

Что такое Apache Kafka?
Kafka – разносторонний инструмент: его можно рассматривать как брокер сообщений, распределенное хранилище событий и платформу для потоковой обработки данных. Изначально Kafka разрабатывался как внутренний проект LinkedIn, но в итоге стал ключевым элементом большинства событийно-ориентированных систем – вот всего несколько примеров того, что можно сделать с помощью Кафки:
- Гиганты уровня Netflix и Uber обрабатывают большие объемы данных в реальном времени.
- E-commerce платформы отслеживают действия пользователей, изменение заказов и состояние запасов.
- Финансовые организации анализируют данные о транзакциях и обнаруживают подозрительные операции.
- Трейдеры выявляют рыночные тренды и аномалии в торгах.
- Ритейлеры анализируют поведение клиентов и их предпочтения в режиме реального времени, чтобы рекомендовать товары и предлагать персонализированные акции.
Почему Kafka стал настолько популярным? Основные причины – надежность и масштабируемость: Kafka эффективно управляет потоками данных в самых крупномасштабных системах. Если вам еще не приходилось использовать Кафку, давайте разберемся, как он работает: возможно, его возможности выведут ваш проект на новый уровень.
Сообщения и пакеты
В Kafka основной единицей данных является сообщение. Сообщение можно сравнить с записью в таблице базы данных, но фактически это просто байтовый массив. Структуру сообщения задают с помощью JSON, XML или системы сериализации Apache Avro.
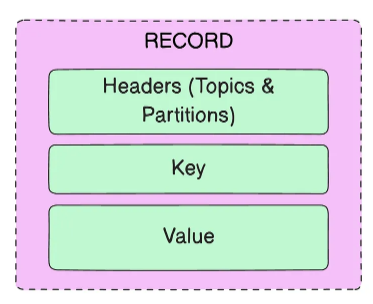
Сообщения записываются пакетами. Пакет – это набор сообщений, относящихся к одной теме и одному разделу. Пакетная запись снижает нагрузку на систему и повышает эффективность передачи данных. Сжатие пакетов делает передачу данных и их хранение более эффективными – меньший объем данных быстрее передается по сети и экономит место на диске. Использование пакетов подразумевает компромисс между задержкой и пропускной способностью:
- Большие пакеты позволяют передавать больше сообщений за одно действие, что увеличивает пропускную способность системы – можно обработать больше данных за меньшее время.
- Однако это также приводит к увеличению задержки для отдельных сообщений. Пока пакет не будет полностью заполнен, отдельное сообщение может дольше ждать отправки.
Поэтому идеальный размер пакета зависит от конкретного сценария использования. Если важнее производительность обработки, лучше использовать большие пакеты. Если же важна низкая задержка (например, при обработке критически важных событий), пакеты должны быть меньше.
Темы и разделы
Тема в Kafka похожа на таблицу в базе данных или папку в файловой системе. Все сообщения распределены по темам. Темы делятся на разделы. Сообщения в теме добавляются в один из ее разделов, причем всегда в конец. Внутри одного раздела сообщения
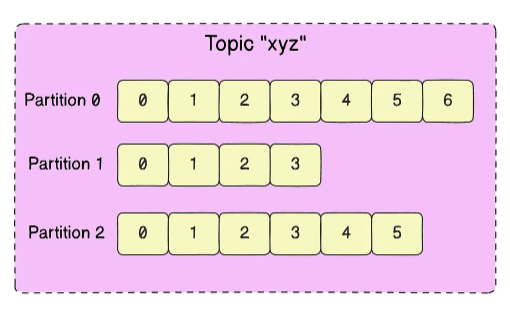
Разделы позволяют масштабировать систему, так как они могут находиться на разных серверах (брокерах). Это также повышает надежность: если один сервер выйдет из строя, данные можно будет получить с другого.
