

В идеальном мире все ваши кодовые базы хранились бы в одном месте. Но в реальном мире разработчикам часто приходится поддерживать один и тот же код в двух разных местах. Например, вам может понадобиться использовать один и тот же код, как в приложении с открытым исходным кодом, так и во внутреннем или проприетарном приложении.
В 2019 году мы столкнулись с этой проблемой в FullStory. Если бы мы попытались синхронизировать код вручную, нам пришлось бы не забывать обновлять репозиторий с открытым исходным кодом всякий раз, когда мы выпускаем новую версию фрагмента. Для этого потребуются две отдельные команды (команда, которая поддерживает исходный код фрагмента, и команда, которая поддерживает репозиторий с открытым исходным кодом) для координации своей работы. И если вы недоумеваете, знайте, что мы – тоже. Нам нужен был автоматизированный способ синхронизации открытого кода со сниппетами кода в закрытом репозитории.
Чтобы решить эту проблему, мы использовали встроенный в GitHub инструмент CI/CD и автоматизации рабочего процесса – GitHub Actions для обновления нашего открытого кода путем загрузки фрагмента кода из нашего API и автоматического создания pull request с любыми изменениями. Благодаря этой архитектуре, мы обнаружили и объединили несколько обновлений с тех пор, как она появилась в сети в декабре 2019 года, обеспечив обновленный код для пользователей нашего Browser SDK и сократив расходы на обслуживание.
Вместо межгруппового, ручного и чреватого ошибками процесса теперь у нас есть безопасное автоматизированное решение. Это позволяет каждой команде работать независимо, помогает повысить нашу производительность и упрощает процесс поддержки проекта с открытым исходным кодом для нашего Browser SDK, гарантируя, что наши потребители пакетов NPM всегда будут иметь последнюю версию нашего сниппета, чтобы воспользоваться преимуществами любых новых функций, которые мы выпускаем. Более того, теперь у нас есть шаблон для синхронизации нашего закрытого исходного кода с репозиториями с открытым исходным кодом без какого-либо вмешательства человека. Сейчас расскажем, как мы это сделали.
Зачем нам нужно было синхронизировать наши репозитории
Мы стремимся создать простой способ реализации для разработчиков, чтобы они могли быстро запустить FullStory на своих сайтах. Наши клиенты запускают наш сервис, копируя и вставляя фрагмент кода JavaScript на свой веб-сайт. Данный способ очень хорошо работает с традиционными HTML-сайтами, а также с системами управления контентом (CMS), диспетчером тегов и платформой электронной коммерции.
Однако если веб-сайт представляет собой одностраничное приложение (SPA), созданное с использованием таких фреймворков, как React, Angular, Vue и т. д., то этот способ далеко не идеален. Мы поняли, что нам нужно предоставить идиоматический способ добавления фрагмента записи и наших клиентских API-интерфейсов JavaScript в SPA. Итак, мы создали пакет NPM с открытым исходным кодом: FullStory Browser SDK.
Поскольку мы предоставляем инструкции по установке как в нашем веб-приложении, так и программно в SDK, код основного фрагмента теперь размещается в двух местах: в нашем репозитории с закрытым исходным кодом и в репозитории с открытым исходным кодом, который содержит код, распространяемый через NPM. Нам нужен был хороший способ, как сделать так, чтобы наши внутренние микросервисы, а также потребители открытого исходного кода могли совместно использовать единый источник достоверных данных, не будучи тесно связанными. Первоначально мы рассматривали модель «push», при которой наша система сборки будет отправлять любые обновления фрагментов в репозиторий с открытым исходным кодом и создавать PR. Недостатком является то, что это потребует от нашей системы сборки поддерживать конфиденциальную информацию и понимать структуру нашего репозитория с открытым исходным кодом, а также поддерживать репозиторий, который ей не принадлежит. Эти дополнительные сложности и зависимости в системе сборки не являются идеальными.
Создаем репозиторий синхронизации Action шаг за шагом
В итоге мы пришли к решению, основанному на двух технологиях:
- Новый общедоступный API, который мы размещаем, возвращает код фрагмента.
- GitHub Actions
При добавлении GitHub Actions в наш репозиторий с открытым исходным кодом было тривиально использовать встроенную функцию cron для извлечения последнего фрагмента кода, который мы предоставляем через конечную точку общедоступного API. Все, что нам было нужно, – это создать новый микросервис, который будет обслуживать фрагмент кода для различных клиентов. Более того, GitHub Actions имеет встроенные операции git и API-интерфейсы управления GitHub, которые упрощают автоматическое обновление файла фрагмента, получение новой ветки, открытие PR и назначение нужных рецензентов.
