

За последний год мы поработали с десятками команд, которые создавали агентов на основе больших языковых моделей (LLM) в разных индустриях. И знаете что? Самые успешные решения не использовали навороченные фреймворки или специальные библиотеки. Вместо этого они строились на простых, комбинируемых паттернах.
В этой статье мы поделимся опытом работы с клиентами и собственными наработками, а также дадим практические советы разработчикам по созданию эффективных агентов.
Что такое «ИИ-агент»?
Термин «ИИ-агент» можно определить по-разному. Некоторые наши клиенты называют агентами полностью автономные системы, которые работают самостоятельно длительное время и используют различные инструменты для выполнения сложных задач. Другие применяют этот термин к более строгим реализациям, следующим предопределенным сценариям. В Anthropic мы относим все эти варианты к агентным системам, но проводим важное архитектурное разделение между рабочими процессами (workflows) и агентами:
- Рабочие процессы — это системы, где LLM, которые работают по заранее прописанному сценарию. Как конвейер на заводе — все четко и предсказуемо.
- Агенты — системы, где LLM самостоятельно управляют своими процессами и использованием инструментов, контролируя способ выполнения задач.
Когда стоит (и не стоит) использовать агентов?
При создании приложений с LLM мы рекомендуем искать максимально простое решение и усложнять его только при необходимости. Возможно, вам вообще не нужны агентные системы 🤔.
- Рабочие процессы обеспечивают предсказуемость и стабильность для четко определенных задач.
- Агенты же лучше подходят, когда требуется гибкость.
Однако для многих приложений достаточно оптимизации единичных вызовов LLM с использованием поиска и контекстных примеров.
О фреймворках
Существует множество фреймворков, упрощающих реализацию агентных систем:
Эти фреймворки облегчают старт, упрощая стандартные низкоуровневые задачи вроде вызова LLM, применения инструментов и объединения вызовов. Однако они часто создают дополнительные слои абстракции, которые могут скрывать базовые промты (запросы) и ответы, что затрудняет отладку.
Посмотрите наш сборник готовых решений и примеров кода.
Строительные блоки: LLM, рабочие процессы и агенты
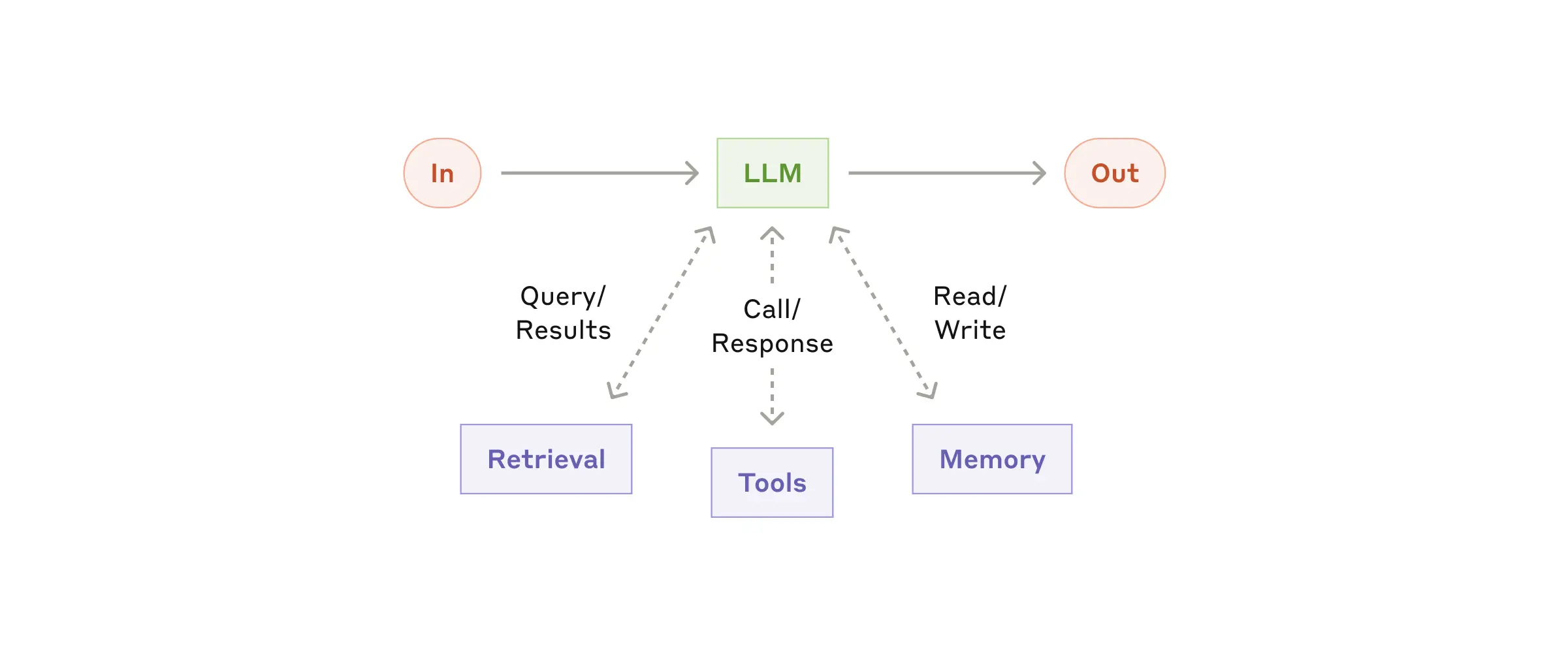
Базовый строительный блок: LLM
Основным строительным блоком агентных систем является языковая модель (LLM), прокачанная дополнительными возможностями:
- поиск информации;
- работа с инструментами;
- память.
