
О структурах данных
Представьте, что вы создали очень популярное приложение, число пользователей которого быстро приближается к миллиону. Хотя пользователям нравится приложение, они жалуются, что оно работает медленно, из-за чего некоторые пользователи покидают ваш сервис.
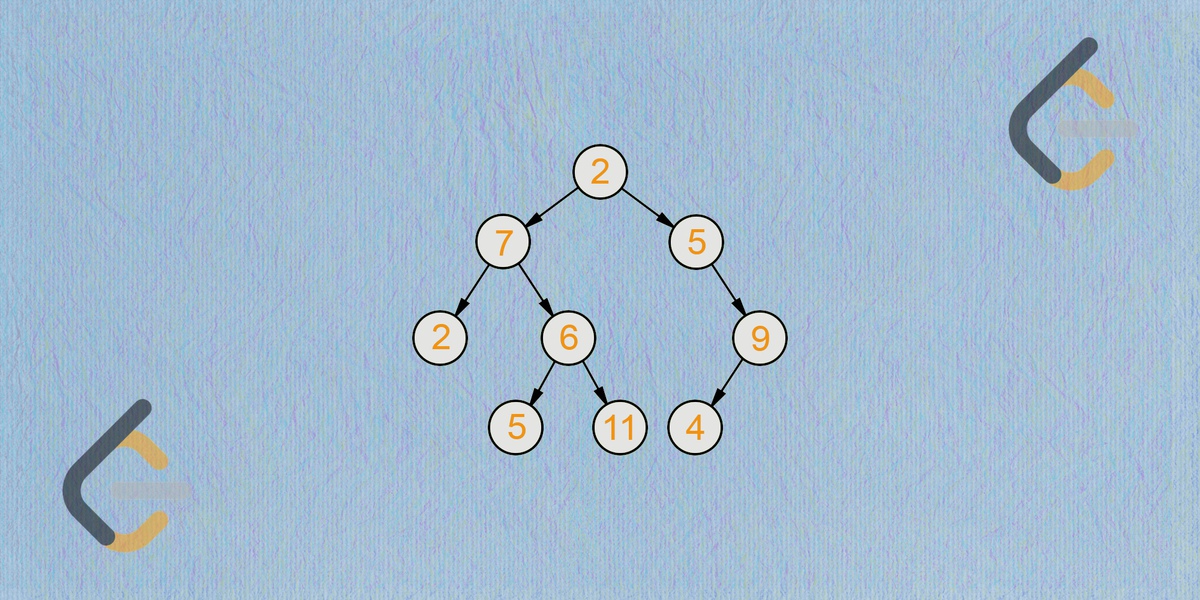
Вы решили разобраться, в чем проблема и заметили, что основным узким местом является способ получения информации о пользователе при аутентификации. Ваше приложение ищет запрашиваемый идентификатор пользователя внутри несортированного списка словарей Python до тех пор, пока идентификатор не будет найден. Именно это создает проблему.
Попытаемся понять, что мы можем сделать. Как мы можем хранить идентификаторы пользователей таким образом, чтобы получить любой из них как можно быстрее? В этом случае может помочь сортировка списка. Однако, если мы каждый раз будем искать id с самого начала, то столкнемся с тем, что новые клиенты с большим количеством идентификаторов будут проходить множество шагов для аутентификации. Если мы попытаемся начать поиск с конца списка, тогда клиенты, которые были с нами с самого начала, будут в низком приоритете.
Более эффективный подход заключается в том, чтобы расположить данные о пользователях в виде двоичного дерева поиска, что позволит нам найти любой из миллиона идентификаторов значительно быстрее. Версия этой структуры данных является одним из способов индексирования записей внутри базы для быстрого поиска. Постепенный перенос информации пользователей в базу данных снижает задержку приложения.
