
Если вы пытались разобраться самостоятельно, что же такое машинное обучение, но безрезультатно, это руководство — для вас.
Поскольку цель этого руководства — быть понятным каждому, будьте готовы к куче обобщений. Если вам станут интересны нюансы и детали благодаря нашему изложению, мы будем рады тому, что наша миссия выполнена.
Что такое машинное обучение?
Машинное обучение состоит в том, что исходные алгоритмы могут сами рассказать кое-что интересное о предоставленных данных, и вам не придётся писать для этого отдельный код. Вместо написания кода вы скармливаете данные исходному алгоритму, и он сам выстраивает логику на основании этих данных.
Возьмём, к примеру, алгоритм классификации. Он может разбивать данные на различные группы. Такой же алгоритм классификации, который используется для распознавания рукописных символов, может быть полезен для разделения электронных сообщений по группам «спам» и «не спам». И для этого не нужно менять ни одну строчку кода. Алгоритм один и тот же, но его обучают разными данными, и поэтому он выстраивает разную логику классификации.
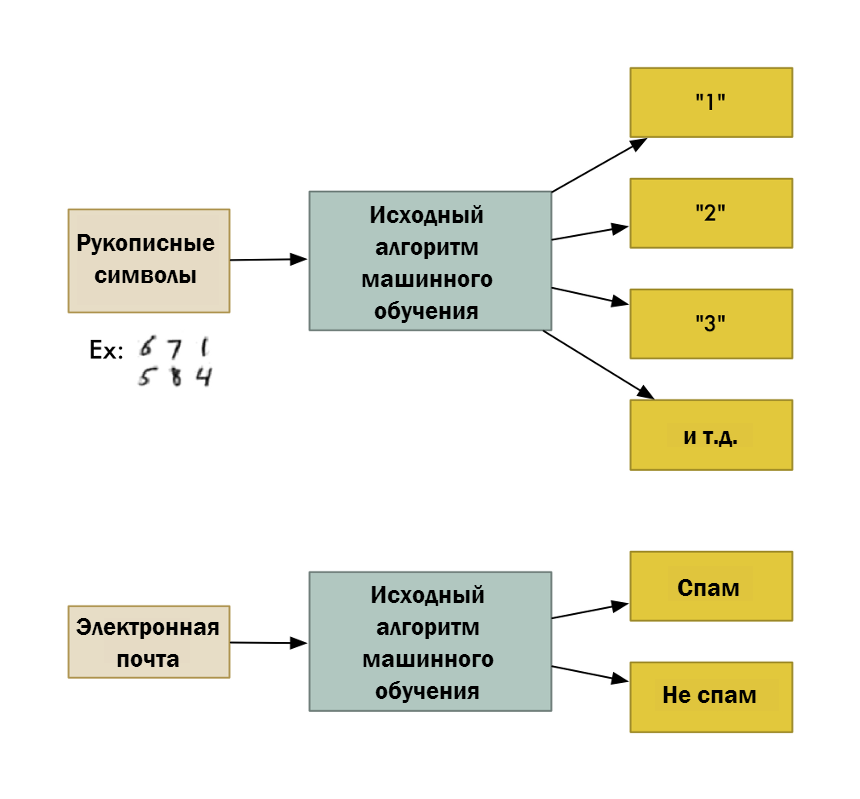
Машинное обучение — это универсальный термин, который относится к огромному количеству исходных алгоритмов.
Два вида алгоритмов машинного обучения
В широком смысле все алгоритмы машинного обучения можно разбить на две большие группы:
алгоритмы обучения с учителем и алгоритмы обучения без учителя.
Обучение с учителем
Представьте, что вы агент по недвижимости. Ваш бизнес растёт, и вы нанимаете себе в подмогу новых агентов-стажёров. Но вот беда: вы-то можете с одного взгляда определить стоимость недвижимости, а вашим стажёрам опыта не хватает.
Чтобы помочь стажёрам и обеспечить себе хоть немного отдыха, вы решаете написать небольшое приложение, которое оценивает стоимость квартиры в вашем городе на основе её площади, расположения и стоимости подобных проданных квартир.
