
В данной статье представлены 6 приложений, использующих глубокое обучение. Любое из приложений легко реализуется, попробуй сам, и тебе понравится!
Введение
В последнее время глубокое обучение стало наиболее изучаемым и обсуждаемым предметом в области анализа данных. И данная тема заслуживает внимания, так как некоторые достижения в области анализа данных лежат как рав в области глубокого обучения. Кажется, что в ближайшем будущем приложения глубокого обучения окажут огромное влияние на нашу жизнь. Однако я считаю, что они уже оказывают свое влияние.
Тем не менее если вы уже смотрели на глубокое обучение со стороны, то оно вам могло показаться сложным и пугающим. Такие термины, как TensorFlow, Keras, GPU, основанные на компьютерных вычислениях, могут показаться пугающими. Но позвольте мне рассказать вам секрет – это не сложно! Вам придётся потратить на изучение современного глубокого обучения много времени и усилий, но зато вы с лёгкостью сможете применять полученные знания для решения повседневных задач.
Кроме того, это весело. Я вновь почувствовал себя любопытным ребёнком, который открывает для себя что-то новое во время применения глубокого обучения. В данной статье я покажу вам 6 приложений, которые могут показаться сложными, но применяя глубокое обучение, вы менее чем за час сможете написать их. Статье предназначена для того, чтобы объяснить принципиально новые слова и показать их в действии.
Давайте начнём!
P.S. Мы предполагаем, что у вас имеются базовые знания Python. Если нет, то посетите данный туториал, а затем вы сможете снова вернуться к данной статье.
Содержание
1. Приложения, использующие современное API
- Достоинства и недостатки API для глубокого обучения
- Раскрашиваем фотографии, используя глубокое обучение и Algorithmia API
- Создание ChatBot с использованием Watson API
- Создание RSS-агрегатора, базирующегося на анализе тональности текста, используя Aylien API
2. Приложения с открытым исходным кодом
- Достоинства и недостатки открытого исходного кода
- Коррекция предложений с помощью глубокого обучения
- Преобразуем мужские портреты в женские и наоборот, используя глубокое обучение
- Создание бота, использующего метод проб и ошибок, для игры во Flappy Bird
3. Другие весьма полезные ресурсы
1. Приложения, использующие современное API
Любое API – это не что иное, как программное обеспечение, запущенное на удаленном ПК, к которому можно получить локальный доступ. Например, вы подключаете Bluetooth-динамики к вашему ноутбуку, хотя в него могут быть встроены свои динамики. Таким образом, мы можем получить доступ к нашим динамикам удаленно, находясь за ноутбуком.
Любое API работает по схожему принципу – кто-то уже сделал за вас сложную работу, и вы можете использовать это для быстрого решения своих задач. Для более детального ознакомления с API перейдите по ссылке.
Я просто составлю список достоинств и недостатков создания приложений, используя API.
1.1.1 Достоинства API для глубокого обучения:
- Любое приложение глубокого обучения требует высоких вычислительных мощностей для GPU и хранения/обработки данных. Поэтому вы можете использовать готовый терминал для своих нужд (или использовать любой облачный сервис) и любую систему. Нужен только локальный доступ к данному терминалу, после чего вы можете запускать ваши приложения;
- Ваши локальные системы не производят вычисления;
- Новый функционал легко встраивается.
1.1.2 Недостатки API для глубокого обучения:
- Создание API - дело затратное. API требует и время, и ресурсы для разработки, и обслуживания, что в некотором роде утомительно;
- Вы ограничены Интернет-соединением, если соединение будет разорвано, то система сломается;
- В вашем приложении должна быть безопасная система доступа, так как без этого любой может с легкостью получить к нему доступ. Для этого вы можете организовать доступ к вашему приложению через парольную аутентификацию, тем самым ограничить доступ к приложению.
Если вы хотите узнать больше о том, что же такое API, посетите данный блог.
Давайте перейдем к нашему приложению!
1.2 Раскрашиваем фотографии, используя глубокое обучение (Algorithmia API)
Автоматическое получение цветного изображения является весьма интересной темой для обсуждения среди сообщества по машинному распознаванию образов. Получение цветной фотографии из черно-белой кажется чем-то фантастическим. Представьте, вы подобрали старый четырёхлетний цветной карандаш и начали раскрашивать им свою раскраску. А сможем ли мы научить нашего искусственного “посредника” делать то же самое и предоставить ему нужное представление вещей?
Несомненно, это сложная задача! Связано это с тем, что мы, люди, каждый день “тренируемся”, видя, как выглядят цветные предметы в реальном мире. Вы могли не заметить, но наш мозг запоминает каждый момент нашей жизни и извлекает важную информацию из этого, например, то, что небо голубое, а трава зелёная. В этом и заключается сложность моделирования искусственного “посредника”.
Последние исследования показывают, что при достаточном обучении нейронной сети на большом наборе подготовленных данных, мы можем получить модель, которая преобразовывает черно-белое изображение в цветное. Вот пример раскрашивания изображения:

Для практической реализации данного примера мы используем API, разработанное Algorithmia.
Требования и спецификации:
- Python (2 или 3);
- Интернет соединение (для получения доступа к API);
- 12 кредитов-algorithmia (несмотря на то, что кредиты платные, algorithmia предоставляет 5000 кредитов при регистрации).
Шаг 1: Регистрируемся на Algorithmia и получаем собственный API ключ. Вы можете найти API ключ в своем профиле.
