

Статья публикуется в переводе, автор оригинального текста Chris Lovejoy.
Создаем собственный алгоритм YouTube (чтобы не тратить время зря)
Я люблю смотреть на YouTube видео, которые существенно улучшают мою жизнь. К сожалению, алгоритм YouTube на это не согласен: он обожает подсовывать мне "ловушки кликов" и прочий мусор.
Здесь нет ничего удивительного – алгоритм ставит на первое место количество кликов и время просмотров.
Поэтому я поставил перед собой задачу: смогу ли я написать код, который автоматически найдет полезные видео, покончив с зависимостью от алгоритма YouTube?
И вот чего я добился.
Самый лучший план
Я начал с попытки представить, что бы мне хотелось получить от собственного инструмента. Я хотел, чтобы он:
- Ранжировал видео по ожидаемой привлекательности для меня и
- Автоматически присылал мне избранные видео, из которых я мог бы выбирать.
Я обнаружил, что мог бы сэкономить кучу времени, если бы я мог выбрать набор видео, которые я собираюсь посмотреть на следующей неделе и избавиться от бесконечной прокрутки видео, предлагаемых YouTube.

Я знал, что мне потребуется YouTube API для получения информации о видео. Затем я создал бы процедуру, обрабатывающую эту информацию для ранжирования видео. В качестве последнего шага я планировал установить автоматическую рассылку списков самых лучших видео самому себе с помощью AWS Lambda.
Однако все закончилось не совсем так, как ожидалось. (Если вы хотите пропустить историю и сразу увидеть финальный код, вам сюда).
Путешествие по YouTube API
Я хотел найти метрики, которые можно было бы использовать для ранжирования видео в терминах их привлекательности для меня.
Я изучил документацию YouTube и узнал, что можно получить информацию на уровне видео (название, дата публикации, количество просмотров, уменьшенное изображение и т.д.) и на уровне канала (количество подписчиков, комментариев, просмотров, плейлисты канала и пр.)
Увидев все это, я получил уверенность, что смогу применить эту информацию для определения метрик и ранжирования видео.
Я получил код API через консоль разработчика и скопировал его в свой скрипт Python. Это позволяет инициализировать вызов API и получать результаты следующими строками кода:
api_key = 'AIzpSyAq3L9DiPK0KxrGBbdY7wNN7kfPbm_hsPg' # Введите свой ключ API вместо этого
youtube_api = build('youtube', 'v3', developerKey = api_key)
results = youtube_api.search().list(q=search_terms, part='snippet', type='video',
order='viewCount', maxResults=50).execute()
Эта функция возвращает объект JSON, который можно разобрать, чтобы найти желаемую информацию. Например, для нахождения даты публикации я могу обратиться к results следующим образом:
publishedAt = results['items'][0]['snippet']['publishedAt']
Здесь можно найти полезную серию видео, демонстрирующих весь процесс использования YouTube API.
Находим полезные видео: определение формулы
Теперь, когда я могу извлечь необходимую информацию, мне нужно было использовать эту информацию для ранжирования видео в смысле их интересности для меня.
Это был сложный вопрос. Что делает видео хорошим? Количество просмотров? Количество комментариев? Количество подписчиков канала?
Я решил начать с общего количества просмотров, как разумного первого приближения "уровня ценности" видео. В теории, интересные и хорошо поданные видео получат положительную реакцию зрителей, привлекут больше зрителей и получат большее количество просмотров.
Однако, есть несколько моментов, которые общее количество просмотров не учитывает:
Во-первых, если канал был создан для большой аудитории, размещенным там видео будет намного проще набрать такое же количество просмотров, чем меньшему каналу. Иногда это может отражать больший опыт, приводящий к лучшим видео, но я не хотел сбрасывать со счетов и потенциально высококачественные видео от меньших каналов. Видео со 100.000 просмотров на канале с 10.000 подписчиков, вероятно, лучше видео с таким же количеством просмотров на канале с миллионом подписчиков.
Во-вторых, видео может получить множество просмотров по неверным причинам, таким, как заголовки для привлечения кликов, продвижение с помощью мини-видео, или видео вызывает споры. Лично я мало заинтересован в видео такого типа.
Мне нужно было встроить другие метрики. Следующей метрикой было количество подписчиков.
Я протестировал ранжирование, основанное исключительно на отношении просмотров к подписчикам (т.е. делим количество просмотров на количество подписчиков).
# Функция для подсчета количества просмотров по отношению к подписчикам
def view_to_sub_ratio(viewcount, num_subscribers):
if num_subscribers == 0:
return 0
else:
ratio = viewcount / num_subscribers
return ratio
Когда я посмотрел на результаты, некоторые из них выглядели многообещающими. Однако я заметил проблему: для видео с очень низким количеством подписчиков оценка получалась чрезвычайно завышенной, и выводила видео в топ.
