

Приложения Django работают с файлами любых форматов – растровыми и векторными изображениями, аудио, видео, архивами и всевозможными документами. Путь к файлам можно указывать точно так же, как в обычных Python скриптах, но проще воспользоваться встроенным инструментом для работы с пользовательскими файлами – папкой media.
Зачем нужна папка media в Django
В папке media размещаются файлы, которые загружаются или создаются пользователями – изображения профилей, фотографии, документы, презентации, аудио, видео и так далее. Django обеспечивает безопасное хранение и обслуживание этих файлов, а также предоставляет удобные методы для их обработки и отображения в приложении. Другими словами, использование папки media в Django значительно упрощает работу с пользовательскими файлами.
Заметим, что media используется для размещения именно пользовательских файлов, а не статических. Статические файлы являются неотъемлемой частью приложения, не претерпевают никаких изменений со стороны пользователя и хранятся в папке static. Подробнее со статическими файлами мы разберемся в следующей главе.
Как настроить media в Django
Прежде всего, нужно создать папку media в корневой директории проекта, на одном уровне с приложениями:
|-- config/
|-- asgi.py
|-- settings.py
|-- urls.py
|-- wsgi.py
|-- __init__.py
|-- __pycache__/
|-- media/
|-- students/
|-- admin.py
|-- apps.py
|-- migrations/
|-- __init__.py
|-- models.py
|-- tests.py
|-- views.py
|-- __init__.py
|-- venv/
|-- manage.py
Затем нужно добавить import os и эти строки в файл настроек config/settings.py:
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
MEDIA_URL = '/media/'
Кроме того, надо внести дополнения в в главный файл маршрутов config/urls.py:
from django.conf import settings
from django.conf.urls.static import static
…
urlpatterns += static(settings.MEDIA_URL,
document_root=settings.MEDIA_ROOT)
Файлы вместо базы данных в Django