В течение трёх месяцев вы записываете все подробности каждой выполненной сделки: количество комнат, площадь, район, цену продажи.

Так выглядят данные для нашего алгоритма
Используя эти данные, мы можем создать программу, которая спрогнозирует стоимость любой квартиры в вашем городе:

Это и называется обучением с учителем. Вы уже знаете, сколько стоила каждая проданная квартира; другими словами, вы знаете решение проблемы и вам остаётся только выстроить логику.
При создании приложения вы заносите полученные данные о каждой квартире в алгоритм машинного обучения. Задача алгоритма — выяснить, какое математическое действие нужно произвести над этими данными.
То, с чем работает алгоритм, выглядит как попытка восстановить информацию в этом примере:

Для того, чтобы восстановить логику приведённых выше вычислений, вам нужно произвести определённые действия в левой части уравнения, чтобы получить результат в правой части уравнения.
В алгоритме обучения с учителем это за вас делает компьютер. Если вы знаете, какие действия необходимы, чтобы решить конкретную задачу, алгоритм может решить все задачи такого типа.
Обучение без учителя
Вы снова тот самый предприимчивый агент по недвижимости. Что делать, если вы не знаете цену каждой квартиры? Хорошие новости: даже если вы знаете только площадь, количество комнат и расположение квартиры, вы уже можете совершить крутой анализ. Это и называется алгоритмом обучения без учителя.

Даже если вы не пытаетесь предсказать значение неизвестной переменной (например, цены), алгоритмы машинного обучения всё равно способны на кое-что интересное.
Представьте, что вам дают список чисел и говорят: «Понятия не имею, что эти числа означают, но если у тебя получится найти в них закономерность — ты молодец». Поиском этих закономерностей и занимается алгоритм обучения без учителя.
Итак, что можно сделать с имеющимися данными? Для начала можно создать алгоритм, который автоматически будет определять различные рыночные сегменты в ваших данных. Может быть, вы обнаружите, что покупатели квартир рядом с местным институтом предпочитают небольшие квартиры с большим количеством комнат, а покупатели загородных домов выбирают большую площадь. В дальнейшем продвижении ваших услуг знание о возможных предпочтениях клиентов сослужит вам неплохую службу.
Что ещё? Алгоритм может автоматически определить отдельные дома, которые не вписываются ни в одну из категорий. Может быть, эти дома окажутся шикарными особняками, и на них можно сконцентрировать продажи, чтобы получить большие комиссионные.
В нашем руководстве мы уделим внимание алгоритмам обучения с учителем. Вовсе не потому что алгоритмы обучения без учителя менее интересны или полезны. На самом деле даже наоборот — обучение без учителя становится всё более важным для изучения, поскольку такие алгоритмы могут использоваться без привязки данных к правильному ответу.
Неужели возможность спрогнозировать цену квартиры уже может считаться машинным обучением?
Человеческий мозг способен анализировать любую ситуацию и обучаться без каких-либо внешних указаний. Если вы, к примеру, долгое время занимаетесь продажей недвижимости, у вас разовьётся некое инстинктивное чувство на правильную цену для конкретной квартиры; нюх на клиентов и на выгодные сделки. Целью «сильного искусственного интеллекта» является как раз воссоздание такой способности человеческого мозга с вычислительными мощностями компьютера.
К сожалению, текущая стадия развития обучающихся алгоритмов не настолько хороша — они работают только в узко ограниченных рамках одной проблемы. Наверное, в этом смысле термин «обучение» скорее означает «способность решить уравнение на основе предоставляемых данных».
Поскольку «способность решить уравнение на основе предоставляемых данных» — слишком громоздкий термин, всё это решили назвать «машинным обучением» в узко специализированной сфере.
Если вы читаете эту статью лет через 50 после её публикации, она уже вам ничем не может быть полезна. Закрой её и попроси своего робота приготовить тебе сэндвич, человек будущего!
