

GitHub Actions – это инструмент непрерывной интеграции и доставки (CI/CD), встроенный в платформу GitHub. Он позволяет автоматизировать различные рабочие процессы – сборку, тестирование и деплой. Среди основных возможностей GitHub Actions:
- Автоматизация сборки, тестирования и развертывания кода.
- Запуск задач по расписанию или в ответ на определенные события в репозитории.
- Настройка сложных рабочих процессов с помощью YAML-файлов.
- Использование готовых действий из Marketplace или создание собственных.
- Интеграция с другими сервисами и API (для создания сложных и многоэтапных рабочих процессов, взаимодействующих с внешними системами).
- Ускорение рабочих процессов с помощью кэширования.
В этой статье мы обсудим тонкости кэширования и решение проблем, связанных со специфическими ограничениями платформы.
Зачем используют кэширование в GitHub Actions
С помощью кэширования можно сохранять и повторно использовать зависимости и другие файлы между сборками. Это помогает:
- Ускорить процесс сборки и тестирования.
- Сократить общее время выполнения рабочих процессов, особенно для больших проектов со множеством зависимостей.
- Уменьшить нагрузку на внешние сервисы, если они задействованы в процессе.
В теории настройка кэширования выглядит очень просто:
- Используем действие actions/cache.
- Определяем кэш с помощью ключа и пути к файлам/директориям.
- При совпадении ключа кэш восстанавливается.
- Если ключ не найден – создается новый кэш.
На практике есть нюансы.
Нюансы кэширования в GitHub Actions
Кейс: настройка кэширования для монорепозитория с 30+ пакетами.
Один из разработчиков Prosopo (открытого проекта, нацеленного на создание децентрализованной сети обнаружения ботов) недавно пришел к выводу, что пора заняться настройкой кэширования: время сборки достигло 20 минут. До этого разработчики использовали GitHub Actions для автоматизации всех аспектов CI/CD, но кэширование никогда не настраивали. Рабочий процесс выглядел стандартно:
- Весь код проекта расположен в монорепозитории.
- Основная ветка main содержит стабильную версию кода. Когда нужно добавить новую функцию, разработчик создает новую ветку от главной.
- Когда функция готова, разработчик создает запрос на слияние. Перед тем, как изменения попадут в главную ветку, запрос на слияние должен пройти ряд автоматических проверок и тестов.
- Если
все проверки пройдены успешно, изменения из новой ветки добавляются в главную
ветку.
Со временем количество пакетов достигло 30 (некоторые их них написаны на Rust). При каждом запуске рабочего процесса все эти пакеты собирались заново с нуля, даже если была изменена всего одна строка кода в одном из них. В результате продолжительность сборки приблизилась к 20 минутам, разработчики начали переключаться на другие задачи во время ожидания. Стало ясно, что пора читать документацию GitHub Actions по кэшированию. В документации все выглядит просто и понятно: кажется, что настройка займет не более 5 минут. На деле работа заняла несколько дней, а в процессе выявились нюансы, которым не уделяется никакого особого внимания в документации, но при этом их необходимо учитывать для реализации успешной стратегии кэширования.
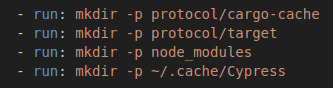
1. Кэшируемые директории должны существовать до восстановления кэша
Если директория не существует, весь процесс восстановления кэша тихо проваливается. Сообщений об ошибках нет – придется самостоятельно догадываться о том, что же пошло не так.
Решение: нужно использовать команду mkdir -p для создания всех кэшируемых директорий перед
восстановлением кэша:
2. Разные ветки не могут иметь общий кэш
Из-за этого ограничения кэширование помогает только при инкрементальных сборках в рамках одной ветки. То есть:
- Вы делаете сборку проекта.
- Вносите небольшие изменения.
- Делаете новую сборку, используя результаты предыдущей для ускорения процесса.
Но если у вас есть две очень похожие ветки (X и Y), то ветка Y не может использовать результаты сборки ветки X для ускорения своей сборки, даже если изменения минимальны:
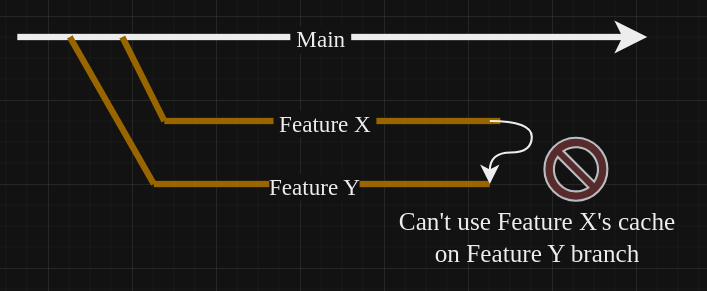
Оказалось, что эту проблему можно решить благодаря следующему нюансу, связанному с наследованием кэша.
