
Список шагов для устранения проблем, связанных с обучением, обобщением и оптимизацией модели глубокого обучения и отладки нейронной сети.

Программный код машинного обучения не совсем похож на другие программные решения. Поэтому он может быть достаточно сложен для отладки. Даже для простых нейронных сетей прямого распространения необходимо принять несколько решений об архитектуре сети, инициализации весов и оптимизации нейросети. На всех этих этапах в концепции обучения и их реализации в виде кода модели могут вкрасться коварные ошибки.
Чейз Робертс в статье «Как делать юнит тесты для машинного обучения» (англ.) выделил три основных типа ловушек:
- Код никогда не падает, вызывает исключения или даже замедляется.
- Пока сеть тренируется, потери не перестают снижаются.
- Значения сходятся через несколько часов, но приводят к плохим результатам.
Что же с этим делать? Эта статья предоставит структуру, которая поможет вам отладить ваши нейронные сети.
1. Начните с простого
Нейронную сеть со сложной архитектурой, регуляризацией и планировщиком скорости обучения будет сложнее отлаживать, чем простую сеть. Этот пункт может представляться несколько надуманным, ведь он не имеет отношения к отладке имеющейся нейросети. Но он важен для тех, кто хочет со старта контролировать ситуацию.
Создайте сначала простую модель
Создайте небольшую сеть с одним скрытым слоем и убедитесь, что все работает правильно. Постепенно усложняя модель, проверяйте, работает ли каждый аспект структуры (дополнительный слой, параметр и т. д.).
Обучите модель на одной точке из массива данных
В качестве быстрой проверки работоспособности используйте одну или две точки тренировочных данных. Нейросеть должна немедленно переобучаться до 100% точности. Если модель не может «воспроизвести» такой малый объем данных, она либо слишком мала, чтобы их аппроксимировать, либо уже имеется ошибка. Итак, вы убедились: модель работает. Прежде чем двигаться дальше, попробуйте потренировать ее один или несколько периодов дискретизации (epoch).
2. Потери
Потери модели (loss) – основной критерий оценки производительности и собственный критерий нейросети, по которому определяется важность какого-либо параметра, поэтому убедитесь в следующем:
- Функция потерь соответствует задаче (например, категориальная кросс-энтропия для задачи классификации или focal loss для несбалансированных классов).
- Функция потерь измеряется по правильной шкале. Если вы используете более одного типа функции потерь (MSE, feature loss, L1), важно проверить, что все потери масштабируются до одного порядка.
Обратите внимание на начальные потери – соответствует ли их порядок модели, начинающейся со случайных предположений. В Стэндфордском курсе CS231n Андрей Карпатый предлагает следующее: «Убедитесь, что вы получаете ожидаемые потери при инициализации малыми параметрами. Регуляризацию сначала лучше уменьшить до нуля. Так, для CIFAR-10 с классификатором Softmax мы ожидаем, что начальные потери будут 2.302. У нас 10 классов, значит, вероятность диффузии составляет 0.1. Потеря Softmax является отрицательным логарифмом от вероятности. То есть потери равны –ln(0.1) = 2.302»
Для бинарного случая выполняется аналогичный расчет для каждого из классов. Допустим, данные на 20% состоят из нулей и 80% – из единиц. Ожидаемая начальная потеря составляет –0.2ln(0.5)–0.8ln(0.5) = 0.693. Если исходные потери много больше 1, нейронная сеть не сбалансирована должным образом (т. е. плохо инициализирована), или данные не нормализованы.
3. Проверьте промежуточные выходы слоев и соединения
Для отладки нейронной сети бывает полезным понимать внутреннюю динамику и ту индивидуальную роль, которую играют промежуточные слои и межсоединения. Вы можете столкнуться с ошибками:
- Некорректные выражения для обновлений градиента.
- Отсутствие обновлений вычисленных весов.
- Исчезающие или лавинообразно нарастающие градиенты.