Хотя веб-приложения обычно работают с базами данных, иногда возникает необходимость сохранять информацию в файлах. Например, конфигурационные файлы JSON и YAML используют для хранения настроек, а Markdown файлы заменяют базу данных в генераторах статических сайтов. Кроме того, веб-приложения часто используют файлы JSON, XLSX, CSV и для загрузки информации в базу данных, и для экспорта данных из БД.
В простых веб-приложениях файлы JSON, XLSX, CSV и YAML вполне могут заменить базу данных. Рассмотрим использование данных из различных файлов на примере приложения students.
Работа с YAML-файлами в Django
В этом примере мы будем использовать YAML файл, поэтому нам нужно установить PyYAML:
pip install pyyaml
Сохраните файл students.yaml в папке media. Поскольку Django знает,
где находится media, путь к файлу выглядит как 'media/students.yaml'. Функция представления students/views.py загружает сведения о студентах из YAML-файла и передает данные в шаблон student_list.html:
import yaml
from django.shortcuts import render
def student_list(request):
with open('media/students.yaml', encoding='utf-8') as file:
students = yaml.safe_load(file)
return render(request, 'student_list.html', {'students': students})
В шаблоне для создания списка используется HTML тег <ul></ul>, а для вывода пунктов – тег <li></li>:
<!DOCTYPE html>
<html>
<head>
<title>Список студентов</title>
</head>
<body>
<h1>Наши студенты</h1>
<ul>
{% for student in students %}
<li>имя: {{ student.name }}, фамилия: {{ student.lastname }}, возраст: {{ student.age }},
курс: {{ student.year }}, факультет: {{ student.faculty }}</li>
{% endfor %}
</ul>
</body>
</html>
Добавьте маршрут для вызова функции в файл students/urls.py:
from django.urls import path
from students.views import student_list
urlpatterns = [
path('students/', student_list, name='student_list'),
]
И включите маршруты приложения students в список маршрутов в config/urls.py:
path('', include('students.urls')),
