
Львиная доля мировой информации хранится в реляционных базах данных. Чтобы работать с ней, нужно владеть языком SQL-запросов.

Для решения многих стандартных задач не требуется быть SQL-виртуозом, достаточно изучить азы работы с базами:
- создание и редактирование таблиц;
- сохранение и обновление записей;
- выборка и фильтрация данных;
- индексирование полей.
Этими азами мы и займемся: разберем синтаксис SQL-запросов в теории и на реальных примерах. К счастью, язык баз данных очень похож на простые английские предложения, так что вы легко с ним справитесь.
Чтобы учиться эффективнее, сразу же закрепляйте новые знания практикой. Поиграть с SQL можно на этом замечательном ресурсе. В левой панели вы должны ввести весь код, относящийся к структуре базы данных. После этого начинайте экспериментировать с SELECT'ами в правом поле.
* В примерах используется SQL-синтаксис для MySQL 5.6. Запросы, предназначенные для разных СУБД, могут различаться.
Терминология
База данных состоит из таблиц, а таблица – из колонок и строк.
Каждая колонка, или поле таблицы, представляет собой конкретный вид информации, например, имя студента (строка) или зарплата сотрудника (число).
Каждая строка, или запись таблицы, – это описание конкретного объекта, например, студента или сотрудника.
Уровень: Новичок
Создание и редактирование таблиц
CREATE
Несложно догадаться, что оператор CREATE создает новую таблицу в базе. Ему нужно передать описания всех полей таблицы в формате:
название_поля тип_данных [атрибуты_поля]
Создадим таблицу с данными о собаках и их рационе питания:
# создать таблицу dogs с 5 полями разных типов CREATE TABLE rations ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, weight INT DEFAULT 0, color VARCHAR(20), portion INT );
ALTER
Не всегда получается создать идеальную таблицу с первого раза. Не бойтесь вносить изменения, добавлять, удалять или изменять существующие поля:
# переименовать таблицу rations в portions ALTER TABLE rations RENAME TO portions; # добавить в таблицу portions числовое поле age ALTER TABLE portions ADD age INT; # удалить из таблицы portions поле color ALTER TABLE portions DROP COLUMN color; # переименовать поле name в dog_name ALTER TABLE portions CHANGE name dog_name VARCHAR(20) NOT NULL;
DROP и TRUNCATE
Оператор DROP удаляет таблицу из базы целиком:
# удалить таблицу portions DROP TABLE portions;
Если вам нужно удалить только записи, сохранив саму таблицу, воспользуйтесь оператором TRUNCATE:
# очистить таблицу portions TRUNCATE TABLE portions;
Атрибуты и ограничения
Можно ограничить диапазон данных, которые попадают в поле, например, запретить устанавливать в качестве возраста или веса отрицательные числа.
Самые распространенные в SQL ограничения целостности (CONSTRAINTS):
- DEFAULT – устанавливает значение по умолчанию;
- AUTO_INCREMENT – автоматически инкрементирует значение поля для каждой следующей записи;
- NOT NULL – запрещает создавать запись с пустым значением поля;
- UNIQUE – следит, чтобы поле или комбинация полей оставались уникальны в пределах таблицы;
- PRIMARY KEY – UNIQUE + NOT NULL. Первичный ключ должен однозначно идентифицировать запись таблицы, поэтому он должен быть уникальным и не может оставаться пустым;
- CHECK – проверяет значение поля на соответствие некоторому условию.
Ограничения можно добавлять при создании таблицы, а затем при необходимости добавлять/изменять/удалять. Они могут действовать на одно поле или комбинацию полей.
Первичный ключ, автоматический инкремент, NOT NULL и значение по умолчанию мы уже использовали в примере с собаками.
Решим новую задачу – составление списка президентов:
# уникальная комбинация страна + имя президента CREATE TABLE presidents ( country VARCHAR(20), name VARCHAR(50), age INT CHECK(age > 50), UNIQUE(country, name) );
Ограничение уникальности не позволит занести в таблицу одного и того же президента одной страны дважды. Кроме того, не попадут в список и слишком молодые политики.
