
Зачем используется Apache Spark? В статье рассмотрим, какую проблему обработки больших объёмов данных решает этот фреймворк.
Цифровая вселенная
Данные повсюду вокруг нас. В IDC оценили размер «цифровой вселенной» в 4,4 зеттабайта (1 триллион гигабайт) в 2013 году. По наблюдениям, цифровая вселенная ежегодно увеличивается на 40%. К 2020 году IDC ожидает, что размер достигнет 44 зеттабайтов – хватит по одному биту данных на каждую звезду физической вселенной.

У нас много данных, и мы не избавляемся от них. Поэтому нужен способ хранения увеличивающихся объёмов данных в масштабе, с защитой от потери в результате аппаратного сбоя. Наконец, нужно средство обработки этой информации с быстрым контуром обратной связи. Спасибо космосу за Hadoop и Spark.
Чтобы продемонстрировать полезность Spark, начнём с примера. 500 ГБ выборочных данных о погоде включают:
Страна | Город | Дата | Температура
Для расчёта максимальной температуры по стране для этих данных начинаем с нативной программы на Java, поскольку Java – наш второй любимый язык программирования:
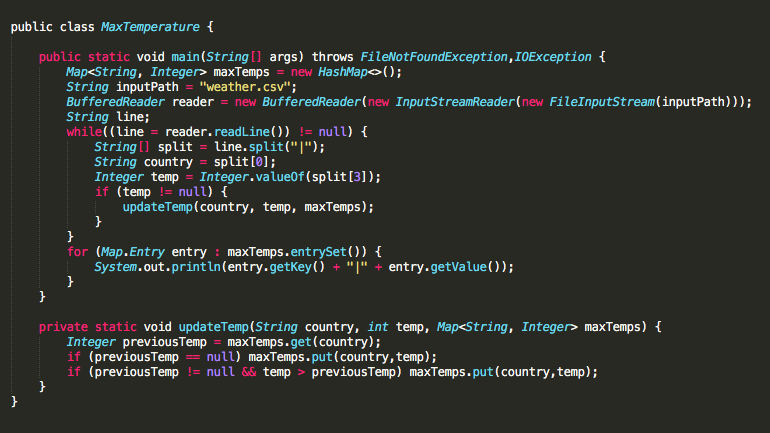
Однако при размере 500 ГБ даже такая простая задача займёт 5 часов с использованием этого нативного Java-метода.
«Java отстой, напишу это на Ruby и круто, если быстро, Ruby – мой любимый»
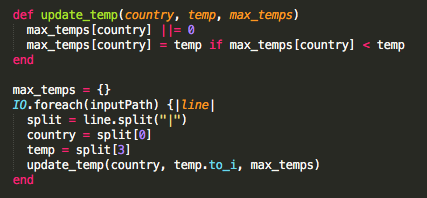
Однако любимый Ruby больше не подходит для этой задачи. Ввод-вывод – не сильная сторона Ruby, поэтому Ruby потребуется ещё больше времени на поиск максимальной температуры, чем Java.
Задачу поиска максимальной температуры по городам лучше решить с помощью Apache MapReduce (держим пари, вы подумали, что скажем Spark). Конкретно здесь MapReduce блистает. С преобразованием городов в ключи, а температур – в значения, получаем результаты за гораздо меньшее время - 15 минут, по сравнению с предыдущими 5+ часами в Java.
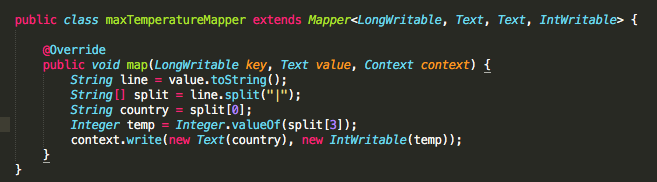
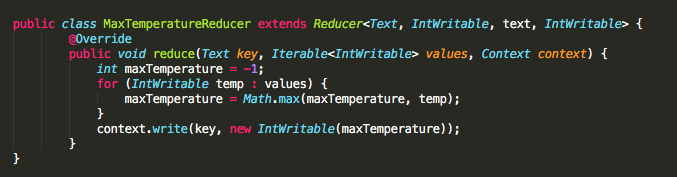
MapReduce – жизнеспособное решение поставленной задачи. Этот подход будет работать намного быстрее по сравнению с нативным решением Java, потому что MapReduce распределяет задачи между рабочими узлами в кластере. Строки из нашего файла передаются на каждый узел кластера параллельно, а в нативный Java-метод работает всего лишь поочередно.