Запустите сервер, перейдите по адресу http://localhost:8000/students/ – приложение успешно загружает данные из файла students.yaml:

Как использовать CSV-файлы в Django
Во втором примере мы воспользуемся файлом students.csv. Для загрузки данных нужно переписать функцию представления в students/views.py, а шаблон и urls.py останутся неизменными:
import csv
from django.shortcuts import render
def student_list(request):
students = []
with open('media/students.csv', 'r', encoding='utf-8') as file:
csv_data = csv.DictReader(file)
for row in csv_data:
students.append(row)
return render(request, 'student_list.html', {'students': students})
Результат будет аналогичен первому примеру:
Как работать с JSON-файлами в Django
Для загрузки данных из JSON-файлов Django использует модуль json из стандартной библиотеки Python, поэтому для этого примера не придется ничего устанавливать. Функция представления будет выглядеть так:
import json
from django.shortcuts import render
def student_list(request):
with open('media/students.json', 'r', encoding='utf-8') as file:
students = json.load(file)
return render(request, 'student_list.html', {'students': students})
Как загружать данные из Excel в Django
Для работы с Excel таблицами в Django можно использовать библиотеку Pandas, которая позволяет загружать данные из XLSX-файлов максимально просто:
import pandas as pd
from django.shortcuts import render
def student_list(request):
file_path = 'media/students.xlsx'
df = pd.read_excel(file_path)
students = df.to_dict('records')
return render(request, 'student_list.html', {'students': students})
Другой способ немного сложнее, зато он позволяет обойтись компактным модулем openpyxl:
from django.shortcuts import render
from openpyxl import load_workbook
def student_list(request):
file_path = 'media/students.xlsx'
workbook = load_workbook(filename=file_path)
worksheet = workbook.active
students = []
skip_first_row = True