Для добавления и удаления ограничений к существующим таблицам используйте оператор ALTER. Ограничениям можно давать имя, чтобы ссылаться на них впоследствии. Для этого предназначена конструкция CONSTRAINT.
CREATE TABLE presidents ( country VARCHAR(20), name VARCHAR(50), age INT ); # добавить именованное ограничение уникальности ALTER TABLE presidents ADD CONSTRAINT unique_president UNIQUE(country, name); # удалить именованное ограничение ALTER TABLE presidents DROP INDEX unique_president; # добавить неименованное ограничение уникальности ALTER TABLE presidents ADD UNIQUE(country, name); # добавить проверку значения ALTER TABLE presidents ADD CHECK (age > 50);
Еще одно удобное ограничение в SQL – внешний ключ (FOREIGN KEY). Он позволяет связать поля двух разных таблиц.
Для примера возьмем базу данных организации с таблицами сотрудников и отделов:
CREATE TABLE departments ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) ); # в поле departament будет храниться id одного из отделов, # перечисленных в таблице departments CREATE TABLE employees ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department INT, salary INT, FOREIGN KEY (department) REFERENCES departments(id) );
Теперь в поле department таблицы employees нельзя будет указать произвольный отдел. Он обязательно должен содержаться в таблице departments.
Сохранение и обновление записей
INSERT
Добавить в таблицу новую запись (или даже сразу несколько) очень просто:
INSERT INTO portions (dog_name, weight, portion) VALUES ("Jack", 25, 250);
INSERT INTO portions (dog_name, weight, portion)
VALUES ("Max", 15, 180), ("Charlie", 37, 350);
Вы даже можете скопировать записи из одной таблицы и вставить их в другую одним запросом. Для этого нужно скомбинировать операторы INSERT и SELECT:
CREATE TABLE dogs( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, weight INT DEFAULT 0 ); INSERT INTO dogs (name, weight) SELECT dog_name, weight FROM portions;
UPDATE
Оператор UPDATE используется для изменения существующих записей таблицы.
UPDATE employees SET salary = 0;
Вот так легким движением руки мы обнулили зарплату сразу у всех сотрудников.
Запрос можно уточнить, добавив секцию WHERE с условием отбора записей.
UPDATE employees SET salary = 0 WHERE name = "Ivan Ivanov";
С условиями мы подробно разберемся чуть позже, когда будем говорить о выборке данных из базы.
DELETE
Можно удалить из таблицы все записи сразу или только те, которые соответствуют некоторому условию:
DELETE FROM employees; # Ивана Иванова пора увольнять DELETE FROM employees WHERE name = "Ivan Ivanov";

Уровень: уверенный пользователь
Выборка и фильтрация данных
Для получения данных из базы служит оператор SELECT. В SQL есть множество способов отфильтровать именно те данные, которые вам нужны, а также отсортировать их и разбить по группам.
