

Содержание
- Git.
- Алгоритмы.
- Алгоритмы на графах.
- Рекурсия.
- SQL и базы данных.
- Агрегационные функции.
- Docker.
- Структуры данных.
1. Git

Работая в команде над одним проектом, вы наверняка столкнетесь с Git. Git — это система управления версиями, которая помогает отслеживать историю изменений файлов.
Нужно знать:
- GIT, удаленный и локальный репозитории.
- понятие ветки.
commit,push,pull.merge request,pull request.- команды
mergeиrebase.
2. Алгоритмы
Следующий момент связан с алгоритмами. На большом количестве данных, задачи, решенные с помощью алгоритмов, будут выполняться быстрее и съедать меньше вычислительных ресурсов по сравнению с заново изобретенным велосипедом.
Нужно знать:
- Что такое О-нотация, обозначающая сложность алгоритма, который мы оцениваем.
- Что такое алгоритмическая сложность.
- Алгоритмы сортировки: пузырьком, слиянием, выборка.
Заучивать алгоритмы не нужно. Поймите концепции сортировки и научитесь оценивать сложность алгоритма — пригодится на собеседовании.
Рекомендую книгу «Грокаем алгоритмы», где простым и доступным языком знакомят с алгоритмами.
3. Алгоритмы на графах
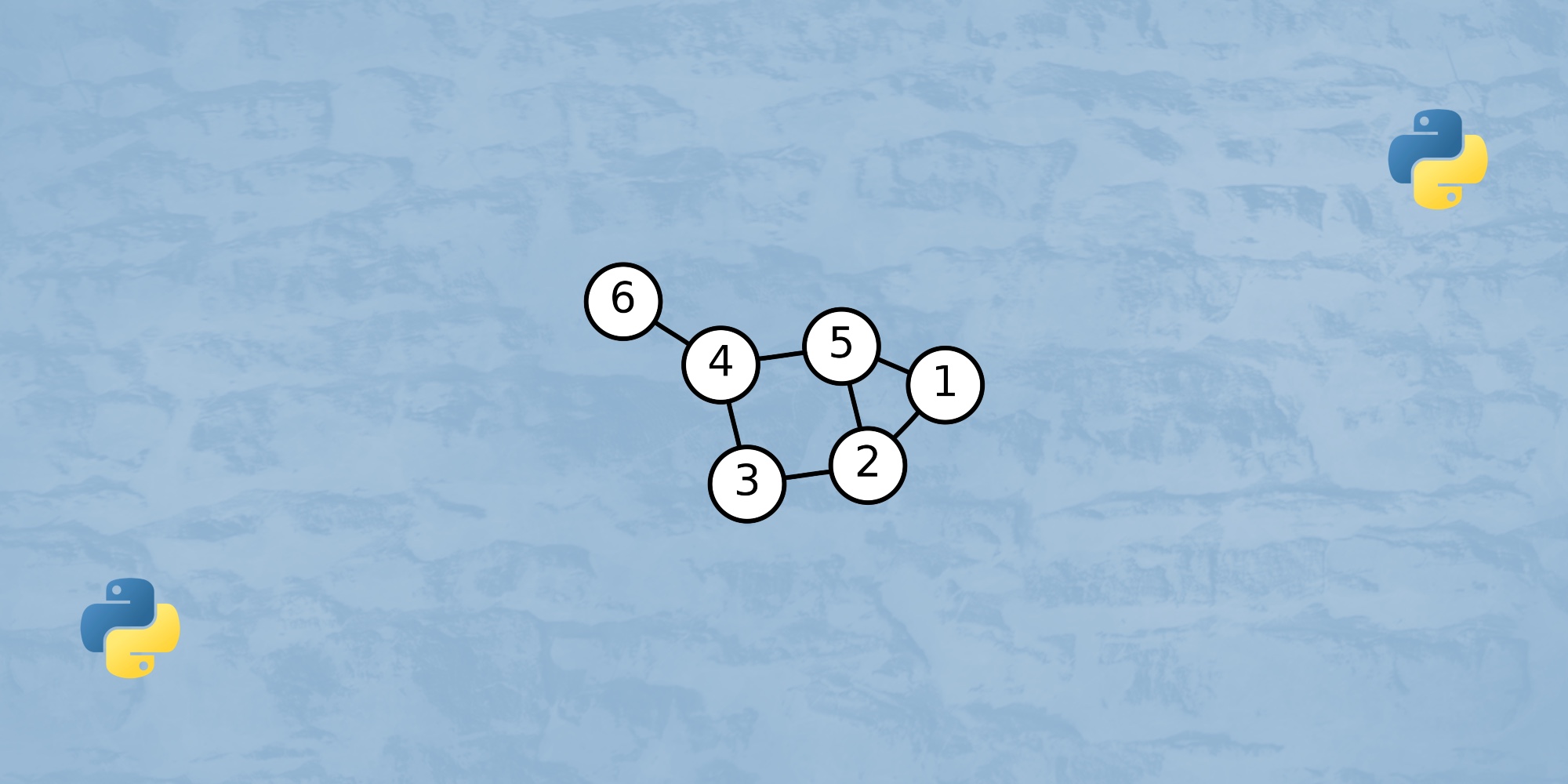
Нужно знать:
- Поиск в ширину.
- Поиск в глубину.
- Алгоритм Дейкстры.
Допустим, мы пишем простой файловый менеджер, которой проходит по директориям и смотрит, какие файлы в них расположены. Это пример классического поиска в глубину или в ширину, в зависимости от того, в какую сторону решаем задачу. Или пишем скрипт, удаляющий или создающий файлы по какому-то условию — это как раз классическая задача поиска в глубину. Чтобы не изобретать велосипед, выучите алгоритмы.
4. Рекурсия

