

Любой, кто применял Python для работы с данными, знаком с библиотекой Pandas – мощным пакетом обработки больших данных с их представлением в табличном виде. Установить Pandas проще всего через терминал:
pip install pandas
Посмотрим, какую статистику можно определить по умолчанию:
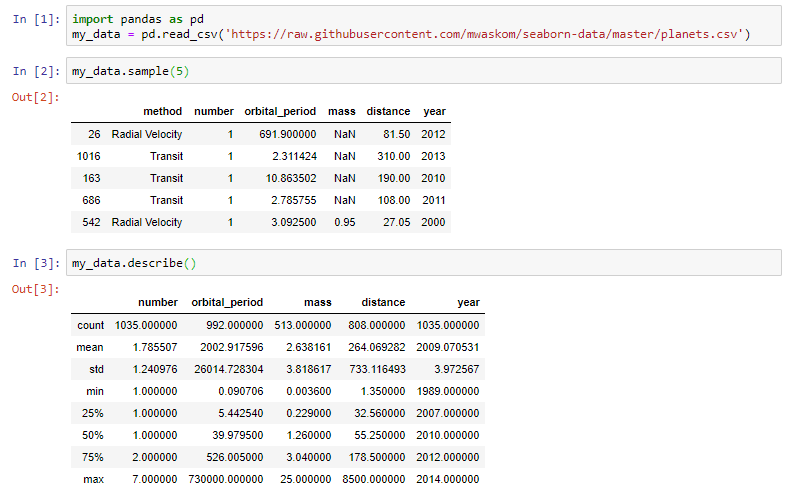
Метод describe есть у любого датафрейма Pandas, создаваемого, например, при вызове read_csv. Однако можно видеть, что метод describe не принимает в расчет категориальные признаки. В нашем примере это столбец method. Мы можем добиться гораздо большего.
Профилирование Pandas
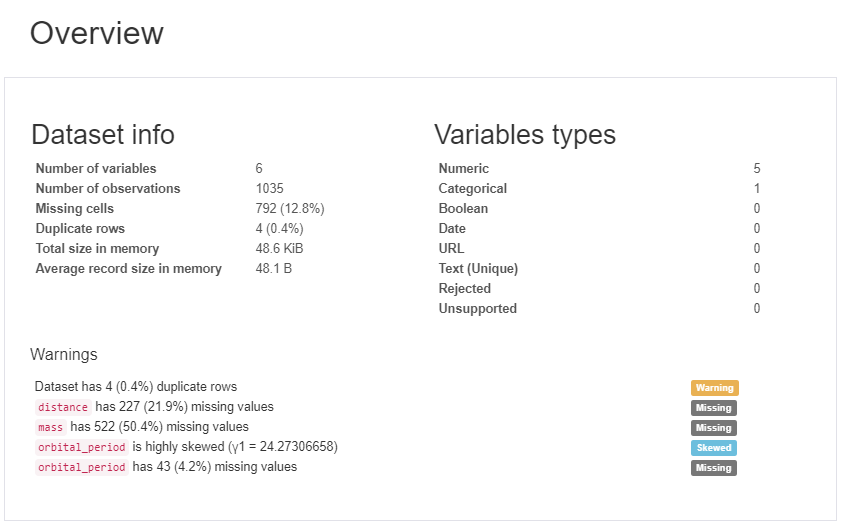
Достаточно всего трех строк на Python, чтобы получить статистику вроде той, что приведена на рисунке. А если не учитывать простейший импорт библиотек, то хватит всего одной строки. В результате вы получаете:
- Сводка по основным характеристикам: типы, уникальные значения, пропущенные значения.
- Статистика квантилей: минимальное и максимальное значения, Q1, медиана, Q3, межквартильный диапазон.
- Описательные статистические данные: среднее значение, мода, стандартное отклонение, среднее абсолютное отклонение, коэффициент вариации, коэффициенты асимметрии и эксцесса.
- Наиболее частые значения.
- Гистограмма.