Вот небольшая демо-база, на которой вы можете попрактиковаться:
CREATE TABLE departments (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20)
);
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department INT,
salary INT,
boss INT
);
INSERT INTO departments (name)
VALUES ("administration"), ("accounting"),
("customer service"), ("finance"),
("legal"), ("logistics"),
("orders"), ("purchasing");
INSERT INTO employees (name, department, salary, boss)
VALUES ("John Doe", 1, 40000), ("Jane Smith", 1, 35000, 1),
("Fred Brown", 1, 48000, 1), ("Kevin Jones", 2, 36000),
("Josh Taylor", 2, 22000, 4), ("Alex Clark", 2, 29000, 5),
("Branda Evans", 2, 27000, 5), ("Anthony Ford", 4, 32000),
("David Moore", 4, 29000, 8), ("Scott Riley", 5, 20000),
("Chris Gilmore", 5, 28000, 10), ("Roberta Newman", 5, 33000, 11),
("Kenny Washington", NULL, 55000);
SELECT
# получить все поля из всех записей SELECT * FROM employees; # получить только имена и зарплаты всех работников SELECT name, salary FROM employees;
Можно переименовывать поля для вывода:
SELECT name as employee FROM employees;
Добавление условий:
# имена работников, зарплата которых выше 20 тысяч SELECT name FROM employees WHERE salary > 20000; # все сотрудники с запрлатой от 25 до 30 тысяч SELECT name FROM employees WHERE salary BETWEEN 25000 AND 30000; # все Джоны среди работников SELECT * FROM employees WHERE name LIKE "john%" # все сотрудники, кроме Джонов и Джонсов SELECT * FROM employees WHERE name NOT LIKE "john%" AND name NOT LIKE "%jones" # все сотрудники юридического отдела, администрации и бухгалтерии SELECT * FROM employees WHERE department IN [1, 2, 5] # все сотрудники, у которых нет начальников SELECT * FROM employees WHERE boss IS NULL
Сортировка:
# по уменьшению зарплаты SELECT name, salary FROM employees ORDER BY salary ASC; # по увеличению зарплаты SELECT name, salary FROM employees ORDER BY salary DESC;
Ограничение количества результатов:
# пять самых высокооплачиваемых работника SELECT name FROM employees ORDER BY salary DESC LIMIT 5; # все работники кроме пяти самых высокооплачиваемых SELECT name FROM employees ORDER BY salary DESC OFFSET 5;
Агрегатные функции и группировка
SQL позволяет привести несколько записей таблицы к некоторому единому значению:
# общее количество работников SELECT COUNT(*) FROM employees; # найти работника с максимальной зарплатой SELECT name, MAX(salary) FROM employees; # найти работника с минимальной зарплатой SELECT name, MIN(salary) FROM employees; # найти среднюю зарплату по предприятию SELECT AVG(salary) FROM employees; # найти сумму всех зарплат SELECT SUM(salary) FROM employees;
Агрегатные функции могут работать со всеми записями таблицы разом, а могут и с отдельными группами. Чтобы эти группы сформировать, используйте оператор GROUP BY:
# найти максимальную зарплату в каждом отделе SELECT department, MAX(salary) FROM employees GROUP BY department;
Полученные группы тоже можно отфильтровывать: для этого предназначена конструкция HAVING. Например, не будем учитывать в выборке отделы, в которых работает меньше трех человек:
SELECT department, MAX(salary) FROM employees GROUP BY department HAVING COUNT(*) > 3;
Объединение таблиц
Очень часто нужная вам информация хранится в разных таблицах – это обусловлено законами нормализации. Поэтому важно уметь объединять их.
В запросе, захватывающем несколько таблиц, нужно указать следующее:
- все интересующие вас поля, которые могут принадлежать разным таблицам;
- тип соединения;
- правило, по которому поля одной таблицы будут поставлены в соответствие полям другой таблицы.
Соединение бывает внутреннее (INNER) и внешнее (OUTER).
Внутреннее соединение
При внутреннем соединении вы получите в результате только те записи, для которых нашлось соответствие во всех таблицах.
SELECT employees.name, employees.salary, departments.name as department FROM employees INNER JOIN departments ON employees.department = departments.id;
SQL просмотрит каждую запись из таблицы employees и попытается поставить ей в соответствие каждую запись из таблицы departments. Если это удастся (id отделов совпадают), запись будет включена в результат, иначе – не будет.
Таким образом, вы не увидите Kenny Washington, у которого отдел не указан, а также все отделы, в которых нет сотрудников.
Если не указано условие для соединения таблиц, SQL создаст все возможные комбинации сотрудников и отделов.
Внешнее соединение
При внешнем соединении в результат попадают также записи без соответствий. При этом вы можете регулировать, из какой таблицы такие записи берутся, а из какой – нет.
Например, чтобы увидеть в результате Kenny Washington, потребуется левое внешнее соединение. Слово OUTER можно не указывать – соединение по умолчанию внешнее:
SELECT employees.name, employees.salary, departments.name as department FROM employees LEFT JOIN departments ON employees.department = departments.id;
Теперь в результате есть все данные из левой таблицы (employees), даже если для них нет соответствия.
