
Разбираемся, какие методы обработки данных используют NoSQL базы, рассматриваем шардинг, репликацию, процесс управления хранилищем и методы обработки запросов.
Методы работы
Причина, по которой существуют многие различные NoSQL базы данных, заключается в том, что какая-то одна система не сможет удовлетворить запросы приложения набором своих свойств.
Скажем, традиционные SQL базы, такие как PostreSQL, созданы для обеспечения полного набора функций: гибкая модель данных, возможность сложных запросов, надежность транзакций.
С другой стороны, существуют хранилища ключ-значение, вроде Dynamo, которые хорошо масштабируются и обеспечивают высокую пропускную способность для чтения-записи, но при этом едва ли способны выдать операции запросов сложнее, чем простейший поиск.
Далее рассмотрим способы проектирования распределенных баз данных, сконцентрировавшись на шардинге, репликации, управлении хранилищем и обработке запросов.
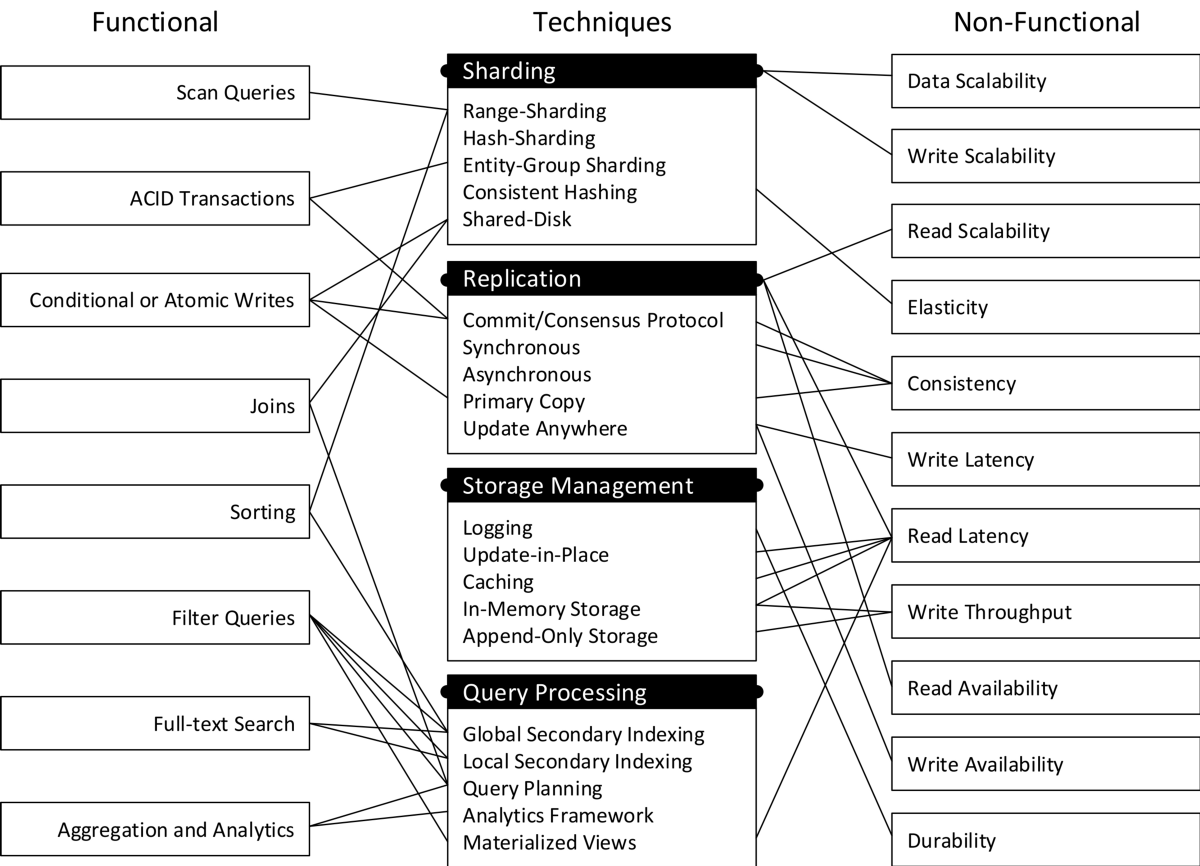
Шардинг
Некоторые распределенные системы реляционных баз данных, такие как Oracle RAC или IBM DB2 pureScale, основаны на архитектуре с общим диском, где все узлы базы данных обращаются к одному и тому же центральному репозиторию. Эти системы всегда обеспечивают согласованность данных, но сложно масштабируются.
NoSQL системы, рассматриваемые в этой статье, построены на архитектуре без общего доступа. То есть каждая система здесь состоит из множества серверов с частной памятью и частными дисками, которые подключены через сеть. Масштабируемость пропускной способности и объема данных достигается путем разбиения (шардинга) данных на разные узлы (шарды) по всей системе.
Для гибкости системы и упрощения поиска данные могут разбиваться по определенным диапазонам между серверами. Управляет всем оркестром баз данных автоматическая система, которая распределяет данные и реагирует на перегрузку шарда, чтобы перенести часть данных на другой, более свободный, шард.