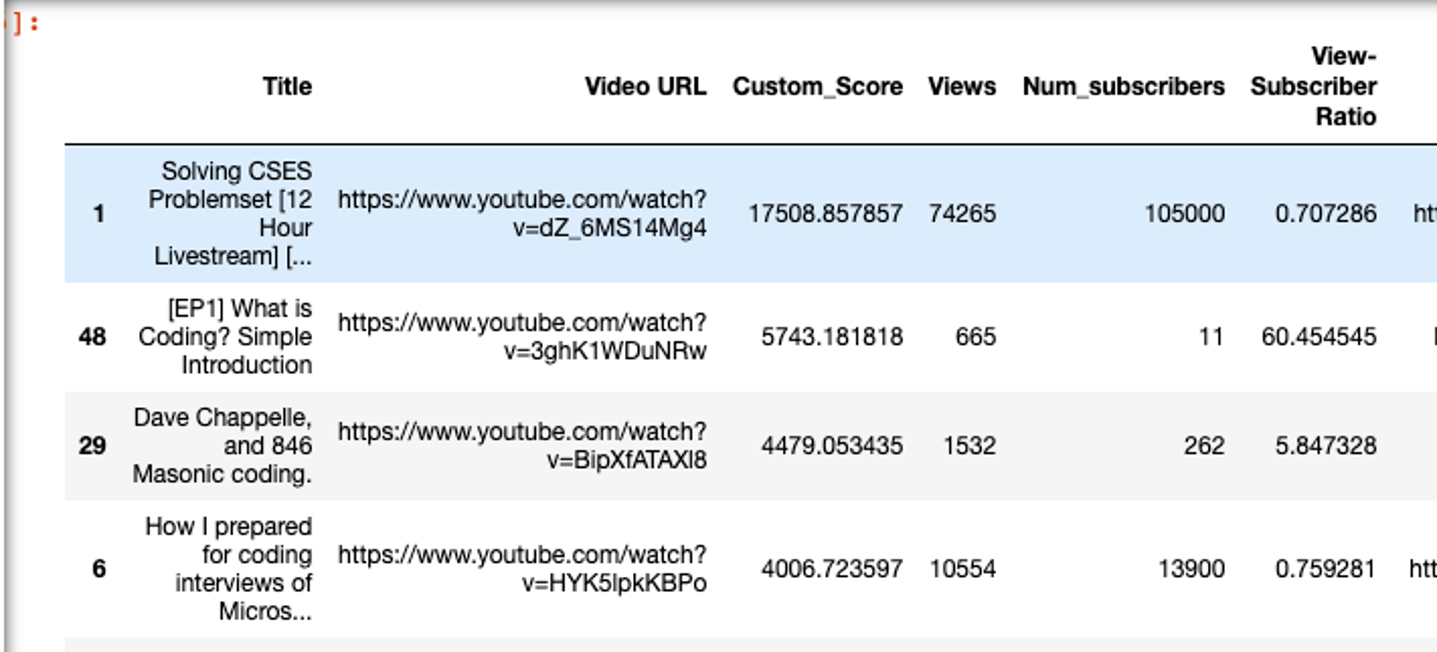
Я предпринял кое-какие попытки устранить подобные крайние случаи:
- Установил минимальное количество просмотров в 5000.
- Установил максимальное значение соотношения количества просмотров к количеству подписчиков в 5.
# Убираем крайние случаи (низкое количество просмотров или подписчиков
def custom_score(viewcount, ratio, days_since_published):
ratio = min(ratio, 5)
score = (viewcount * ratio)
return score
Я попробовал различные пороги, и похоже, что эти значения довольно хорошо фильтруют видео с низким количеством просмотров или подписчиков. Я протестировал этот код на нескольких различных темах, и начал получать довольно приличные результаты.
Однако я заметил другую проблему: видео, опубликованные достаточно давно, имели больше шансов получить значительное количество просмотров. У них просто было больше времени для сбора просмотров.