Современные модели активно используют эти возможности – они могут сами формировать поисковые запросы, выбирать подходящие инструменты и решать, какую информацию стоит сохранить. (Прямо как Skynet, только добрее.)
На что обратить внимание при реализации
При внедрении такой системы мы рекомендуем сосредоточиться на двух ключевых аспектах:
- Адаптация этих возможностей под ваши конкретные задачи.
- Обеспечение простого и хорошо документированного интерфейса для вашей LLM.
Хотя существует множество способов реализации этих улучшений, один из подходов – использование недавно выпущенного Model Context Protocol. Он позволяет разработчикам интегрироваться с растущей экосистемой сторонних инструментов через простую клиентскую реализацию.
В дальнейшем мы будем исходить из того, что каждый вызов LLM имеет доступ к этим расширенным возможностям. Это как дать модели «суперсилы», которые она может использовать для решения более сложных задач.
Цепочки промптов
Цепочка промптов – разбиение сложной задачи на последовательность шагов, где каждый вызов LLM обрабатывает результат предыдущего. Как конвейер, где каждый рабочий выполняет свою часть работы и передает результат дальше.
В любой момент мы можем добавить программные проверки (что-то вроде «контролера качества») между этапами, чтобы убедиться, что процесс идет по плану. Как отдел технического контроля на заводе, только без злобного начальника цеха.
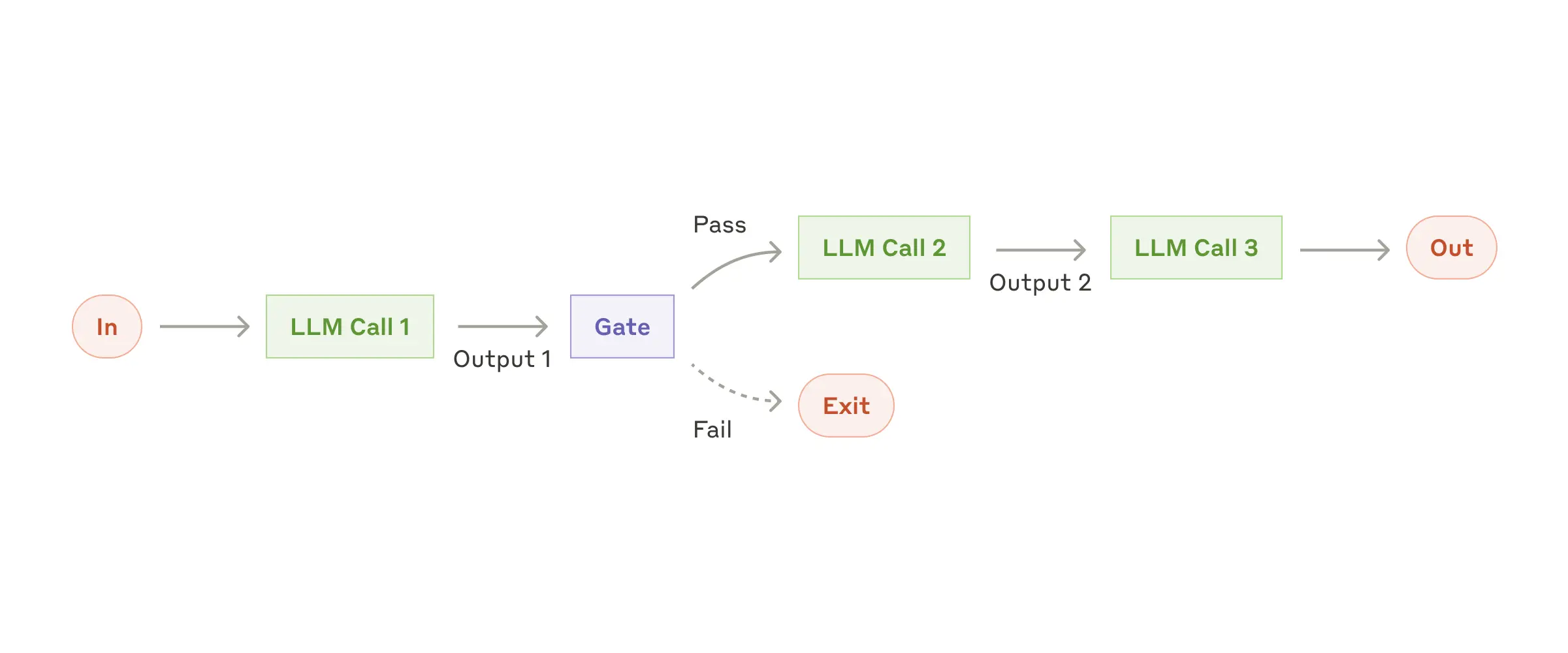
Когда это использовать
Такой подход идеально подходит для ситуаций, когда задачу можно четко разделить на фиксированные подзадачи. Основная идея здесь – пожертвовать скоростью ради точности, сделав каждый отдельный вызов LLM проще и понятнее.
Примеры использования
Вот пара реальных сценариев, где цепочки промптов реально работают:
- Сначала генерируем маркетинговый текст на одном языке, потом переводим его на другой.