Правое соединение соответственно проигнорирует Кенни, но выведет все пустые отделы:
SELECT employees.name, employees.salary, employees.department, departments.name FROM employees RIGHT JOIN departments ON employees.department = departments.id;
И наконец, полное внешнее соединение выведет и соответствия, и пустые отделы, и сотрудников без отдела.
SELECT employees.name, employees.salary, employees.department, departments.name FROM employees FULL JOIN departments ON employees.department = departments.id;
Декартово произведение
Оператор CROSS JOIN позволяет получить все возможные комбинации записей из двух таблиц:
SELECT * FROM employees CROSS JOIN departments;
Автосоединение
Кроме того, таблицу можно соединять с самой собой. Это пригодится, чтобы найти босса для каждого сотрудника. Сейчас в поле boss находится идентификатор другого сотрудника, необходимо вывести его имя:
SELECT e1.name, e1.department, e2.name as boss FROM employees e1 LEFT JOIN employees e2 ON e1.boss = e2.id
Благодаря использованию левого соединения мы можем вывести также сотрудников, не имеющих руководителей.
Объединение выборок
SQL позволяет сделать две отдельные выборки, а затем объединить их результаты по определенному правилу:
UNION
Объединить штатных и внештатных сотрудников
// без дублей (или со всеми дублями) SELECT * FROM employees UNION [ALL] SELECT * FROM freelancers;
INTERSECT
Найти всех сотрудников, которые участвуют в сборной предприятия по спортивной ходьбе
SELECT name FROM employees INTERSECT SELECT name FROM race_walking_team
MINUS
Найти всех сотрудников, которые не участвуют в сборной предприятия по спортивной ходьбе и заставить участвовать:
SELECT name FROM employees MINUS SELECT name FROM race_walking_team

Уровень: SQL-мастер
Представления
Views, или представления, в SQL – это SELECT-запрос, который вы можете сохранить для дальнейшего использования. Один раз написали, а потом можете пользоваться полученной таблицей, которая – внимание! – всегда остается актуальной в отличие от результата обычных запросов.
У представлений есть еще одна важная миссия: обеспечение безопасности. Под view вы легко можете скрыть бизнес-логику и архитектуру базы и защитить свое приложение от нежелательных вторжений.
Представление может извлекать данные из одной или нескольких таблиц. Кроме того, при соблюдении ряда условий представление может быть изменяемым, то есть совершая операции над ним, можно изменять базовые таблицы.
// простое представление CREATE VIEW view(name, salary) AS SELECT name, salary FROM employees;
Если представление изменяемое, можно использовать при его создании CHECK OPTION для проверки изменений на соответствие некоторому предикату:
CREATE VIEW view(name, salary)
AS
SELECT name, salary
FROM employees WHERE salary > 30000
WITH CHECK OPTION;
// в такое представление не получится вставить следующую запись
INSERT INTO view (name, salary)
VALUES ("Jack Daniels", 25000);
Представления могут основываться как на таблицах базы, так и на других представлениях, образуя несколько уровней вложенности. С учетом этого предложение WITH можно расширить:
- WITH CASCADED CHECK OPTION – проверяет запросы на всех уровнях вложенности;
- WITH LOCAL CHECK OPTION – проверяет только "верхний" запрос.
CREATE VIEW view(name, salary)
AS
SELECT name, salary
FROM employees WHERE salary > 30000;
CREATE VIEW view2(name, salary)
AS
SELECT name, salary
FROM view WHERE salary > 10000
WITH LOCAL CHECK OPTION;
// строка будет вставлена в таблицу, но не будет видна в представлениях
INSERT INTO view2 (name, salary)
VALUES ("Jack Daniels", 15000);
Представление даже может ссылаться само на себя.
Чтобы удалить представление, используйте уже знакомый оператор DROP:
DROP VIEW view;
Индексы
Индексы – это специальный таблицы, которые позволяют ускорить поиск по базе данных. Их можно представить как алфавитный указатель в большой книге.