Экскурс в `Snippet-Sync-Job`
Шаг 1. Создание службы сниппетов и предоставление общедоступной конечной точки API
Чтобы иметь возможность получить последний сниппет из наших репозиториев с закрытым исходным кодом, нам нужно было предоставить общедоступный API, обслуживающий код сниппета. Он обслуживает либо «основную», либо «ES-модульную» версию сниппета на основе переданных параметров URL. И вуаля! У нас есть способ получить последний сниппет. Стоит отметить, что эта служба также используется различными другими службами, которые мы размещаем внутри через gRPC.
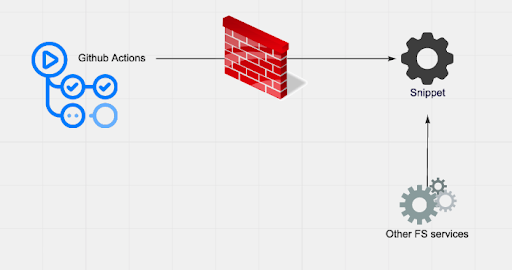
Данное изображения и все последующие взяты отсюда.
Шаг 2. Добавление Github Actions в наш репозиторий с открытым исходным кодом
Чтобы подключить GitHub Actions, создайте файл main.yaml в папке github/workflows. И благодаря нескольким строкам мы можем определить задание cron и получать обновления каждые 24 часа.
on:
schedule:
- cron: '0 0 * * *' # every 24 hours
jobs:
sync:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
- name: npm ci
run: npm ci
working-directory: ./.github/actions/sync-snippet-action
- name: Sync snippet
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
SNIPPET_ENDPOINT: https://api.fullstory.com/code/v1/snippet?type=esm
uses: ./.github/actions/sync-snippet-action
GitHub Actions упрощают встраивание аутентификации в рабочий процесс, предоставляя секрет GITHUB_TOKEN и несколько других переменных среды по умолчанию. Вместе с конечной точкой snippet API теперь у нас есть все необходимое для дальнейших действий.
// accessing environment variables in .github/actions/sync-snippet-action
const {
SNIPPET_ENDPOINT,
GITHUB_REPOSITORY,
GITHUB_TOKEN,
GITHUB_SHA,
} = process.env;
// parsing the owner and repo name from GITHUB_REPOSITORY
const [owner, repo] = GITHUB_REPOSITORY.split(‘/’);
const repoInfo = { owner, repo };
Мы используем все импортированные переменные среды и проанализированный repoInfo позже.
Шаг 3. Проверьте наличие обновлений сниппетов и существующих открытых PR
На этапе Sync snippet мы уже проверили последнюю ветку main. Сначала мы используем axios для извлечения текста последнего фрагмента через REST API, а затем сравниваем хэш текста последнего фрагмента с тем, который у нас есть в файловой системе извлеченного репозитория. Мы переходим к следующим шагам только тогда, когда обнаруживаем несоответствие в хэш-значениях, что означает обнаружение обновления фрагмента. Если мы понимем, что требуется обновление, мы инициализируем клиент octokit из пакета @actions/github. Клиент аутентифицируется с помощью переменной env GITHUB_TOKEN, объявленной в файле main.yaml.
Затем мы получаем список текущих открытых PR и проверяем, не был ли уже создан такой же PR. Поскольку мы запускаем синхронизацию каждые 24 часа, возможно, что существующий PR был открыт, но еще не объединен, и в этом случае мы не хотим открывать другой PR. Мы достигаем этого, просто ища PR, созданный ботом Github Actions, и тем, что заголовок (title) является константой:
// “The FullStory snippet has been updated”
const SNIPPET_PATH = 'src/snippet.js';
const PR_TITLE = 'The FullStory snippet has been updated';
const octokit = new github.GitHub(GITHUB_TOKEN);
const openPRs = await octokit.pulls.list({
...repoInfo,
state: ‘open’,
});
console.log(‘checking for an on open snippet sync PR’);
// Look for PR created by github-actions[bot] with the same title
const existingPR = openPRs.data.filter(pr => pr.title === PR_TITLE && pr.user.login === ‘github-actions[bot]’);
if (existingPR.length > 0) {
core.setFailed(`There is already an open PR for snippet synchronization. Please close or merge this PR: ${existingPR[0].html_url}`);
return;
}
Шаг 4. Используйте Github `octokit` для получения объекта дерева
Следующим шагом является обновление файла snippet.js и создание PR.
Чтобы программно обновить файл и открыть PR, нам нужно углубиться в то, что git называет командами Plumbing. Если вы не знакомы с внутренней работой git, мы рекомендуем прочитать раздел «Plumbing and Porcelain» документации Git, прежде чем продолжить.
Древовидный объект – это структура данных, которая содержит отношения между вашими файлами (BLOB-объектами), подобно упрощенной файловой системе UNIX. Нам нужно сначала создать новый Tree Object с новым содержимым фрагмента кода. А затем используйте только что созданное дерево, чтобы проверить ветку и открыть новый PR.