- Сначала создаем структуру документа, проверяем, что она соответствует всем требованиям, и только потом пишем сам документ на основе проверенного плана.
В обоих случаях разбиение на этапы дает нам больше контроля над процессом и лучшее качество конечного результата.
Маршрутизация
Маршрутизация определяет тип входящего запроса, а затем направляет его к специализированному обработчику. Это как умный диспетчер, который знает, кому именно передать конкретную задачу.
Такой подход позволяет разделить зоны ответственности и создать более специализированные промпты для каждого типа задач. Без маршрутизации попытка оптимизировать систему под один тип запросов может негативно сказаться на обработке других. Как говорится, нельзя быть экспертом во всем сразу.
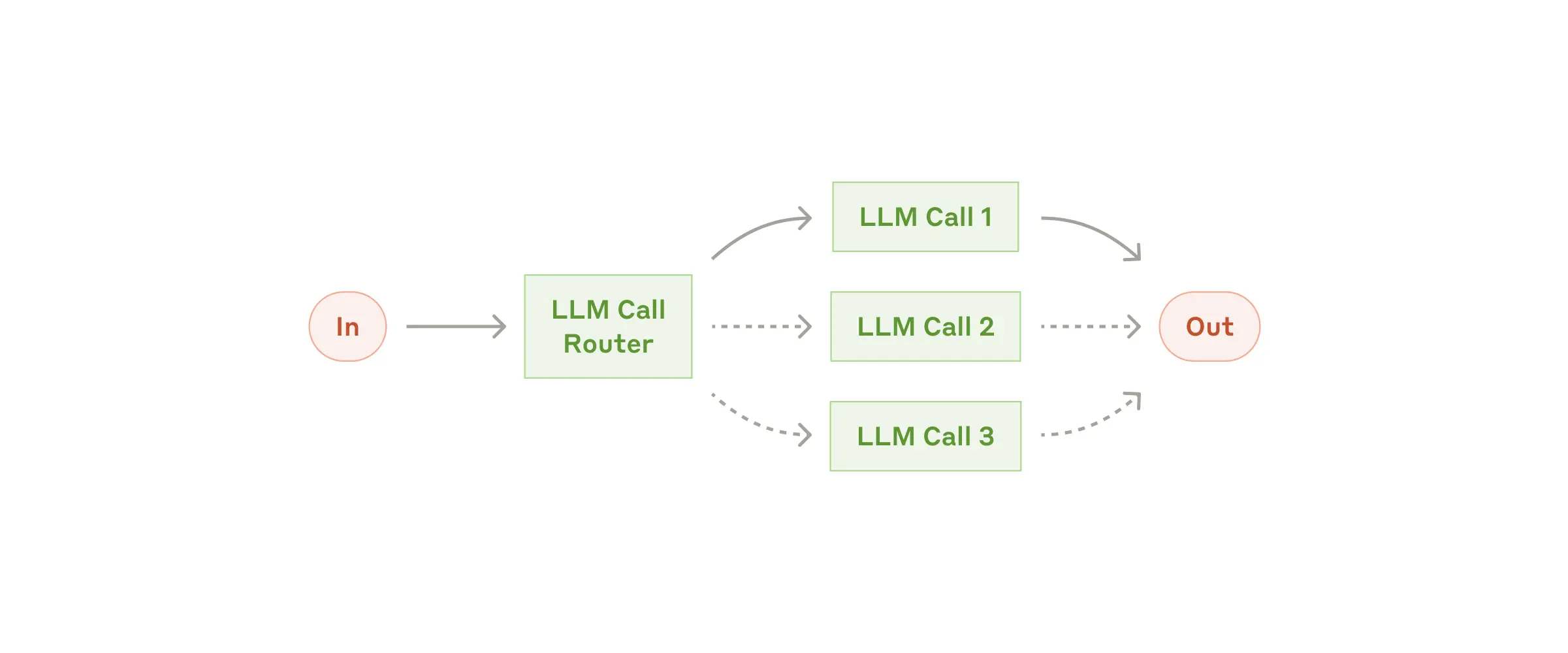
Когда это нужно
Маршрутизация особенно хорошо работает для сложных задач, где есть четко различимые категории, которые лучше обрабатывать по-разному. При этом важно, чтобы классификация могла выполняться точно – будь то с помощью LLM или более традиционных алгоритмов классификации.
Практическое применение
Вот где маршрутизация действительно показывает себя в деле:
- В службе поддержки: разные типы запросов (общие вопросы, возврат средств, техподдержка) направляются в разные процессы обработки, с разными промптами и инструментами.
- В оптимизации ресурсов: простые и типовые вопросы обрабатываются легкими моделями вроде Claude 3.5 Haiku, а сложные и нестандартные направляются к более мощным, как Claude 3.5 Sonnet. Это позволяет найти баланс между стоимостью обработки и скоростью ответа.
Распараллеливание задач
Языковые модели могут работать над задачей одновременно, а их результаты можно программно объединять. Такой подход, который мы называем распараллеливанием, реализуется в двух основных вариантах:
- Разделение на части: представьте, что вы разбиваете сложную задачу на независимые подзадачи. Каждая может решаться параллельно, как будто у вас не один, а целая команда помощников.
- Голосование: здесь мы запускаем одну и ту же задачу несколько раз, чтобы получить разные варианты решения. Это как спросить мнение нескольких экспертов.
