

Веб-скрапинг используется для сбора различной информации, в том числе для таких видов данных, которые регулярно обновляются, например, сообщений с досок объявлений о новых вакансиях. В этом проекте мы развернём на сервере Heroku приложение Django, которое посылает соответствующие уведомления о публикации новых мест работы.
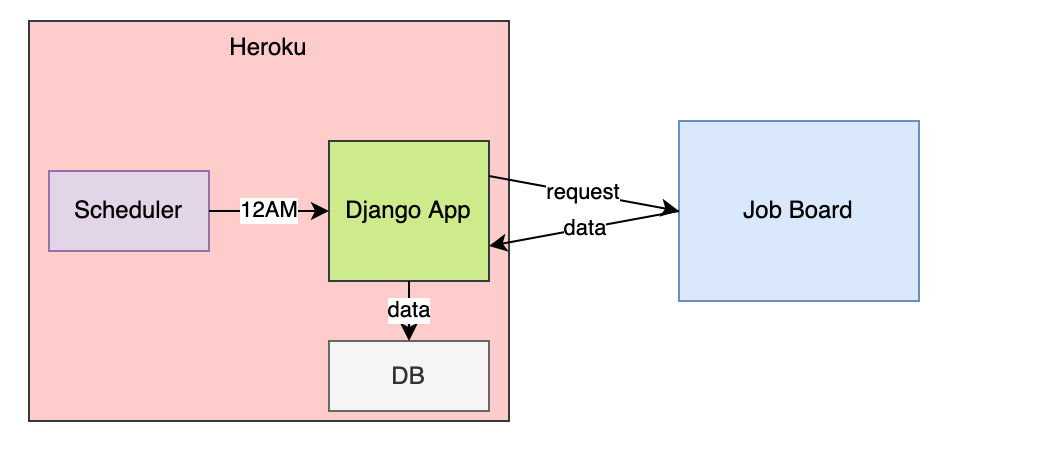
План рассказа:
- Создаём Django приложение
- Создаём и настраиваем модель вакансии
- Настраиваем базу данных
- Тестируем приложение
- Настраиваем команды django-admin
- Разёрываем приложение на Heroku
- Планируем расписание скрапинг
1. Создаём Django приложение
Создаём каталог приложения и переходим в него.
mkdir jobs && cd jobs
Создаём и запускаем виртуальную среду. Устанавливаем необходимые пакеты.
python -m venv env
source env/bin/activate
pip3 install django psycopg2 django-heroku bs4 gunicorn
Создаём проект Django.
django-admin startproject jobs
Заходим в проект и создаём приложение для скрапинга.
cd jobs
django-admin startapp scraping
2. Создаём и настраиваем модель
Теперь нужно определить единственную модель нашего приложения – модель работы. Она соответствует записям о вакансиях, которые мы будем собирать.
Файл /scraping/models.py перезаписываем со следующим содержанием.
from django.db import models
from django.utils import timezone
class Job(models.Model):
url = models.CharField(max_length=250, unique=True)
title = models.CharField(max_length=250)
location = models.CharField(max_length=250)
created_date = models.DateTimeField(default=timezone.now)
def __str__(self):
return self.title
class Meta:
ordering = ['title']
class Admin:
pass
Зарегистрируем модель в /scraping/admin.py. Это позволит просматривать записи в стандартной панели администратора Django (скоро мы к этому вернёмся):
from scraping.models import Job
admin.site.register(Job)
Добавялем scraping в установленные приложения в /jobs/settings.py.
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'scraping'
]
3. Настраиваем базу данных
Настраиваем базу данных. В нашем примере это будет PostgreSQL (Библиотека программиста писала о том, как начать разбираться в PostgreSQL).
Создаём базу данных для проекта в командной строке. Открываем консоль PostgreSQL:
psql -d template1
Создаём пользователя и базу данных, выходим:
create user django_user;
create database django_jobs owner django_user;
\q
В /jobs/settings.py обновите константу DATABASES:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'django_jobs',
'USER': 'django_user',
'HOST': '',
'PORT': ''
}
}
Создаём файлы для миграции и переносим базу данных.
