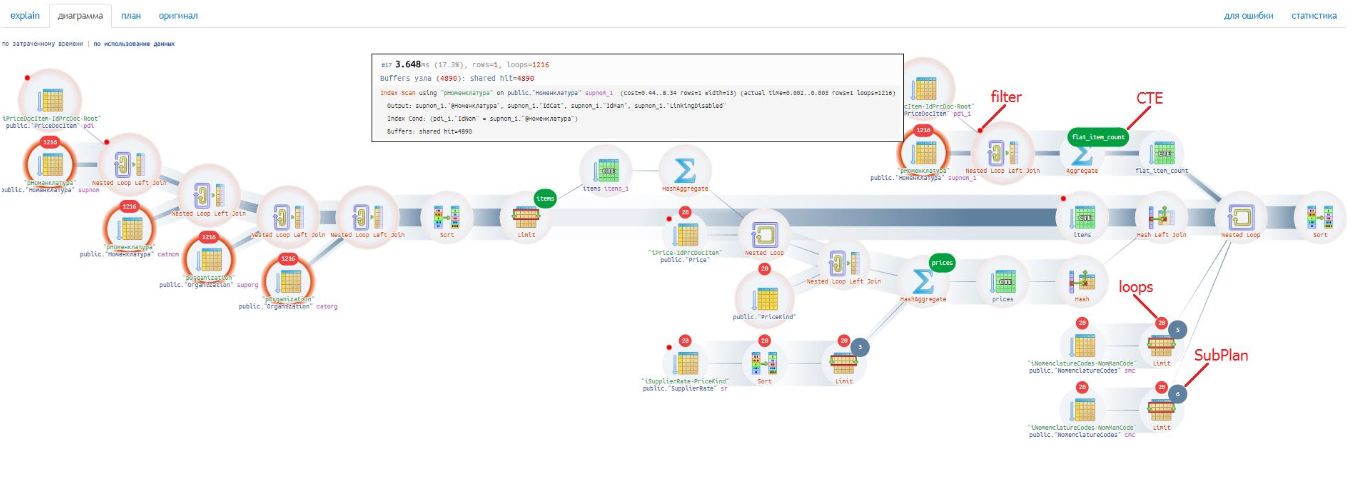
На схеме видно то, что облегчает разработчику анализировать план запроса:
- отсутствие вынесенных отдельно узлов
CTE,SubPlan: они отображаются в информационном порядке над первыми под ними узлами; - красная точка – обозначение фильтрации, которая иногда делает ситуацию критической и требует проверки;
- число внутри красной фигуры над узлом – количество циклов. Если число четырёхзначное, обратите внимание на эту операцию.
В конце концов, проблем с планами запросов становится меньше, но если у вас сотни серверов, появляется ещё одна проблема – тонны логов.
Консолидация логов
Для объединения информации PostgreSQL предоставляет дефолтный инструмент pg_stat_statements. При использовании этого модуля возникают такие неудобства:
- сбор статистики происходит по запросам, а не планам, что снижает информативность;
- нет группировки одинаковых запросов из разных схем;
- статистика ограничена показателями агрегации: вы не узнаете, когда выполнялся запрос и в какой базе.
С учётом копипасты в масштабах выгоднее написать собственный коллектор, который по SHH обращается к серверу PostgreSQL, запускает там tail и получает зеркальный трафик логов. Причём эта информация доступна онлайн. Для сохранения ресурсов коллектор поддерживает соединение и периодически проверяет pg_stat_activity и pg_locks.