for row in worksheet.iter_rows(values_only=True, min_row=2 if skip_first_row else 1):
student = {
'name': row[0],
'lastname': row[1],
'age': row[2],
'faculty': row[3],
'year': row[4],
'average': row[5]
}
students.append(student)
return render(request, 'student_list.html', {'students': students})
Результат будет одинаковым:
Проект 1: Приложение Books для хранения информации о книгах
Мы разработаем приложение, которое будет использовать XLSX-файл вместо базы данных. Код готового приложения находится здесь.
Хотя Django может работать с практически любыми файлами, удобнее всего использовать именно XLSX, поскольку такие файлы можно редактировать с помощью любого приложения для работы с электронными таблицами – Excel, Google Sheets, LibreOffice Calc и так далее. Таблица, в которой хранятся данные о книгах, выглядит так:
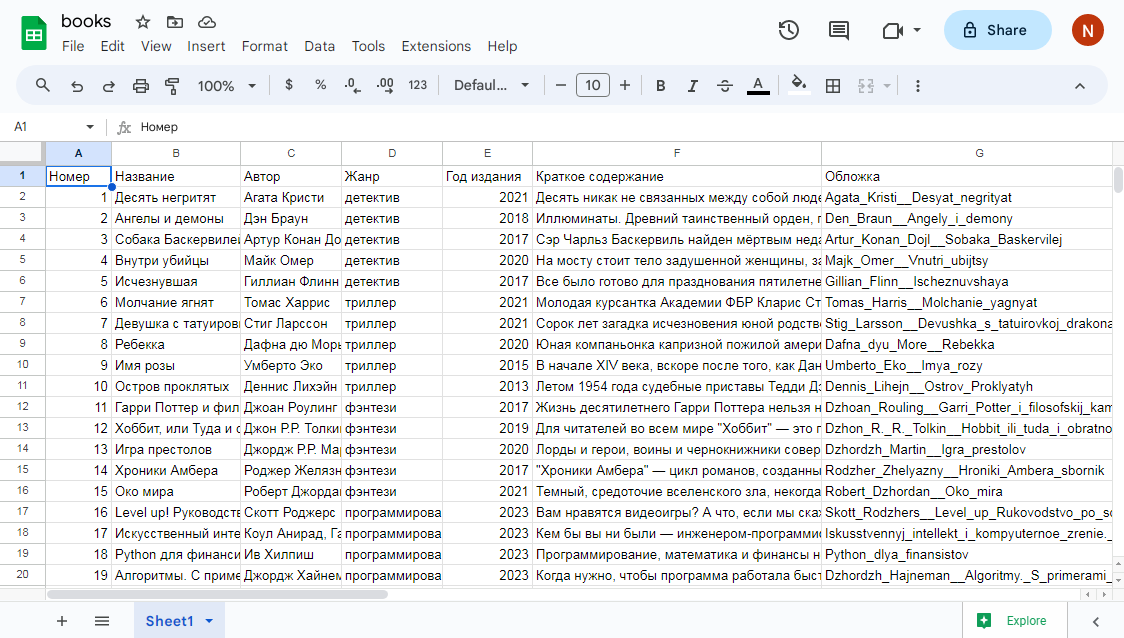
Обзор проекта
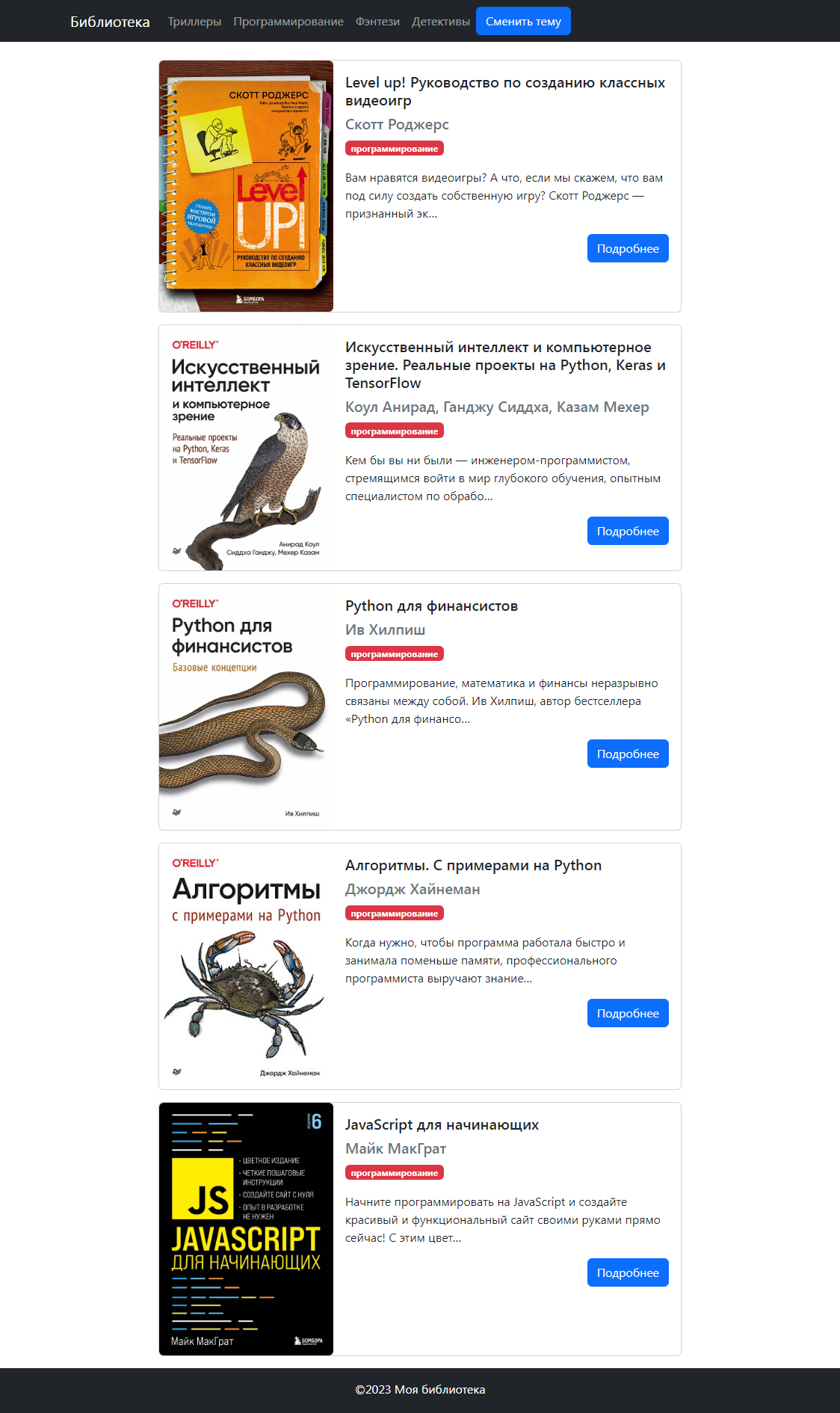
Приложение будет выводить данные из файла books.xlsx, который хранится в папке media. Для каждой книги выводится одинаковый набор данных:
- название;
- автор;
- жанр;
- год издания;
- краткое содержание;
- обложка.
Обложки находятся в media/covers.
Предусмотрено переключение темы со светлой на темную:
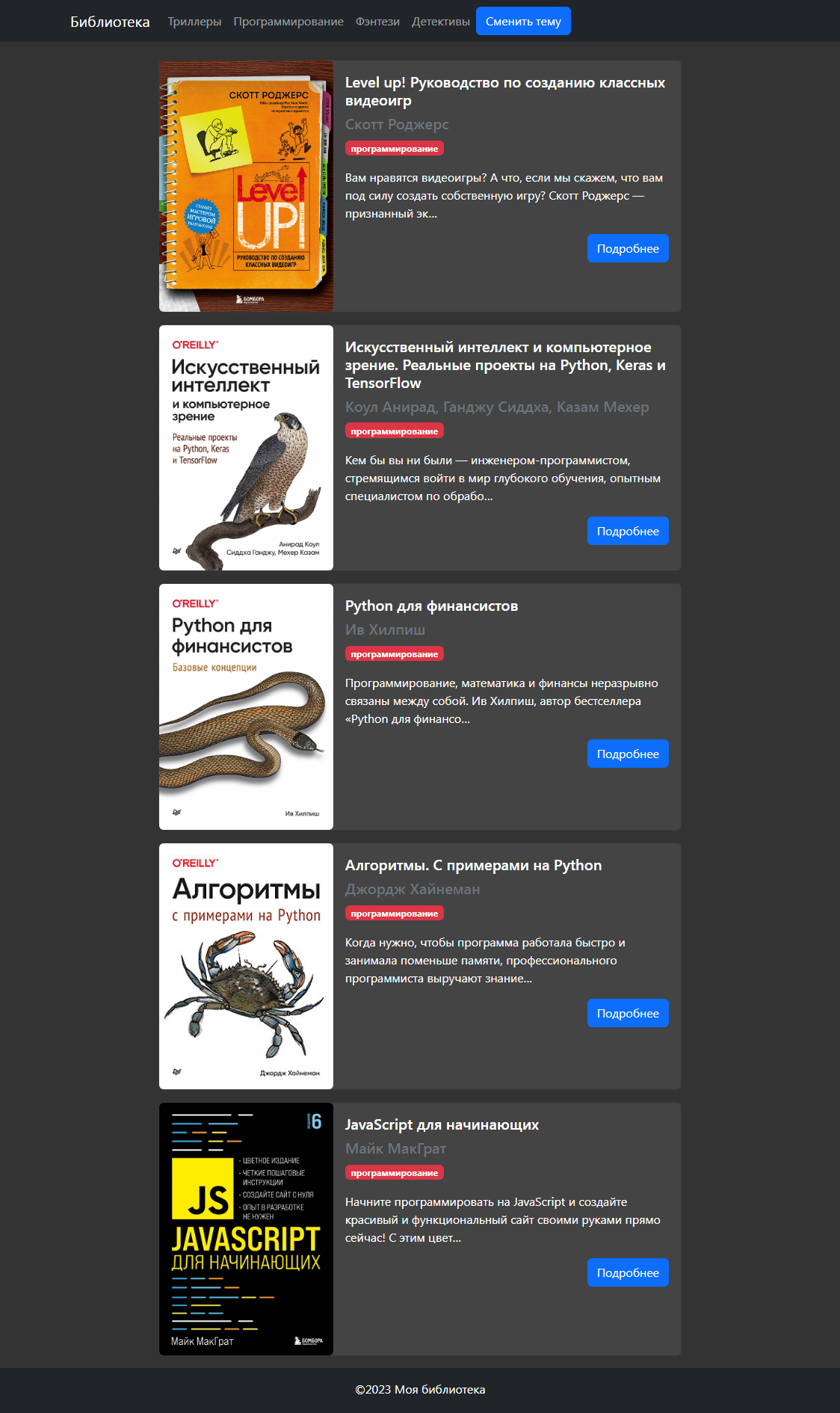
Приступаем к работе
Создайте виртуальное окружение и активируйте его:
python -m venv myproject\venv
cd myproject
venv\scripts\activate
Поместите файл requirements.txt в myproject и установите все нужные зависимости:
pip install -r requirements.txt
Создайте проект config и приложение books:
django-admin startproject config .
manage.py startapp books
Теперь нужно зарегистрировать приложение books в config/settings.py и добавить туда же настройки для папки media:
INSTALLED_APPS = [
…
'books.apps.BooksConfig',
]
…
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
MEDIA_URL = '/media/'
Не забудьте добавить настройки media в файл config/urls.py:
urlpatterns += static(settings.MEDIA_URL,