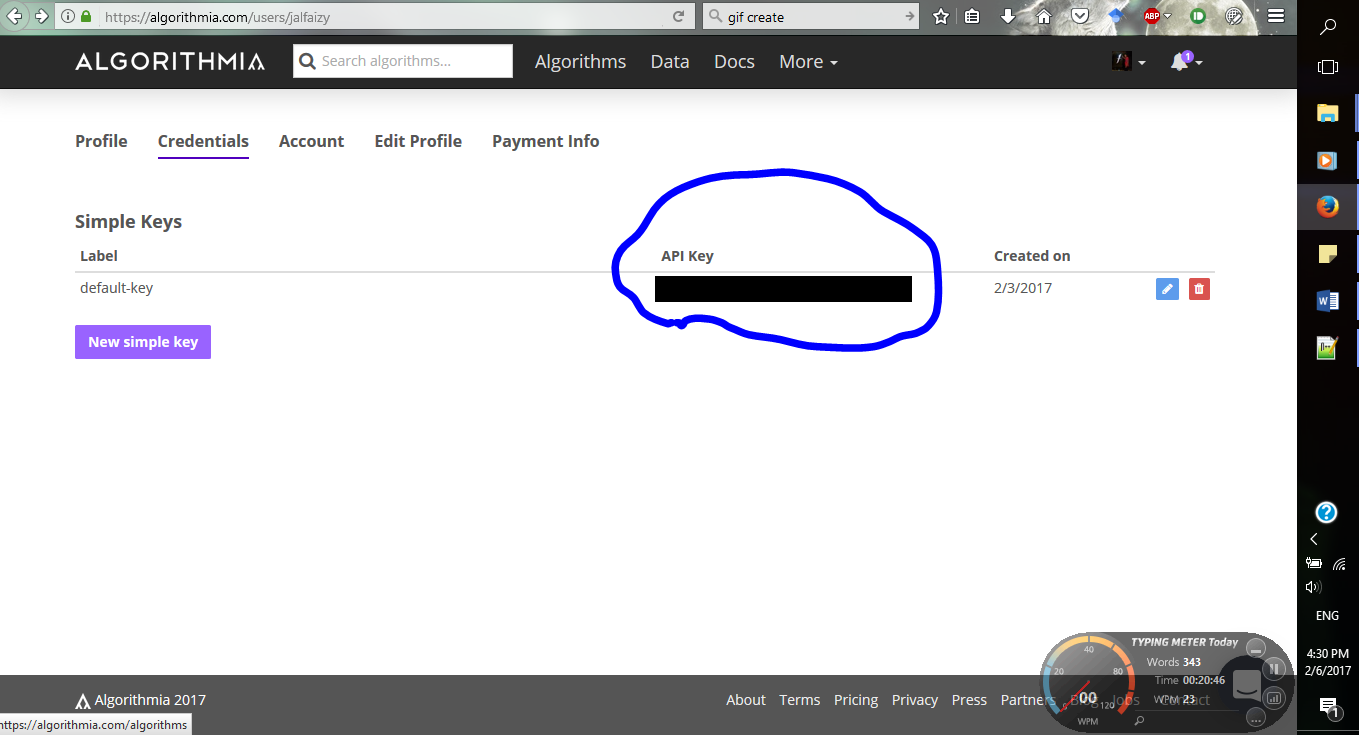
Шаг 2: Устанавливаем algorithmia, вводя
pip install algorithmia
Шаг 3: Выберете фотографию, которую хотите раскрасить, и загрузите её в раздел Data, предусмотренный algorithmia.
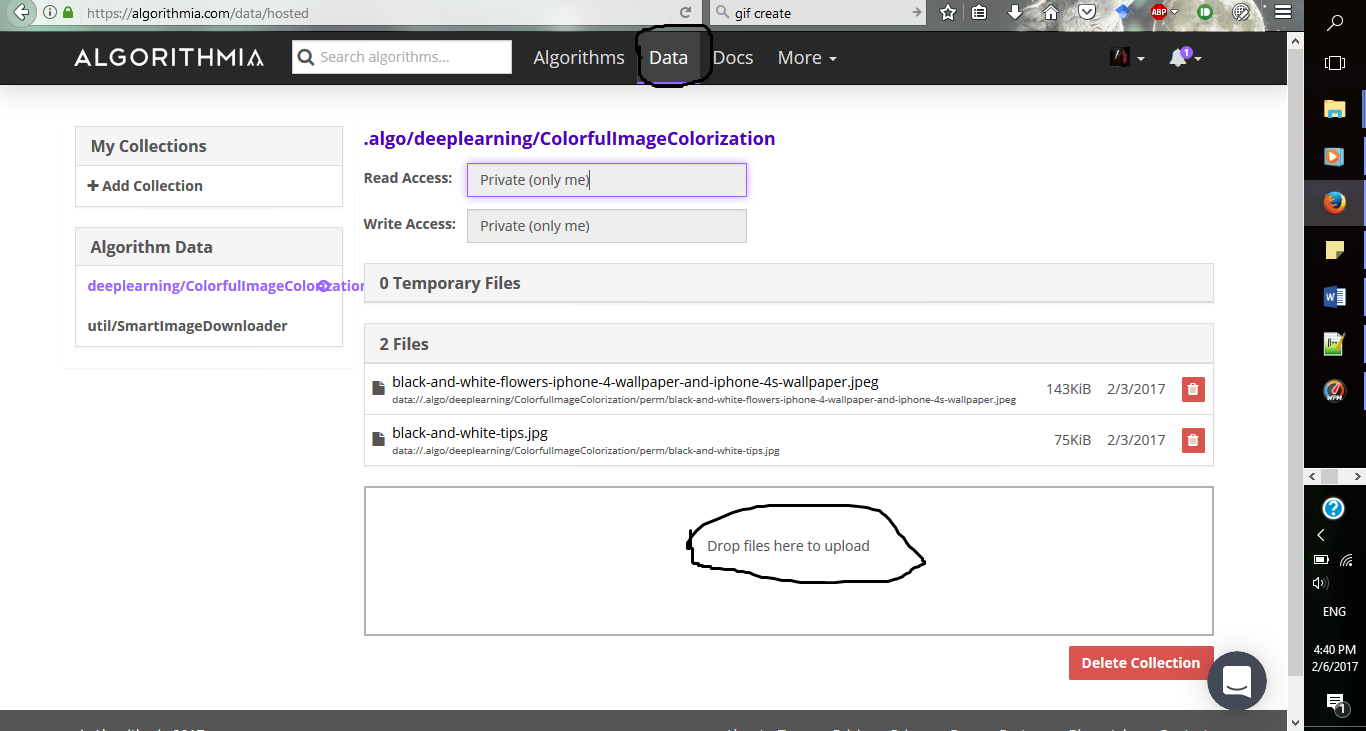
Шаг 4: Создайте локальный файл с именем trial.py. Откройте его и напишите код, что представлен ниже. Обратите внимание, что вам нужно указать расположение вашего изображения и ваш API ключ.