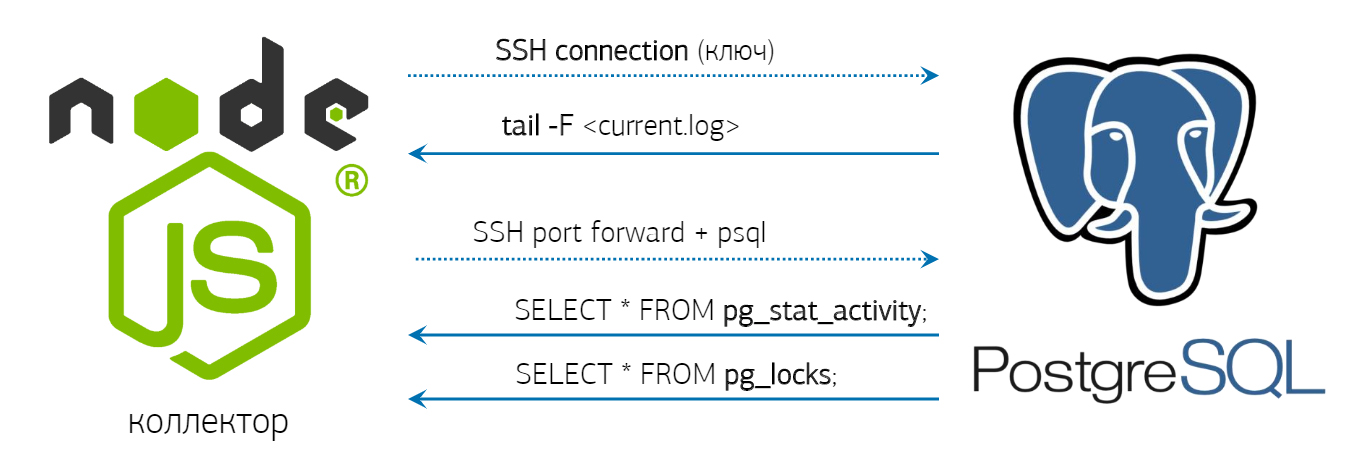
При мониторинге сотен серверов приходится ускорять запись в базу. Когда объёмы данных большие, нет ничего быстрее COPY ... FROM STDIN. Если у вас 50 тысяч запросов в секунду на 100 серверов, то получите 100–150 гигабайт логов в сутки. Поэтому сразу становится вопрос секционирования по дням, очень быстрого «потокового» COPY и частичного отказа от триггеров. Приходится убирать внешние ключи, потому что каждый раз на проверку тратятся ресурсы. Агрегация и хеширование переносятся на коллектор, а для каждой сущности в базе выделяется отдельный COPY-поток, который закрывается через заданный интервал времени для завершения транзакции.
Тестирование показало, что данные лучше отправлять сразу после создания, то есть без буферизации. Поскольку перешли на вставку через COPY, в словарных таблицах понадобился триггер BEFORE INSERT для избежания дубликатов, который с версии 9.5+ заменяется на INSERT ... ON CONFLICT DO NOTHING.
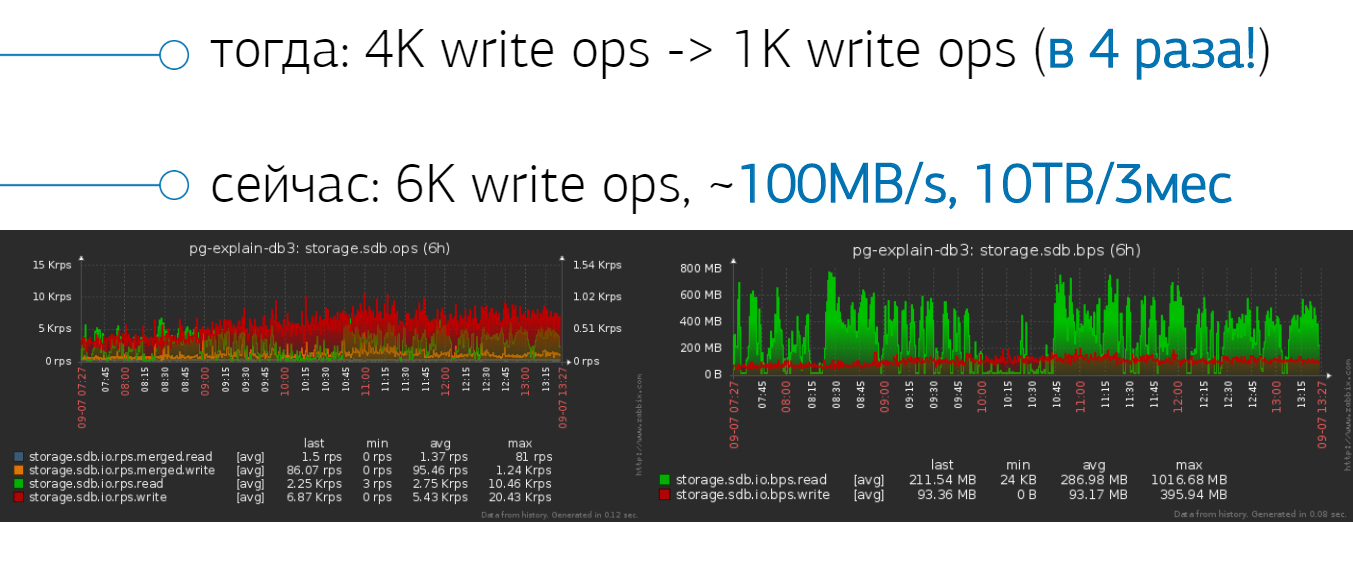
Благодаря COPY-потоку удалось снизить нагрузку с 4 тысяч операций в секунду до 1 тысячи. При дальнейшем увеличении нагрузки до 6 тысяч потоковая запись идёт со скоростью 100 мегабайт в секунду. Сколько разработчик будет разбираться с проблемой? За три месяца уж справится с любым сложным запросом, при этом размер архива оставит 10 терабайт.