3. Дочерние ветки могут наследовать кэш от родительской ветви
Это очень полезная фича, которая позволяет обойти ограничение на прямой обмен кэшами между ветками. Вот как это работает:
- Предположим, у вас есть ветка C (родительская).
- От нее создаются ветки A и B (дочерние).
- Если вы соберете проект в ветке C и закэшируете результат, то ветки A и B получат доступ к этому кэшу:
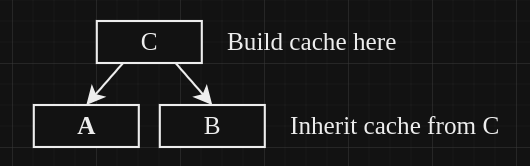
Эту особенность можно использовать с максимальной пользой, если все ветки в репозитории наследуются от главной:
- Проект собирается на главной ветке, результат кэшируется.
- Теперь все ветки могут использовать общий кэш – в результате процесс сборки для каждой из них значительно ускоряется.
4. Неизменность кэша
Как ни странно, после создания кэша его нельзя обновить. Это создает нелепую проблему:
- Вы создаете кэш на главной ветке.
- Объединяете запрос на вытягивание с новой функцией.
- Теперь нужно собрать главную ветку с новой функцией и сохранить результат в кэш.
- Но вы не можете этого сделать, потому что нельзя перезаписать существующий кэш.
Обычное решение этой проблемы – удалить старый кэш и создать новый. Но это создает новую проблему:
- Между удалением старого кэша и созданием нового всегда есть некий промежуток времени.
- Для больших кэшей (например, 1,3 ГБ) этот промежуток может составлять около 2 минут.
- В это время рабочие процессы не имеют доступа к кэшу, что значительно увеличивает время их выполнения (до 20 минут).
И все это происходит гораздо чаще, чем может показаться на первый взгляд:
- При каждом слиянии запроса на вытягивание.
- При каждом коммите в открытом запросе на вытягивание, который запускает процессы CI/CD.
При наличии множества активных запросов на вытягивание (например, 10 запросов одновременно – обычное дело для проекта) это превращается в очень серьезную проблему:
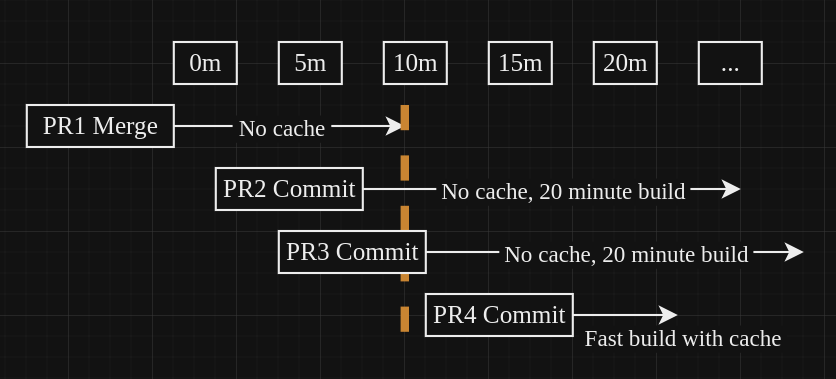
Решить проблему с неизменяемыми кэшами можно с помощью символов подстановки в именах. Если имя кэша заканчивается на -, оно рассматривается как регулярное выражение с подстановочным знаком в конце. Например, abc-def- будет соответствовать abc-def-1, abc-def-2 и т.д. GitHub использует самый последний кэш.
Чтобы обеспечить специфичность кэша для ОС и архитектуры, а также отличать кэши разных запусков, стоит давать им названия в таком формате:
project-cache-${{ runner.os }}-${{ runner.arch }}-${{ github.run_id }}-${{ github.run_attempt }}
Таким образом, кэши будут сохраняться с известным префиксом и неизвестным суффиксом (в который входит id и попытка запуска). Если при восстановлении кэша указано имя project-cache-${{ runner.os }}-${{ runner.arch }}-– GitHub будет использовать самый последний подходящий кэш.
5. Ограничение размера кэша
Лимит кэша в GitHub – 10 Гб. При достижении лимита GitHub автоматически удаляет самые старые кэши. Ограничивать объем кэша, конечно, нужно – серверы не резиновые. Но если у проекта есть, например, два кэша с разной частотой обновления, это может привести к проблемам: тот кэш, что обновляется часто (и в итоге приводит к превышению лимита), GitHub не тронет, а удалит второй, который обновляется реже (и может быть гораздо важнее, чем первый).
Для решения проблемы с лимитом нужно самостоятельно удалять старые кэши, а не полагаться на автоматическое удаление: это позволяет контролировать, какие именно кэши удаляются, и избегать ситуаций, когда часто обновляемый кэш вытесняет редко обновляемый, но важный кэш. Реализовать это можно так:
- Сначала сохраняем новый кэш. Он включает несколько директорий и использует уникальный ключ, содержащий информацию о ОС, архитектуре, ID запуска и попытке.