import Algorithmia
input = {
"image": "data:// … " # Указываете расположение вашего изображения
}
client = Algorithmia.client(‘…’) #вставляете свой API ключ
algo = client.algo('deeplearning/ColorfulImageColorization/1.1.5')
print algo.pipe(input)
Шаг 5: Откройте командную строку и запустите ваш код, введя эту команду.
python trial.py
Результат автоматически сохранится в вашем Data разделе. Вот что получилось у меня:

 Ну вот и все, мы создали простое приложение, которое ведет себя, как ребенок, и может раскрасить изображение! Занимательное задание.
Ну вот и все, мы создали простое приложение, которое ведет себя, как ребенок, и может раскрасить изображение! Занимательное задание.
1.3 Создание ChatBot с использованием Watson API.
Watson – это отличный пример, показывающий, чего может достичь искусственный “посредник”. Вы могли слышать историю о том, как Watson победил человека в игре-викторине Jeopardy! Несмотря на то, что Watson использует набор различных техник для работы, глубокое обучение является основой процесса обучения, особенно при обработке естественного языка.
Для создания разговорной службы, она же chatbot, мы будем использовать одно из многих приложений Watson-a. Chatbot – это некий “посредник”, который отвечает на распространённые вопросы, как человек. Такие посредники используются если, например, вам нужно своевременно отвечать клиентам на их вопросы.
Здесь вы можете посмотреть демонстрацию платформы:
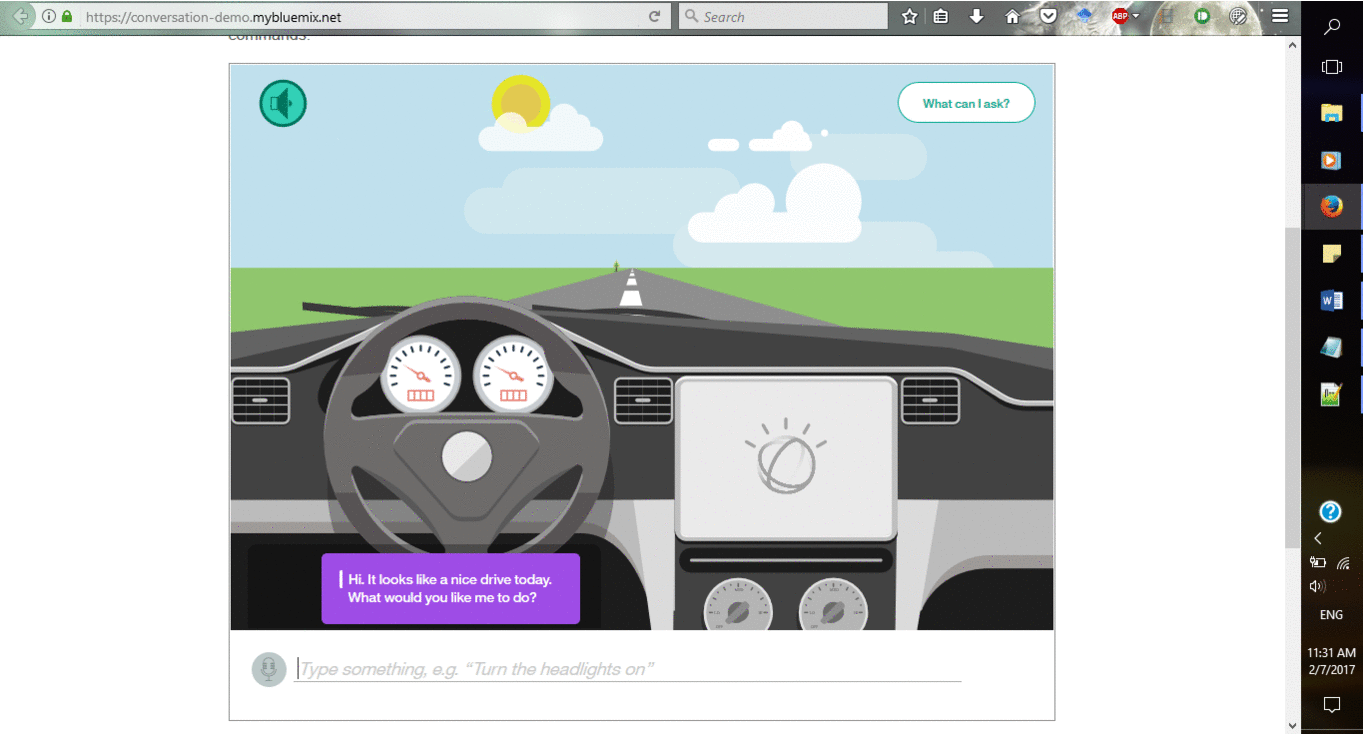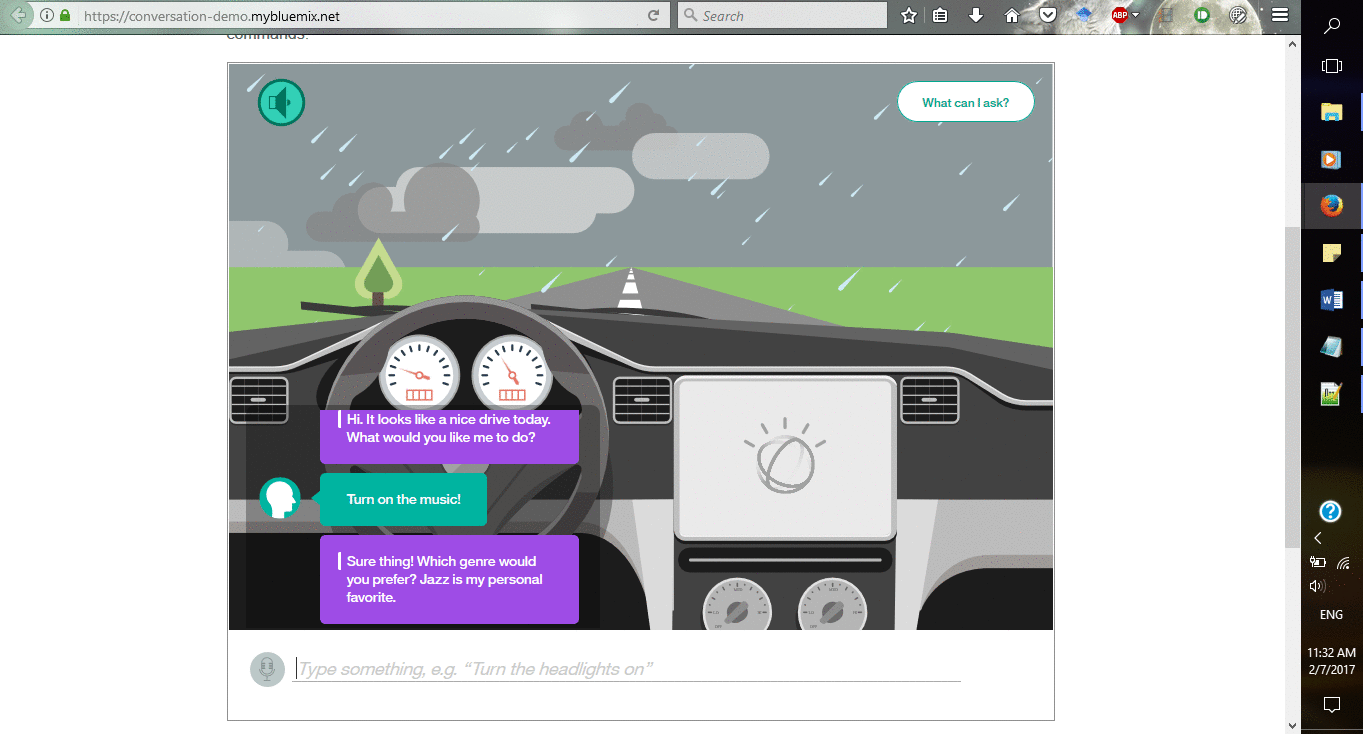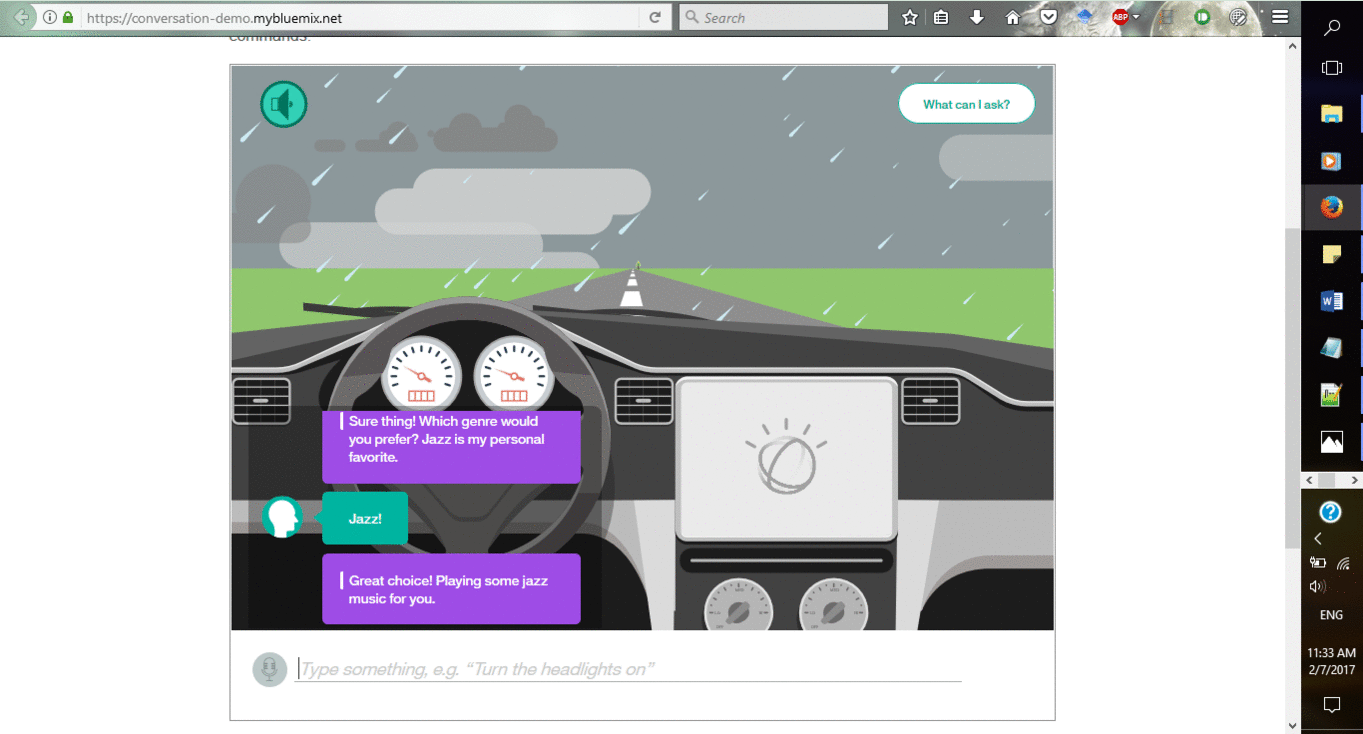
Требования и спецификации:
- Python (2 или 3);
- Интернет соединение (для получения доступа к API);
- Активный Bluemix аккаунт (пробный период длится 30 дней).
