


Первое января – прекрасный день, чтобы перебрать свои зимние вещи. Именно это было у меня на уме, когда я подходила к своему гардеробу месяц назад. Монотонный процесс складывания свитеров, носков и шарфов медитативен по своей природе и приводит ко многим открытиям. Вроде того, что у меня три розовые блузки одного и того же стиля. Это открытие помогло мне осознать, что мне неизбежно придется оптимизировать свой запас модных вещей, повысив их разнообразие и сократив избыточность моих предметов одежды. Естественно, моей целью должно быть моделирование содержимого своего гардероба в виде графа предметов одежды, содержащего типы предметов (свитер, штаны и т.п.), их атрибуты (ткань, стиль, цвет и т.д.) и отношения (можно ли сочетать эти предметы в одном образе). В этой статье я расскажу о подходе, который я использовала для получения своего набора данных, а именно – как распознать тип одежды случайного предмета.
Эта статья состоит из следующих частей:
- Данные.
- Обучение модели.
- Оценка модели.
- Как загрузить предобученную модель из Fastai в PyTorch.
- Заключение.
Хотя я годами использовала для глубокого обучения Keras, на этот раз я решила дать шанс PyTorch и Fastai. Полный код, использованный в этой статье, можно найти здесь.
Данные
Чтобы определить, к каким категориям относятся предметы моего гардероба, мне потребуется модель, обученная для решения этой задачи, а для обучения такой модели нужны данные. В этом проекте я использовала набор данных DeepFashion, огромную базу данных для предсказания категории и атрибутов одежды, собранную Лабораторией Мультимедия Китайского университета в Гонконге.

Критерий оценки классификации был опубликован в 2016-м. Он оценивает производительность модели FashionNet в предсказании 46 категорий и 1000 атрибутов одежды. Оригинальный документ можно найти здесь: "DeepFashion: надежное распознавание и восстановление одежды с подробными аннотациями", CVPR 2016.
База данных DeepFashion содержит несколько наборов данных. В этом проекте мы используем набор "Category and Attribute Prediction" ("предсказание категории и атрибутов"). Этот набор содержит 289.222 разнообразных изображений одежды, принадлежащих 46 различным категориям.
Метки классов для обучения хранятся в train_labels.csv в следующем формате:
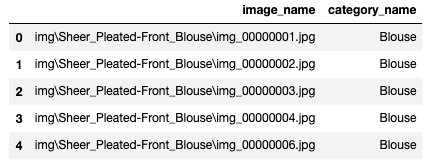
Этот файл тренировочных данных содержит расположение файлов изображений и метки. Метки хранятся как строковые объекты, по одной на изображение.
Мы можем загрузить эти данные train_labels.csv в класс ImageDataLoaders с помощью метода from_csv:
data = ImageDataLoaders.from_csv(PATH, csv_fname=TRAINING_PATH,
item_tfms=Resize(300),
batch_tfms=aug_transforms(size=224, min_scale=0.9),
valid_pct=0.1,
splitter=RandomSplitter(seed=42), #seed=42
num_workers=0)
Я использую стратегию дополнения (augmentation) данных Fastai, называемую предмасштабированием (presizing). Она сначала сокращает изображения до квадратов меньшего размера. Это позволяет выполнять будущие дополнения изображений быстрее, поскольку квадратные изображения можно обрабатывать на GPU. Затем мы применяем дополнение к каждому пакету данных (batch). batch_tfms производит все дополнения вроде поворотов и масштабирований последовательно, с единственной интерполяцией в конце. Эта стратегия дополнения позволит нам добиться лучшего качества дополненных изображений и выиграть в скорости обработки вследствие обработки на GPU.
Давайте посмотрим на некоторые изображения из нашего набора данных.
data.show_batch(max_n=6, nrows=1)

Мы также можем проверить, как выглядят дополненные изображения, передав параметр showImage=True в упомянутый выше метод show_batch().

Как видите, изображения сохранили свое качество после дополнения.
Обучение модели
В этом проекте я использовала предобученную модель ResNet34. Я экспериментировала с более современными архитектурами, но они не привели к существенному улучшению. Основная сложность набора данных DeepFashion – это качество меток. Например, на приведенном выше рисунке видны два предмета одежды: блуза и шорты, но его метка лишь "блуза". Таким образом, модель будет неизбежно страдать от шума.