Давайте уже напишем эту программу!
Может, у вас есть уже какие-то прикидки насчёт того, как бы вы написали программу, оценивающую стоимость квартиры на основе предоставляемых данных? Подумайте пару минут прежде, чем читать дальше.
Подумали? Приступим.
Если бы вы ничего не знали о машинном обучении, вы бы, скорее всего, попытались написать несколько простых правил, оценивающих стоимость дома:
# !/usr/bin/python
# -*- coding: utf-8 -*-
def estimate_house_sales_price(num_of_bedrooms, sqm, neighborhood):
price = 0
# Средняя цена квартиры в моем районе – 200$ за кв.м
price_per_sqm = 200
if neighborhood == "Арбат":
# В некоторых районах квартиры стоят дороже
price_per_sqm = 400
elif neighborhood == "Южное Бутово":
# В других районах квартиры стоят дешевле
price_per_sqm = 100
# начнём с базовой оценки стоимости на основе общей площади квартиры
price = price_per_sqm * sqm
# теперь уточним нашу оценку, указав количество комнат
if num_of_bedrooms == 0:
# квартиры-студии стоят дешевле
price = price — 20000
else:
# квартиры с большим количеством комнат
# стоят дороже
price = price + (num_of_bedrooms * 1000)
return price
Если вы ещё несколько часов посидите над кодом (и если очень повезёт), вся эта мутотень заработает. При этом полученное решение будет далеко от идеала и будет постоянно нуждаться в доработке, ведь цены постоянно меняются.
А давайте обучим компьютер
Не удобнее ли позволить компьютеру самому разобраться, каким способом он может решить эту задачу? Кого волнует, что конкретно выполняет функция, если она возвращает нужное значение?
# !/usr/bin/python
# -*- coding: utf-8 -*-
def estimate_house_sales_price(num_of_bedrooms, sqm, neighborhood):
price = <компьютер, сделай всё за меня>
return price
Нужно подойти к решению совершенно иначе. Представим, что цена — это борщ, который нам нужно приготовить. Его ингредиенты — это количество комнат, общая площадь и расположение. Если вы сможете вычислить, какое количество каждого ингредиента влияет на общие вкусовые свойства борща (цены, вы помните, да?), вы сможете рассчитать и пропорции ингредиентов, которые образуют финальный результат (снова цену).
Это упростит ваш начальный код (со всеми этими безумными if и else), превратив его во что-то вроде:
# !/usr/bin/python
# -*- coding: utf-8 -*-
def estimate_house_sales_price(num_of_bedrooms, sqm, neighborhood):
price = 0
# добавим щепотку вот этого
price += num_of_bedrooms * .841231951398213
# затем горсть вот этого
price += sqm * 1231.1231231
# ещё ложечку вот этого
price += neighborhood * 2.3242341421
# и немного пряностей
price += 201.23432095
return price
Обратите внимание на волшебные числа: .841231951398213, 1231.1231231,2.3242341421 и 201.23432095. Это наши коэффициенты. Если мы вычислим идеальные коэффициенты, которые будут работать для каждой квартиры, наша функция сама будет оценивать её стоимость!
Самый грубый способ рассчитать коэффициенты может выглядеть вот так:
Шаг 1:
Установим значения всех коэффициентов на 1.0:
# !/usr/bin/python
# -*- coding: utf-8 -*-
def estimate_house_sales_price(num_of_bedrooms, sqm, neighborhood):
price = 0
# добавим щепотку вот этого
price += num_of_bedrooms * 1.0
# затем горсть вот этого
price += sqm * 1.0
# ещё ложечку вот этого
price += neighborhood * 1.0
# и немного пряностей
price += 1.0
return price
Шаг 2:
Теперь мы прогоним все известные нам выставленные на продажу квартиры через эту функцию и выясним, насколько правильно функция угадывает цену для каждой квартиры:

К примеру, если первую квартиру на самом деле купили за 250 000$, а ваша функция оценила её в 178 000 долларов, где-то по пути вы потеряли 72 000 долларов.