Как сказано в книге «Грокаем алгоритмы»: «Любой цикл можно заменить рекурсией и любую рекурсию можно заменить циклом». Цикл и рекурсия — взаимозаменяемые вещи и нужно понимать, что рекурсию сложнее писать и поддерживать, но бывают ситуации, когда цикл писать также сложно и проще написать функцию, которая вызывает саму себя.
Классический пример применения рекурсии – знакомые нам из предыдущего пункта алгоритмы для обхода графов.
Здесь нужно помнить об ошибке предельной глубины рекурсии и затратах памяти.
5. SQL и базы данных

Нужно знать:
- Реляционную базу данных.
- NOSQL.
- Вы должны знать простые команды на создание, изменение и удаление таблицы.
- Простые выборки по колонкам с условием:
select, где вы указываете перечень колонок, из которых вы делаете этотselectи пишете условие where.
Когда использовать реляционную БД и NOSQL:
- Если задачи решаются с помощью join между таблицами, то здесь лучше использовать только реляционные БД, либо сразу два вида БД на проекте.
- Если задачи связаны с частым изменением структур данных — NOSQL.
6. Агрегационные функции

Досконально знать их, наверное, не нужно. Достаточно понимать, что такое groupby, count, sum, average и уметь объяснить, как они работают и где они могут пригодиться. Классический пример — посчитать среднее значение в колонке по месяцам. Вы можете использовать агрегационную функцию, сводящую все к одному значению и использовать группировку в рамках месяца.
Следующий момент — join’ы, позволяющие делать стыки таблиц с таблицами, делать оттуда подселекты и получать информацию, которая связывает одну таблицу и другую таблицу, при этом не имея между собой никаких связей через какую-нибудь третью таблицу.
Я не отношу сюда оконные функции, так как это считается высшим пилотажем в SQL. Да и они редко встречаются в моей работе.
7. Docker

Нужно знать:
- Что такое образ, контейнер.
- Сеть докера.
- Тома докера.
- Написание файлов Docker Compose.
Если вы не будете понимать разницу между докером и контейнером, вы не будете понимать, как это все работает на базовом уровне. Образ поднимает отдельный процесс, который является самим контейнером.
Обращаться к контейнерам, вы, скорее всего, будете с помощью внешних запросов и без понимания того, как настраивается сетка для докеров, вам будет тяжело это сделать: вы будете брать какие-то готовые решения и, кроме номера порта, вы вряд ли сможете что-либо изменить.
О томах: если вы хотите, чтобы после удаления контейнера данные не пропадали из базы, смонтируете место на жестком диске, куда данные будут сохраняться.
8. Структуры данных

Нужно знать, что такое:
- Массив и множество.
- Хеш-таблица.
- Стек, дек и очередь.
- Связанный список.
- Графы.
Это основные структуры данных, с которыми нужно быть знакомыми, чтобы понимать, где, например, быстрее происходит поиск.
Общие моменты
Нужно знать:
- Чем отличается интерпретатор от компилятора.
- Что такое программа в целом и из чего она состоит: операнды, выражения, блоки выражений и т. д.
- Что такое IDE и зачем она нужна. Я рекомендую Jupyter Notebook, PyCharm или VScode
- Популярные форматы передачи данных: xml, json и yaml. Вне зависимости от направления, в которое вы пойдете, с ними вы будете сталкиваться постоянно, т. к. практически вся информация по сети гоняется в виде xml и json.
Комментарии