Давайте посмотрим шаг за шагом, как создать простой chatbot с помощью Watson.
Шаг 1: Регистрируемся на Bluemix и активируем аккаунт для получения регистрационных данных.
Шаг 2: Открываем терминал и запускаем команды, как указано ниже:
pip install requests responses pip install --upgrade watson-developer-cloud
Шаг 3: Создаем файл trial.py и копируем в него указанный ниже код. Не забудьте указать ваши регистрационные данные.
import json
from watson_developer_cloud import ConversationV1
conversation = ConversationV1(
username='ВАШ ЛОГИН ',
password='ВАШ ПАРОЛЬ',
version='2016-09-20')
# переместите ваш workspace_id
workspace_id = ' ВАШ ID'
response = conversation.message(workspace_id=workspace_id, message_input={
'text': 'What\'s the weather like?'})
print(json.dumps(response, indent=2))
Шаг 4: Сохраните файл и запустите его, введя в консоли эту команду:
python trial.py
В консоли вы получите ответ на тот вопрос, который задали Watson-у.
Вопрос: Покажи мне, что находится рядом со мной?
Ответ: Как я понимаю, вы хотите, чтобы я показал вам различного рода удобства. Я могу найти ближайшие рестораны, заправки и туалеты.
Если вы хотите создать более полноценный проект разговорной службы с анимированной автомобильной панелью (как показано на гифке выше), то посетите данный github репозиторий.
1.4 Создание RSS-агрегатора, базирующегося на анализе тональности текста, используя Aylien API.
Иногда хочется видеть только хорошие новости, происходящие в мире. Как было бы хорошо, если мы могли бы отфильтровать все плохие новости во время чтения газеты и видеть только “хорошие” новости!
С помощью современных технологий обработки естественной речи (одной из которых является глубокое обучение) это все больше и больше становится реальным. В настоящий момент вы можете отфильтровать новости за счет анализа тональности текста и предоставить их читателю.
Далее мы рассмотрим и применим Aylien’s News API. Ниже приведены скриншоты демо-версии News API. Вы можете создать свой собственный запрос и посмотреть на полученный результат.
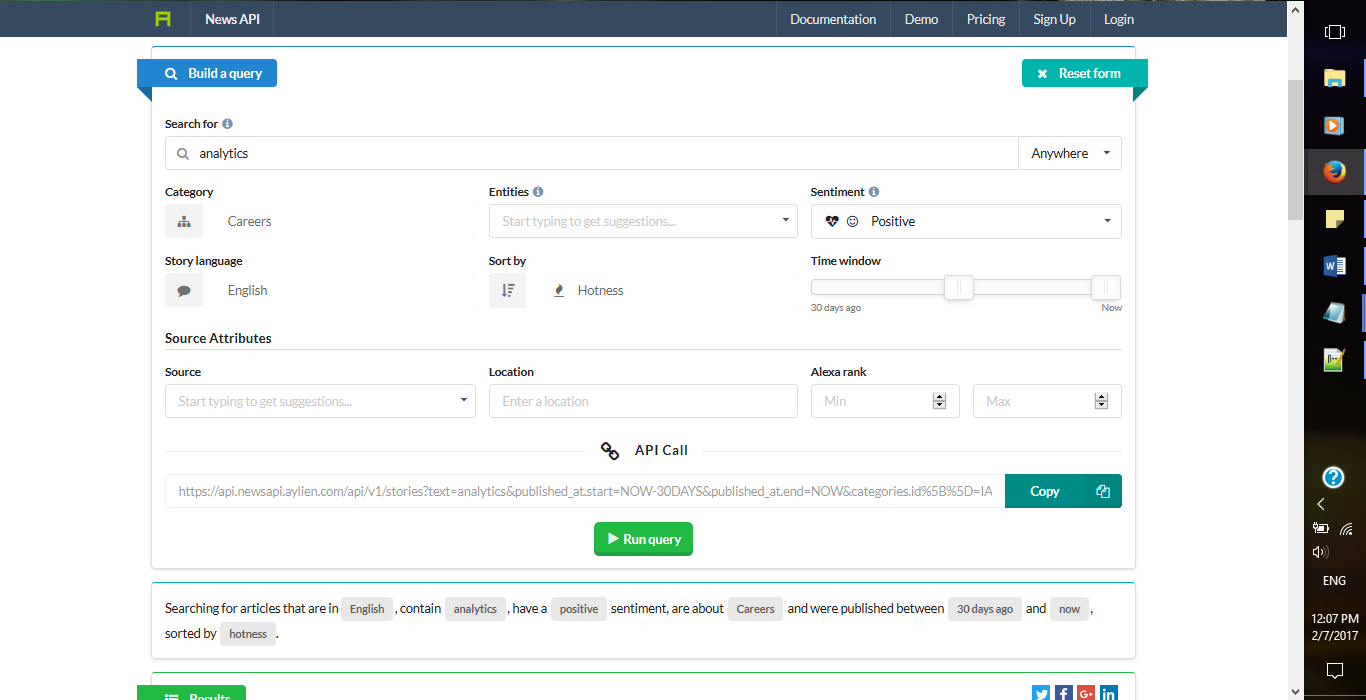
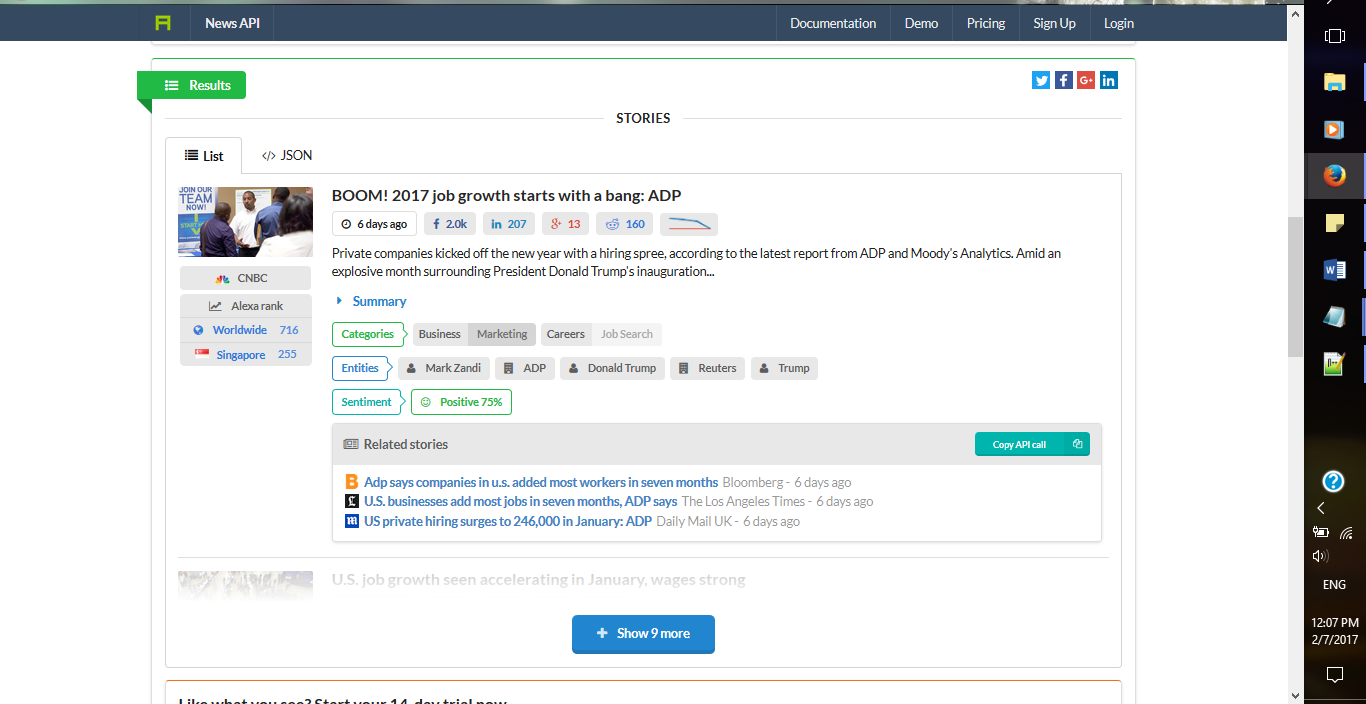
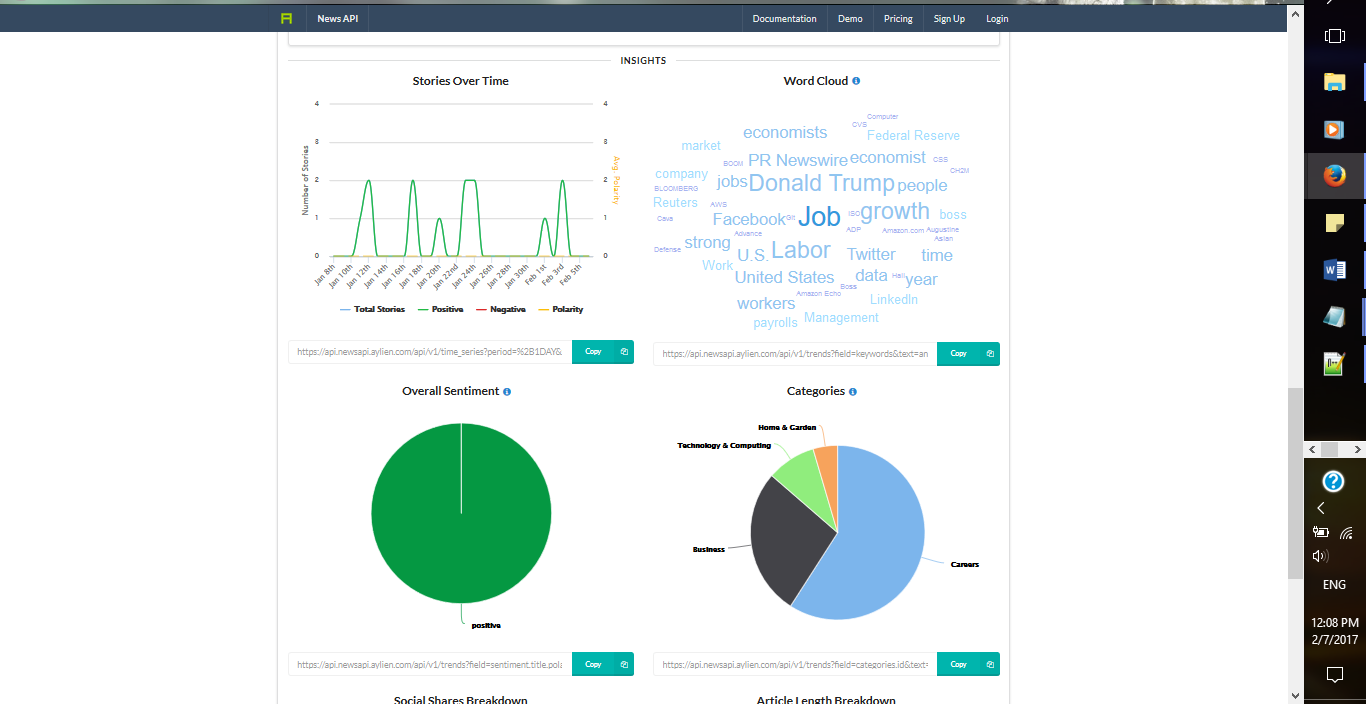
Давайте посмотрим на Python реализацию
Требования и спецификации:
- Python (2 или 3);
- Интернет-соединение (для получения доступа к API).