document_root=settings.MEDIA_ROOT)
Напомним, что папка media располагается на одном уровне с приложением books. В media находится файл books.xlsx и вложенная директория covers, в которой хранятся обложки книг.
Функции представления views.py
Все основные действия по извлечению из Excel-файла информации о книгах выполняет get_books(). Остальные функции, которые выводят список всех книг, а также книги конкретных жанров, полагаются на get_books():
from django.shortcuts import render
from openpyxl import load_workbook
def get_books(genre=None):
file_path = 'media/books.xlsx'
workbook = load_workbook(filename=file_path)
worksheet = workbook.active
books = []
skip_first_row = True
for row in worksheet.iter_rows(values_only=True, min_row=2 if skip_first_row else 1):
genre_check = row[3].lower() == genre.lower() if genre else True
if genre_check:
book = {
'book_id': int(row[0]),
'title': row[1],
'author': row[2],
'genre': row[3],
'year': int(row[4]),
'description': row[5],
'cover': row[6]
}
books.append(book)
return books
def all_books(request):
books = get_books()
return render(request, 'books.html', {'books': books})
def book_detail(request, book_id):
books = get_books()
book = books[int(book_id) - 1]
return render(request, 'book_detail.html', {'book': book})
def thriller(request):
books = get_books('триллер')
return render(request, 'books.html', {'books': books})
def mystery(request):
books = get_books('детектив')
return render(request, 'books.html', {'books': books})
def fantasy(request):
books = get_books('фэнтези')
return render(request, 'books.html', {'books': books})
def programming(request):
books = get_books('программирование')
return render(request, 'books.html', {'books': books})
При обработке данных из файла media/books.xlsx функция пропускает первую строку с названиями столбцов.
Порядковый номер и год выпуска преобразуются в целые числа int(), так как по умолчанию модуль openpyxl
считает их float().
