
Создание модели начинается с подготовки данных
Как и обычные сверточные нейронные сети, визуальные трансформеры обучаются в контролируемом режиме. Это означает, что модель обучается на наборе данных, состоящем из изображений и соответствующих им меток. Каждый единичный пример в наборе называется точкой данных.

Подготовка точки данных
Модель обучается на множестве точек данных, то есть размеченных изображений. Чтобы понять, как именно это происходит, мы проследим за подготовкой отдельной точки данных. На этом этапе нас интересует только изображение, а не его метка (метки нам понадобятся на следующем этапе). Основная идея всех описанных ниже манипуляций – преобразовать исходное изображение в структурированный входной массив, который трансформер сможет эффективно обработать.
Каждое изображение разделяется на равные части размером p x p пикселей.

Затем эти фрагменты преобразуются в векторы размерности p'= p²*c, где p – размер фрагмента, а c – количество каналов.

После этого векторы фрагментов изображения кодируются с помощью линейного преобразования. В результате получается векторное представление фрагмента размера d.
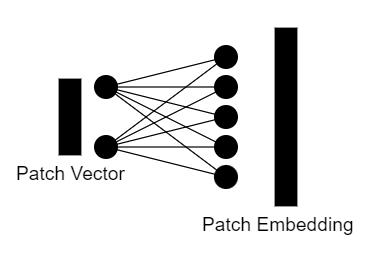
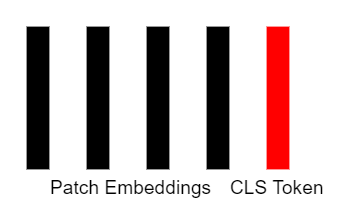
После того как мы получили векторы представления для всех фрагментов изображения, у нас есть массив размера n x d, где n – количество фрагментов изображения, а d – размер эмбеддинга фрагмента.

Для эффективного обучения модели необходимо расширить массив векторных представлений фрагментов дополнительным вектором, который называется токеном классификации (CLS token). Этот вектор является обучаемым параметром сети и инициализируется случайно. Важно отметить, что у нас только один токен классификации, и мы добавляем его ко всем точкам данных.
До сих пор наши векторные представления не содержали никакой информации о позиции фрагментов. Поэтому мы добавляем к каждому из них обучаемый, случайно инициализированный позиционный вектор. Такой же вектор нужно добавить к токену классификации.
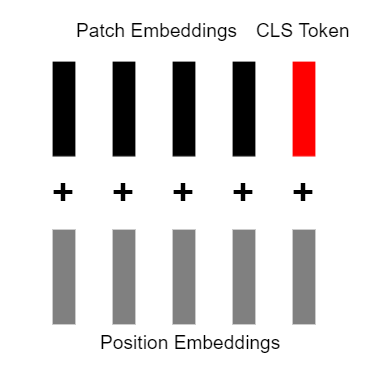
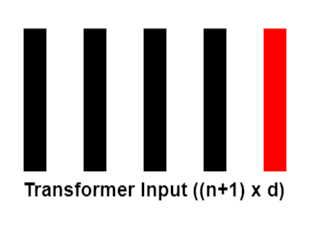
После добавления позиционных векторов, у нас получился массив размера (n+1) x d, где n – количество фрагментов, на которые было разбито изображение, а d – размер векторного представления каждого фрагмента. Этот массив будет подаваться на вход трансформеру, который будет его дальше обрабатывать и преобразовывать.

Машинное обучение
На курсе «Базовые модели ML и приложения» наши опытные преподаватели помогут тебе разобраться в сложных алгоритмах и концепциях, а также покажут, насколько увлекательным и полезным может быть применение машинного обучения на практике. На курсе ты:
- Познакомишься с основными моделями машинного обучения.
- Научишься выбирать и применять подходящие tree-based модели.
- Получишь основу для дальнейшего изучения более сложных нейронных сетей.
Программа курса
- Бустинг, Бэггинг и Ансамбли.
- Алгоритмы рекомендаций.
- Архитектуры нейросетей.