Структуризация собранной информации
Что делать с миллионами сохранённых планов? Без структурирования ничего не понятно, поэтому нужна такая информация о запросе:
- какое приложение или метод выполняли его;
- на каком сервере или базе данных;
- в чём выражалась проблема, с точки зрения плана выполнения.
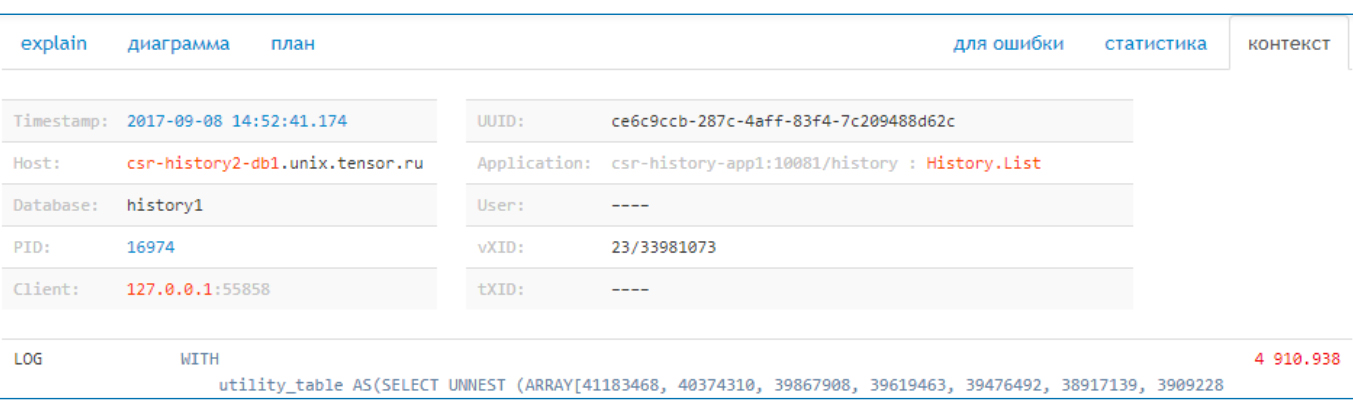
Для определения «хозяина» запроса используйте SET APPLICATION NAME = '<host>:<method>'. Длину названия сервера или метода иногда приходится подрезать из-за ограничения 63 байта в поле name. С помощью настройки log_line_prefix вы получите необходимую информацию. При log_line_prefix = '%m [%p:%v] [%d] %r %a' заголовок лога выглядит так:

Отсюда легко отобразить пользователю, когда и на каком сервере базы выполнялся запрос, PID процесса и другие данные, которые вы выбрали при конфигурации log_line_prefix.