Если приложение использует не локальный файл books.xlsx из папки media, а таблицу Google Sheets, то функции будут выглядеть так:
from django.shortcuts import render
import csv
import requests
def get_books(request, genre=None):
sheet_id = "1IkfPkI5ZBtzVJlyomD21nFg4ZUMnJgqLqVrNbiTWkME"
sheet_name = "Books"
url = f"https://docs.google.com/spreadsheets/d/{sheet_id}/gviz/tq?tqx=out:csv&sheet={sheet_name}"
response = requests.get(url)
if response.ok:
book_data = response.text
reader = csv.DictReader(book_data.splitlines())
books = [
{
'book_id': int(row['Номер']),
'title': row['Название'],
'author': row['Автор'],
'genre': row['Жанр'],
'year': int(row['Год издания']),
'description': row['Краткое содержание'],
'cover': row['Обложка']
}
for row in reader if genre is None or row['Жанр'].lower() == genre.lower()
]
return render(request, 'books.html', {'books': books})
else:
return render(request, 'error.html', {'message': 'Ошибка получения данных'})
def all_books(request):
return get_books(request)
def book_detail(request, book_id):
books = get_books(request)
book = books[int(book_id)]
return render(request, 'book_detail.html', {'book': book})
def thriller(request):
return get_books(request, 'триллер')
def mystery(request):
return get_books(request, 'детектив')
def fantasy(request):
return get_books(request, 'фэнтези')
def programming(request):
return get_books(request, 'программирование')
Заметим, что при использовании данных из таблицы Google Sheets имеет смысл хранить изображения не на локальном сервере, а загружать на подходящий фотохостинг. В этом случае в столбце Обложка нужно указывать прямую ссылку на изображение.
Данные передаются в шаблон books.html. Обратите внимание, что шаблон books.html наследует базовый шаблон base.html, в котором:
- Определена общая для всех страниц разметка.
- Подключен Bootstrap – CSS/HTML/JS фреймворк.
- Заданы дополнительные CSS стили
<style></style>. - Содержится JS-скрипт, который переключает тему со светлой на темную и запоминает выбор пользователя в localStorage браузера.