Что происходит внутри трансформера
Создание векторов Q, K и V
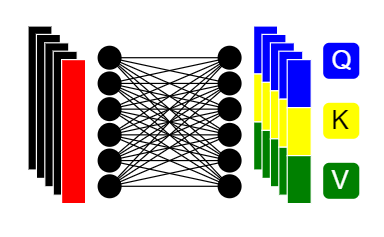
Входной массив, состоящий из эмбеддингов фрагментов изображения и токена классификации, поступает в трансформер. Внутри трансформера векторные представления линейно преобразуются в три равных по размеру вектора:
- Q (Query Vector) – вектор запроса
- K (Key Vector) – вектор ключа
- V (Value Vector) – вектор значения
Для каждого входного элемента будет создано (n+1) наборов векторов Q, K и V, где n – количество входных элементов. Ключевая идея этого шага – разбить каждый входной вектор на три отдельных вектора, которые будут играть различные роли в последующих операциях трансформера:
- Вектор запроса Q представляет текущий элемент, по которому мы ищем связи с другими элементами.
- Вектор ключа K представляет все элементы, по которым мы будем искать соответствия с текущим запросом Q.
- Вектор значения V содержит информацию, которую мы хотим извлечь из этих соответствий.
Механизм внимания
Процесс вычисления оценок внимания – важная часть механизма внимания в архитектуре трансформера. Этот процесс выглядит так:
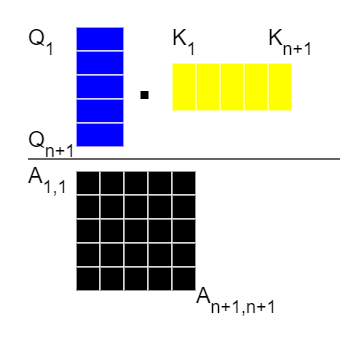
Вычисление матрицы оценок внимания. Мы берем все векторы запроса Q и перемножаем их со всеми векторами ключа K. В результате получается матрица оценок внимания A размером (n+1) x (n+1), где n – количество входных элементов. Каждый элемент этой матрицы представляет собой оценку внимания между соответствующими парами входных элементов.
Применение функции Softmax. Затем мы применяем функцию Softmax к каждой строке матрицы оценок внимания A. Это приводит к тому, что каждая строка матрицы становится вектором вероятностей, сумма элементов которого равна 1. Таким образом, мы получаем нормализованные значения оценок внимания, отражающие относительную важность каждого элемента входных данных для текущего элемента.
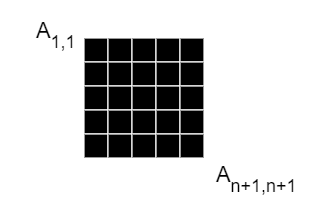
Вычисление агрегированной контекстной информации. Для получения агрегированной контекстной информации для первого входного элемента мы сначала фокусируемся на первой строке матрицы нормализованных оценок внимания, а затем используем значения этой строки в качестве весов для соответствующих векторов значений V. Результатом будет вектор агрегированной контекстной информации для первого входного элемента. Этот вектор отражает контекст, который необходим для дальнейшей обработки первого входного элемента.
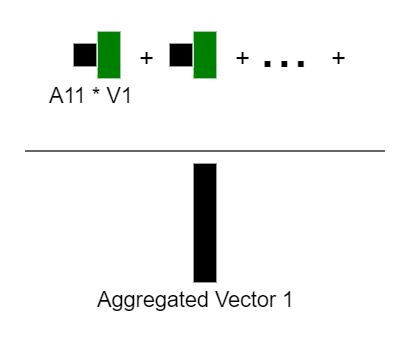
Этот процесс вычисления оценок внимания и агрегированной контекстной информации повторяется для каждого входного элемента. Результатом работы механизма внимания будут (n+1) агрегированных векторов контекстуальной информации – один для каждого массива векторных представлений изображения и один для токена классификации.

Блок многомерного самовнимания
Мы уже рассмотрели, что происходит в блоке внимания:
- Входные векторы разделяются на Q, K и V векторы.
- Вычисляется матрица оценок внимания.
- Выполняется нормализация матрицы оценок с помощью Softmax.
- Подготавливается агрегированная контекстная информация.
В блоке многомерного самовнимания весь этот процесс повторяется несколько раз, но с разными линейными преобразованиями векторов Q, K и V. Предположим, что в нашем трансформере используются два блока многомерного самовнимания (на практике таких блоков будет гораздо больше): это означает, что мы получим 2 набора матриц оценок внимания и 2 набора агрегированной контекстной информации.