Теперь вычислите общую сумму потерь функции с каждой квартиры в вашей базе данных. Допустим, в вашей базе данных 500 лотов, и общая сумма составила 86 123 373$. Это степень ошибочности вашей функции.
Теперь возьмите эту сумму и разделите её на 500, чтобы получить среднее значение ошибки функции для каждой квартиры. Назовите это среднее значение погрешностью функции.
Если вы сумеете свести погрешность функции к нулю, играя с коэффициентами, она будет работать превосходно. Превосходно — это когда функция в каждом случае выдаст идеальную оценку квартиры в зависимости от введённых данных. Итак, наша цель на данном этапе — сделать погрешность функции минимальной, подставляя различные значения коэффициентов.
Шаг 3:
Повторяйте Шаг 2 снова и снова, пока не проверите все возможные комбинации коэффициентов. Как только найдёте комбинацию, которая придаёт погрешности максимально близкое к нулю значение, — вы выиграли!
А теперь разрушаем легенды
Как просто, да? Всего-то нужно взять данные, провести их через три простых этапа и прийти в итоге к функции, которая выдаёт предположительную стоимость каждой квартиры в городе. У = Успех.
Но рано радоваться, юные друзья. Вот несколько фактов, которые убьют все надежды на светлое будущее нашего решения:
- За последние 40 лет исследования в сфере лингвистики/перевода доказали, что исходные обучающиеся алгоритмы оказываются значительно эффективнее, чем правила, созданные настоящими людьми. Машинное обучение в таких случаях побеждает человеческий подход.
- Функция, которую вы тут наизобретали, ничегошеньки не знает. Она не знает, что такое «квадратные метры» или «комнаты». Всё, что она умеет — это тасовать числа, чтобы получить нужное значение.
- Вы сами понятия не имеете, почему работает именно такая комбинация коэффициентов. Вы написали функцию, которую сами не понимаете, но которая работает.