Проблема
Вычислить максимальную температуру для каждой страны – по сути новая задача, но далеко не новаторский анализ. Данные реального мира несут в себе более громоздкие схемы и сложный анализ. Это подталкивает к использованию специальных инструментов.
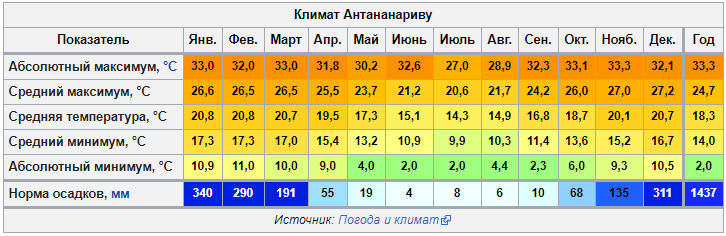
Что, если вместо максимальной температуры, нас попросят найти максимальную температуру по стране и городу, а потом разбить по дням? Что, если мы перепутали, и нужно найти страну с самыми высокими средними температурами? Или, если хотим найти среду обитания, где температура никогда не ниже 15°C и не выше 20°C (Антананариву, Мадагаскар, кажется привлекательной).
MapReduce справляется с пакетной обработкой данных. Однако отстаёт, когда дело доходит до повторного анализа и небольших циклов обратной связи. Единственный способ повторно использовать данные между вычислениями – записать их во внешнюю систему хранения (например, HDFS). MapReduce записывает содержимое всех Map для каждого задания – до Reduce-шага. Это означает, что каждое MapReduce-задание выполнит одну задачу, которая определена в его начале.
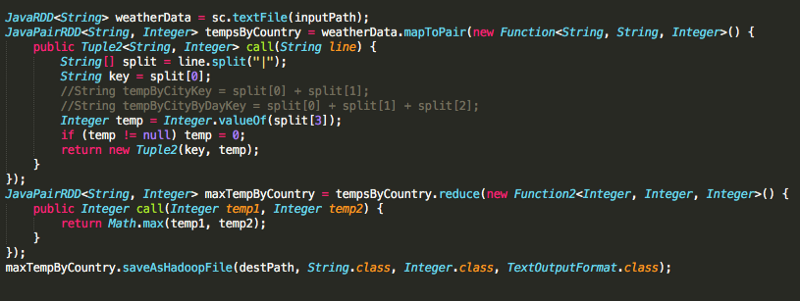
Для выполнения упомянутого выше анализа потребовалось бы три отдельных задания MapReduce:
MaxTemperatureMapper,MaxTemperatureReducer,MaxTemperatureRunnerMaxTemperatureByCityMapper,MaxTemperatureByCityReducer,MaxTemperatureByCityRunnerMaxTemperatureByCityByDayMapper,MaxTemperatureByCityByDayReducer,MaxTemperatureByCityByDayRunner.
Очевидно, что это легко выйдет из-под контроля.
Обмен данными в MapReduce происходит медленно из-за самой природы распределённых файловых систем: репликации, сериализации и, главное, дискового ввода-вывода. Приложения MapReduce тратят до 90% времени на чтение и запись с диска.
Столкнувшись с такой проблемой, исследователи решили разработать специальный фреймворк, который мог бы выполнять то, что MapReduce не может: вычисления в оперативной памяти на кластере подключенных машин.
Решение: Apache Spark

Spark решает эту проблему. Spark обрабатывает несколько запросов быстро и с минимальными издержками.
Три указанных выше маппера реализуются в одном и том же задании Spark. И выдают несколько результатов, если нужно. Закомментированные строки легко использовать для установки правильного ключа в зависимости от требований конкретного задания.
Spark ещё и выполняет обработку в 10 раз быстрее, чем MapReduce, при сопоставимых задачах, поскольку Spark работает только в оперативной памяти. Поэтому не используются операции записи и чтения с диска, как правило, медленные и дорогостоящие.
Apache Spark – удивительно мощный инструмент для анализа и преобразования данных. Если эта публикация пробудила в вас интерес, следите за обновлениями. Скоро будем постепенно углубляться в тонкости Apache Spark Framework.
Комментарии