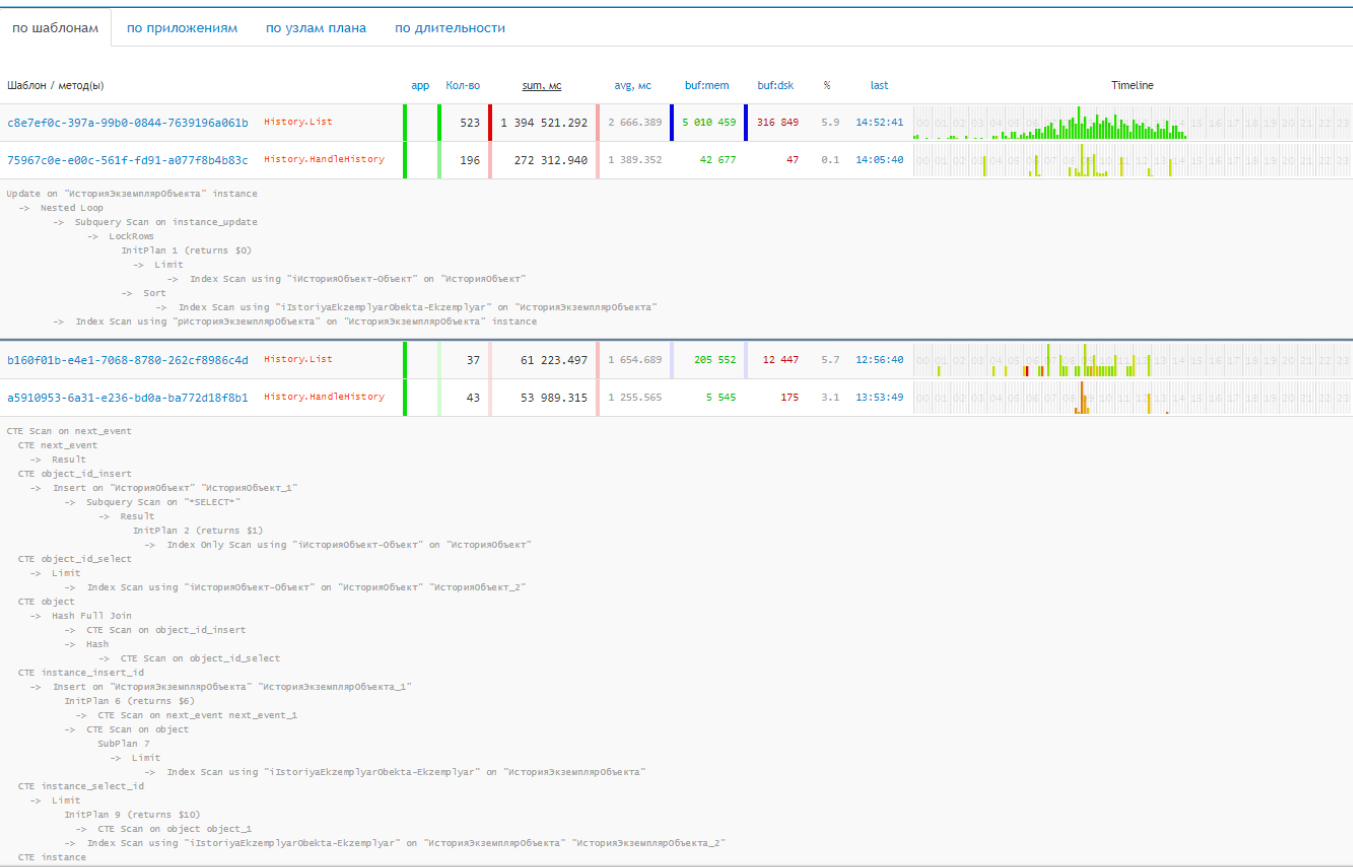
Помимо именования, запросы разделяют по серверам и дням, а также рассматривают в пределе шаблона (сокращённого плана), приложения или метода и узла. Шаблоны уменьшают количество анализируемых объектов в несколько раз, например, из 1121 получаем 80. С помощью timeline вы находите общие паттерны поведения и сопоставляете с действиями.

При анализе планов важно обратить внимание на следующие показатели:
- количество фактов выполнения шаблона или метода;
- среднее и суммарное время для понимания, какая модель запроса заняла процессорные ресурсы;
- количество потреблённых страниц, чтобы отследить, какой запрос постоянно читает с диска и найти выход из ситуации;
- timeline помогают понять распределение посуточно, увидеть периодичность и частоту выполнения запроса.
Выяснилось, что подобный мониторинг нужен и по отдельным узлам, а также по динамическим вроде CTE scan и Subquery.
На основании полной информации в компании сделали подсказчик, который рекомендует разработчику те или другие решения, благодаря выявленным паттернам поведения:

Заключение
Для решения проблем с производительностью запросов в PostgreSQL нужен детальный анализ плана запроса. С учётом разбора времени выполнения каждого узла, потребления ресурсов и отслеживания поведенческих паттернов вы понимаете, какая операция валит показатели и что требуется исправить.
Когда речь идёт о сотнях серверов, важно консолидировать логи. Теперь вы знаете, насколько нетривиальная эта задача и какие принципы применять.
Комментарии