Чтобы заставить трансферное обучение работать, нам нужно заменить последний слой сети новым линейным слоем, содержащим столько же активаций, сколько классов в нашем наборе данных. В нашем случае есть 46 категорий одежды, то есть в нашем новом слое будет 46 активаций. Веса нового слоя инициализируются случайным образом. То есть, до обучения наша модель будет выдавать случайные результаты, но это не значит, что модель полностью случайна. Все остальные слои, которые мы не меняли, сохранят те же веса, как и в исходной модели, и они будут хорошо распознавать такие визуальные концепции, как основные геометрические формы, градиенты и т.п. Поэтому, когда мы будем обучать нашу модель распознаванию категорий изображений, мы заморозим всю сеть, кроме последнего слоя. Это позволит нам оптимизировать веса последнего слоя, не меняя весов более глубоких слоев.
learn = cnn_learner(data, resnet34, metrics=accuracy, pretrained=True)
learn.fine_tune(2)
learn.save('stage-1_resnet34')
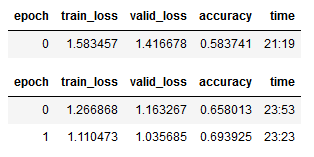
Когда мы вызываем learn.fine_tune(), мы замораживаем всю нейронную сеть и обучаем случайно инициализированные веса нашего нового слоя одну эпоху. Затем мы размораживаем сеть и обучаем все ее слои заданное количество эпох (в нашем случае две). Вот почему в выходных данных мы видим одну "лишнюю" эпоху.
Ранняя оценка (Early evaluation)
Ранняя оценка позволяет нам проверить прогресс обучения на ранних стадиях и уловить ошибки в наших подходах, прежде чем мы потратим огромное количество времени на обучение модели. Есть множество способов посмотреть на промежуточные результаты обучения нейронной сети. Чтобы получить быстрое представление об этом, мы можем посмотреть на классы, которые ошибочно распознаются чаще всего:
interp = ClassificationInterpretation.from_learner(learn)
interp.most_confused(min_val=70)

Как можно заметить, нейронная сеть чаще всего путает 'Top' (топ) с 'Blouse' (блузкой), 'Romper' (комбинезон) с 'Dress' (платьем) и 'Tee' (футболку) с 'Blouse' (блузкой). Даже человек может сделать такие ошибки. Таким путем мы можем на раннем этапе оценить, правильно ли обучается наша нейронная сеть.
Другой способ посмотреть на ошибки – это вывести объекты с максимальными значениями функции потерь:
interp.plot_top_losses(6, nrows=2)
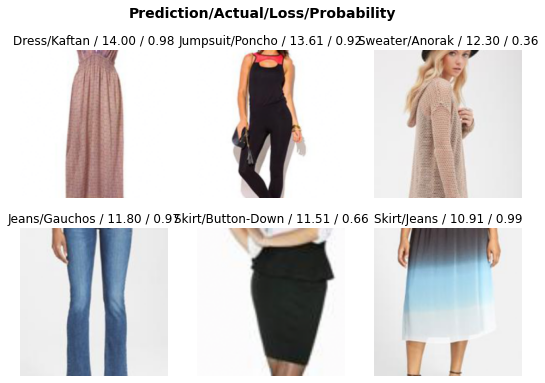
Как мы уже говорили, в исходных метках немало шума. Наша модель правильно распознала Jumpsuit (комбинезон), две Skirt (юбки) и Dress (платье), тогда как метки для этих предметов в наборе данных были неверными.