- А теперь представьте, что вместо обработки параметров «квадратные метры» и «количество комнат» ваша предиктивная функция способна обработать массив чисел. Давайте представим, что каждое число представляет собой яркость одного пикселя в изображении, сделанном камерой, расположенной на крыше вашей машины. Представьте, что вместо «цены» ваша функция выводит значение «на сколько градусов нужно повернуть руль автомобиля». Стойте-стойте… Да это же функция, которая позволит создать самоуправляемый автомобиль!
А что насчёт «Пробуй все варианты, пока не сдохнешь» из шага 3?
Конечно, это безумие — перебирать все возможные комбинации коэффициентов, чтобы найти лучшую. На это понадобится вечность и ещё пара недель.
Математики знают много изящных способов быстро найти годные значения без помощи бесконечного тупого перебора. Давайте поступим так:
- Для начала напишем простое уравнение, которое заменяет собой действия в шаге 2 (нахождение погрешности):
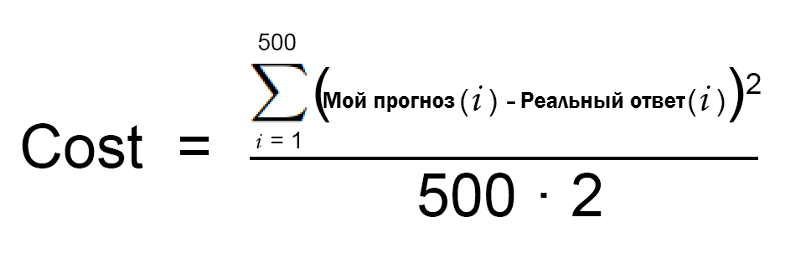
- Теперь немного видоизменим это уравнение, используя лексикон машинного обучения (пока не обращайте на это внимания):
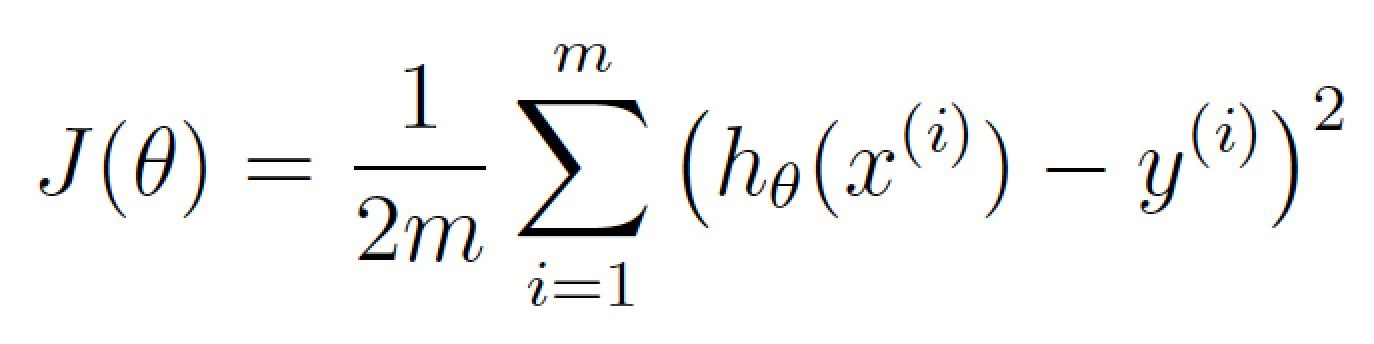
Если мы изобразим это уравнение, высчитывающее погрешность функции для всех возможных значений number_of_bedrooms и sqm, мы получим примерно такой график:
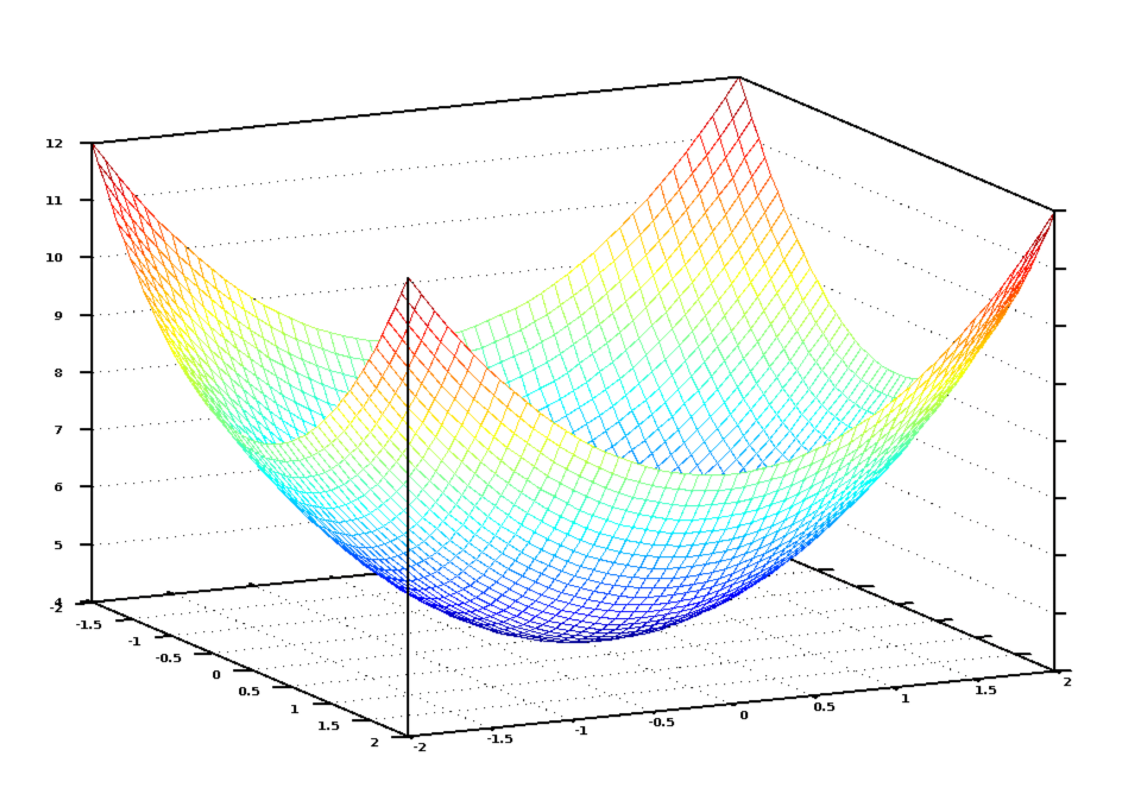
График нашей функции выглядит как чаша. По вертикальной оси — значения погрешности
В этом графике нижней точкой (синей) является минимальная погрешность — именно здесь наша функция работает наиболее правильно. В верхних точках функция наиболее сурово ошибается. Так что, если мы найдём коэффициенты, приводящие нас к нижней точке графика, мы найдём решение!