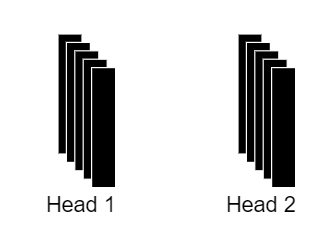
Полученные наборы агрегированной контекстной информации собираются вместе в один общий вектор. Этот объединенный вектор затем линейно преобразуется в вектор того же размера, что и исходные входные векторы.
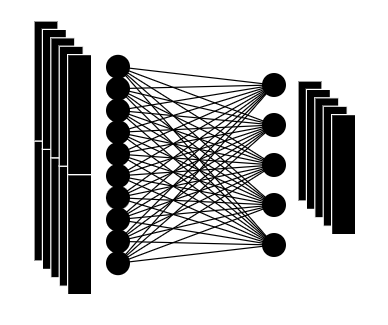
В итоге, на выходе мы получаем набор векторов того же размера, что и на входе, поскольку слой внимания сохраняет размерность входных векторов, и обогащает их контекстной информацией, извлеченной из нескольких блоков многомерного самовнимания.
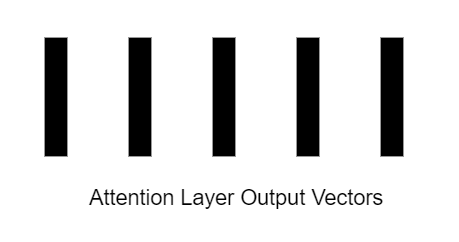
Использование блоков многомерного самовнимания позволяет трансформерам фокусироваться на различных аспектах входных данных параллельно, что повышает их способность учитывать разнообразные контекстуальные связи. Это является ключевой особенностью, обеспечивающей высокую эффективность трансформеров в задачах компьютерного зрения (и обработки естественного языка).
Остаточные связи
После блока внимания следует этап остаточных связей. На этом этапе мы берем вектор агрегированной контекстной информации, полученный на выходе блока внимания, и суммируем его с входным вектором, который подавался на блок внимания. В результате этого суммирования мы получаем вектор того же размера, что и входные данные.
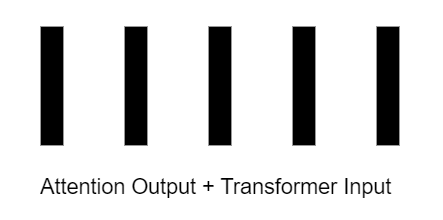
Остаточные связи не только позволяют сохранять размерность данных на протяжении всей архитектуры трансформера, но и дают модели несколько важных преимуществ:
- Предотвращают проблему исчезающих градиентов – помогают градиентам свободно проходить через слои, предотвращая их затухание.
- Облегчают обучение – позволяют модели изучать лишь небольшие изменения относительно входных данных.
- Улучшают производительность – помогают трансформерам решать многие типы сложных задач с максимальной скоростью.
Полносвязная нейросеть
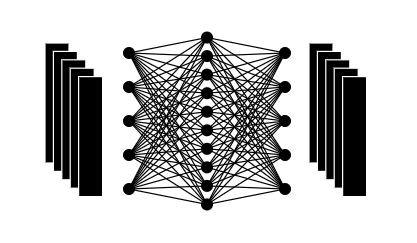
После применения механизма внимания и добавления остаточных связей, полученные векторы подаются на вход полносвязной нейронной сети. Эта полносвязная сеть состоит из нескольких слоев с нелинейными функциями активации (ReLU, GELU, Swish и т. д).
Основная цель этого компонента – дополнительно преобразовать и обогатить представление входных данных, используя нелинейные функции.
Финальный результат работы трансформера
На выходе полносвязной нейронной сети мы получаем векторы того же размера, что и на входе трансформера. Затем к выходу полносвязной сети применяется еще один этап остаточных связей, где выходные векторы суммируются с входными векторами слоя трансформера. В результате мы получаем входные данные, обогащенные контекстной информацией, извлеченной с помощью механизма внимания и дополнительной обработки полносвязной сетью.
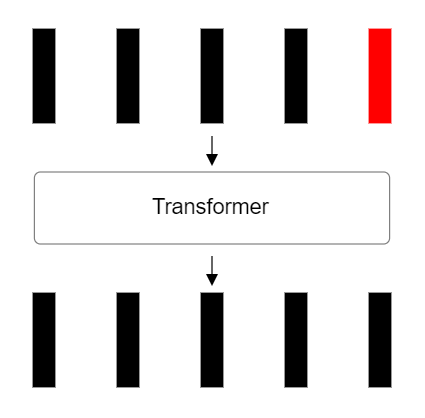
Повторение обработки в слое трансформера
Важно отметить, что весь описанный процесс преобразования и насыщения данных контекстной информацией повторяется несколько раз. В современных моделях количество слоев-трансформеров варьируется от 6 до 24 и более: многократное прохождение векторов сквозь чередующиеся слои многомерного самовнимания и полносвязные нейронные сети позволяет модели последовательно извлекать все более сложные и абстрактные представления из входных данных.