Поиск скорости обучения
Теперь давайте пройдем по данным, загруженным в DataLoader, и будем постепенно повышать скорость обучения в каждом мини-наборе (mini-batch), чтобы наблюдать, как изменяется значение функции потерь при изменении скорости обучения. Наша цель – найти наиболее эффективную скорость обучения, позволяющую сети быстрее сходиться к минимуму функции потерь. Скорость обучения имеет оптимальное значение в точке максимальной крутизны кривой потерь, поскольку это означает, что потери уменьшаются быстрее. Точки экстремума (минимум и максимум) и плоские участки кривой соответствуют таким скоростям обучения, которые не позволяют сети учиться, поскольку потери в этих точках не уменьшаются.
learn = cnn_learner(data, resnet34, metrics=accuracy)
lr_min, lr_steep = learn.lr_find()
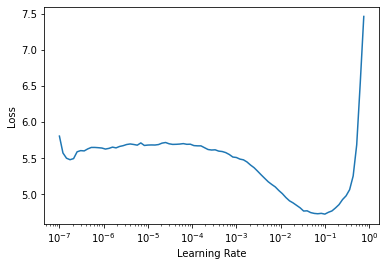
В нашем случае, максимальная крутизна кривой потерь достигается при скорости обучения, равной 0.005. Именно это значение мы будем использовать для дальнейшего обучения.
learn.fine_tune(2, base_lr=5e-3)
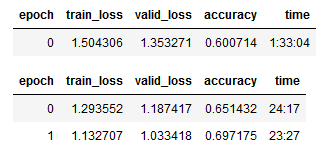
После обучения модели на протяжении 3 эпох мы получили точность 0.697, что является улучшением по сравнению с 0.694, которую мы получили при скорости обучения, установленной по умолчанию.
Дискриминационные скорости обучения
После обучения всех слоев нейронной сети нам придется снова пересмотреть скорость обучения, поскольку после обучения на нескольких тренировочных пакетах (batches) скорость, с которой обучается наша сеть, снижается, и с высокой скоростью обучения мы рискуем "перепрыгнуть" минимум функции потерь. Поэтому скорость обучения должна быть снижена.
Когда мы выведем график кривой потерь после трех эпох обучения, мы сможем увидеть, что он выглядит по-другому, поскольку веса нейронной сети больше не случайные.
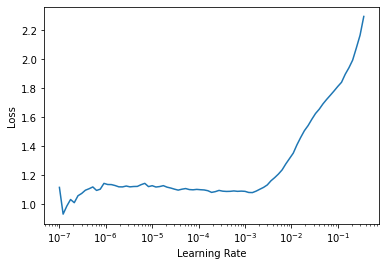
Мы не обращаем особого внимания на резкое падение в точке, в которой веса обновляются от случайных к тем, которые уменьшают значение потерь. Форма кривой потерь выглядит плоской. Для будущего обучения мы будем брать значения скоростей от точки резкого падения до той точки, в которой потери снова начинают расти.
Как упоминалось выше, слои, переданные из предобученной модели, уже хорошо распознают фундаментальные визуальные концепции и не требуют особого обучения. Однако более глубокие слои, отвечающие за распознавание сложных форм, специфичных для нашего проекта, получат преимущества от более высоких скоростей обучения. Таким образом, нам нужны меньшие скорости обучения для первых слоев и большие скорости для последних слоев, чтобы позволить им автоматически подстраиваться быстрее.
learn.fit_one_cycle(6, lr_max=slice(1e-7, 1e-3))
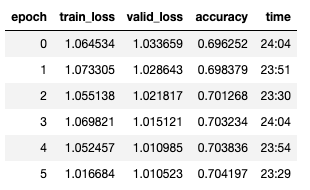
Мы ясно видим, что наша сеть добивается прогресса в обучении. Однако трудно сказать, должны ли мы продолжать обучение или остановиться, чтобы не переобучить модель. Вывод графика тренировочных и валидационных потерь может помочь нам оценить, нужно ли продолжать.
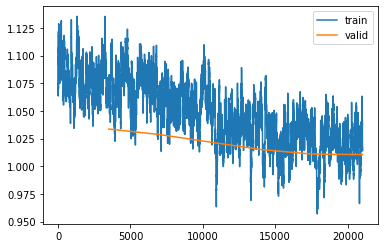
Мы можем увидеть, что валидационные потери больше практически не улучшаются, хотя тренировочные потери все еще продолжают улучшаться. Если мы продолжим обучение, мы увеличим разрыв между тренировочными и валидационными потерями, а это будет значить, что мы переобучили нашу модель. Поэтому будет лучше, если мы сейчас остановим обучение и перейдем к следующему шагу – оценке модели.
Оценка модели
На предыдущем шаге мы сумели достичь Топ-1 точности 70.4% на валидационном наборе данных. Если мы выведем график валидационной точности, мы сможем увидеть, как она улучшается с каждой эпохой обучения.