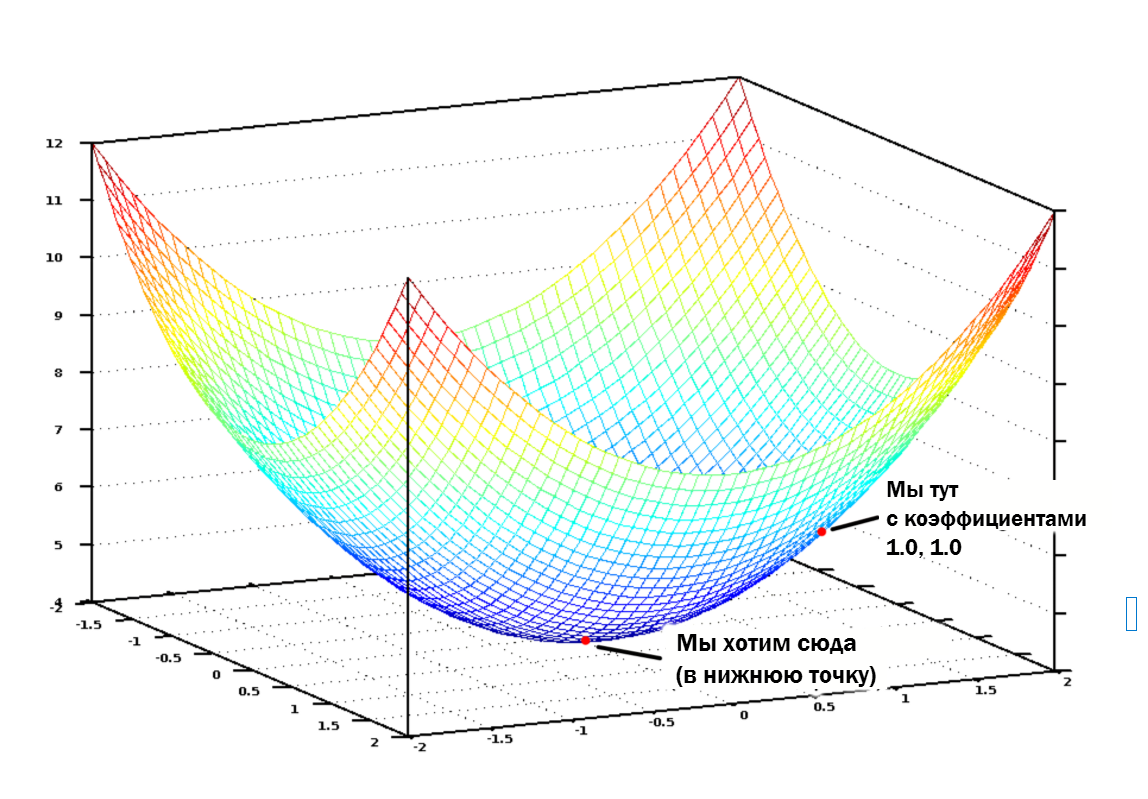
Как будем искать минимальную погрешность?