- name: Save cache
uses: actions/cache/save@v3
if: always()
with:
path: |
protocol/cargo-cache
protocol/target
node_modules
~/.cache/Cypress
key: project-cache-${{ runner.os }}-${{ runner.arch }}-${{ github.run_id }}-${{ github.run_attempt }}
- После сохранения у нас будет ≥ 2 кэша (включая предыдущий). Напишем действие, которое удалит все кэши, кроме только что созданного:
name: Cleanup caches
if: always()
run: |
set +e; gh extension install actions/gh-actions-cache; set -e
REPO=${{ github.repository }}
echo "Fetching list of cache key"
cacheKeys=$(gh actions-cache list --sort created-at --order desc --limit 100 -R $REPO --key project-cache-${{ runner.os }}-${{ runner.arch }}- | cut -f 1 | tail -n +3)
echo caches to be removed:
echo ${cacheKeys}
set +e
for cacheKey in $cacheKeys
do
gh actions-cache delete $cacheKey -R $REPO --confirm
done
Этот код:
- Устанавливает расширение gh для работы с кэшами GitHub Actions.
- Получает список ключей кэшей, соответствующих шаблону
project-cache-${{ runner.os }}-${{ runner.arch }}-. - Удаляет все кэши, кроме самого последнего.
Процесс затрагивает только кэши с определенным ключом, а другие остаются нетронутыми. Таким образом, можно будет иметь несколько разных кэшей одновременно, если их общий размер не превышает 10 ГБ.
Как выглядит процесс кэширования
Процесс запускается после слияния запроса в ветку main (или вручную через GitHub). Проект собирается, результат сохраняется в кэше:
name: post_pr
on:
push:
branches:
- 'main'
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: mkdir -p protocol/cargo-cache
- run: mkdir -p protocol/target
- run: mkdir -p node_modules
- run: mkdir -p ~/.cache/Cypress
# build the code here!
- name: Save cache
uses: actions/cache/save@v3
if: always()
with:
path: |
protocol/cargo-cache
protocol/target
node_modules
~/.cache/Cypress
key: project-cache-${{ runner.os }}-${{ runner.arch }}
Особенности:
- Создаются четыре директории: cargo-cache, target, node_modules, Cypress cache. Это делается для безопасности, чтобы избежать сбоя механизма кэширования, если директории не существуют.
- Ключ кэша
project-cache-${{ runner.os }}-${{ runner.arch }}позволяет иметь разные кэши для разных ОС и архитектур. - Кэш не восстанавливается из предыдущих сборок, чтобы избежать петли кэширования: это предотвращает накопление артефактов от предыдущих сборок и разрастание кэша, с которым GitHub расправляется беспощадно :(.
При создании запроса на вытягивание автоматически запускаются CI/CD-процессы. Так, например, выглядит использование кэша в процессе тестирования:
name: tests
on:
pull_request:
branches: [main]
workflow_dispatch:
jobs:
check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: mkdir -p protocol/cargo-cache
- run: mkdir -p protocol/target
- run: mkdir -p node_modules
- run: mkdir -p ~/.cache/Cypress
- name: Restore cache
uses: actions/cache/restore@v3
with:
path: |
protocol/cargo-cache
protocol/target
node_modules
~/.cache/Cypress
key: project-cache-${{ runner.os }}-${{ runner.arch }}
# build and test here!
Создание необходимых директорий перед работой с кэшем предотвращает тихий провал процесса, а ключ с подстановочным символом обеспечивает использование самого свежего кэша.
Что еще стоит сделать
Важно настроить рабочие процессы так, чтобы их можно было отменить при необходимости:
- Если в проект вносятся новые изменения (например, новый коммит), старые проверки уже не актуальны.
- Отмена устаревших процессов позволяет сразу начать проверку самой свежей версии кода.
- И самое главное – отменяемость предотвращает одновременное создание нескольких кэшей. Хотя (теоретически) несколько одновременных процессов создания кэша не должны конфликтовать, есть небольшой шанс, что в итоге вы получите кэш от более старого процесса вместо нового.
Отменяемость процессов в GitHub Actions это обычно реализуют с помощью настройки concurrency – она позволяет автоматически отменять предыдущие запущенные процессы при появлении новых.
Подведем итог
Кэширование в GitHub Actions – мощный инструмент оптимизации, способный значительно ускорить процессы CI/CD. Однако, как мы увидели, его эффективное использование требует знания нюансов работы платформы и преодоления ряда ограничений. Применяя описанные в статье подходы – от правильного именования кэшей до стратегий их обновления и очистки – можно существенно сократить время выполнения рабочих процессов, особенно в крупных проектах.
Комментарии