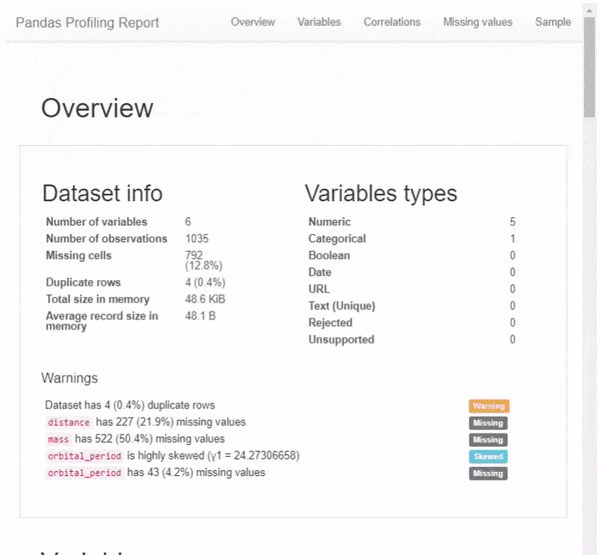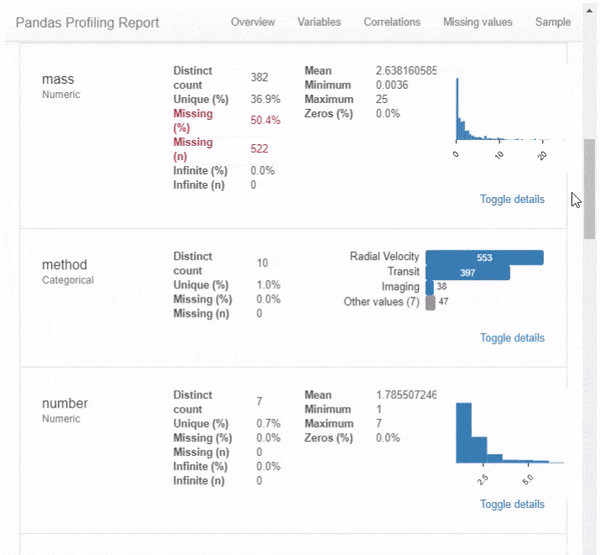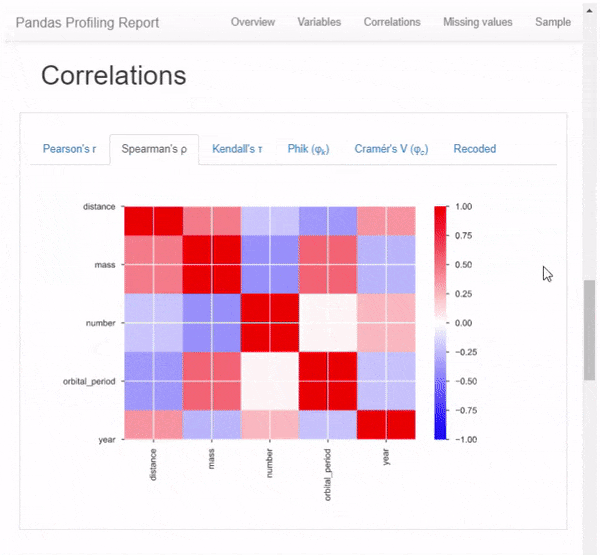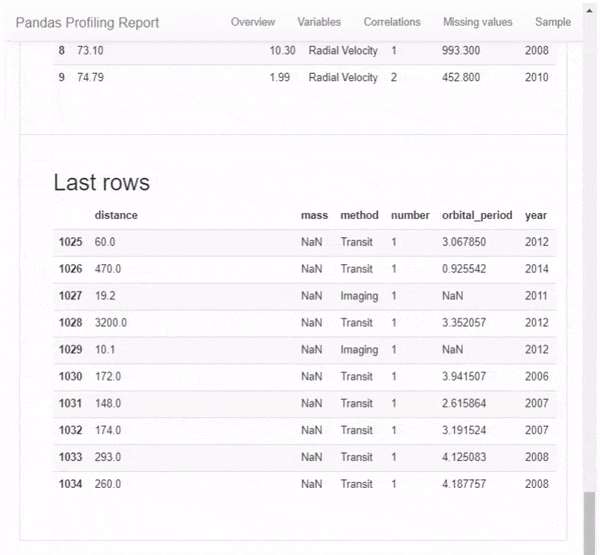
- Корреляции для высоко коррелированных переменных, матрицы корреляции Спирмена, Пирсона и Кендалла.
- Отсутствующие значения: матрица, счетчик, тепловая карта и дендрограмма отсутствующих значений.
Прочие функции перечислены на странице pandas_profiling. Именно так называется библиотека, которая так упрощает процесс анализа исходных данных. Установить ее можно так же, как и Pandas:
pip install pandas_profiling
Чтобы воспользоваться библиотеками, их нужно импортировать в Jupyter:
import pandas as pd
import pandas_profiling
А далее та самая единственная строка, чтобы проанализировать данные:
pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/planets.csv').profile_report()
В этой строке создается объект типа DataFrame и тут же профилируется с помощью метода profile_report.
Первое, что вы увидите, – это обзор данных, как на рисунке выше. Обзор дает высокоуровневую статистику по данным и переменным, а также предупреждения в случае высокой корреляции данных, асимметрии и т. д. Но и это не всё. Прокрутив вниз, вы обнаружите, что отчет содержит еще несколько разделов. Пример вы можете видеть на гифке ниже.
Итог
Резюмируем. Чтобы быстро проанализировать статистику датасета, достаточно выполнить два шага:
1. Установить две библиотеки:
pip install pandas
pip install pandas_profiling
2. Импортировать установленные библиотеки и запустить однострочник на Python:
import pandas as pd
import pandas_profiling
pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/planets.csv').profile_report()
Надеемся, этот простой трюк будет вам полезен.
Комментарии