Я планировал запускать этот код раз в неделю, так что я решил ограничить поиск видео теми, которые были опубликованы за последние 7 дней:
def get_start_date_string(search_period_days):
"""Returns string for date at start of search period."""
search_start_date = datetime.today() - timedelta(search_period_days)
date_string = datetime(year=search_start_date.year,month=search_start_date.month,
day=search_start_date.day).strftime('%Y-%m-%dT%H:%M:%SZ')
return date_string
date_string = vf.get_start_date_string(7)
results = youtube_api.search().list(q=search_terms, part='snippet',
type='video', order='viewCount', maxResults=50,
publishedAfter=date_string).execute()
Я также добавил "количество дней с момента публикации" в метрику ранжирования. Я решил разделить предыдущую метрику на это количество дней, чтобы итоговый результат не зависел от того, как долго видео было опубликовано.
def custom_score(viewcount, ratio, days_since_published):
ratio = min(ratio, 5)
score = (viewcount * ratio) / days_since_published
return score
Я снова протестировал свой код, и обнаружил, что постоянно обнаруживаю отличные видео, которые я хотел посмотреть. Я поиграл с разными вариациями и пробовал назначать разные веса различным компонентам своей формулы, но обнаружил, что это не точная наука, так что в конце концов я остановился на следующей формуле, в которой простота сочеталась с эффективностью:
Тестирование моего нового инструмента
Сначала я протестировал его с запросом термина "medical school" и получил следующие результаты:

Затем я пошел на YouTube и вручную поискал там видео, относящиеся к медицине и обучению медицине. Оказалось, что мой инструмент захватил все видео, которые мне было бы интересно посмотреть. Особенно мне понравилось второе видео, от доктора Кевина Джаббала.
Я протестировал с другим условием поиска, "productivity", и результаты снова меня порадовали.

Второе видео оказалось слегка неожиданным – оно совсем не из тех видео, которые я искал. Но я не смог придумать простого способа отфильтровать такие видео, выбранные по другим значениям слов, заданных для поиска.
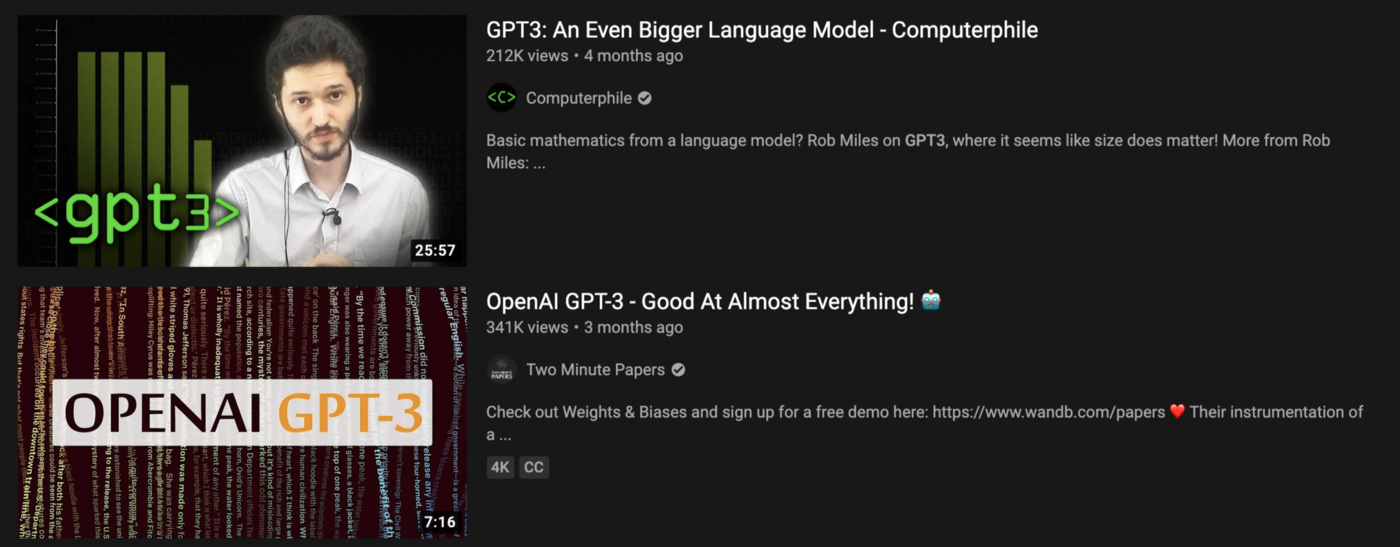
Несколько месяцев назад OpenAI выложила действительно интересную новую нейронную сеть, называемую "GPT-3". Я решил протестировать мой поисковик видео, передав в качестве критерия поиска "GPT-3", и нашел вот это видео:
Это интересное видео от создателя, имеющего всего несколько тысяч подписчиков
Если бы я выполнил такой же поиск на YouTube, мне пришлось бы прокрутить все видео от крупных каналов, прежде чем я нашел бы это видео на 31-м месте.
С помощью кода Video Finder, который я написал, намного проще находить эти интересные видео, содержащие новые перспективы.