Для этого нам нужно сначала получить текущий коммит. Вернувшись на первый шаг, мы проверили main и получили текущий sha коммита из process.env на шаге 1. С помощью sha коммита мы теперь можем получить текущий коммит через ` octokit.git.getCommit ` , который содержит хеш объекта tree object: tree sha. Затем с помощью tree sha мы можем получить объект дерева через ` octokit.git.getTree` с рекурсивным параметром.
Как только мы получили объект дерева, мы нашли «узел дерева» ( srcTree) с нашим известным SNIPPET_PATH. Этот узел дерева представляет файл snippet.js.
console.log("getting source tree from main");
const getCommitResponse = await octokit.git.getCommit({
...repoInfo,
commit_sha: GITHUB_SHA,
});
const getTreeResponse = await octokit.git.getTree({
...repoInfo,
tree_sha: getCommitResponse.data.tree.sha,
recursive: 1,
});
const srcTree = getTreeResponse.data.tree.find(el => el.path === SNIPPET_PATH);
Шаг 5. Создайте новое «Tree» с измененным содержимым.
Подытожим, что мы имеем на данный момент:
- У нас есть новый фрагмент из общедоступного API, размещенного на FullStory, в строковом формате.
- У нас есть исходный «узел дерева» с содержимым фрагмента из текущего коммита в основной ветке.
После чего нужно создать новый tree object с обновленным кодом сниппета. Для этого мы создаем новое дерево с помощью `octokit.git.createTree` и указываем обновленный объект: наш новый текст сниппета. Помните, что мы получили исходный объект дерева рекурсивно, то есть объект дерева содержит ссылки на все файлы с их вложенными путями. Новое дерево будет содержать всю информацию из исходного дерева, но обновит только то, что нам нужно: файл snippet.js.
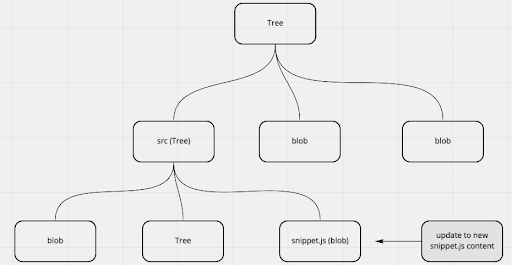
console.log('creating updated source tree with new snippet file');
const createTreeResponse = await octokit.git.createTree({
...repoInfo,
tree: [{
path: SNIPPET_PATH,
content: remoteSnippetText,
mode: ‘100644’,
type: ‘blob’,
base_tree: srcTree.sha,
},
...getTreeResponse.data.tree.filter(el => el.type !== ‘tree’ && el.path !== SNIPPET_PATH)]
});
Шаг 6. Зафиксируйте изменение в новой ветке
Теперь, когда у нас есть новый tree object с обновленным текстом фрагмента, нужно просто зафиксировать изменение и открыть PR.
С текущим коммитом в качестве родителя мы создаем новый коммит, используя `octokit.git.createCommit` и передаем созданное дерево tree sha, затем создаем новую ссылку (ветвь) с именем: snippetbot/updated-snippet- ${Date.now()} с помощью `octokit.git.createRef`, предоставив только что созданный коммит sha:
console.log('committing new snippet file');
const commitResponse = await octokit.git.createCommit({
...repoInfo,
message: `updated ${SNIPPET_PATH}`,
tree: createTreeResponse.data.sha,
parents: [GITHUB_SHA],
});
const branchName = `refs/heads/snippetbot/updated-snippet-${Date.now()}`;
console.log(`creating new branch named ${branchName}`);
await octokit.git.createRef({
...repoInfo,
ref: branchName,
sha: commitResponse.data.sha,
});
Шаг 7. Откройте PR и назначьте его сопровождающим
Последним шагом является создание PR через `octokit.pulls.create` и назначение его сопровождающим репозитория через `octokit.issues.addAssignees`.
Для получения исполнителей у нас есть файл MAINTAINERS.json, который содержит все дескрипторы GitHub сопровождающего для этого репозитория, поэтому соответствующие члены команды будут уведомлены о необходимости просмотреть и объединить новый PR.
console.log(`creating PR for branch ${branchName}`);
const base = GITHUB_REF.split('/').pop();
const prResponse = await octokit.pulls.create({
...repoInfo,
title: PR_TITLE,
head: branchName,
base,
});
console.log(‘assigning PR to reviewers’);
const maintainers = JSON.parse(fs.readFileSync(‘./MAINTAINERS.json’));
await octokit.issues.addAssignees({
...repoInfo,
issue_number: prResponse.data.number,
assignees: maintainers,
});
console.log(`created PR: ${prResponse.data.html_url}`);
Результаты и заключительные мысли
Вы можете ознакомиться с нашим решением и узнать больше о SDK FullStory Browser в нашем репозитории GitHub. Ваше решение может быть иным, но, надеюсь, того, что мы здесь сделали, вам будет достаточно для начала. Вероятно, в будущем мы снова будем использовать этот шаблон.
Комментарии