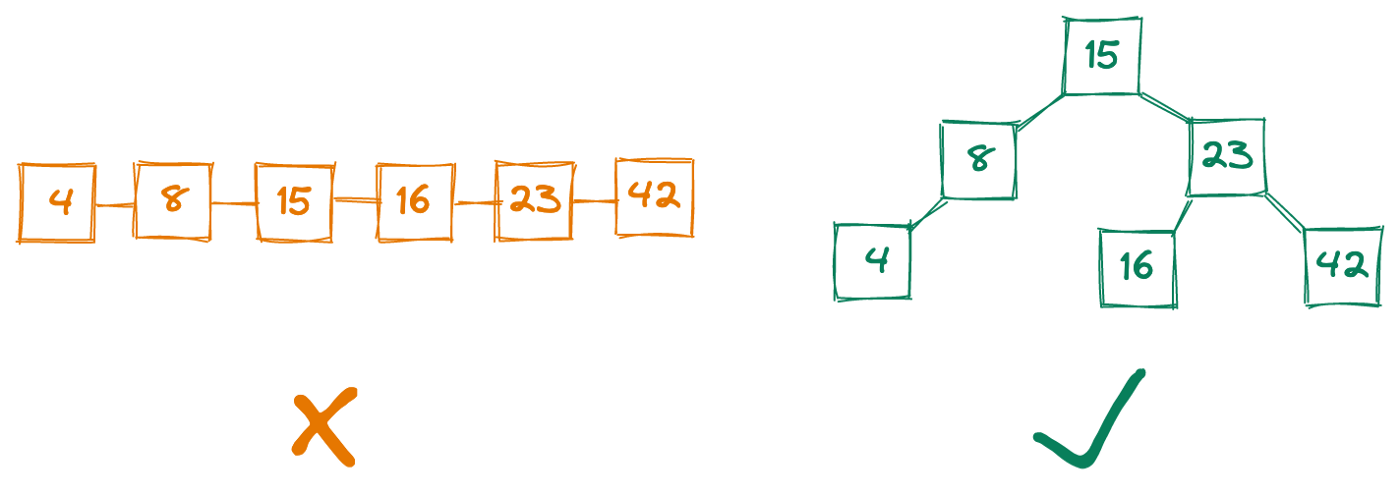
Структуры данных, которые используют программы из примера выше, определяют, будет ли код масштабироваться по мере роста объема данных. Или придется переписывать все с нуля каждый раз, когда количество пользователей будет увеличиваться?
Выбор правильных структур данных имеет решающее значение для масштабируемого кода. От этого зависит все: быстрый поиск кратчайшего пути между локациями, постоянное обслуживание приоритетных элементов в регулярно меняющемся списке, мгновенное и безопасное подтверждение корректно введенного пароля.
Прежде чем приступить к изучению структур данных, необходимо понять, что это такое и как их сравнивать. Начнем с изучения различий внутри структур данных и их назначения – абстрактных типов данных. Далее расскажем про Big O нотацию – метрику для сравнения скорости операций над структурами данных и пройдемся по основным типам данных, которые хранятся внутри структуры данных.
Необходимо понять, что не существует «идеальной» структуры данных, потому что её полезность полностью зависит от того, как она используется. Исходя из этого важно определить потребности вашей программы, чтобы подобрать подходящий инструмент для работы.
Структуры данных vs абстрактные типы данных
В программировании, как и в реальной жизни, существует множество способов выполнения задачи. Допустим, вы хотите выкопать яму. В вашем распоряжении есть вилы, молоток, пила и лопата. Каждый инструмент можно рассматривать как «структуру данных» в том смысле, что он является конкретным средством для решения проблемы.
Однако, если отделить задачу от способа ее выполнения, вы увидите, что данные инструменты выполняют роль «средства для копания» и являются абстрактным типом данных. То, как вы на самом деле копаете, можно назвать структурой данных. Абстрактный тип данных – это теоретическая сущность, а структура данных – это ее реализация.
Рассмотрим еще один пример. Предположим, вы хотите навестить своего друга, живущего на другом конце города. В вашем распоряжении велосипед, автомобиль и ноги. Здесь транспортное средство – это абстрактный тип данных. То, как вы передвигаетесь – это структура данных.
Это различие важно, так как существует несколько способов выполнения задачи. У каждого из них свои плюсы и минусы, которые зависят от конкретной программы. Так, для рытья ям лучше всего подходит лопата. Однако, для перемещения по городу «правильная» структура данных зависит от внешнего контекста. Например, автомобиль является самым быстрым способом, но для него нужны дороги, тогда как наши ноги медленнее, но могут использовать любые маршруты.
Структура данных – это конкретный инструмент, который мы используем для выполнения задачи. Но нашего пользователя волнует только абстрактный тип данных. Вашего друга не беспокоит, как вы доберетесь до его дома, главное, чтобы вы пришли вовремя.
Еще один пример. Представьте, что вам нужно убрать чистое белье. Структурой данных с низким временем записи и высоким временем чтения будет стопка одежды. Добавление в эту стопку происходит быстро, но извлечение конкретного предмета происходит медленнее, так как приходится искать его в несортированном белье.