За последние несколько месяцев я перепробовал множество условий поиска видео, основанных на моих интересах – например, 'artificial intelligence', 'medical AI' и 'Python programming'. Практически всегда в первой пятерке предложений Video Finder'а было хотя бы одно интересное видео.
Запускаем рабочий процесс
Я причесал весь свой код и выложил его на GitHub.
На высоком уровне, теперь мой код работал примерно так:
- Используем условия поиска, период поиска и ключ API для получения информации о видео с YouTube.
- Рассчитываем "метрику интересности" для видео.
- Используем "функцию ценности" для ранжирования этих видео по предполагаемой интересности.
- Сохраняем интересующую нас информацию в DataFrame.
- Печатаем информацию (включая ссылки) о 5 лучших видео в консоль.
Я хотел найти способ запускать этот скрипт автоматически, и решил использовать AWS Lambda (платформу без сервера). Lambda позволяет писать код, который не выполняется, пока не сработает триггер (например, раз в неделю, или при происхождении какого-либо события).
Идеальный рабочий процесс заключался в том, чтобы автоматически присылать самому себе список видео каждую неделю с помощью Lambda. При этом я мог бы выбирать видео, которые хотел бы посмотреть на следующей неделе, и мне больше никогда не приходилось бы заходить на главную страницу YouTube.
Однако этот план не сработал.
Это была моя первая попытка использовать Lambda, и как я ни старался, я не смог заставить все импортированные библиотеки работать одновременно. Чтобы выполняться, коду требовался почтовый клиент boto3, OAuth для вызова API, Pandas для хранения результатов, и множество модулей, от которых они зависят. Обычно установка этих пакетов довольно проста, но на Lambda возникли дополнительные сложности. Во-первых, там есть лимиты на загрузку файлов, так что мне пришлось упаковать библиотеки, а потом распаковать их после загрузки. Во-вторых, AWS Lambda использует собственную версию Linux, которая затруднила использование правильных библиотек с кросс-платформной совместимостью. В-третьих, мой Mac вел себя странно с ее виртуальными окружениями.
Потратив около 10-15 часов на поиск советов на StackOverflow, загрузку и повторную загрузку различных codebase и совещания с несколькими друзьями, я так и не смог заставить все это заработать. Так что, в конце концов я решил сдаться (если у вас есть какие-нибудь хорошие идеи, сообщите мне!)
Вместо этого, я реализовал план Б: запускать скрипт вручную на своем локальном компьютере раз в неделю (после автоматического напоминания через email). Честно говоря, это не конец света.
Итоговые мысли
В целом, это был действительно забавный проект. Я научился использовать YouTube API, познакомился с AWS Lambda и создал инструмент, который могу использовать в дальнейшем.
Использование своего кода для принятия решений, какие видео смотреть, повысило мою продуктивность, по крайней мере, пока я способен отказываться от переходов по ссылкам вроде "смотри также". Возможно, я и пропущу какие-нибудь интересные видео, но я и не пытался "поймать" все видео, заслуживающие просмотра (и не думаю, что это вообще возможно). Вместо этого я хотел поднять планку качества тех видео, которые я действительно смотрю.
Этот проект – лишь одна из множества моих идей, относящихся к автоматизации обработки информации. Я верю, что в этой области есть огромный потенциал для повышения нашей продуктивности и высвобождения нашего времени посредством разумного цифрового минимализма.
Если вы хотите присоединиться к моему путешествию, вы можете добавиться в мой почтовый список и на мой канал YouTube.
Возможные дальнейшие шаги
В целом, проект еще достаточно сырой, и здесь многое можно сделать:
- Метрика для ранжирования видео довольно груба, и я мог бы ее улучшить. Естественным следующим шагом было бы встроить соотношение лайков и дизлайков.
- При задании условий поиска также много условностей. Если строка поиска не содержится в названии видео или его описании, видео не будет выбрано. Я мог бы исследовать способы обойти эту проблему.
- Я мог также создать интерфейс, позволяющий пользователю просто вводить условия поиска и период поиска. Это сделало бы инструмент более доступным, а также позволило бы пользователям смотреть видео, не заходя на youtube.com.
- В настоящее время код работает довольно медленно. Я не приложил особых усилий к его оптимизации и ускорению, учитывая, что я собирался запускать этот код всего раз в неделю. Но есть несколько очевидных мест, где можно было бы повысить эффективность.
Полезные ссылки
Похожие проекты:
YouTube API:
- Официальная документация.
- Пример кода API.
- Серия видео про использование YouTube API (Indian Pythonista).
- Другая серия видео про использование YouTube API (Corey Schafer).
AWS Lambda:
Комментарии