Подробнее механизмы наследования и включения шаблонов мы рассмотрим в главе, посвященной шаблонизатору Django. Заметим, что дополнительные CSS стили и JS-скрипты для крупных проектов обычно хранятся в отдельных файлах в папке static – с этой концепцией мы подробно разберемся в разделе «Статические файлы».
Вывод данных в шаблоне происходит в цикле:
{% for book in books %}
<div class="card mb-3 px-0">
<div class="row g-0">
<div class="col-md-4 card-image">
<img src="/media/covers/{{book.cover}}.jpeg" class="img-fluid rounded" alt="{{ book.cover }}">
</div>
<div class="col-md-8">
<div class="card-body">
<h5 class="card-title">{{ book.title }}</h5>
<h5 class="card-title text-muted">{{ book.author }}</h5>
<span class="badge text-bg-danger">{{ book.genre }}</span>
<p class="card-text">{{ book.description|truncatechars:"120"|linebreaks }}</p>
<p class="text-end"><a href="{% url 'book_detail' book_id=book.book_id %}" class="btn btn-primary">Подробнее</a></p>
</div>
</div>
</div>
</div>
{% endfor %}
Для ограничения описания книги до 120 символов используется
конструкция |truncatechars:"120"|linebreaks. Ссылка,
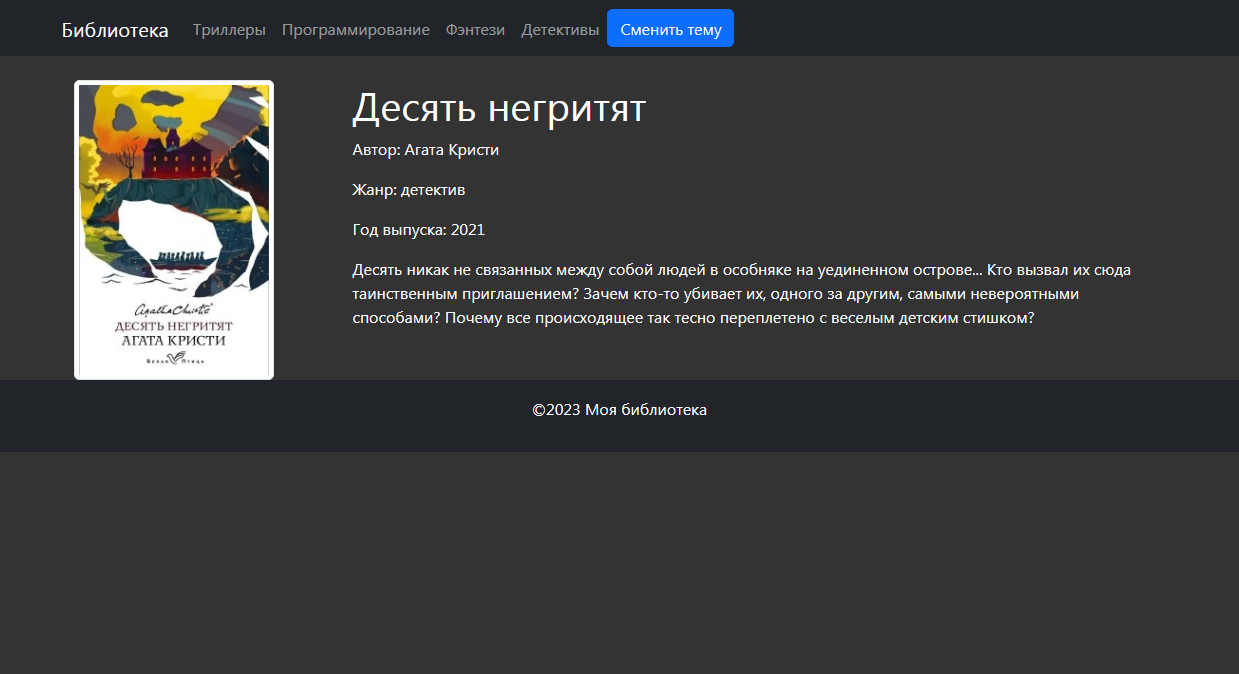
привязанная к кнопке «Подробнее», обеспечивает передачу в функцию book_detail() порядкового номера книги – так Django узнает,
о какой именно книге нужно вывести информацию на отдельной странице:
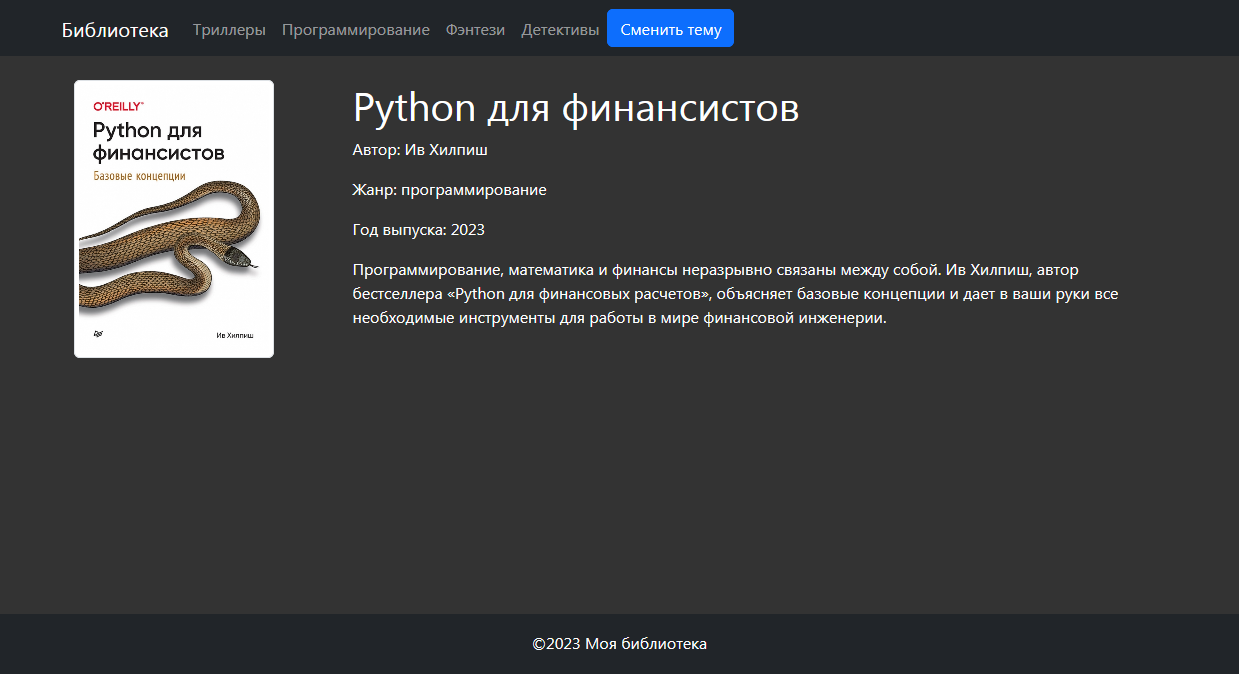
Верхнее меню содержит ссылки на другие функции представления, которые обеспечивают вывод книг по жанрам:
<ul class="navbar-nav ml-auto">
<li class="nav-item">
<a class="nav-link" href="{% url 'thriller' %}">Триллеры</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{% url 'programming' %}">Программирование</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{% url 'fantasy' %}">Фэнтези</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{% url 'mystery' %}">Детективы</a>
</li>
</ul>