Альтернативным методом может быть аккуратное размещение одежды в комоде или шкафу. Этот метод имеет высокое время записи и низкое время чтения, поскольку потребуется больше времени, чтобы разложить одежду, но вы сможете быстрее получить доступ к любому предмету, который вы искали.

Данные примеры не далеки от стратегий сброса данных в AWS S3 по сравнению с базой данных или хранения данных в высокоструктурированной базе данных SQL по сравнению с гибкой базой данных NoSQL.
Big O нотация
Логично, что лопатой легче выкопать яму, чем молотком, но как оценить разницу в производительности? Количество секунд, которые мы потратим на то, чтобы вырыть яму – это хорошая метрика. При этом для работы с ямами разного размера нам нужен расчет времени, который учитывает объем и глубину. Есть и другие факторы, которые придется учесть. Такие, как разный размер лопат и возможности людей, которые копают. Бодибилдер с молотком может выкопать яму быстрее, чем ребенок с лопатой, но это не значит, что молоток – лучший инструмент для копания.
В компьютерных терминах эти два аспекта можно представить как объем обрабатываемых данных и как используемую машину. При сравнении того, насколько хорошо структуры данных выполняют какую-либо операцию, нам нужна метрика, которая количественно определяет, как производительность зависит от объема данных. Например, хранение новых данных или получение запрошенного элемента. Это не зависит от того, какую машину мы используем.
Для этого мы можем обратиться к нотации Big O, обозначаемой как O(⋅). Big O – это мера эффективности «в худшем случае», верхняя граница того, сколько времени потребуется для выполнения задачи, или сколько памяти для этого необходимо. Например, поиск элемента в несортированном списке имеет значение O(n). Для получения результата, возможно, вам придется перебрать весь список.
Вот еще один пример операции с временной сложностью O(n). При увеличении количества элементов в списке, печать каждого элемента в Python списке занимает больше времени. Если вы удваиваете количество элементов, то удваивается и их время вывода, которое растет линейно.
# сложность времени O(n)
def print_num(arr: list):
for num in arr:
print(num)
Если же мы выводим каждую пару элементов в массиве, то сложность становится O(n²). Массив из 4 элементов требует 16 шагов, массив из 10 элементов – 100 шагов и так далее.
# сложность времени O(n^2)
def print_pairs(arr: list):
for num1 in arr:
for num2 in arr:
print(num1, num2)
Алгоритм O(n²) не является идеальным. Нам нужен алгоритм, который работает в постоянном режиме. Или O(1), где время выполнения не зависит от объема данных. Например, печать случайного значения из массива всегда будет занимать одно и то же время, независимо от размера массива.
# время O(1)
def print_idx(arr: list, i: int):
print(arr[i])
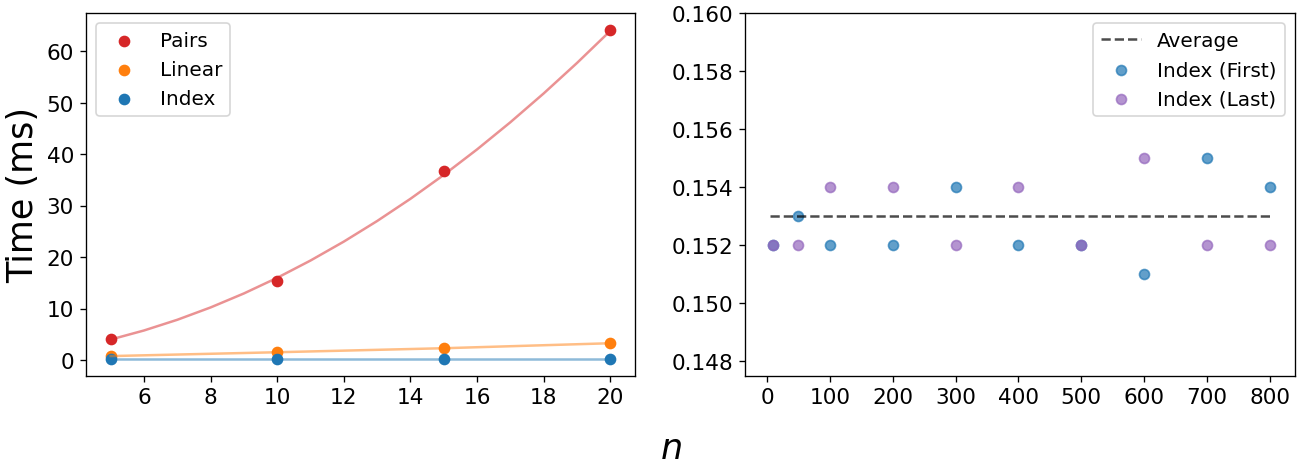
Можно количественно оценить эффективность этих функций с помощью команды %%timeit в Jupyter Notebook. Ниже видно резкое увеличение времени выполнения O(n²) print_pairs. Также видно силу функции O(1) print_idx, время выполнения которой колеблется около 0.153 мс, независимо от размера массива и от того, какой элемент запрашивается, первый или последний.