Шаг 1: Регистрируемся на сайте Aylien.
Шаг 2: Берем API_key и App_ID из своего профиля после регистрации.
Шаг 3: Устанавливаем Aylien News API с помощью командной строки.
pip install aylien_news_api
Шаг 4: Создаем файл trial.py и копируем следующий код:
[spoiler title='Код']
import aylien_news_api
from aylien_news_api.rest import ApiException
# Configure API key authorization: app_id
aylien_news_api.configuration.api_key['X-AYLIEN-NewsAPI-Application-ID'] = ' 3f3660e6'
# Configure API key authorization: app_key
aylien_news_api.configuration.api_key['X-AYLIEN-NewsAPI-Application-Key'] = ' ecd21528850dc3e75a47f53960c839b0'
# create an instance of the API class
api_instance = aylien_news_api.DefaultApi()
opts = {
'title': 'trump',
'sort_by': 'social_shares_count.facebook',
'language': ['en'],
'published_at_start': 'NOW-7DAYS',
'published_at_end': 'NOW',
'entities_body_links_dbpedia': [
'http://dbpedia.org/resource/Donald_Trump',
'http://dbpedia.org/resource/Hillary_Rodham_Clinton'
]
}
try:
# List stories
api_response = api_instance.list_stories(**opts)
print(api_response)
except ApiException as e:
print("Exception when calling DefaultApi->list_stories: %s\n" % e)
[/spoiler]
Шаг 5: Сохраняем файл и запускаем его:
python trial.py
Результатом будет json-дамп, как представлено ниже:
[spoiler title='Дамп']
{'clusters': [],
'next_page_cursor': 'AoJbuB0uU3RvcnkgMzQwNzE5NTc=',
'stories': [{'author': {'avatar_url': None, 'id': 56374, 'name': ''},
'body': 'President Donald Trump agreed to meet alliance leaders in Europe in May in a phone call on Sunday with NATO Secretary General Jens Stoltenberg that also touched on the separatist conflict in eastern Ukraine, the White House said.',
'categories': [{'confident': True,
'id': 'IAB20-13',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB20-13',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB20'},
'score': 0.3734071532595844,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB11-3',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB11-3',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB11'},
'score': 0.2898707860282879,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB10-5',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB10-5',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB10'},
'score': 0.24747867463774773,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB25-5',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB25-5',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB25'},
'score': 0.22760056625597547,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB20',
'level': 1,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB20',
'parent': None},
'score': 0.07238470020202414,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB10',
'level': 1,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB10',
'parent': None},
'score': 0.06574918306158796,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB25',
...
[/spoiler]
Ого! Теперь я могу предоставить к вашим услугам chatbot, точно такой же сервис, как Alexa, которая читает интересующие вас новости! Я уверен, что вы будете удивлены глубоким обучением прямо сейчас!
2. Приложения с открытым исходным кодом
Наилучшим решением, которое прямо сейчас может помочь научному сообществу, являются ресурсы с открытым исходным кодом. В настоящий момент многие исследователи готовы поделиться своими достижениями, что, в свою очередь, способствует развитию глубокого обучения, вследствие чего данная сфера будет расти как на дрожжах. Здесь я приведу примеры проектов с открытым исходным кодом, которые были созданы на основе научных исследований.
2.1.1 Достоинства приложений с открытым исходным кодом:
- Если приложение имеет открытый исходный код, то вы с легкостью можете посмотреть все детали приложения и с такой же легкостью настроить их под свои нужды;
- Такие приложения строятся на основе опыта многих разработчиков из различных компаний. Такой подход делает приложение намного лучше его исходных версий. Также в силу того, что многие смогут воспользоваться таким приложением, то, следовательно, оно будет хорошо протестировано и готово к использованию.
2.1.2 Недостатки приложений с открытым исходным кодом:
- Теряется фактор “владения” такого продукта, словно нет поддержки со стороны какой-либо организации. Так что, если что сломается, то никто не виноват!
- Также встает вопрос лицензирования, так как многие компании не захотят, чтобы к их проектам был открытый доступ.
Примечание: Перед тем как начать работу с подобного рода приложениями, я советую начать с их официальных репозиториев. Причиной этому является то, что многие из них находятся в стадии разработки и могут отрицательно повлиять на ваш еще не готовый разум.
А теперь давайте посмотрим на несколько подобных приложений!