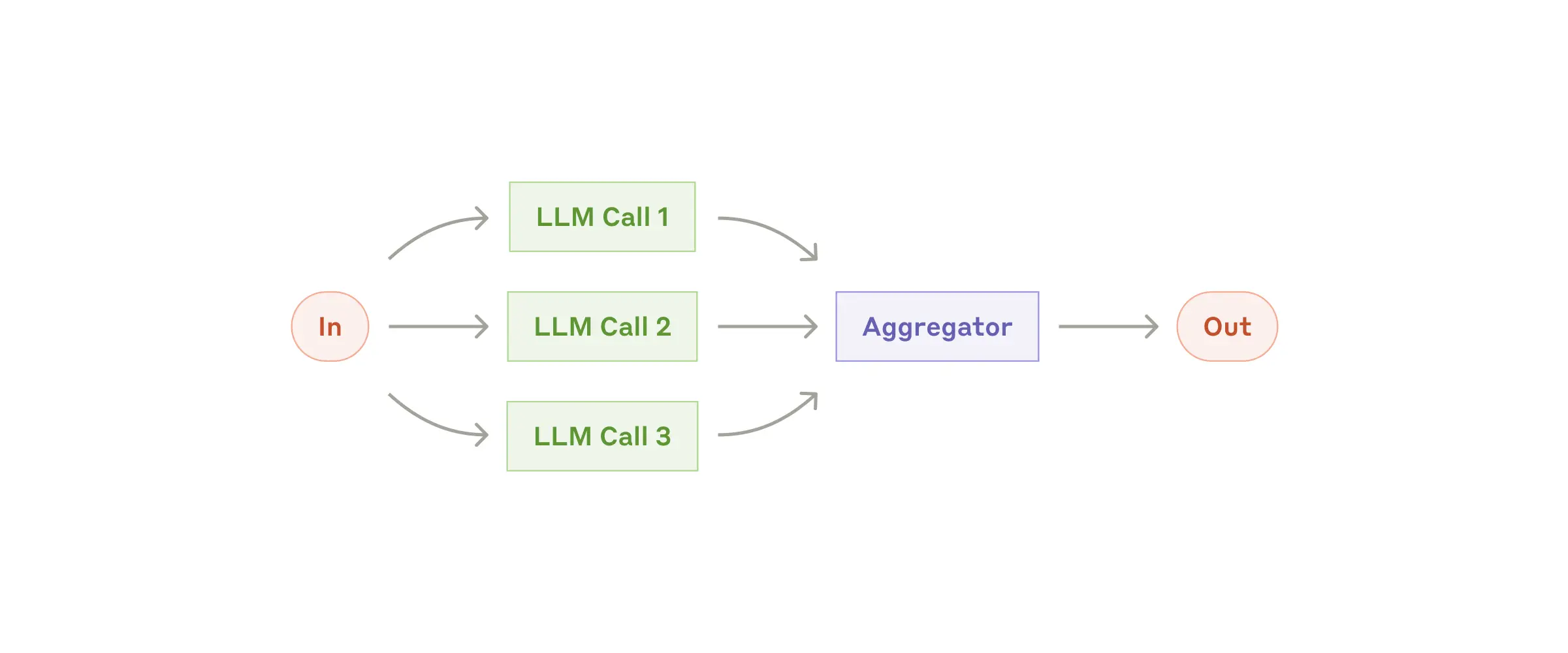
Когда это работает
Распараллеливание особенно эффективно в двух случаях: когда нужно ускорить работу над независимыми подзадачами или когда требуется повысить надежность результата за счет множественных проверок. Практика показывает, что языковые модели справляются лучше, если могут сосредоточиться на одном аспекте задачи за раз.
Практические примеры
Разделение на части:
- Система модерации, где один экземпляр модели обрабатывает запросы пользователей, а другой проверяет их на предмет неприемлемого содержания.
- Автоматизированное тестирование производительности LLM, когда разные экземпляры оценивают различные аспекты работы модели.
Голосование:
- Проверка кода на уязвимости несколькими промптами, каждый из которых ищет свои типы проблем.
- Оценка контента на предмет нарушений, где разные промпты анализируют различные аспекты с разными порогами срабатывания. Такой подход помогает избежать ошибок: как ложных срабатываний (когда нормальный контент ошибочно блокируют), так и пропусков нарушений (когда плохой контент остается незамеченным).
Оркестратор и исполнители
Представьте себе руководителя проекта, который не просто раздает задания, а действительно понимает суть работы. В нашем случае это центральная LLM-модель (оркестратор), которая разбивает сложные задачи на подзадачи, распределяет их между другими моделями-исполнителями и потом собирает все воедино. Прямо как продвинутый скрам-мастер, только без утомительных ежедневных митингов.