При нажатии на эти ссылки происходит запуск соответствующих функций представления в books/views.py:
- thriller() – выбирает из books.xlsx все триллеры;
- mystery() – выводит детективы;
- fantasy() – отбирает книги в жанре фэнтези;
- programming() – выбирает книги по программированию.
Маршруты, которые приводят в действие все эти функции, определены в books/urls.py:
urlpatterns = [
path('books/', views.all_books, name='all_books'),
path('book/<int:book_id>/', views.book_detail, name='book_detail'),
path('programming/', views.programming, name='programming'),
path('thriller/', views.thriller, name='thriller'),
path('mystery/', views.mystery, name='mystery'),
path('fantasy/', views.fantasy, name='fantasy'),
]
Все классы, используемые в шаблонах (например, class="card-text">) являются классами Bootstrap. Классы позволяют применять к
элементам шаблона наборы CSS
стилей, которые обеспечивают тексту и изображениям привлекательный внешний вид.
Стили можно дополнять, а при необходимости – полностью переопределять. Например,
в шаблоне base.html мы
определяем два стиля, которые обеспечивают фиксированную позицию для футера –
внизу страницы:
.content-wrapper {
min-height: 100%;
position: relative;
padding-bottom: 60px;
}
footer {
position: absolute;
bottom: 0;
width: 100%;
height: 60px;
background-color: #343a40;
color: #fff;
text-align: center;
padding: 15px;
}
Без этих стилей футер не будет «прилипать» к низу страницы, если на ней мало контента:
Подведем итоги
Небольшие веб-приложения вполне могут обойтись без базы данных. К тому же использование файла вместо БД может быть оптимальным решением в том случае, если над сбором данных работают несколько человек: предоставить общий доступ к XLSX-файлу гораздо проще, чем к базе.
Содержание курса
- Часть 1: Django — что это? Обзор и установка фреймворка, структура проекта
- Проект 1: Веб-приложение на основе XLSX вместо базы данных
- Часть 2: ORM и основы работы с базами данных
- Проект 2: Портфолио разработчика
Комментарии