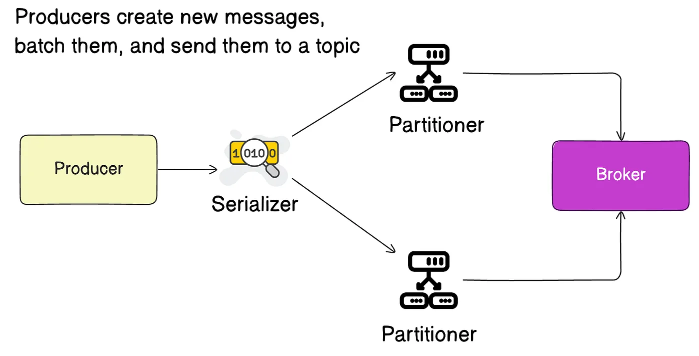
Производители и потребители
Основные пользователи Kafka – это производители и потребители, которые взаимодействуют в соответствии с известным паттерном издатель-подписчик. Производители создают и отправляют сообщения в брокер Kafka, указывая, в какую тему их отправить:
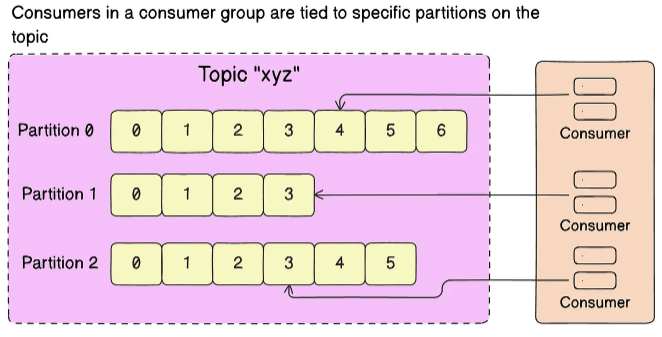
Потребители считывают сообщения из тем, работая в составе групп потребителей. Каждая группа следит за тем, чтобы один раздел обрабатывался только одним участником группы. Если один потребитель выходит из строя, другие участники группы перенимают его задачи:
Брокеры и кластеры
Каждый сервер Kafka называется брокером. Со стороны производителей брокер выполняет три основные задачи:
- Получает сообщения от производителей.
- Назначает смещение (порядковый номер, индекс) для сообщений.
- Сохраняет сообщения на диске.
Со стороны потребителей брокер выполняет эти задачи:
- Обрабатывает запросы на получение данных из разделов.
- Отправляет опубликованные сообщения в ответ на эти запросы.
Один брокер может управлять тысячами разделов и миллионами сообщений в секунду. Брокеры обычно объединяются в кластер. В кластере один из брокеров выполняет роль контроллера, распределяя разделы и отслеживая сбои.
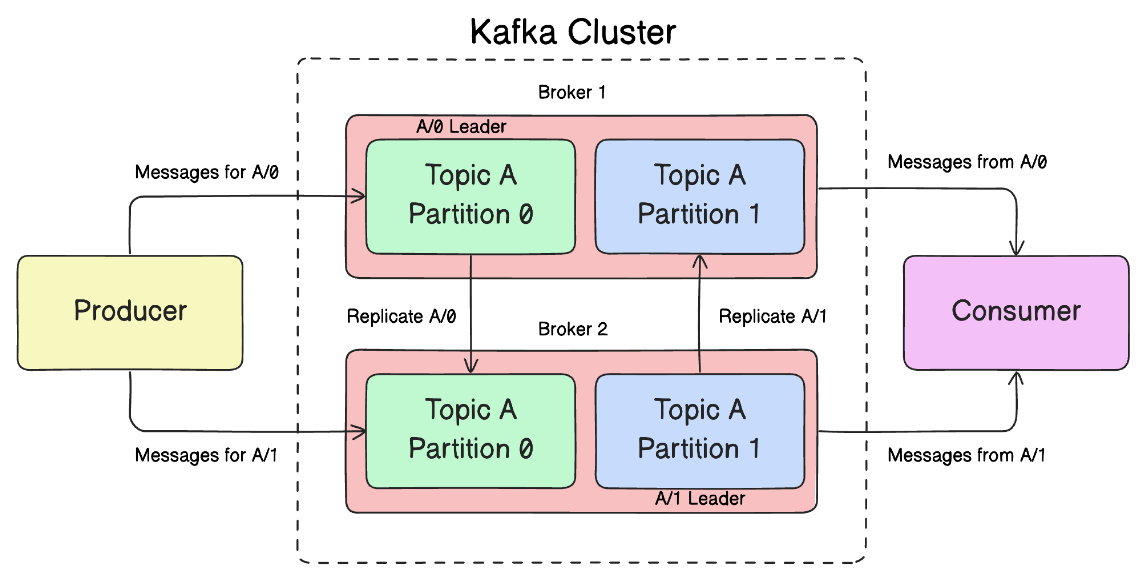
Репликация
Главное преимущество кластера Kafka – возможность репликации сообщений. Репликация обеспечивает резервирование хранящихся в разделе сообщений. В Kafka каждый раздел всегда принадлежит одному брокеру в кластере, который называется лидером этого раздела. Однако, когда раздел реплицируется, он также назначается дополнительным брокерам. Эти дополнительные брокеры являются последователями (фолловерами) раздела. Если у раздела есть несколько копий, взаимодействие производителей и потребителей выглядит так:
- Производители всегда подключаются к лидеру раздела, чтобы публиковать сообщения в этот раздел.