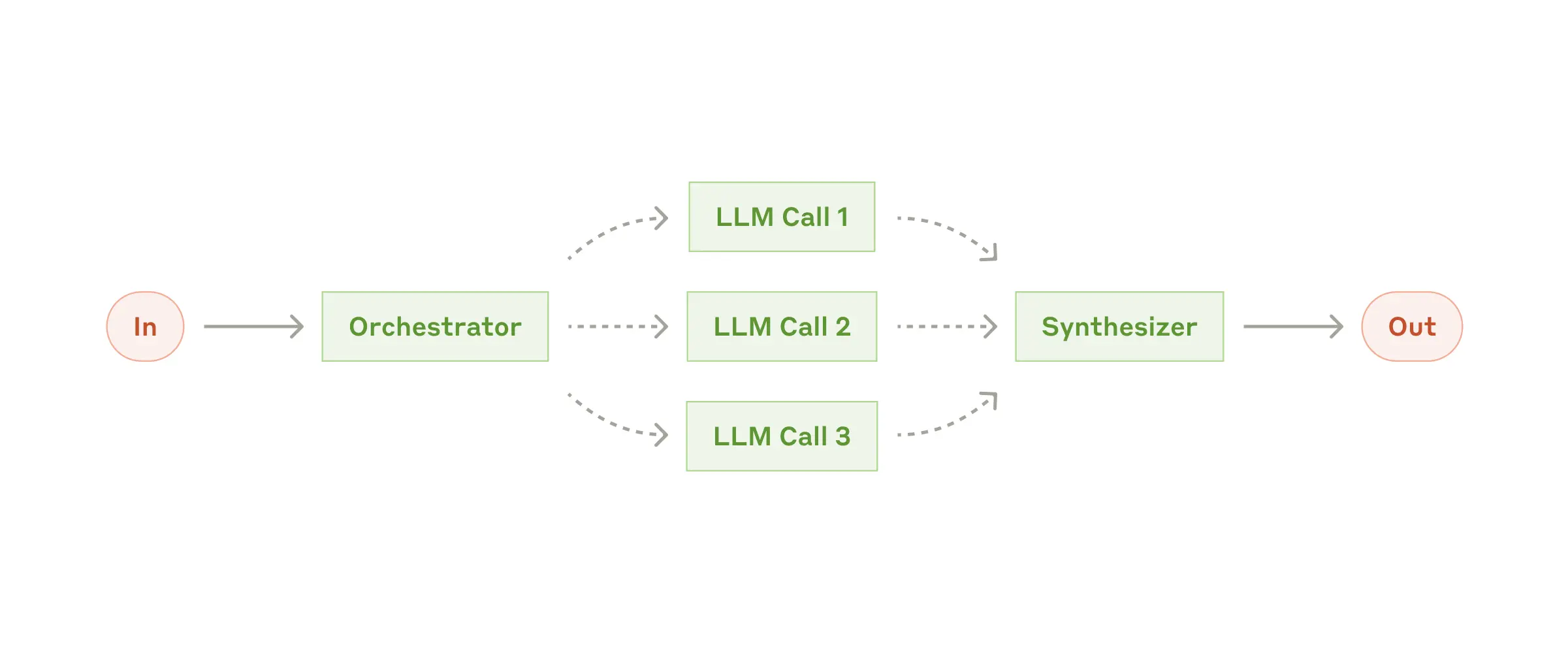
Когда это применять
Этот подход особенно хорош для сложных задач, где заранее трудно предугадать, какие именно подзадачи потребуются. Например, при работе с кодом часто невозможно предсказать, сколько файлов придется изменить и какие именно правки потребуются – все зависит от конкретной задачи.
И хотя внешне этот процесс может напоминать обычное распараллеливание, главное отличие здесь – в гибкости. Подзадачи не определены заранее, а формируются оркестратором на лету, исходя из специфики входящего запроса.
Где это работает
Такой подход особенно эффективен в двух сценариях:
- В инструментах разработки, где требуется вносить сложные изменения сразу в несколько файлов проекта.
- При выполнении поисковых задач, когда нужно собрать и проанализировать информацию из разных источников, чтобы найти действительно релевантные данные.
Оценка и оптимизация
Представьте себе тандем из двух специалистов: один генерирует контент, а второй выступает в роли придирчивого редактора, который не просто критикует, а дает конструктивную обратную связь. Примерно как в паре «разработчик-тестировщик», только без извечного противостояния.
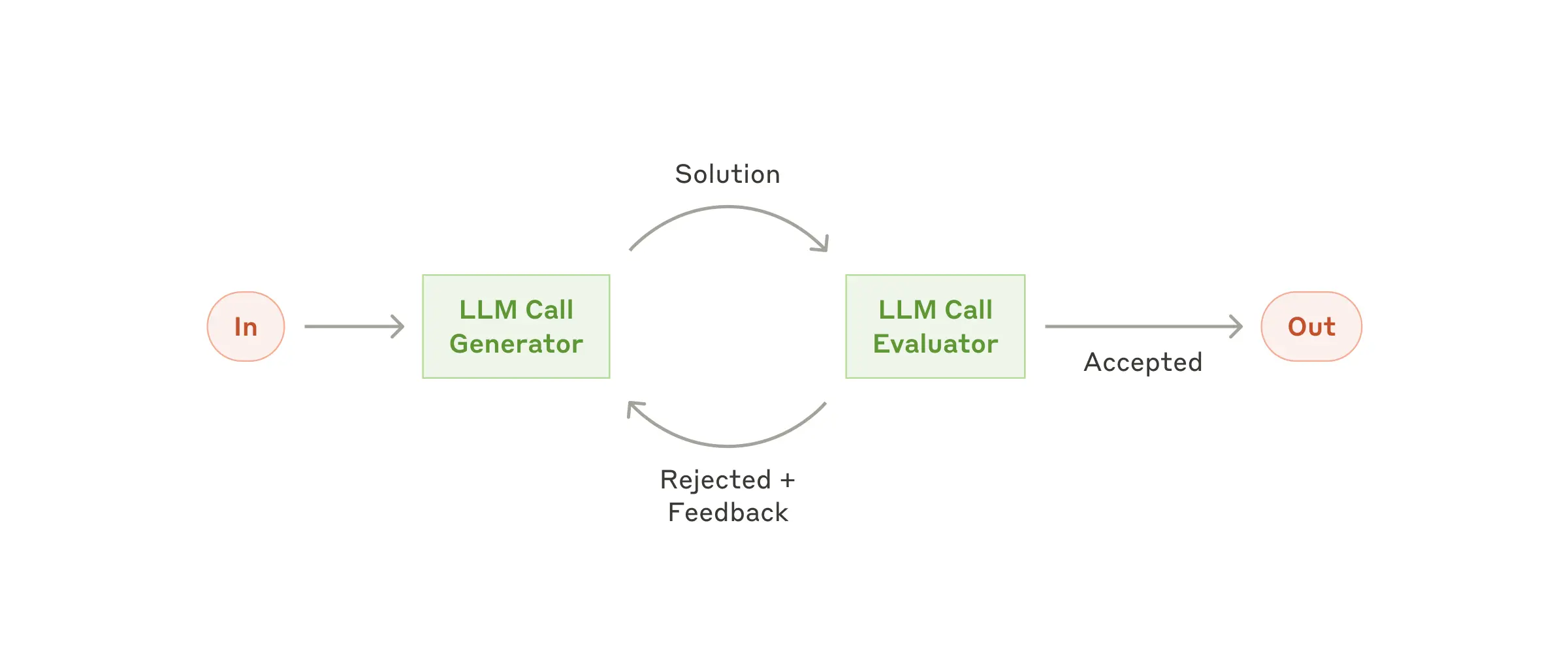
Когда это эффективно
Этот подход особенно хорош, когда у нас есть четкие критерии оценки, а последовательное улучшение дает заметный результат. Работает это в двух случаях: когда мы видим, что ответы LLM становятся лучше после человеческой обратной связи, и когда сама LLM способна давать такую же качественную обратную связь.
Практическое применение
Такой подход особенно хорошо показывает себя в двух сценариях:
- При литературном переводе, когда переводчик-LLM может упустить тонкие нюансы в первой итерации, но оценщик-LLM способен указать на эти упущения и предложить улучшения.
- В сложных поисковых задачах, требующих несколько раундов поиска и анализа. Здесь оценщик определяет, нужны ли дополнительные итерации поиска для получения полной картины.
Агенты: самостоятельные LLM-помощники
По мере того как LLM-модели становятся все более продвинутыми в понимании сложных задач, планировании и использовании инструментов, появляется возможность создавать настоящих цифровых агентов 🤖. Почти как младшие разработчики, только без утренних опозданий на стендап.
Принцип действия
Агент начинает работу после получения команды или короткого диалога с пользователем. Получив четкое понимание задачи, он действует самостоятельно, обращаясь к человеку только при необходимости дополнительной информации или принятия важных решений.
Ключевой момент в работе агента – постоянное получение «обратной связи» от окружения на каждом шаге, будь то результаты использования инструментов или выполнения кода. Это позволяет агенту оценивать свой прогресс и корректировать действия. При этом всегда предусмотрены «стоп-краны» вроде максимального числа итераций – чтобы держать процесс под контролем.
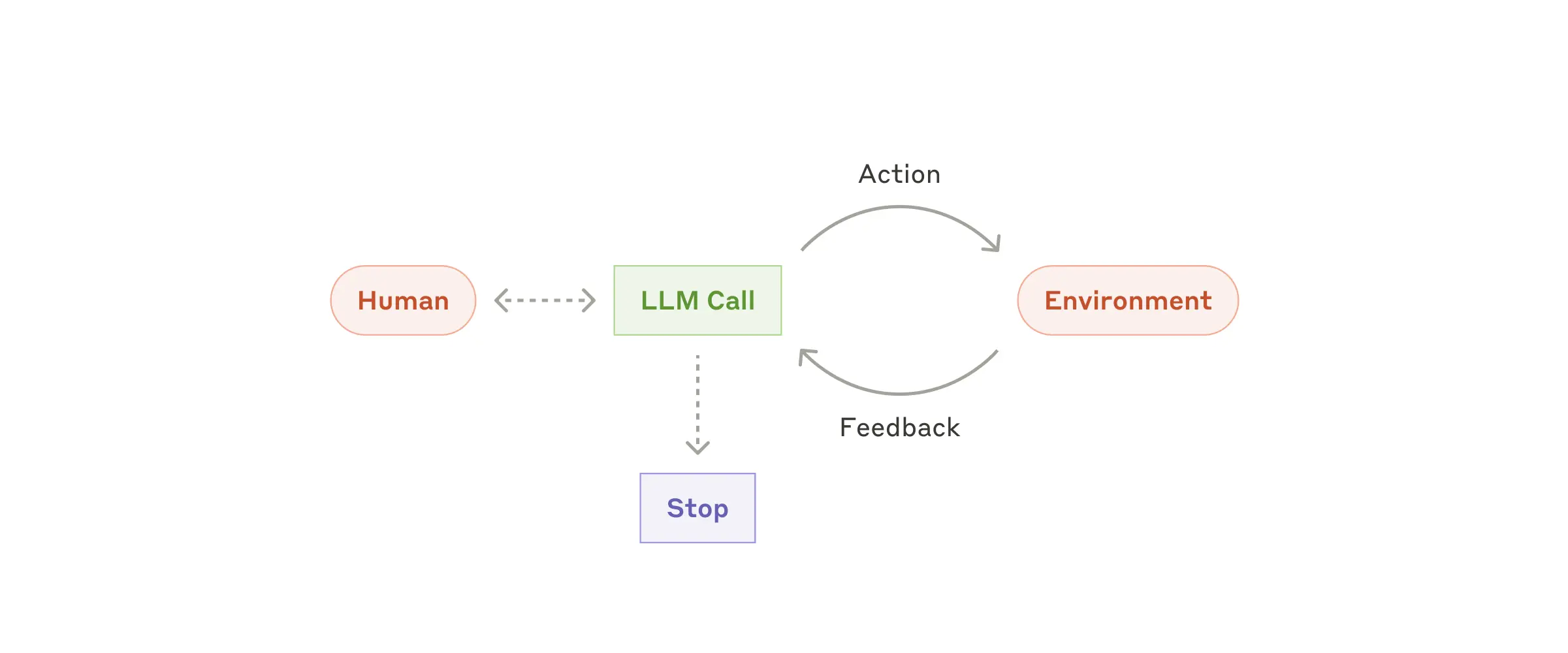
Особенности применения
Несмотря на способность решать сложные задачи, реализация агентов часто оказывается довольно простой – по сути, это та же LLM-модель, использующая инструменты на основе обратной связи от окружения. Главное здесь – тщательно продумать набор инструментов и их документацию.