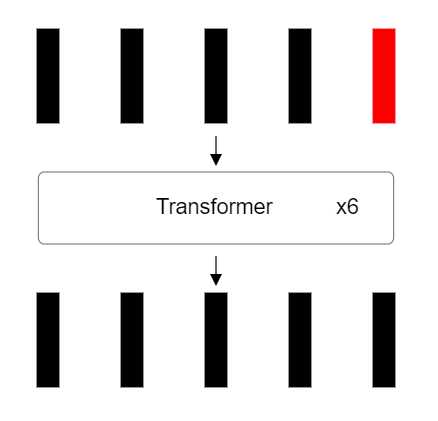
Идентификация токена классификации
Итак, мы прошли через несколько повторяющихся слоев-трансформеров, которые преобразовывали и обогащали представление входных данных. Как упоминалось в самом начале, при разделении входного изображение на фрагменты, мы добавили к массиву специальный токен классификации.
Этот токен классификации прошел через все слои трансформеров вместе с фрагментами изображения и теперь содержит в себе обобщенное представление всего входного изображения. Выходной вектор, соответствующий этому токену, будет использован на следующем этапе для предсказания класса изображения.
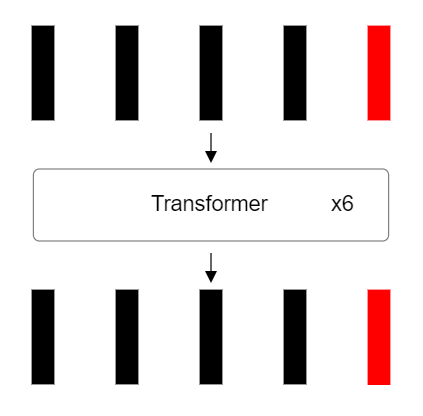
Предсказание принадлежности изображения к определенному классу
На финальном этапе мы берем выходной вектор токена классификации и подаем его на вход полносвязной нейронной сети. Эта сеть предназначена для предсказания вероятностей принадлежности входного изображения к различным классам. На выходе мы получаем вектор вероятностей, соответствующий распределению классов.
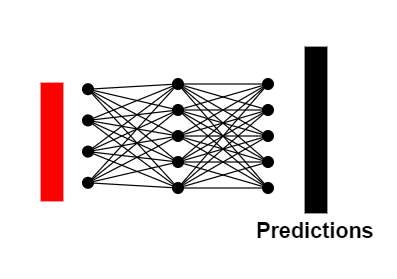
Обучение визуальных трансформеров
Для обучения ViT используются стандартные техники обучения нейронных сетей – метод обратного распространения ошибки и градиентный спуск.
Функцией ошибки в данном случае является перекрестная потеря, которая сравнивает предсказанные вероятности классов с истинными метками классов. Путем минимизации этой функции ошибки модель обучается корректно предсказывать классы входных изображений.
Заключение
Mы детально рассмотрели архитектуру и принцип работы Vision Transformer – модели компьютерного зрения, основанной на трансформерах.
Ключевыe особенности визуальных трансформеров:
- Разделение входного изображения на фрагменты и их линейное преобразование.
- Использование механизма многомерного самовнимания для моделирования взаимосвязей между фрагментами.
- Применение остаточных соединений и полносвязных нейронных сетей для обогащения представлений.
- Многократное повторение трансформер-слоев для последовательного извлечения сложных визуальных признаков.
- Выделение специального токена классификации для итогового предсказания класса изображения.
Эффективность этого подхода подтверждается впечатляющими результатами, достигнутыми на популярных бенчмарках компьютерного зрения. Успех ViT демонстрирует, что архитектура трансформера, изначально разработанная для задач обработки естественного языка, может быть с успехом применена и в области компьютерного зрения. Дальнейшие исследования в этом направлении, вероятно, приведут к появлению еще более мощных и универсальных ИИ-моделей.
При подготовке статьи использовалась публикация A Visual Guide to Vision Transformers.
Комментарии