Нам нужно лишь настроить коэффициенты таким образом, чтобы мы «спускались» по кривой этого графика к самой нижней точке. Понемногу изменяя значения наших коэффициентов, мы придём к этой точке без необходимости перебора всех возможных значений.
Если вы хоть что-то помните из теории мат.анализа, вы, должно быть, знаете, что производная функции в данной точке равна тангенсу угла между касательной к графику этой функции в данной точке и осью абсцисс. Другими словами, значение производной функции скажет нам, куда идёт наклон в каждой точке нашего графика. В нашем спуске по графику это знание нам очень пригодится.
Итак, если мы рассчитаем частичную производную нашей функции погрешности в отношении каждого из коэффициентов, мы можем извлечь это значение из каждого коэффициента. Это на один шаг приближает нас к нижней точке спуска. Несколько таких итераций, и мы достигнем этой нижней точки, которая скажет нам лучшие значения всех наших коэффициентов.
Всё вышенаписанное — это достаточно грубое обобщение способа нахождения коэффициентов для функции, которое называется градиентным спуском.
Надо сказать, если вы используете библиотеку машинного обучения в реальной жизни, вся эта магия уже проделана до вас и за вас. Тем не менее, неплохо иметь представление о том, что происходит за кулисами.
Что ещё мы пропустили?
Описанный здесь трёхступенчатый алгоритм называется множественной линейной регрессией. Вы создаёте уравнение для ряда факторов, соответствующих данным обо всех квартирах в вашей базе данных. Затем вы используете это уравнение, чтобы спрогнозировать цену продажи квартир, которых вы никогда не видели.
Подход, который здесь продемонстрирован, работает в простых случаях, но он не универсален. Даже в нашем примере с недвижимостью он недостаточен, потому что цены не всегда формируются настолько простым образом, чтобы создать линейную модель.
К счастью, существует ещё тонна подходов, чтобы справиться с этим. Есть множество алгоритмов машинного обучения, которые работают с нелинейными данными (например, нейросети или метод опорных векторов). Даже ту же самую линейную регрессию можно использовать более мудро для более сложных линейных моделей. В любом случае, везде действует один и тот же принцип: найти лучшие коэффициенты для данной функции.
Кроме того, мы полностью упустили проблему переобучения. Эта проблема возникает тогда, когда коэффициенты прекрасно работают при прогнозировании цен на квартиры в вашей базе данных, но не работают при прогнозировании цен на неизвестные алгоритму квартиры. Но и для этой проблемы есть решения (например, регуляризация или использование метода перекрёстной проверки). Научившись справляться с подобными проблемами, вы научитесь эффективно применять машинное обучение в своих проектах.
Основная идея машинного обучения, как видите, довольно проста, но, конечно, требует навыков и опыта для успешной реализации. Но ведь именно этим занимается любой уважающий себя программист — постоянно расширяет базу своих навыков.
Машинное обучение — это панацея?
Как только вы увидите, как машинное обучение применяется к действительно сложным задачам (например, распознавание рукописного текста), у вас тут же возникнет обманчивое впечатление о том, что алгоритмы машинного обучения можно применять абсолютно во всех случаях, где у вас есть база данных. Просто даём алгоритму данные, а компьютер сам всё сделает!
Важно не забывать, что алгоритмы машинного обучения работают только тогда, когда имеющихся данных действительно достаточно для решения проблемы.
Если вам нужно предсказать цены на недвижимость, основываясь на разновидностях комнатных растений в каждом доме, машинное обучение тут точно не поможет. Алгоритм просто не увидит взаимосвязи между наличием фикуса в доме и конечной ценой.
Поэтому нужно помнить, что если человек не может использовать данные для решения проблемы, компьютер, скорее всего, тоже не сможет. Вместо этого старайтесь использовать алгоритмы машинного обучения для решения тех проблем, которые может решить и человек, но сделает это гораздо медленнее.
Другие статьи по теме
Основы машинного обучения за неделю
Огромное спасибо Adam Geitgey за прекрасный пост на Medium
Перевод: Люся Ширшова.


Комментарии