- Если лидер выходит из строя, один из последователей берет на себя роль лидера этого раздела. Это обеспечивает высокую доступность и устойчивость к сбоям.
- Потребители могут получать сообщения как от лидера, так и от одного из последователей. Это позволяет распределить нагрузку и улучшить производительность.
Преимущества Kafka
Kafka обладает рядом преимуществ, которые делают его уникальным инструментом для обработки больших потоков данных в реальном времени:
- Поддержка множества производителей. Kafka может легко работать с несколькими источниками данных одновременно. Например, если у вас есть веб-приложение со множеством микросервисов, каждый из которых отслеживает действия пользователей, Kafka может собирать данные о просмотрах страниц в единую тему. Это позволяет агрегировать данные из различных источников и приводить их к единому формату.
- Поддержка множества потребителей. Kafka позволяет нескольким потребителям одновременно читать один и тот же поток сообщений, не мешая друг другу. В отличие от других систем очередей, где сообщение удаляется после его обработки, в Kafka одно и то же сообщение может быть прочитано разными процессами. Кроме того, несколько потребителей могут объединяться в группы, и тогда каждое сообщение будет обрабатываться только одним участником группы.
- Гибкие правила сохранения на диске. Kafka дает возможность настроить правила хранения. Это позволяет потребителям не беспокоиться о том, что они могут отстать из-за медленной обработки, резкого увеличения нагрузки или временного выхода из строя. Сообщения не потеряются, и потребители смогут продолжить работу с того места, на котором остановились. Это также упрощает администрирование потребителей, так как их можно отключать и перезапускать без опасений потерять данные.
- Масштабируемость. Kafka способен обрабатывать любые объемы данных: на этапе разработки можно начать можно с одного брокера, а затем в продакшене постепенно увеличить количество до нескольких десятков или даже сотен брокеров. Расширение можно выполнять без остановки системы, что делает Кафку особенно удобным для использования в высоконагруженных приложениях.
Недостатки Kafka
Как и любое другое ПО, Kafka не идеален:
- Сложность настройки. Правильная настройка системы требует глубокого понимания всех опций, что порой затрудняет оптимизацию работы, поскольку Кафка предлагает огромное количество конфигурационных параметров. Разобраться в них не так просто даже для опытных разработчиков, не говоря уже о начинающих.
- Встроенные инструменты управления Kafka оставляют желать лучшего. Например, названия аргументов командной строки отличаются непоследовательностью.
- Недостаток зрелых клиентских библиотек. Хотя Kafka отлично поддерживается в Java и C/C++, клиентские библиотеки для других языков программирования не всегда достигают нужного уровня качества. Впрочем, эта проблема скоро будет решена: сообщества нескольких ЯП интенсивно работают над улучшением качества библиотек.
- Отсутствие полноценной мультиарендности. Kafka не поддерживает настоящую мультиарендность – пока что нет возможности создавать полностью изолированные логические кластеры внутри физического кластера. Это ограничивает использование Kafka для раздельной работы нескольких команд или организаций в одном кластере.
Какой самый неожиданный use-case для Kafka ты встречал в своей практике?
Комментарии