
Обучение с подкреплением в – это способ машинного обучения, при котором система обучается, взаимодействуя с некоторой средой.
В последние годы мы наблюдаем прогресс в исследованиях в данной области. Например DeepMind, Deep Q learning в 2014, победа чемпиона мира в Go с помощью алгоритма AlphaGo в 2016, OpenAl и PPO в 2017
В этой статье мы сфокусируемся на изучении различных архитектур, которые активно используются вместе с обучением с подкреплением в наши дни для решения различного рода проблем, а именно Q-learning, Deep Q-learning, Policy Gradients, Actor Critic и PPO.
Из этой статьи, вы узнаете:
- Что такое обучение с подкреплением и для чего оно вообще нужно.
- Три подхода к обучению с подкреплением.
Очень важно освоить все эти элементы, прежде чем погружаться в реализацию системы глубинного обучения с подкреплением.
Идея обучения с подкреплением заключается в том, что система будет учиться в среде, взаимодействовать с ней и получать вознаграждение за выполнение действий.

Представьте, что вы ребенок в гостиной. Вы увидели камин и захотели подойти к нему.
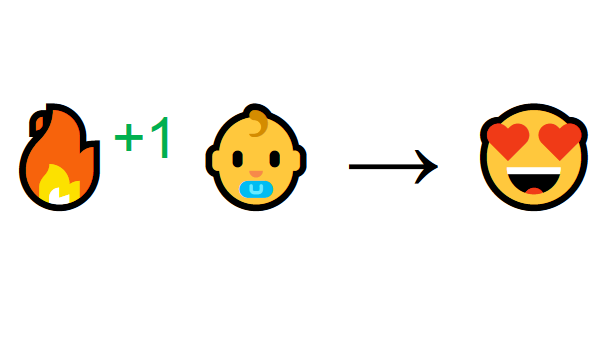
Тут тепло, вы хорошо себя чувствуете. Вы понимаете, что огонь – это хорошо.
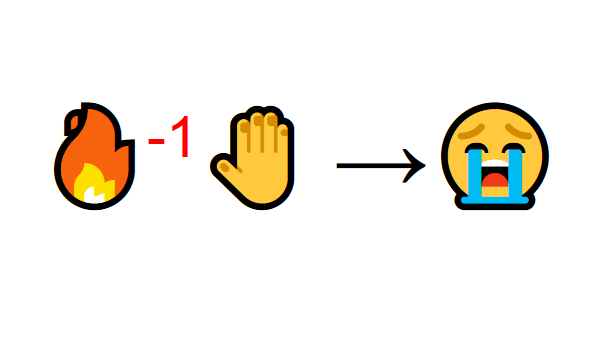
Но потом вы пытаетесь дотронуться до огня и обжигаете руку. Только что вы осознали, что огонь – это хорошо, но только тогда, когда находитесь на достаточном расстоянии, потому что он производит тепло. Если подойти слишком близко к нему, вы обожжетесь.
Вот как люди учатся через взаимодействие. Обучение с подкреплением – это просто вычислительный подход к обучению на основе действий.
Как выглядит обучение с подкреплением

Давайте в качестве примера представим, что система учится играть в Super Mario Bros. Процесс обучения с подкреплением может быть смоделирован как цикл, который работает следующим образом:
- Наша система получает состояние S0 от окружающей среды (в нашем случае мы получаем первый кадр нашей игры (состояние) от Super Mario Bros (окружающая среда))
- Основываясь на этом состоянии, система выполняет действие A0 (наш герой будет двигаться вправо)
- Переход среды в новое состояние S1 (новый фрейм)
- Среда дает некоторую награду R1 нашему герою
Этот цикл ОП выводит последовательность состояний, действий и вознаграждений.
Цель системы – максимизировать ожидаемое вознаграждение.
Главная идея гипотезы вознаграждения
Почему целью системы является максимизация ожидаемого вознаграждения?
Обучение с подкреплением основано на идее гипотезы вознаграждения. Все цели можно описать максимизацией ожидаемого вознаграждения.
Именно поэтому в ОП, для того чтобы сделать наилучший ход , нужно максимизировать ожидаемое вознаграждение.
Вознаграждение на каждом временном шаге (t) может быть записано как:

Что эквивалентно:
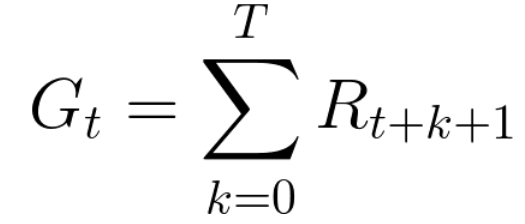
Однако на самом деле мы не можем просто добавить такие награды. Награды, которые приходят раньше (в начале игры), более вероятны, так как они более предсказуемы, чем будущие вознаграждения.

Допустим, ваш герой – это маленькая мышь, а противник – кошка. Цель игры состоит в том, чтобы съесть максимальное количество сыра, прежде чем быть съеденным кошкой.
Как мы можем видеть на изображении, скорее всего мышь будет есть сыр рядом с собой, нежели сыр, расположенный ближе к кошке (т.к. чем ближе мы к кошке, тем она опаснее).
Как следствие, ценность награды рядом с кошкой, даже если она больше обычного (больше сыра), будет снижена. Мы не уверены, что сможем его съесть.
Перерасчет награды, мы делаем таким способом:
Мы определяем ставку дисконтирования gamma. Она должна быть в пределах от 0 до 1.
- Чем больше гамма, тем меньше скидка. Это означает, что в приоритете долгосрочные вознаграждения.
- С другой стороны, чем меньше гамма, тем больше скидка. Это означает, что в приоритете краткосрочные вознаграждения
Ожидаемые вознаграждения можно рассчитать по формуле:
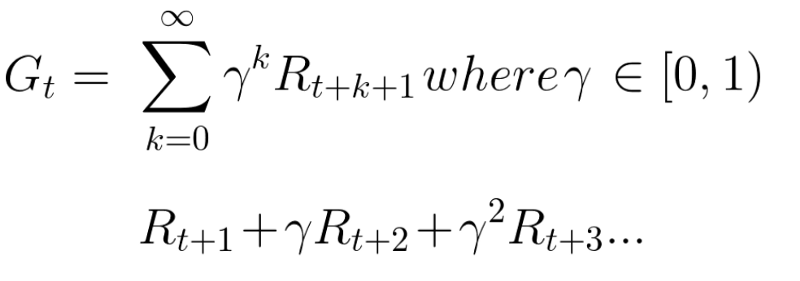
Другими словами, каждая награда будет уценена с помощью gamma к показателю времени (t). По мере того, как шаг времени увеличивается, кошка становится ближе к нам, поэтому будущее вознаграждение все менее и менее вероятно.
Эпизодические или непрерывные задачи
У нас может быть два типа задач: эпизодические и непрерывные.
Эпизодические задачи
В этом случае у нас есть начальная и конечная точка. Это создает эпизод: список состояний, действий, наград и будущих состояний.
Например в Super Mario Bros, эпизод начинается с запуска нового Марио и заканчивается, когда вы убиты или достигли конца уровня.
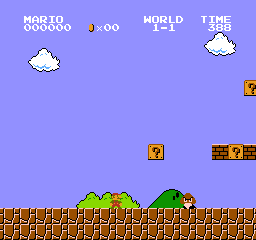
Непрерывные задачи
Это задачи, которые продолжаются вечно. В этом случае система должна научиться выбирать оптимальные действия и одновременно взаимодействовать со средой.
Как пример можно привести систему, которая автоматически торгует акциями. Для этой задачи нет начальной точки и состояния терминала. Что касается нашей задачи, то герой будет бежать, пока мы не решим остановить его.
Борьба методов: Монте-Карло против Временной разницы
Существует два основных метода обучения:
- Монте-Карло: Сбор наград в конце эпизода, а затем расчет максимального ожидаемого будущего вознаграждения.
- Временная разница: Оценка награды на каждом этапе.
Монте-Карло
Когда эпизод заканчивается, система смотрит на накопленное вознаграждение, чтобы понять насколько хорошо он выполнил свою задачу. В методе Монте-Карло награды получают только в конце игры.
Затем, мы начинаем новую игру с новыми знаниями. С каждым разом система проходит этот уровень все лучше и лучше.
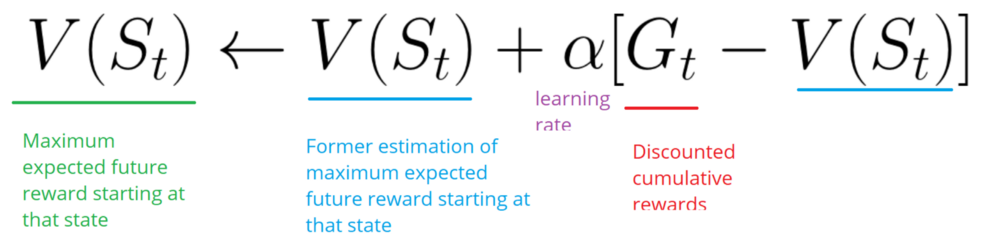
Возьмем эту картинку как пример:
- Каждый раз мы будем начинать с одного и того же места.
- Мы проиграем, если кошка съедает нас или если мы сделаем более 20 шагов.
- В конце эпизода у нас есть список состояний, действий, наград и новых состояний.
- Система будет суммировать общее вознаграждение Gt.
- Затем она обновит V (st), основываясь на приведенной выше формулы.
- Затем начнет игру заново, но уже с новыми знаниями.
Временная разница: обучение на каждом временном шаге
Этот метод не будет ждать конца эпизода, чтобы обновить максимально возможное вознаграждение. Он будет обновлять V в зависимости от полученного опыта.
Метод вызывает TD (0) или One step TD (обновление функции value после любого отдельного шага).