Где это применяется
Агенты особенно полезны в ситуациях с открытым финалом, где сложно предсказать необходимое количество шагов и невозможно заранее прописать четкий алгоритм действий. Важно понимать, что их автономность – палка о двух концах: с одной стороны, это позволяет масштабировать решение задач, с другой – требует особого внимания к тестированию и установке ограничений.
Примеры успешного применения:
- Агент-программист для решения задач на платформе SWE-bench, где требуется вносить изменения в множество файлов на основе описания задачи.
- Реализация, где Claude использует компьютер юзера для выполнения различных задач.
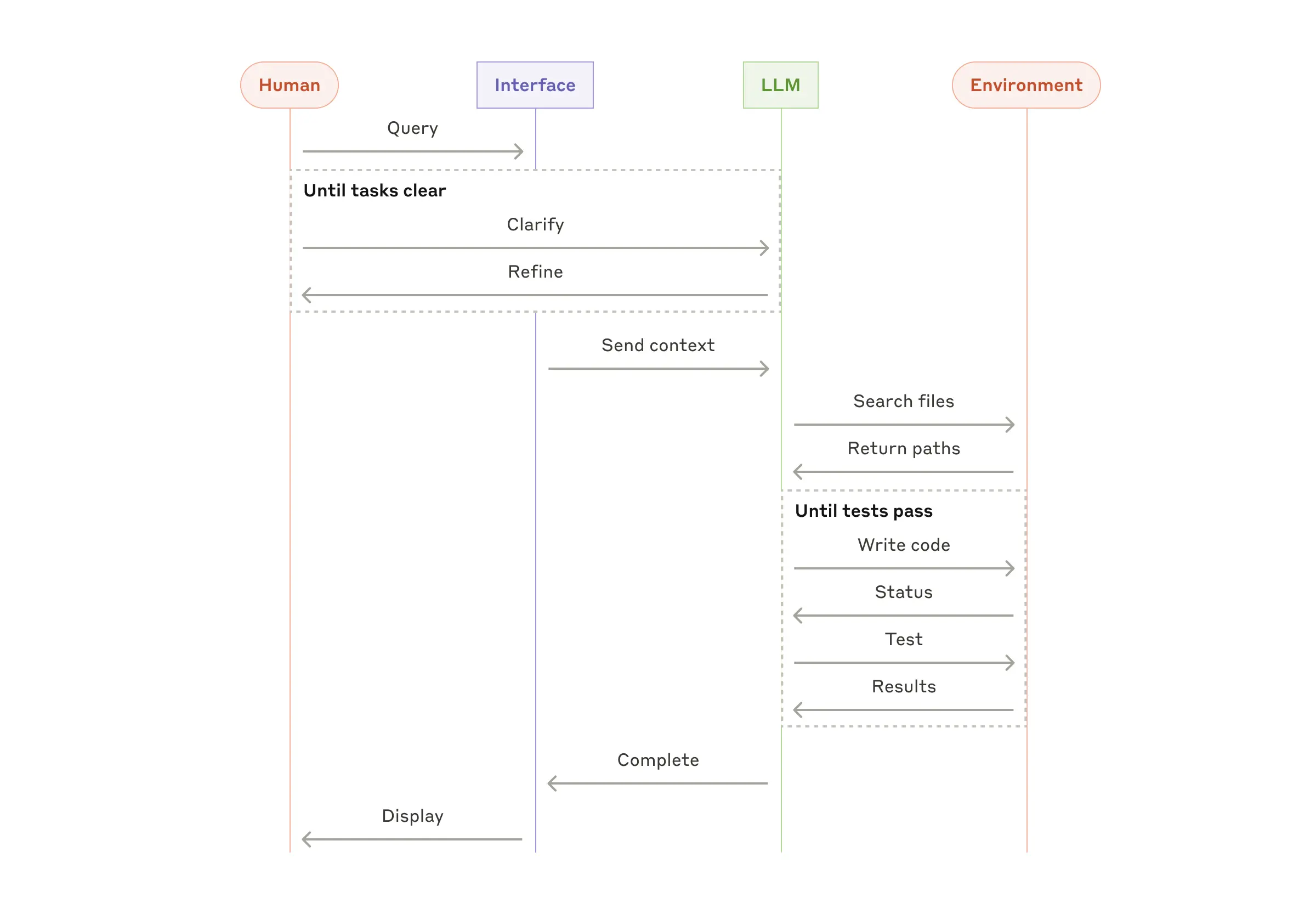
В поисках золотой середины: как собрать все воедино
Описанные паттерны – это не жесткая инструкция, а скорее набор кубиков LEGO 🧩, из которых можно собрать то, что нужно именно вам. Главное не увлечься и не построить Звезду Смерти там, где хватило бы простого спидера.
