
Если хочешь подтянуть свои знания, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в решение практических задач;
- узнаешь все про сложные алгоритмы, сортировки, сжатие данных и многое другое.
Ты также будешь на связи с преподавателем и другими студентами.
В итоге будешь браться за сложные проекты и повысишь чек за свою работу 🙂
Что такое алгоритм?
Алгоритм – это совокупность четко сформулированных инструкций, которые решают точно обозначенную задачу, если им следовать. Здесь решение задачи подразумевает преобразование входных данных в желаемый конечный результат. К примеру, сортировка – это задача упорядочивания последовательности чисел в порядке возрастания. Более формально мы можем определить эту проблему в виде входных и выходных данных: входными данными является любая последовательность чисел, а выходными – перестановка входной последовательности, при которой меньшие элементы располагаются перед большими. Алгоритм можно считать правильным, если для каждого из возможных входных данных он дает желаемый результат. Алгоритм должен быть однозначным, то есть инструкции должны быть понятными и иметь только единственное толкование. Алгоритм также не должен выполняться бесконечно и завершаться после конечного числа действий.
Важность алгоритмов в информатике трудно переоценить. Они позволяют программисту реализовать эффективные, надежные и быстрые решения за короткий промежуток времени. Почти любые сложные программы на современных компьютерах в значительной степени опираются на алгоритмы. Операционные системы пользуются алгоритмами планирования, которые организуют и распределяют процессорное время между процессами, создавая иллюзию, что они выполняются одновременно. Многие умные алгоритмы, такие как растеризация, отсечение, back-face culling и сглаживание, служат для создания потрясающих 3D-миров в реальном времени. Алгоритмы позволяют найти кратчайший маршрут к месту назначения в городе, содержащем тысячи улиц. Благодаря алгоритмам машинного обучения произошла революция в таких областях, как распознавание изображений и речи. Перечисленные алгоритмы – это только вершина айсберга, и изучение этого предмета откроет множество дверей в карьере программиста.
Пример алгоритма
Начнем мы наше путешествие в мир алгоритмов со знакомства с алгоритмом, который называется сортировкой вставками. Данный алгоритм является одним из многих методов решения ранее упомянутой задачи сортировки. Сортировка вставкой во многом напоминает то, как некоторые сортируют карты в своих руках. Представим, что у нас в руке имеются карты, которые уже отсортированы. Когда крупье передает нам новую карту, мы сразу кладем ее в правильное положение, чтобы карты оставались отсортированными. Мы повторяем это до тех пор, пока все карты не будут сданы. Концептуально сортировка вставкой делит массив на две части: отсортированную и неотсортированную. Поначалу отсортированная часть состоит только из первого элемента массива, а остальная его часть не отсортирована. Сортировка вставками на каждой итерации извлекает один элемент из несортированной части, определяет его местоположение в отсортированном списке и вставляет его туда. Этот процесс продолжается до тех пор, пока в несортированной части не останется ни одного элемента. Визуализация сортировки вставками:







Здесь отсортированный подмассив выделен синим цветом. Данная диаграмма не показывает, как именно сортировка вставками перемещает элементы из несортированного подмассива в сортированный. Она вставляет элемент в отсортированный подмассив следующим образом:
- Сохраняет значение элемента во временной переменной;
- Перемещает все элементы, которые больше чем вставляемый элемент (расположенные перед этим элементом) на одно место вправо;
- Помещает значение временной переменной в освободившееся место.
Давайте подробнее рассмотрим этот процесс на примере:

Здесь, единственный элемент, который осталось вставить в отсортированный подмассив – это 4. Мы сохраняем это значение во временною переменную.

Мы сравниваем 4 с 7, и поскольку 7 больше, мы копируем его на позицию справа (значения, которые мы сравниваем с вставляемым элементом, обозначены фиолетовым).

Сравниваем 4 с 6, и поскольку 6 больше, копируем его на позицию справа.

Сравниваем 4 с 5, а поскольку 5 тоже больше чем 4, его тоже копируем его на позицию справа.

Наконец, мы сравниваем 4 с 3, и так как 3 меньше чем 4, мы присваиваем значение временной переменной на позицию рядом с ним. И теперь наша работа выполнена; мы расположили 4 в правильное положение.