python manage.py makemigrations
python manage.py migrate
Это создаст таблицу с именем scraping_job. Название соответствует соглашению Django о пространстве имён.
Создаём суперпользователя и пароль:
python manage.py createsuperuser --email admin@example.com --username admin
4. Тестируем приложение
Мы уже что-то сделали, но пока понятия не имеем, работает ли оно. Давайте проверим, прежде чем идти дальше:
python manage.py runserver
Переходом в браузере по адресу http://127.0.0.1:8000/admin. Входим в систему под суперпользователем, которого только что создали. После входа в систему, нажимаем jobs в разделе scraping, затем add job в правом верхнем углу. Заполняем пример информации и жмём save. Если вы видите созданную вами запись, то всё работает.
5. Настраиваем команды django-admin
Теперь настроим кастомную команду django-admin, которая производит скрапинг доски с вакансиями. Это то, что мы планируем на уровне инфраструктуры, чтобы автоматизировать скрапинг.
Внутри каталога /scraping создаём каталог с именем /management и каталог внутри /management с именем /commands. В папке /commands создаём два файла Python: _private.py и scrape.py.
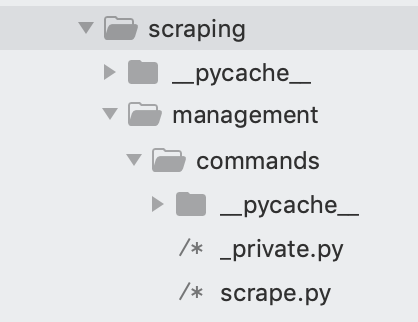
Ниже идёт код скрапера, записанный в scrape.py. При необходимости перепишете его под страницу, с которой нужно собирать информацию. Здесь это вакансии фирмы, в которой автору интересно работать.
from django.core.management.base import BaseCommand
from urllib.request import urlopen
from bs4 import BeautifulSoup
from scraping.models import Job
class Command(BaseCommand):
help = "collect jobs"
# определяем логику команд
def handle(self, *args, **options):
# собираем html
html = urlopen('https://jobs.lever.co/opencare')
# преобразуем в soup-объект
soup = BeautifulSoup(html, 'html.parser')
# собираем все посты
postings = soup.find_all("div", class_="posting")
for p in postings:
url = p.find('a', class_='posting-btn-submit')['href']
title = p.find('h5').text
location = p.find('span', class_='sort-by-location').text # check if url in db
try:
# сохраняем в базе данных
Job.objects.create(
url=url,
title=title,
location=location)
print('%s added' % (title,))
except:
print('%s already exists' % (title,))
self.stdout.write( 'job complete' )
Функция handle в определении класса Command сообщает Django, что это пользовательская команда django-admin. Для самого скрапинга используем BeautifulSoup. В Библиотеке программиста есть популярный видеокурс по парсингу сайтов со ссылками на видео и листингом кода.
Запускаем свежесозданную пользовательскую команду:
python manage.py scrape
Видим следующий вывод:

Запустив снова, увидим следующее:

Разный вывод связан с тем, что в scrape.py мы запретили добавлять дубликаты записей.
Если у вас установлена программа администрирования баз данных (например, dbeaver), вы также можете проверить строки в БД. Это должно выглядеть приблизительно так, как показано ниже.

6. Развёртываем на Heroku
Перенесём получившийся результат на Heroku. Заморозим зависимости, чтобы Heroku знал, что устанавливать при развёртывании.
pip3 freeze > requirements.txt
Предотвратим перенос ненужных файлов. В .gitignore запишем следующее:
.DS_Store
jobs/__pycache__
scraping/__pycache__
Создаём файл с именем Procfile в корне и вставляем приведённые ниже строки:
web: gunicorn jobs.wsgi
release: python manage.py migrate
Первая строка говорит Heroku о запуске web dyno, вторая команда переносит базу данных.
Дерево файлов будет выглядеть так.

Заходим в heroku из командной строки (heroku login). Создаём приложение с любым подходящим именем. Имя обязано быть уникальным среди всех приложений Heroku. Вводим heroku create имя-приложения .
Теперь добавляем следующие строки в самый конец файла settings.py. Модуль heroku_django позаботится за вас о настройках конфигурации.
import django_heroku
django_heroku.settings(locals())
Обновляем в настройках DEBUG, если не хотим развертывать в режиме отладки.
DEBUG = False
Добавляет файлы в Git.
git init
git add . -A
git commit -m 'first commit'
Пушим приложение в Heroku.
git push heroku master
7. Планируем расписание скрапинга
Конечно, можно вручную запускать задание из командной строки
heroku run python manage.py scrape
Но мы же хотим автоматизировать процесс! Входим в консоль Heroku, идём в Resources, затем find more add-ons.
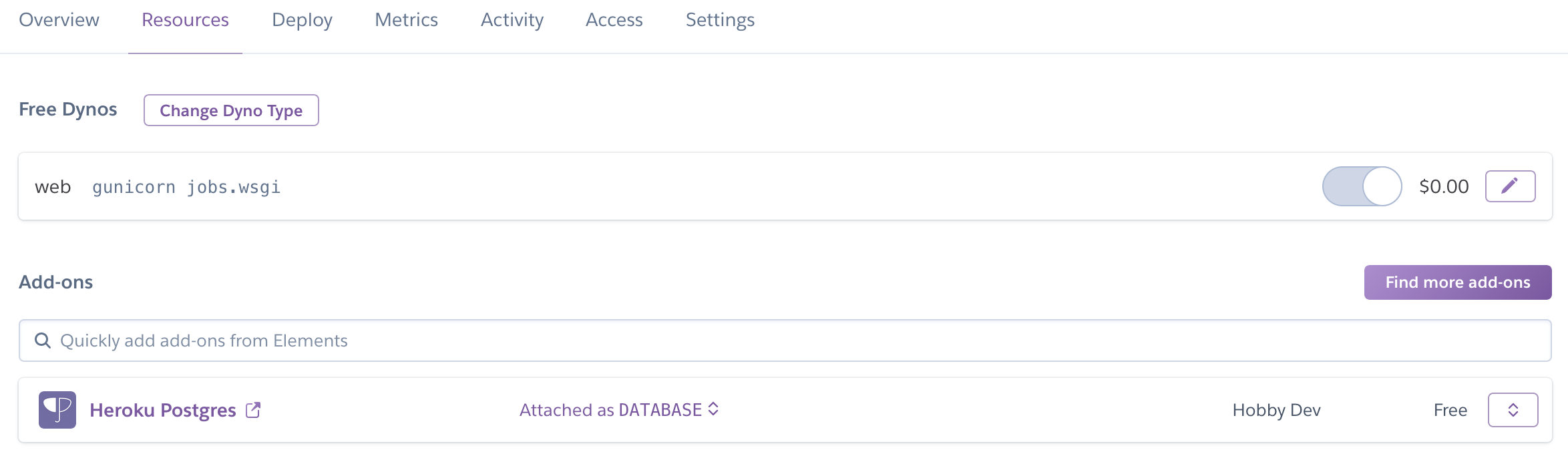
Находим и нажимаем на дополнение, ищем scheduler .


Нажимаем, выбираем время, например, everyday at... 12am UTC. Не пингуем сайты больше чем нужно. Вводим созданную команду и сохраняем.
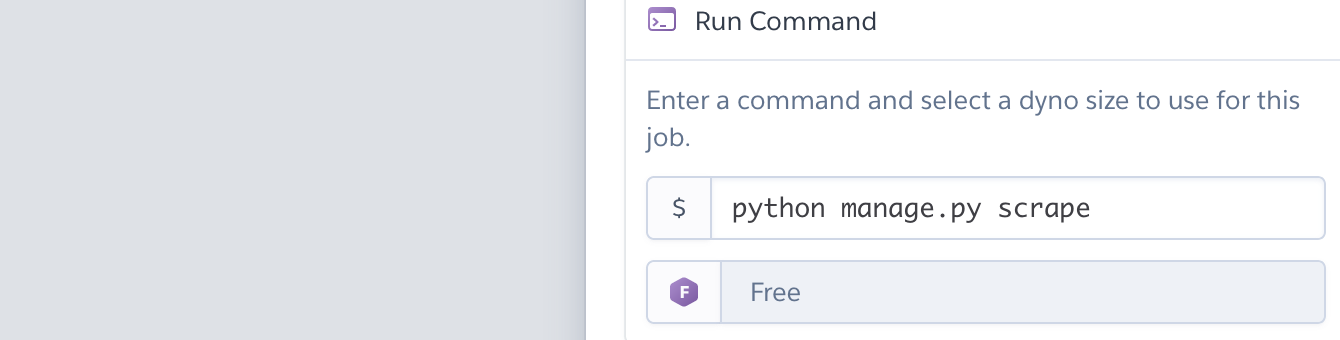
Теперь просто дожидаем 12:00 UTC или другого времени, и проверяем базу данных.
Заключение
Мы коснулись здесь многих разных вещей: Django, Heroku, веб-скрапинг, PostgreSQL. О всех этих инструмента по отдельности Библиотека программиста уже писала, а объединяющего практического материала – ещё не было. Если что-то оказалось сложным, воспользуйтесь приведёнными ссылками.
Конечно, у вас могут быть другие идеи для использования отложенного скрапинга. Например:
- Компании электронной коммерции хотят отслеживать цены конкурентов..
- Разработчики отслеживают IT-мероприятия и курсы из разных источников.
- Аналитики собирают информацию о конкурсах по анализу данных с нескольких платформ.
Это пособие лишь конкретный пример использования подхода. Дайте нам знать, если вам интересны подобные проекты.
Комментарии