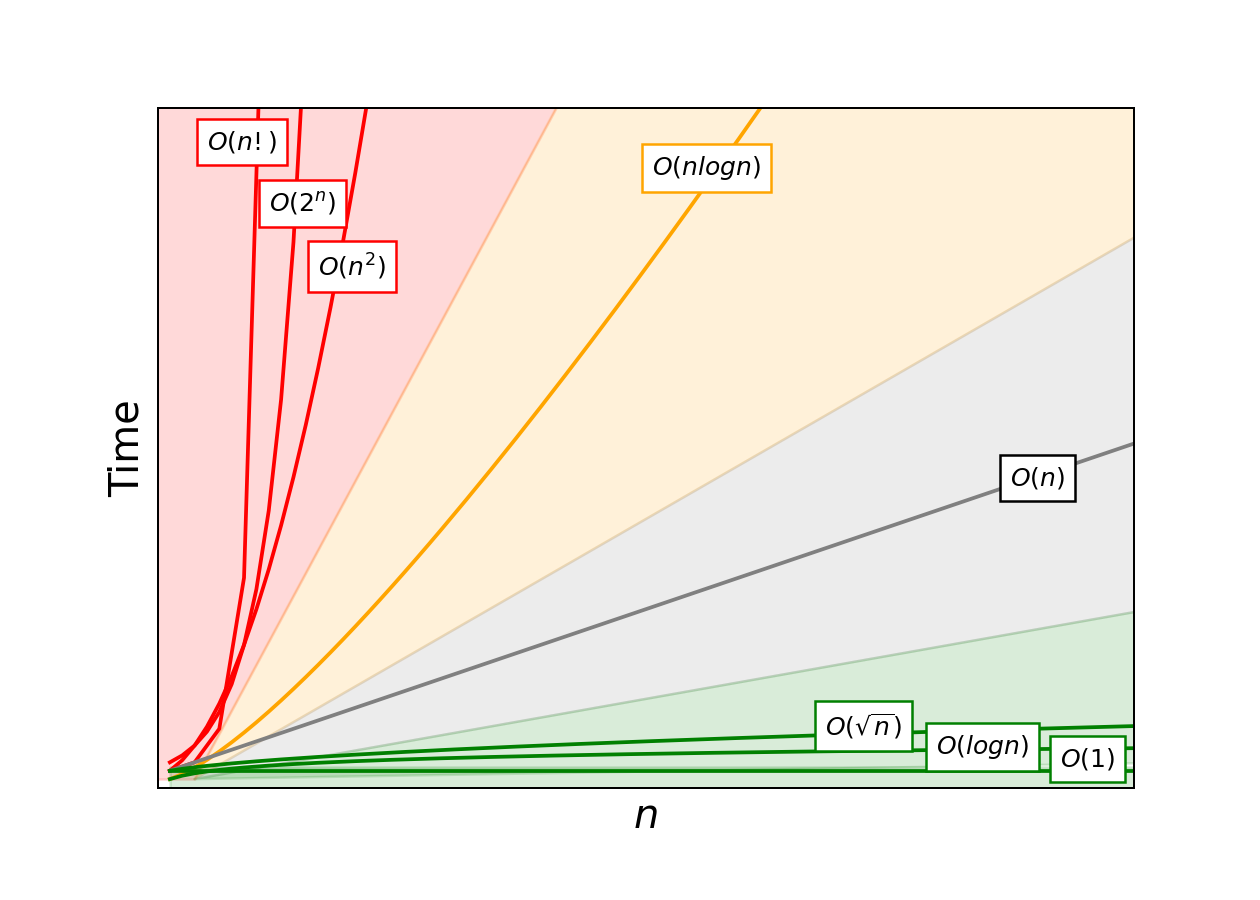
Можно использовать график, подобный приведенному ниже, чтобы сравнить, как масштабируются алгоритмы с различной эффективностью. Зеленая область является идеальной – это наиболее масштабируемое время выполнения, которое растет значительно медленнее, чем объем данных. Данные в серой зоне выглядят удовлетворительно. Ситуация в оранжевой зоне нежелательна. Того, что вы видите в красной зоне, лучше избегать.