Он будет только ждать следующего временного шага, чтобы обновить значения. В момент времени t+1 обновляются все значения, а именно вознаграждение меняется на Rt+1, а текущую оценка на V(St+1).
Разведка или эксплуатация?
Прежде чем рассматривать различные стратегии решения проблем обучения с подкреплением, мы должны охватить еще одну очень важную тему: компромисс между разведкой и эксплуатацией.
- Исследование – это поиск дополнительной информации об окружающей среде.
- Эксплуатация – это использование известной информации для получения максимального вознаграждения.
Помните, что цель нашей системы заключается в максимизации ожидаемого совокупного вознаграждения. Однако мы можем попасть в ловушку.
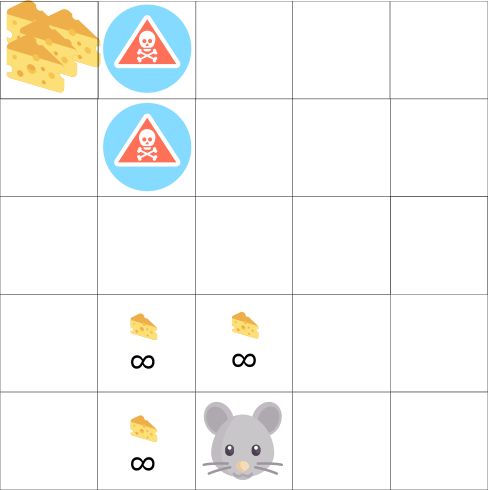
В этой игре, наша мышь может иметь бесконечное количество маленьких кусков сыра (+1). Однако на вершине лабиринта есть гигантский кусок сыра (+1000).
Но, если мы сосредоточимся только на вознаграждении, наша система никогда не достигнет того самого большого куска сыра. Вместо этого она будет использовать только ближайший источник вознаграждений, даже если этот источник мал (эксплуатация).
Но если наша система проведет небольшое исследование, она найдет большую награду.
Это то, что мы называем компромиссом между разведкой и эксплуатацией. Мы должны определить правило, которое поможет справиться с этим компромиссом.
Три подхода к обучению с подкреплением
Теперь, когда мы определили основные элементы обучения с подкреплением, давайте перейдем к трем подходам для решения проблем, связанных с этим обучением.
На основе значений
В обучении с подкреплением на основе значений целью является оптимизация функции V(s).
Функция value – это функция, которая сообщает нам максимальное ожидаемое вознаграждение, которое получит система.
Значение каждой позиции – это общая сумма вознаграждения, которую система может накопить в будущем, начиная с этой позиции.
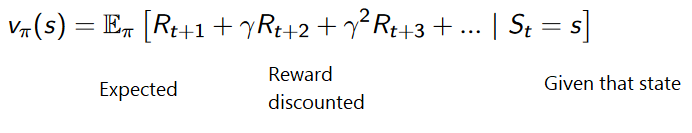
Система будет использовать эту функцию значений для выбора состояния на каждом шаге. Она принимает состояние с наибольшим значением.