Если значение градиента равно нулю, это может означать, что скорость обучения в оптимизаторе слишком мала. Или то, что вы столкнулись с первой из перечисленных ошибок.
Помимо просмотра абсолютных значений обновлений градиента, обязательно следите за величинами активаций, весов и обновлениями каждого слоя. Например, величина обновлений параметров (весов и смещений) должна составлять 1-e3.
Существует явление, называемое «умирающий ReLU» или «проблема исчезающего градиента». Оно происходит, когда нейроны обучаются с большим отрицательным смещением весов. В этом случае нейроны больше не активируются ни на одной из точек данных. Вы можете использовать проверку градиента для отслеживания таких ошибок, аппроксимируя градиент численным образом. Для этого ознакомьтесь с соответствующими разделами CS231n (раз и два) и специальным уроком Эндрю Ына.
Что касается визуализации нейронной сети, Файзан Шейх описал три основных группы методов:
- Предварительные методы. Простые методы, показывающие общую структуру тренируемой модели с печатью форм и фильтров индивидуальных слоев нейросети и параметров каждого слоя.
- Методы, основанные на активации. В этих методах расшифровывается активация отдельных нейронов и групп нейронов.
- Методы, основанные на градиенте. Эти методы стремятся к манипуляции градиентами, которые формируются при проходах вперед и назад при обучении модели (включая карты значимости и карты активации классов).
Существует множество полезных инструментов для визуализации активаций и соединений отдельных слоев, например, ConX и TensorBoard. Здесь представлен пример визуализацией нейросети, сделанной с помощью ConX:
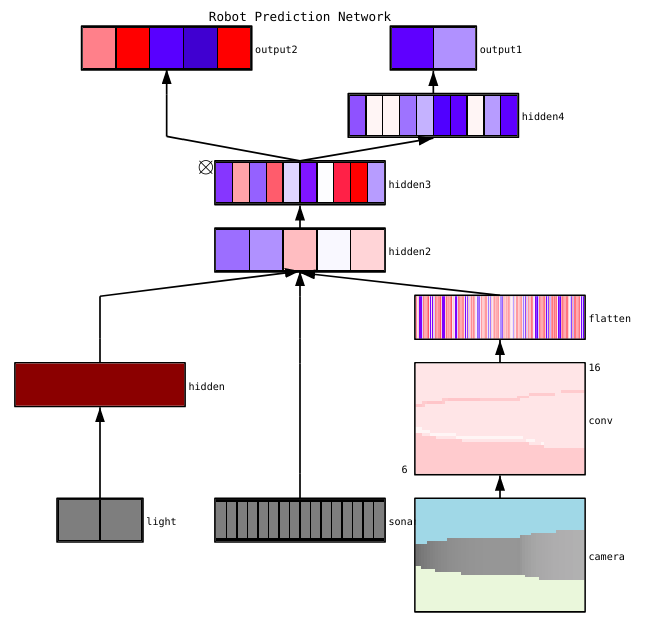
Если для вас важны вопросы отладки нейронной сети, обрабатывающей изображения, ознакомьтесь с красочной публикацией Эрика Риппела «Визуализация частей сверточных нейронных сетей с использованием Keras и кошек» (англ.).
4. Диагностика параметров
Нейронные сети имеют огромное число параметров для настройки, к тому же взаимосвязанных, что затрудняет их оптимизацию. Обратите внимание: эта сфера является областью активных исследований. Так что изложенные ниже рекомендации – лишь начальные точки.
Размер батча (mini-batch)
С одной стороны, размер пакета должен быть довольно большим, чтобы сделать оценку ошибки градиента. С другой, батч должен быть довольно мал, чтобы градиентный спуск мог регуляризовать нейросеть. Слишком малые размеры батча заставляют процесс обучения быстро сходиться за счет шума и могут приводить к трудностям оптимизации.