Как правило, программисты описывают алгоритмы в виде псевдокода. Псевдокод – это неформальный способ описания алгоритмов, который не имеет строгого синтаксиса, свойственного языкам программирования и не требует соблюдения технологических соображений. Приведем пример псевдокода сортировки вставками:
n ← Array.size
For i=2 to n
j ← i – 1
temp ← Array[j]
While Array[j-1]>temp and j>0
Array[j] ← Array[j-1];
j ← j-1
Array[j] ← temp
Написание алгоритмов в псевдокоде порой бывает полезным, но поскольку эти статьи посвящены алгоритмам на C++, в дальнейшем мы сосредоточимся на реализации алгоритмов на C++. Пример программы на C++, которая реализует сортировку вставками:
void insertionSort(int *array, int n)
{
for(int i=2;i<=n;++i)
{
int j=i-1;
int temp = array[j];
while(array[j-1]>temp)
{
array[j]=array[j-1];
--j;
}
array[j]=temp;
}
}
Основы анализа
Разработав алгоритм для решения задачи, нам необходимо определить, сколько ресурсов, таких как время и память, он потребляет. Ведь если алгоритму требуются годы для получения правильного результата или он занимает сотни терабайт, то на практике он непригоден. Также, алгоритмы, решающие одну и ту же задачу, могут потреблять разное количество ресурсов в зависимости от входных данных, поэтому при выборе алгоритма необходим тщательный анализ.
При изучении алгоритмов мы редко обращаем внимание на детали реализации языков программирования и компьютеров. Учитывая, насколько быстро развивается компьютерная индустрия, такие детали постоянно меняются. С другой стороны, алгоритмы сами по себе неподвластны времени. Следовательно, нам нужен метод оценки производительности алгоритма в независимости от компьютера, на котором он работает. Два основных средства, используемые нами для этой цели, это – абстрактная модель машины (компьютера) и асимптотический анализ.
Абстрактная модель машины
В процессе анализа алгоритмов мы представляем, что выполняем их на простой гипотетической компьютерной модели. Как и все современные компьютеры, наша модель выполняет инструкции последовательно. Модель поддерживает ряд простых операций, таких как сложение, вычитание, умножение, присвоение, сравнение, доступ к памяти и т.д. Но в отличие от текущих компьютеров, все эти простые операции занимают одну единицу времени. Поэтому время работы алгоритма эквивалентно количеству выполняемых им примитивных операций. Также предполагается, что машина имеет бесконечную память, а целые числа имеют фиксированный размер. Время, необходимое для завершения цикла, пропорционально количеству итераций умноженному на стоимость итерации.
Асимптотический анализ
Когда представлены два алгоритма, решающие одну и ту же задачу, и нам нужно определить, какой из них быстрее, один из возможных способов – реализовать эти алгоритмы, запустить их с разными входными данными и измерить время выполнения. Но это не лучшее решение, поскольку один алгоритм может быть быстрее при небольшом количестве входных данных и медленнее при большем. Чтобы точно проанализировать производительность, программисты спрашивают, как быстро увеличивается время выполнения при увеличении входных данных. Например, когда размер входных данных удваивается, увеличивается ли время работы пропорционально? Или оно увеличивается в четыре раза, а может быть, даже экспоненциально?
Те же вопросы можно задать и о производительности алгоритма в различных условиях. Для большинства алгоритмов размер входных данных не является единственным фактором, но особенности входных данных также влияют на время выполнения. В качестве примера можно привести линейный поиск. Это простой алгоритм для нахождения элемента в списке. Он последовательно проверяет каждый элемент списка до тех пор, пока не обнаружит совпадение или пока не просмотрит весь список. Очевидно, что время работы этого алгоритма может резко отличаться для списков с одинаковым размером n. В лучшем случае, если искомый элемент является первым в списке, алгоритму требуется только одно сравнение. С другой стороны, если в списке отсутствует нужный элемент или он оказался последним, алгоритм выполнит ровно n сравнений. В целом, при анализе используется один из следующих двух подходов: либо можно считать входные данные случайными и анализировать среднюю производительность, либо мы можно подобрать худшие входные данные и исследовать наихудшую производительность. В этой серии статей мы будем придерживаться анализа наихудшего случая, поскольку это гарантирует, что для любого примера входных данных размера n время работы не превысит полученного предела. Кроме того, как мы определяем "средние" данные, может повлиять на результат анализа.