Ключевые принципы
При разработке агентов мы придерживаемся трех основных правил:
- Простота архитектуры: чем проще система, тем надежнее она работает
- Прозрачность действий: агент должен явно показывать свои шаги планирования
- Качественный интерфейс взаимодействия: тщательно документированные инструменты и серьезное тестирование
Практические рекомендации
Успех в работе с LLM не в создании самой навороченной системы, а в построении решения, идеально подходящего под ваши задачи. Начните с простых промптов, оптимизируйте их на основе тщательного тестирования, и только когда простые решения перестанут справляться – переходите к более сложным многоступенчатым системам.
Технический аспект
Готовые фреймворки могут помочь быстро начать, но не бойтесь упростить уровни абстракции и использовать базовые компоненты при переходе в продакшн. Такой подход поможет создать агентов, которые будут не только мощными, но и надежными, простыми в поддержке и заслуживающими доверия пользователей.
Приложение 1: где агенты уже приносят пользу
Работа с клиентами показала два особенно перспективных направления применения AI-агентов. В обоих случаях ключевым фактором успеха стало сочетание разговорного взаимодействия с конкретными действиями, четкими критериями успеха и грамотно выстроенной системой обратной связи.
Поддержка клиентов
Представьте себе чат-бота на стероидах только без побочных эффектов. Такие агенты особенно эффективны потому, что:
- Естественно вписываются в формат диалога, имея при этом доступ к внешним данным.
- Могут работать с историей заказов, базой знаний и данными клиентов.
- Способны самостоятельно выполнять простые операции вроде оформления возврата.
- Имеют четкие метрики успеха в виде решенных обращений.
Некоторые компании настолько уверены в эффективности своих агентов, что перешли на модель оплаты за успешно решенные кейсы.
Программирование
В разработке ПО агенты показали себя особенно хорошо, эволюционировав от простого автодополнения кода до решения самостоятельных задач. Успех здесь обусловлен несколькими факторами:
- Возможность автоматической проверки кода через тесты.
- Способность агентов улучшать решения на основе результатов тестирования.
- Четко определенная и структурированная область задач.
- Объективные критерии качества кода.
Наши агенты уже умеют решать реальные задачи из GitHub в рамках бенчмарка SWE-bench Verified, опираясь только на описание пул-реквеста. Однако, несмотря на автоматизированное тестирование, человеческий код-ревью остается критически важным для соответствия решений общей архитектуре системы.
Приложение 2: Тонкая настройка инструментов для агентов
Какую бы агентную систему вы ни создавали, инструменты (tools) будут играть в ней ключевую роль. Именно они позволяют Claude взаимодействовать с внешними сервисами и API. И поверьте, настройка этих инструментов заслуживает не меньше внимания, чем работа над основными промптами.
Выбор формата имеет значение
Представьте, что вы можете описать одно и то же действие разными способами. Структурированные данные можно вернуть в markdown или в JSON. (Звучит как выбор между пиццей и бургером – вроде бы без разницы, но на практике очень даже есть.)
С технической точки зрения эти форматы в целом эквивалентны, но для LLM некоторые из них могут быть настоящей головной болью. Например, написание JSON заставляет экранировать переносы строк и кавычки.
Правила хорошего тона
При разработке инструментов рекомендуем придерживаться следующих принципов:
- Давайте модели достаточно токенов для «размышлений».
- Используйте форматы, которые модель могла встретить в обучающих данных.
- Избегайте лишней технической нагрузки вроде подсчета строк или сложного экранирования.
Как работать с агентом
Вот несколько практических советов:
- Поставьте себя на место модели — очевидно ли, как использовать инструмент, основываясь на описании и параметрах?
- Тщательно подбирайте названия параметров и их описания.
- Протестируйте, как модель использует ваши инструменты.
- Защитите ваши инструменты от ошибок (защита от дурака).
Какой опыт создания ИИ-агентов есть у вас? С какими основными сложностями вы столкнулись в процессе разработки?"
Телеграм каналы об ИИ
- 🤖🦾 Библиотека робототехники и беспилотников | Роботы, ИИ, интернет вещей
- 🤖🔊 Библиотека нейрозвука | Транскрибация, синтез речи, ИИ-музыка
- 🤖✍️ Библиотека нейротекста | ChatGPT, Gemini, Bing
- 🤖🎥 Библиотека нейровидео | Sora AI, Runway ML, дипфейки
- 🤖🎨 Библиотека нейрокартинок | Midjourney, DALL-E, Stable Diffusion
Комментарии