Однако, для решения каких задач может потребоваться алгоритм из красной зоны? Они необходимы для решения задач, где требуется знать все возможные ответы на вопрос. Одним из таких примеров алгоритма O(2ⁿ) является поиск всех подмножеств массива. Каждый элемент множества может быть либо включен, либо исключен из подмножества. Набор из четырех элементов [A,B,C,D] будет иметь 2⁴ или 16 подмножеств:
- [], [A], [B], [C], [D]
- [A,B], [A,C], [A,D], [B,C], [B,D], [C,D]
- [A,B,C], [A,B,D], [A,C,D], [B,C,D]
- [A,B,C,D]
Худшее время выполнения у алгоритма O(n!), который представляет из себя перестановки – классический пример n-факторной сложности. Чтобы найти все возможные варианты расположения [A, B, C, D] мы начинаем с одной из четырех букв в первой позиции, затем одну из оставшихся трех во второй позиции и так далее. Таким образом, будет 4 × 3 × 2 × 1, или 24 перестановки:
- [A,B,C,D], [A,B,D,C], [A,C,B,D], [A,C,D,B], [A,D,B,C], [A,D,C,B]
- [B,A,C,D], [B,A,D,C], [B,C,A,D], [B,C,D,A], [B,D,C,A], [B,D,A,C]
- [C,A,B,D], [C,A,D,B], [C,B,A,D], [C,B,D,A], [C,D,B,A], [C,D,A,B]
- [D,A,B,C], [D,A,C,B], [D,B,A,C], [D,B,C,A], [D,C,A,B], [D,C,B,A]
Время выполнения этих задач быстро увеличивается. Массив из 10 элементов имеет 1024 подмножества и 3 628 800 перестановок. Массив из 20 элементов имеет 1 048 576 подмножеств и 2 432 902 008 176 640 000 перестановок.
Если ваша задача состоит в том, чтобы найти все подмножества или перестановки введенного массива, сложно избежать времени выполнения O(2ⁿ) или O(n!). Однако, если вы выполняете эту операцию более одного раза, есть несколько архитектурных трюков, которые можно использовать для уменьшения нагрузки.
Типы данных
Перейдем к фундаментальным типам данных. Если структура данных – это набор данных, возникает вопрос: какие типы данных должны быть в наших структурах? Есть несколько типов данных, универсальных для всех языков программирования:
- Целые числа (Integers), такие как
1,-5и256.
В других языках программирования (кроме Python) вы можете определить тип целого числа. Например, знаковое (+/-) или беззнаковое (только +), а также количество бит, которое может содержать целое число.
- Числа с плавающей запятой (Float) – это числа с десятичными знаками. Например,
1.2,0.14.
В Python к ним относятся числа, определенные с помощью научной нотации, такие как 1e5. В более низкоуровневых языках, например, C или Java, есть родственный тип double. Он обозначает дополнительную точность после запятой.
- Заголовки (Chars) – это буквы
a,b,c. Их набор – это строка, которая технически является массивомchars. Строковые представления чисел и символов, таких как5или?, тоже являются символами.
- Void – ноль, как
Noneв Python. Указывает на отсутствие данных. Это помогает при инициализации массива, который будет заполняться. Например, функция, которая выполняет действие, но ничего не возвращает. Такая, как отправка электронного письма.
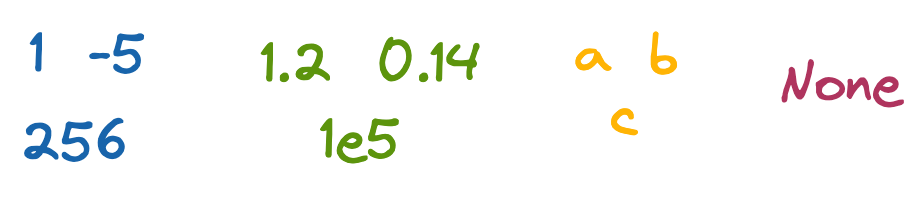
В следующей части материала мы приступим к изучению массивов и связанных списков.
Комментарии