
Вы пропустили лекцию и попросили тетрадку у однокурсника, чтобы наверстать материал. Но переписывать длинный конспект нет ни времени, ни желания – что же делать?
Понадобится приложение, распознающее текст в нетекстовых документах. К счастью, такая технология существует и называется OCR (Optical Character Recognition). Более того, она доступна даже на JavaScript!
Встречайте Tesseract.js – мощную библиотеку, умеющую распознавать символы на любом изображении. Сегодня мы разберёмся, как с ней работать.
1. Подключаем Tesseract.js
Tesseract.js – это обычная JavaScript-библиотека. Чтобы использовать её возможности в проекте, необходимо подключить нужный файл. Сделать это можно любым удобным способом, например, используя CDN (https://unpkg.com/tesseract.js@v2.0.0-alpha.13/dist/tesseract.min.js) или в виде npm-пакета:
// через npm
npm install tesseract.js
// через yarn
yarn add tesseract.js
2. Готовим разметку
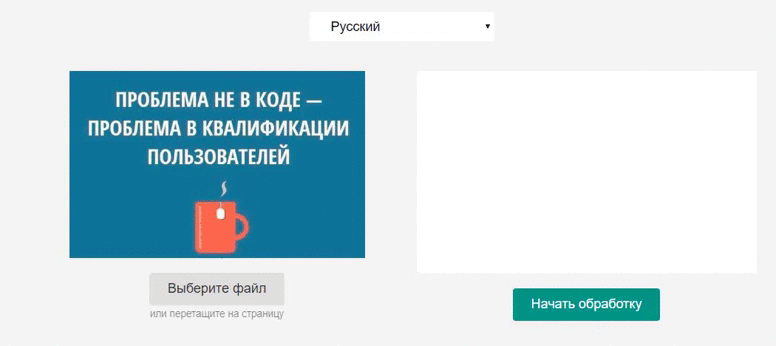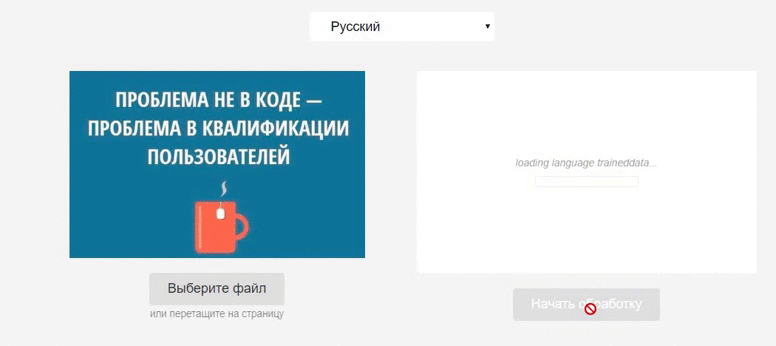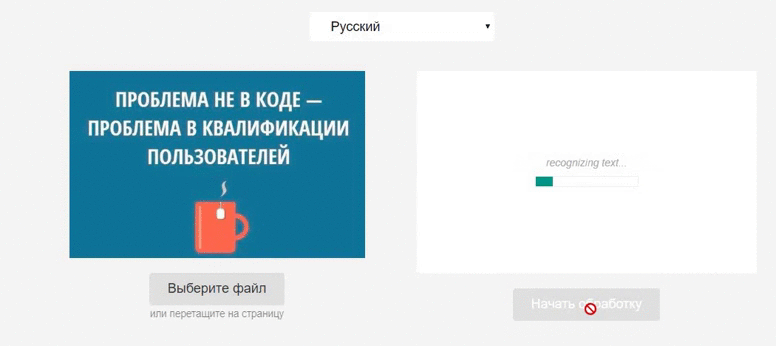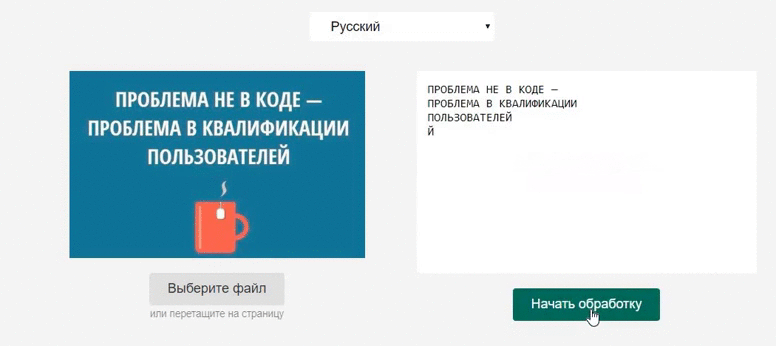
Согласно официальному сайту Tesseract.js поддерживает более 100 языков, в том числе и русский – для демонстрации возможностей добавим в приложение выбор языка. Ещё нам потребуется input для загрузки самого изображения и поле для вывода результатов обработки.