В публикации «Об использовании крупных батчей для глубокого обучения: разрыв в обобщении и острые минимумы» (англ.) говорится: «На практике наблюдалось, что при использовании крупных батчей качество модели ухудшалось. Это было определено по способности модели к обобщению. Исследуя причину ухудшения, мы представили численные доказательства того, что метод крупных батчей имеет тенденцию сходиться к резким минимизаторам функций обучения и тестирования. А резкие минимумы, как известно, приводят к худшей обобщающей способности. Напротив, методы с малыми батчами сходятся к плоским минимизаторам. Эксперименты подтверждают мнение, что такое поведение обусловлено внутренним шумом при оценке градиента».
Скорость обучения
При низкой скорости обучения процесс рискует застрять в локальных минимумах. Слишком высокая скорость обучения приведет к расхождению процесса оптимизации, так как вы можете «перепрыгнуть» через узкую, но глубокую часть функции потерь. Рассмотрите вопрос планирования скорости обучения, чтобы правильно снижать скорость обучения по мере тренировки нейросети. В курсе CS231n имеется раздел, посвященный методикам реализации процедуры отжига при настройке скорости обучения. Многие фреймворки используют планировщики скорости обучения или схожие стратегии. Приведем здесь ссылки на соответствующие разделы документации: Keras, TensorFlow, PyTorch, MXNet.
Ограничение нормы градиента (gradient clipping)
Gradient clipping предполагает ограничение параметров градиента в процессе обратного распространения по максимальному значению или максимальной норме. Этот подход полезен для устранения взрывных градиентов.
Пакетная нормализация
Пакетная нормализация используется для нормализации входных данных каждого слоя, чтобы бороться с проблемой внутреннего ковариантного сдвига. Наиболее распространенные ошибки, связанные с пакетной нормализацией, описаны в соответствующей публикации Дишэнка Банзала.
Стохастический градиентный спуск
Существует несколько разновидностей стохастического градиентного спуска (СГС), использующих импульс, адаптивные скорости обучения и обновления Нестерова. Но ни одна из этих разновидностей не выигрывает одновременно и по эффективности обучения, и по его обобщению (см. обзор алгоритмов оптимизации градиентного спуска и эксперимент SDG > Adam). Рекомендуемой отправной точкой является Adam или простой СГС с импульсом Нестерова.
Регуляризация
Регуляризация имеет решающее значение для построения обобщаемой модели. Она добавляет штраф за сложность модели или экстремальные значения параметров. Это значительно уменьшает дисперсию модели без существенного увеличения ее смещения.
Важное замечание дается в курсе CS231n: «Часто функция потерь представляет собой сумму потерь данных и потерь регуляризации (например, штраф L2 по весам). Опасность в том, что потеря регуляризации может превысить потерю данных. В этом случае градиенты будут исходить в основном от компонента, обусловленного регуляризацией. Он обычно имеет более простое выражение градиента. Это может маскировать неправильную реализацию градиента потери данных». В таком случае вы должны отключить регуляризацию и независимо проверить градиент потери данных.
Исключение (dropout)
Исключение – еще одна техника, позволяющая регуляризовать вашу нейросеть и избежать переобучения. Использование дропаута в процессе обучения заключается в ограничении числа активных нейронов при помощи вероятностного гиперпараметра. В результате нейросети требуется использовать другое подмножество параметров для пакета, на котором происходит обучение. Исключение уменьшает изменение определенных параметров, которые начинают доминировать над другими. То есть более обученные нейроны получают в сети больший вес.
Теперь важное предупреждение, если вы используете вместе дропаут и пакетную нормализацию. Будьте осторожны с порядком выполнения этих операций или совместным использованием. В этом вопросе пока не найден консенсус. Некоторые идеи на этот счет можно найти в следующей публикации.
5. Документируйте результаты экспериментов и отладки нейронной сети
Легко недооценивать важность документации ваших экспериментов до тех пор пока вы не забудете какие скорости обучения и веса классов вы ранее использовали. Важно иметь возможность легко отслеживать, просматривать и воспроизводить предыдущие эксперименты. Это уменьшает объем повторяемых работ и упрощает процесс отладки нейронной сети.