«O» большое
Эти правила просты в применении, несмотря на кажущуюся формальность. Мы применим каждое из этих правил на практике, чтобы облегчить их усвоение.
Пример правила 1: Взгляните на реализацию алгоритма, который вычисляет сумму всех элементов в массиве, на языке C++.
int sum(int* array, int n)
{
int sum = 0;
for(int i=0;i<n;++i)
{
sum+=array[i];
}
return sum;
}
Пример правил 2 и 3: Приведенная ниже программа складывает две квадратные матрицы.
void matrixAddition(int** m1, int** m2, int** dest, int n)
{
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
dest[i][j]=m1[i][j]+m2[i][j];
}
}
}
Пример правил 4 и 5: Обратите внимание на программу ниже
void function(int** dest, int n)
{
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
dest[i][j]=1;
}
}
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
for(int k = 0; k < n; ++k)
{
dest[i][j]=2;
}
}
}
}
Часто встречающиеся функции времени выполнения
В этом разделе мы рассмотрим несколько наиболее распространенные функции времени выполнения, которые встречаются при анализе алгоритмов. Знакомство с этими функциями даст вам хорошее представление об особенностях различных времен выполнения и поможет определить, является ли сложность вашего алгоритма приемлемой.
void displayPairs(int* array, int n)
{
int count = 0;
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
count++;
cout<< "Pair #"<<count<<':'<< array[i] <<'-' << array[j] <<endl;
}
}
}
Визуализация функций
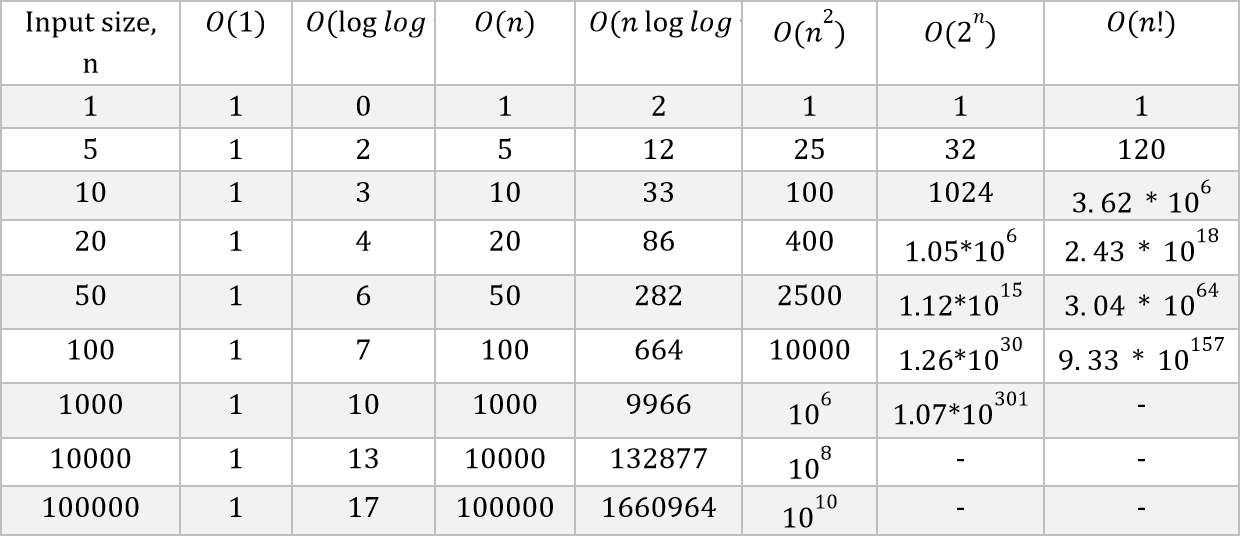
Визуализация функций времени выполнения вам наглядно покажет, почему выбор алгоритма с оптимальной сложностью имеет такое большое значение. В таблице ниже приведены несколько значений для функций, описанных в предыдущем разделе.