В примере лабиринта, на каждом шаге мы будем принимать наибольшее значение: -7, затем -6, затем -5 (и так далее), чтобы достичь цели.
На основе политики
В обучении с подкреплением на основе политики мы хотим напрямую оптимизировать функцию политики π (s) без использования функции значения.
Политика – это то, что определяет поведение системы в данный момент времени.
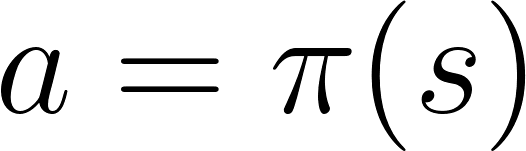
Это позволяет нам сопоставить каждую позицию с наилучшим действием.
Существует два типа политики:
- Детерминированный: будет возвращать одно и то же действие.
- Стохастический: выводит вероятность распределения по действиям.
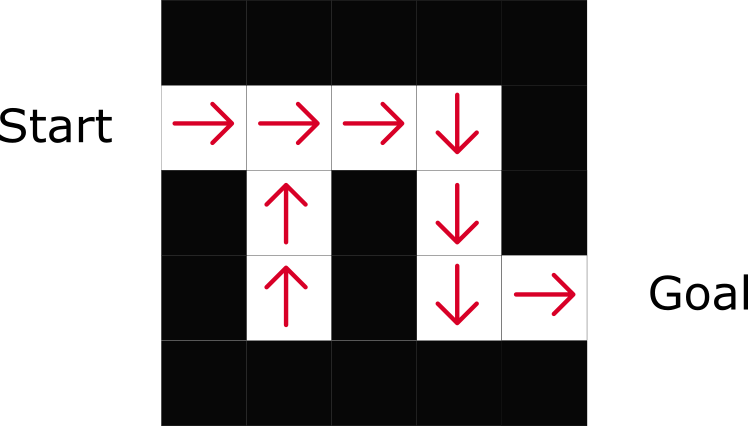
Как можно заметить, политика прямо указывает на лучшие действия для каждого шага.

На основе модели
В подходе на основании модели мы моделируем среду. Это означает, что мы создаем модель поведения среды.
Проблема каждой среды заключается в том, что понадобятся различные представления данной модели. Вот почему мы особо не будем раскрывать эту тему.
В этой статье было довольно много информации. Убедитесь, что действительно поняли весь материал, прежде чем продолжить изучение. Важно освоить эти элементы перед тем как начать самую интересную часть: создание ИИ, который играет в видеоигры.
Другие материалы по теме:
-
- Трейдинг и машинное обучение с подкреплением
- 11 must-have алгоритмов машинного обучения для Data Scientist
Комментарии