// создание индекса для двух полей CREATE INDEX index_name ON table(column1, column2);
Наличие индексов в базе ускоряет выполнение операций SELECT и вычисление условий WHERE. Но есть и обратная сторона медали: замедляются операции вставки и удаления данных, так как при этих изменениях необходимо пересчитывать индексы.
Триггеры
Триггеры в SQL – это процедуры, которые автоматически запускаются при выполнении определенной операции (INSERT/UPDATE/DELETE) – до (BEFORE) или после (AFTER) нее.
// создание триггера // бонус к зарплате каждому новому сотруднику DELIMITER $$ CREATE OR MODIFY TRIGGER bonuses BEFORE INSERT ON employees FOR EACH ROW BEGIN SET NEW.salary = NEW.salary+3000; END$$
Удалить существующий триггер можно с помощью оператора DROP:
DROP TRIGGER bonuses;
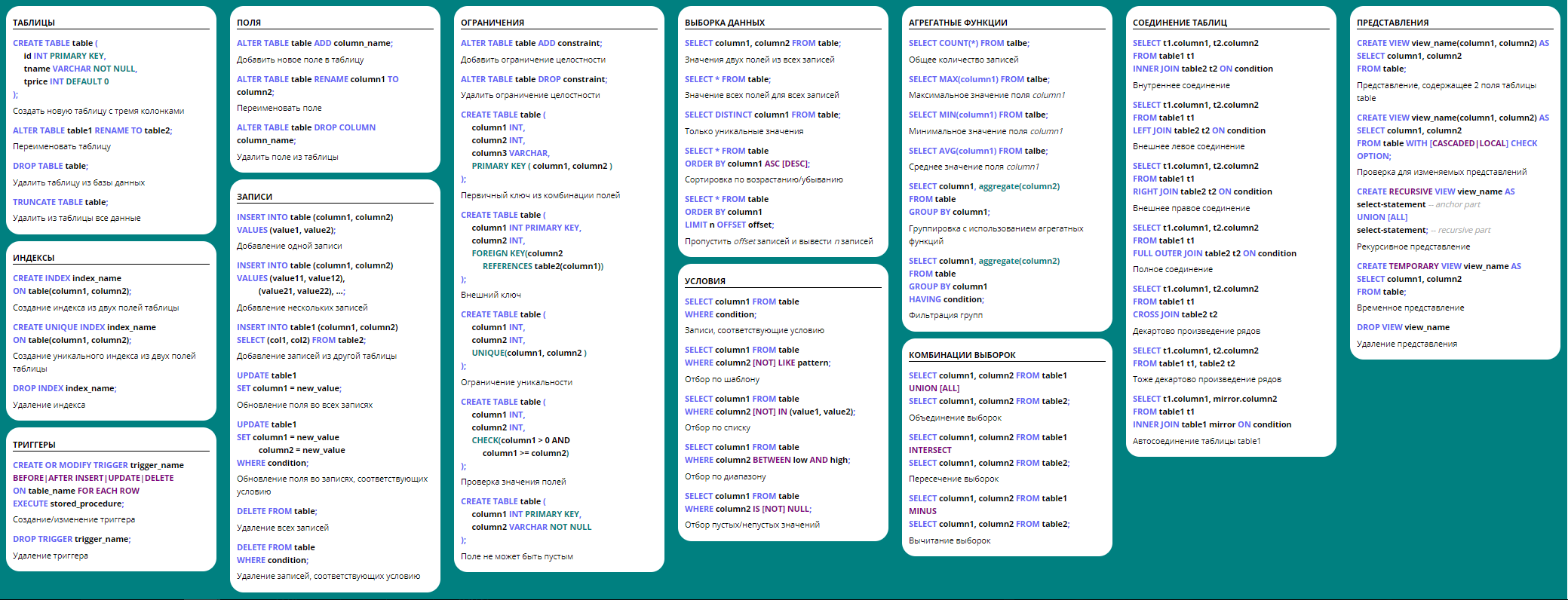
Удобные шпаргалки по SQL в pdf-формате.


Комментарии