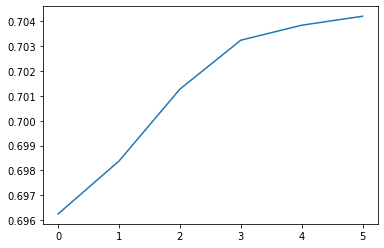
Оценка на тренировочном наборе данных
Для начала мы посмотрим на предсказания на тренировочном наборе данных, чтобы оценить, насколько велико наше смещение (bias) от истинного результата.
learn.show_results()

Предсказания на тренировочном наборе данных выглядят неплохо. Наша модель захватывает основные концепции. Дальнейшего улучшения можно достичь усовершенствованием меток и очисткой данных.
Оценка на тестовом наборе данных
А теперь давайте загрузим тестовые данные и проверим, как модель работает на них.
test_img_data = ImageDataLoaders.from_csv(PATH, csv_fname=TEST_PATH,
item_tfms=Resize(224),
num_workers=0)
learn.data = test_img_data
learn.validate()
learn.show_results()

Тестовая точность Топ-1 нашей модели равна 70.4%. Она неправильно классифицирует некоторые объекты, но все-таки очень близка к результату, который мы получили на валидационном наборе.
Авторы исходной статьи "DeepFashion: надежное распознавание и восстановление с подробными аннотациями", CVPR 2016 использовали точность Топ-3 и Топ-5 для этой оценки.
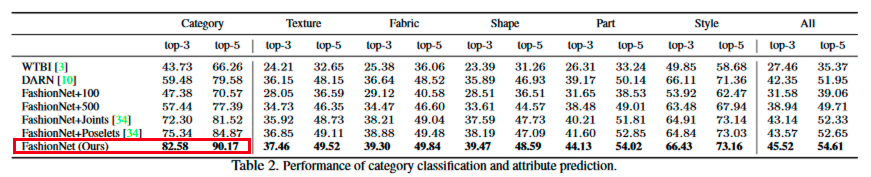
Чтобы сделать наши результаты сравнимыми, я использую те же метрики.
# https://forums.fast.ai/t/return-top-k-accuracy/27658/3
# модифицировано для работы на PyTorch 1.7.1
def accuracy_topk(output, target, topk=(3,)):
"""Computes the accuracy for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].contiguous().view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
output, target = learn.get_preds()
print(accuracy_topk(output=output, target=target))
print(accuracy_topk(output=output, target=target, topk=(5,)))
Точность Топ-3 нашей модели равна 88.6%, что на 6% выше исходной точности, а точность Топ-5 нашей модели равна 94.1%, что на 4% выше исходной. Это не должно нас удивлять, поскольку авторы исходной статьи использовали в качестве базовой архитектуры VGG16, менее мощную модель, чем наша ResNet34.
Оценка на пользовательском наборе данных
Наконец-то мы можем проверить, как наша модель работает на моих изображениях. Я сняла 98 изображений своих предметов одежды на камеру смартфона. Давайте загрузим эти изображения и проверим, сможет ли модель правильно их классифицировать.
test_dict = {}
size = 224,224
missclassified_list = []
reader = csv.DictReader(open(PATH + CUSTOM_DATASET_PATH))
for row in reader:
test_dict[row["image_name"]] = row["category_name"]
for key, value in test_dict.items():
predicted = learn.predict(PATH + key)[0]
print("Predicted: ", predicted, "True: ", value)
img=Image.open(PATH + key)
img.thumbnail(size,Image.ANTIALIAS)
display(img)
if predicted != value:
missclassified_list.append((predicted, value))
Точность модели Топ-1 на пользовательских данных равна 62.4%, что ниже показателя для набора данных DeepFashion. Однако она все еще хороша для модели классификации с 46 классами.