Простейшая разметка выглядит так:
3. Запускаем Tesseract
3.1. Воркер
Всю работу выполняет воркер TesseractWorker, поэтому импортируем из пакета tesseract.js функцию createWorker. При создании воркеру можно передать функцию логирования, вызываемую при переходе между этапами обработки.
import { createWorker } from 'tesseract.js';
const worker = createWorker({
logger: (data) => console.log(data)
});
Приходящий в логгер объект данных содержит два поля: status и progress – их можно использовать для отображения прогресса обработки.

Инициализируем воркер с нужными настройками языка и запускаем процесс распознавания:
async function recognize() {
const file = document.getElementById('file').files[0];
const lang = document.getElementById('langs').value;
await worker.load();
await worker.loadLanguage(lang);
await worker.initialize(lang);
const { data: { text } } = await worker.recognize(file);
console.log(text);
await worker.terminate();
return text;
}
3.2. Метод recognize
То же самое можно сделать более декларативно – с помощью метода recognize объекта Tesseract:
import Tesseract from 'tesseract.js';
function recognize() {
const file = document.getElementById('file').files[0];
const lang = document.getElementById('langs').value;
return Tesseract.recognize(file, lang, {
logger: data => console.log(data),
})
.then(({ data: {text }}) => {
console.log(text);
return text;
})
}
Этот метод принимает файл, язык и объект настроек с логгером. Метод работает асинхронно и возвращает обычный Promise.
4. Отображение прогресса и результата
В результате выполнения метода recognize мы получаем много полезных данных:

Тут не только извлечённый текст, но и уровень уверенности (confidence), и даже расположение на изображении символов, слов, абзацев.
Осталось продемонстрировать полученные результаты пользователю.
const log = document.getElementById('log');
// Отслеживание прогресса обработки
function updateProgress(status, progressValue) {
log.innerHTML = '';
const statusText = document.createTextNode(status);
const progress = document.createElement('progress');
progress.max = 1;
progress.value = progressValue;
log.appendChild(statusText);
log.appendChild(progress);
}
// Вывод результата
function setResult(text) {
log.innerHTML = '';
text = text.replace(/\n\s*\n/g, '\n');
const pre = document.createElement('pre');
pre.innerHTML = text;
log.appendChild(pre);
}
Наконец, добавим обработчик кликов на кнопку Начать обработку и соберём всё вместе:
import Tesseract from 'tesseract.js';
// Распознавание изображения
function recognize(file, lang, logger) {
return Tesseract.recognize(file, lang, {logger})
.then(({ data: {text }}) => {
return text;
})
}
const log = document.getElementById('log');
// Отслеживание прогресса обработки
function updateProgress(data) {
log.innerHTML = '';
const statusText = document.createTextNode(data.status);
const progress = document.createElement('progress');
progress.max = 1;
progress.value = data.progress;
log.appendChild(statusText);
log.appendChild(progress);
}
// Вывод результата
function setResult(text) {
log.innerHTML = '';
text = text.replace(/\n\s*\n/g, '\n');
const pre = document.createElement('pre');
pre.innerHTML = text;
log.appendChild(pre);
}
document.getElementById('start').addEventListener('click', () => {
const file = document.getElementById('file').files[0];
if (!file) return;
const lang = document.getElementById('langs').value;
recognize(file, lang, updateProgress)
.then(setResult);
});
Вот и вся программа! Поэкспериментируйте с разными изображениями и языками.
Наша демка сейчас обладает самым минимальным функционалом. Её можно существенно улучшить:
- Оформить элементы с помощью CSS.
- Добавить предпросмотр загруженного изображения.
- Установить изображение по умолчанию.
- Разрешить drag-n-drop-перетаскивание файлов.
Работающий демо-проект (с улучшениями) + его github-репозиторий.
Tesseract.js – отличная JS-библиотека для распознавания текста с изображений. Конечно, её возможности сильно ограничены. Зашумлённый фон и нестандартные шрифты существенно снижают точность обработки. Однако для множества проектов она может стать замечательным решением. В комментариях вы можете поделиться примерами того, как библиотека распознала (или не распознала) какой-либо текст – вместе мы сможем лучше понять ограничения библиотеки.
Комментарии