2.2 Коррекция предложений с помощью глубокого обучения
В настоящий момент любая система может с легкостью находить и исправлять ошибки правописания, но исправление грамматических ошибок - задача более сложная. Для облегчения данной задачи мы можем использовать глубокое обучение, чтобы исправлять предложения. Данный репозиторий создан специально для решения данной задачи.
У нас имеется нейронная сеть, распознающая последовательности данных, которая была обучена на наборе грамматически неверных предложений и их корректных аналогах. Такая модель показывает многообещающие результаты корректировки предложений. Приведем пример:
Ввод: “Kvothe went to market”
Вывод: “Kvothe went to the market”
Ошибка заключается в отсутствии определённого артикля the, необходимость артикля заключается в том, что Kvothe ходил на определённый рынок.
Модель не идеальна и не может исправить все предложения, однако при большем количестве обучающих данных и эффективных алгоритмах глубокое обучение может значительно улучшить результаты.
Требования:
- Python (2 или 3);
- GPU (опционально, для более быстрого обучения).
Шаг 1: Устанавливаем TensorFlow с их официального сайта. Также скачиваем репозиторий и сохраняем его у себя на компьютере.
Шаг 2: Скачиваем набор данных (Cornell Movie-Dialogs Corpus) и переносим его в свою рабочую директорию.
Шаг 3: Создаем обучающие данные, запустив команду.
python preprocessors/preprocess_movie_dialogs.py --raw_data movie_lines.txt \ --out_file preprocessed_movie_lines.txt
Также создаем файлы для проверки, тестирования и обучения и сохраняем их в текущей рабочей директории.
Шаг 4: Теперь обучаем нашу модель:
python correct_text.py --train_path /movie_dialog_train.txt \ --val_path /movie_dialog_val.txt \ --config DefaultMovieDialogConfig \ --data_reader_type MovieDialogReader \ --model_path /movie_dialog_model
Шаг 5: Для обучения требуется время, после можно переходить к тестированию:
python correct_text.py --test_path /movie_dialog_test.txt \ --config DefaultMovieDialogConfig \ --data_reader_type MovieDialogReader \ --model_path /movie_dialog_model \ --decode
2.3 Преобразуем мужские портреты в женские и наоборот, используя глубокое обучение
Прежде, чем я что-либо скажу по поводу приложения, просто давайте посмотрим на следующие результаты:

Первое изображение было преобразовано во второе с помощью модели глубокого обучения! Это и вправду веселое приложение, предназначенное для демонстрации возможностей глубокого обучения. Основой приложения является сеть GAN (generative adversarial networks), которая является разновидностью модели глубокого обучения, способной к воспроизведению новых примеров.
Требования:
- Python (3.5+);
- TensorFlow (0.12+);
- GPU (опционально, для более быстрого обучения).
Предупреждение перед тем, как вы начнете делать это. Обучение модели занимает очень много времени, если вы не используете GPU. Даже при использовании высокотехнологичных GPU, например, Nvidia GeForce GTX 1080, процесс обучения занимает 2 часа для одного изображения.
Шаг 1: Скачиваем и сохраняем репозиторий.
Шаг 2: Скачиваем “Align&Cropped изображения” из набора данных CelebA. Создаем папку “dataset” для набора данных и переносим все изображения в неё.
Шаг 3: Обучаем модель.
python3 dm_main.py --run train
После тестируем модель на нужном нам изображении.
python3 dm_main.py --run inference image.jpg
2.4 Создание бота, использующего метод проб и ошибок, для игры во Flappy Bird
Возможно, некоторое время назад вы играли во Flappy Bird. Для тех, кто не знает – это игра, вызывающая сильное привыкание, целью которой является достижение максимального результата путем обхода птичкой препятствий.
В данном приложении реализован бот для игры во Flappy Bird с помощью современных методов проб и ошибок.
Пример обученного бота:

Требования:
- Python (2 или 3);
- TensorFlow (0.7+);
- Pygame;
- Opencv-python.
Реализация довольно простая, так как имеются все составляющие.
Шаг 1: Скачиваем официальный репозиторий.
Шаг 2: Убеждаемся, что установлены все взаимосвязи, после запускаем команду, указанную ниже:
python deep_q_network.py
3. Другие весьма полезные ресурсы
Мы просмотрели просторы Интернета, чтобы понять возможности глубокого обучения. Каждый день выкладывается множество полезных материалов, которые помогут создать подобные приложения, поэтому не имеет значения, кто первый выложил тот или иной материал!
Здесь просто собраны полезные ссылки и ресурсы:
- Сборник приложений глубокого обучения, написанный Károly Zsolnai-Fehér
- Создание искусственного художника
- Создаем игрушечного бота, самоуправляемого авто вместе с Mario Kart
- 9 прикольных приложений с использованием глубокого обучения (YouTube-канал: Two Minute Papers)
- 10 еще более прикольных приложений с использованием глубокого обучения (YouTube-канал: Two Minute Papers)
- 10 точно прикольных приложений с использованием глубокого обучения (YouTube-канал: Two Minute Papers)
- Список стартапов по глубокому обучению
- Список отличных проектов с использованием глубокого обучения
Заключение
Я надеюсь, вам было весело при прочтении данной статьи. Я уверен, что данные приложения мотивируют вас. Кто-то из вас знал об этих приложениях, кто-то нет. Если вы работали с данными приложениями, то поделитесь своим опытом. Уверен, что многие читатели определенно хотели бы узнать об этом.
А если вы столкнулись с данными приложениями впервые, то обязательно поделитесь полученными впечатлениями.
Другие статьи по теме
Основы машинного обучения за неделю
Ссылка на оригинальную статью
Перевод: Александр Давыдов
Комментарии