Ручное документирование информации практически всегда трудоемко. Поэтому пригодятся такие инструменты, как Comet.ml, помогающие автоматически отслеживать наборы данных, изменения кода, историю экспериментов и производственные модели. В том числе и такие ключевые сведения о вашей модели, как гиперпараметры, показатели производительности и детали программного окружения.
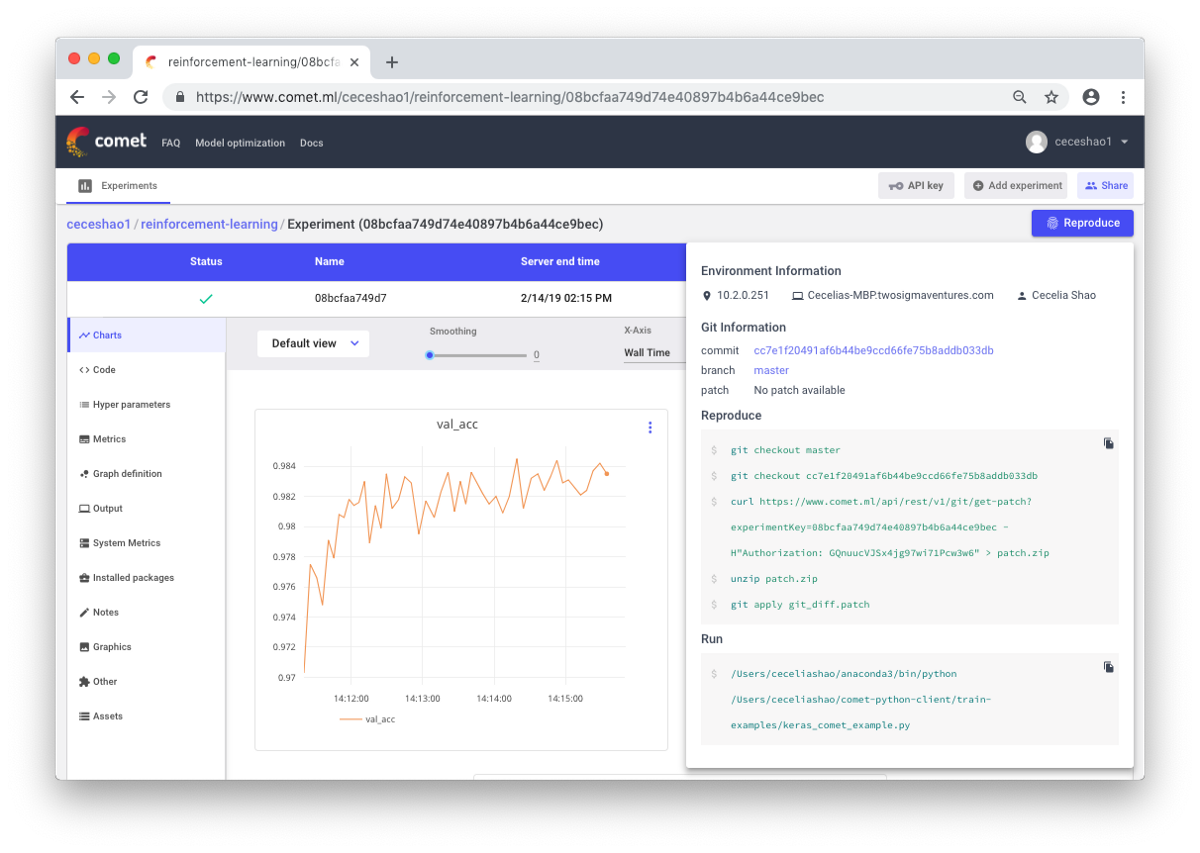
Нейросеть может быть чувствительной к небольшим изменениям данных, параметров и версий пакетов. Это может приводить к падению производительности модели. Отслеживание вашей работы – первый шаг, который вы можете предпринять, чтобы стандартизировать рабочую среду.
Комментарии