Репликация
Репликация – это еще одна техника масштабирования баз данных. Идея репликации состоит в том, чтобы постоянно копировать (реплицировать) данные с одного сервера на другой (реплику) или несколько таких серверов. Таким образом, приложение может использовать для обработки запросов не один сервер, а параллельно два или больше – это разгружает сервера.
Существует два подхода в работе с репликацией данных:
- Master-Slave репликация
- Master-Master репликация
Master-Slave репликация
В этом подходе существует один основной сервер, который называется Мастером – на нем происходят все изменения данных. Слейв-сервер должен копировать все изменения, происходящие на Мастере. Для чтения данных приложение отправляет запросы на Слейв, а Мастер отвечает только за запись и изменения. В этой системе может быть несколько Слейв-серверов.
Master-Master репликация
В этой схеме любой сервер может быть использован для изменения и чтения данных, при этом происходящие на нем изменения будут продублированы на другой сервер.
Управление хранилищем
В отличие от реляционных баз данных, NoSQL решения избегают специализированных аппаратных архитектур с общим диском в пользу кластеров с общим доступом на обычных серверах. В хранении данных принимают участие как оперативная память, так и SSD и жесткие диски. Обычно их изображают как «пирамиду хранения»:
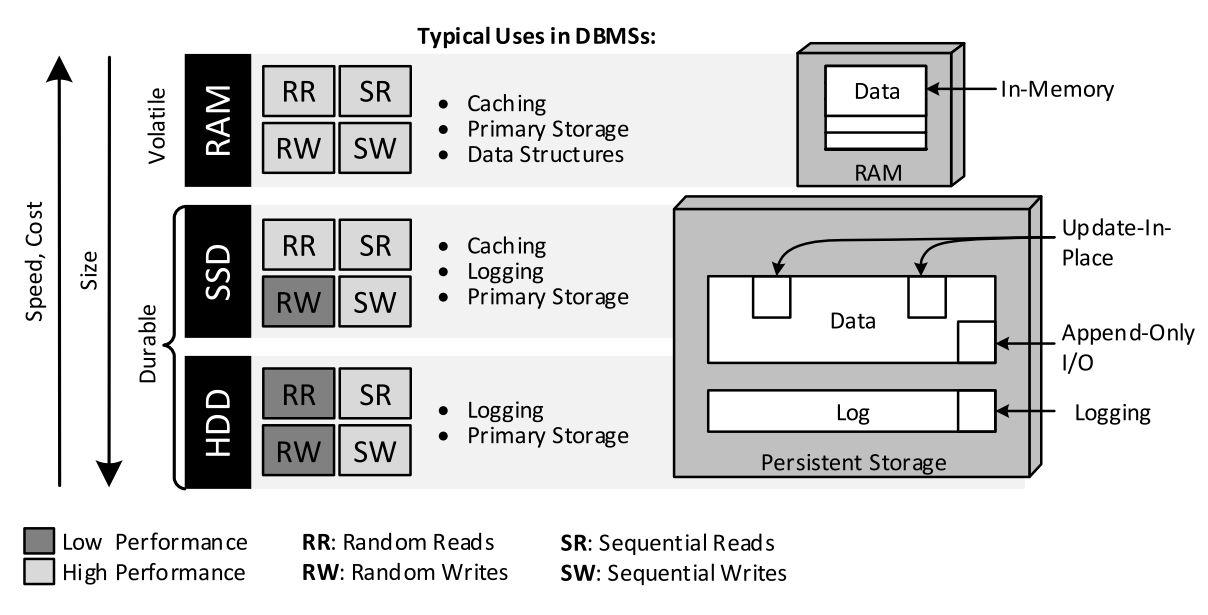
Применяются также кэши процессоров L1-L3 и дисковые буферы, которые используются неявно за счет хорошо спроектированных алгоритмов баз, локализирующих данные.
Для хранения основных данных и работы с ними могут применяться любые носители, в том числе оперативная память. Основное ее преимущество – в большой пропускной способности, однако она недолговечна и даже небольшое отключение питания может стать причиной утраты данных. Эта проблема может быть решена за счет репликации данных на множество узлов, однако этот способ хранения при всей скорости доступа является затратным.
HDD и твердотельные накопители являются классическими устройствами для хранения данных и используются в большинстве хранилищ.
Обработка запросов NoSQL базы данных
Возможности обработки запросов NoSQL базы данных напрямую следуют из ее модели распределения. Поиск по ключу, то есть возможность найти и отдать данные по id, поддерживают любые NoSQL базы данных.
Сложные запросы, а точнее аналитика полученных из базы данных, могут выполняться либо изначально (как например, в MongoDB, Riak, CouchDB), так и через внешние платформы для аналитики, такие как Hadoop, Spark и Flink (например, для Cassandra и HBase).
Популярное решения для распределенных вычислений кластеров NoSQL базы данных – MapReduce. MapReduce работает в два шага:
- Map-шаг: предварительная обработка полученных данных. На этом шаге Мастер или один из Мастер-серверов получает данные задачи, разделяет их на части и передает для предварительной обработки другим узлам.
- Reduce-шаг: свертка обработанных данных. Мастер получает от прочих узлов подготовленные данные, формирует и отдает ответ, который является решением входной задачи.
Комментарии