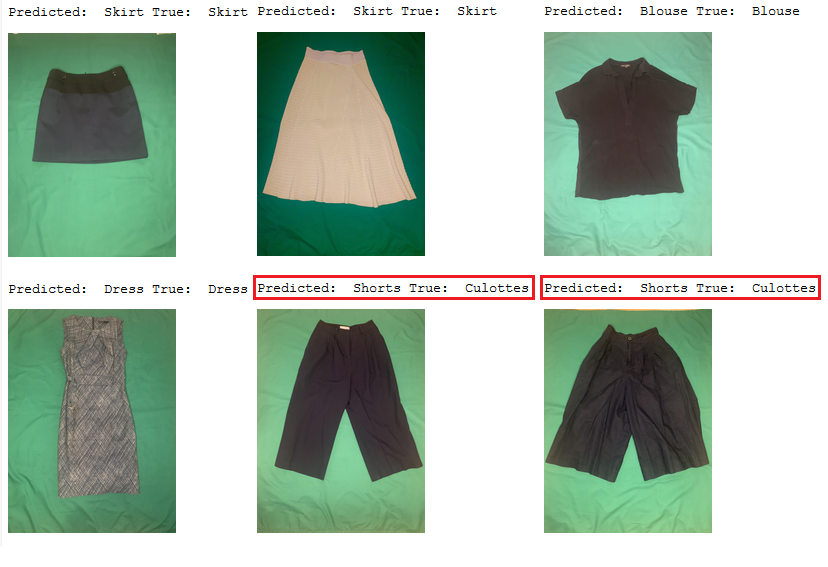
Изображения в пользовательском наборе данных довольно сильно отличаются от тех, на которых была обучена модель. Например, пользовательские изображения показывают только предметы одежды, тогда как изображения в наборе данных DeepFashion показывают человека, носящего эту одежду, что упрощает масштабирование одежды. Почти все штаны в пользовательском наборе данных были классифицированы как шорты, поскольку модели очень трудно оценить их длину относительно человеческого тела. Тем не менее, модель усвоила основные концепции, и ее можно использовать для разнообразных областей моды.
Как загрузить предобученную модель из Fastai в PyTorch
После обучения модели мы можем захотеть запустить ее на машине для вывода, не имеющей инсталляции Fastai. Для этого нам сначала потребуется сохранить модель и ее словарь:
modelname = learn.model
modelname.cpu()
torch.save(modelname, 'stage-1_resnet34.pkl')
with open(PATH+CLASSES_PATH, 'w') as f:
for item in data.vocab:
f.write("%s\n" % item)
torch.save сохраняет веса предобученной модели. Она использует утилиту Python pickle для сериализации. Чтобы запустить модель на PyTorch, нам нужно загрузить веса и заново определить модель:
class ClassificationModel():
def __init__(self):
return
def load(self, model_path, labels_path, eval=False):
self.model = torch.load(model_path)
self.model = nn.Sequential(self.model)
self.labels = open(labels_path, 'r').read().splitlines()
if eval:
print(model.eval())
return
def predict(self, image_path):
device = torch.device("cpu")
img = Image.open(image_path)
test_transforms = transforms.Compose([transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
image_tensor = test_transforms(img).float()
image_tensor = image_tensor.unsqueeze_(0)
inp = Variable(image_tensor)
inp = inp.to(device)
output = self.model(inp)
index = output.data.cpu().numpy().argmax()
return self.labels[index]
Заметьте, что на этот раз мы должны масштабировать и нормализовать изображения, прежде чем запускать предсказание. Библиотека Fastai хранит информацию о трансформациях, которые нужно произвести, в learner'е, но когда мы запускаем модель за пределами Fastai, мы должны сначала масштабировать изображения.
После этого мы можем запускать предсказания, используя определенный нами класс:
learner = ClassificationModel()
learner.load(MODEL_PATH, CLASSES_PATH)
learner.predict(DATA_PATH+"img-phone-jpg\IMG_2966.jpg")
Заключение
В этом руководстве я показала, как обучить модель ResNet34 для распознавания типа одежды, используя библиотеку Fastai и набор данных DeepFashion. Мы увидели, что мы можем обучить модель, которая превзойдет текущие базовые показатели на 6% для точности Топ-3 и на 4% для точности Топ-5. Мы запустили оценку для моих собственных изображений и убедились, что модель классифицировала предметы правильно, если не считать предметы, чувствительные к масштабу (проблема "штаны или шорты"). Производительность модели можно еще улучшить, если повысить качество тренировочных меток или повысить разнообразие изображений.
Комментарии