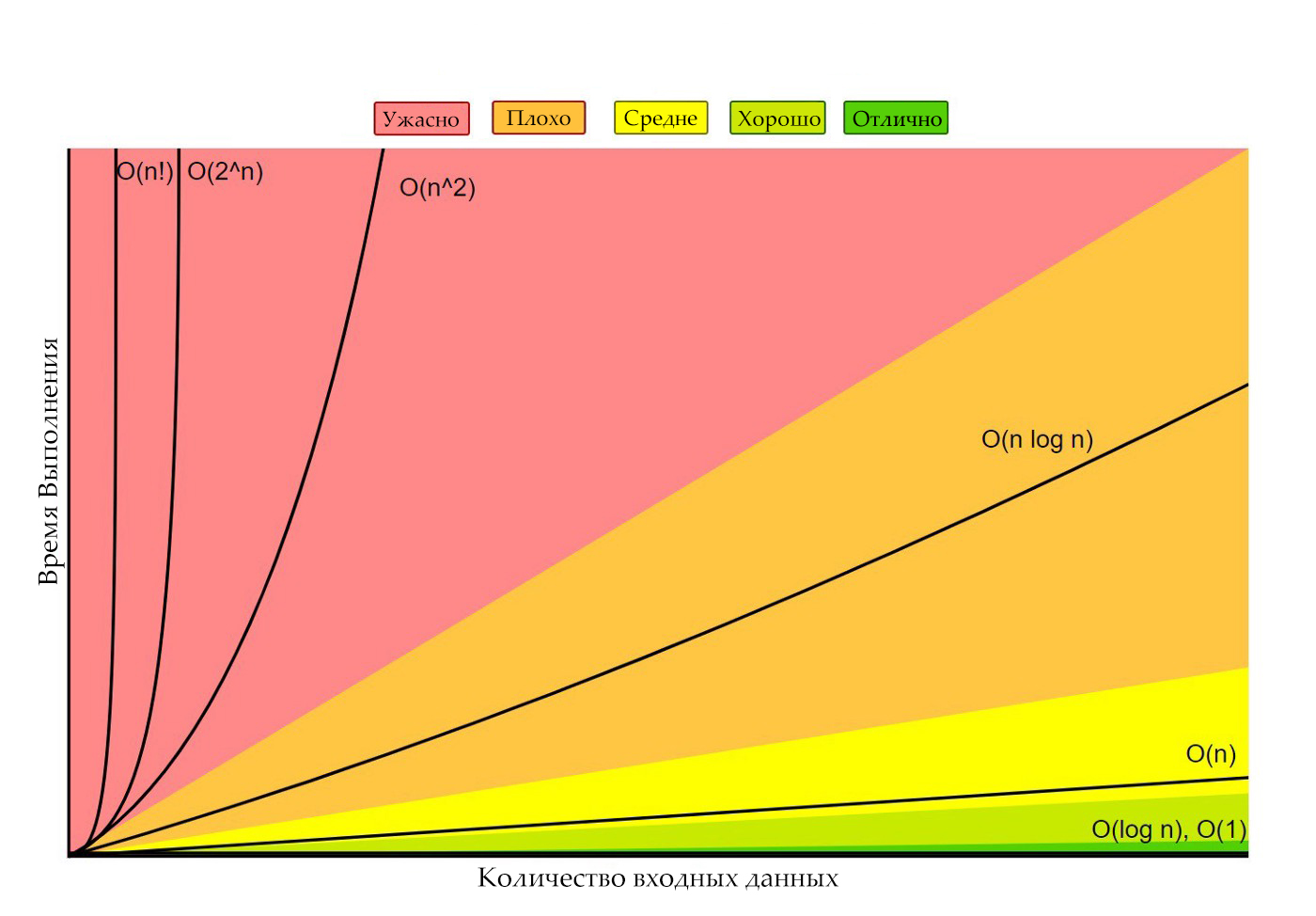
На приведенном ниже изображении показаны графики распространенных функций времени выполнения.
Заключение
Чтобы извлечь
максимальную пользу из алгоритма, необходимо понимать не только то, как он
работает, но и его производительность. В этой главе мы объяснили нотацию
Большого О, которая используется для анализа производительности алгоритма. Если
вам известно, как выглядит асимптотическое время работы алгоритма, вы можете
оценить, насколько изменится время работы при изменении размера задачи.
Комментарии