

Что такое «Согласованность в конечном счете»?
Согласованность в конечном счете (или просто «конечная согласованность», eventual consistency) – исключительно важная концепция для распределенных систем, где разные части системы могут обрабатывать данные асинхронно.
Как работает конечная согласованность
В распределенных системах данные могут находиться на разных серверах, зачастую даже в разных дата-центрах. Когда происходят изменения, например, обновляется профиль пользователя, данные могут не синхронизироваться мгновенно во всех узлах системы. При конечной согласованности система гарантирует, что со временем все узлы придут к одному и тому же состоянию, но допускается временная рассогласованность.
Почему использование принципа конечной согласованности неизбежно
В любой масштабируемой распределенной системе применение механизма конечной согласованности практически неизбежно, так как мгновенная синхронизация всех узлов невозможна. Распределенные системы требуют времени для обмена данными, что приводит к задержкам в распространении обновлений между сервисами.
Преимущества паттернов конечной согласованности
Хотя конечная согласованность вводит временную несогласованность данных, она позволяет масштабировать систему, избегая строгих требований к синхронизации и снижая нагрузку на сеть. Для управления такими системами важно применять проверенные паттерны, которые упрощают достижение конечной согласованности и делают поведение системы предсказуемым.
Паттерны конечной согласованности
Рассмотрим самые распространенные шаблоны, с помощью которых можно реализовать конечную согласованность в распределенной системе.
Событийная конечная согласованность
Этот подход делает систему слабосвязанной, так как сервисы напрямую не взаимодействуют, а «слушают» события:
- Каждый сервис, в котором происходят изменения, отправляет сообщения (события) о произошедших изменениях другим сервисам.
- Другие сервисы подписаны на эти события и получают обновления, чтобы синхронизировать свои данные.
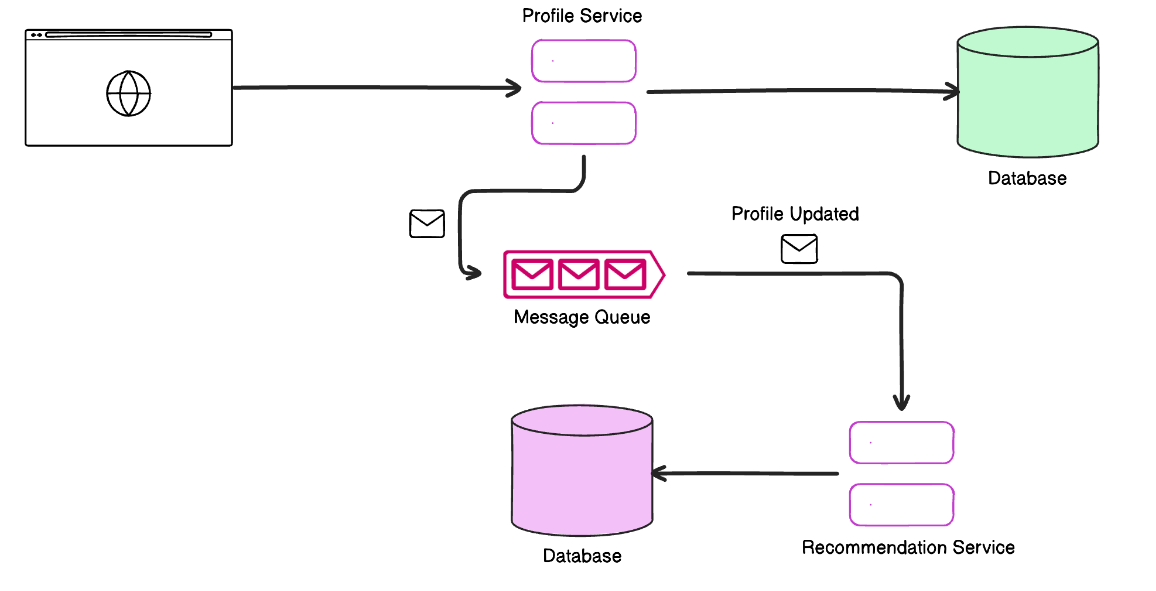
Пример: платформа электронной коммерции
- Один сервис управляет профилем пользователя (например, его предпочтениями).
- Другой сервис отвечает за рекомендации (например, подбор товаров, которые могут понравиться пользователю).
Когда пользователь обновляет свои предпочтения, сервис профиля отправляет событие, например обновление профиля. Сервис рекомендаций «слышит» это событие и обновляет свою базу данных в соответствии с новыми предпочтениями пользователя. Между моментом обновления профиля и моментом, когда рекомендации начинают учитывать эти изменения, есть небольшая задержка, что и приводит к конечной согласованности.
Плюсы событийного подхода
- Масштабируемость – сервисы не перегружают друг друга прямыми запросами, а просто отправляют события, которые обрабатываются в фоновом режиме.
- Гибкость – изменение логики одного сервиса не требует изменений в других, что упрощает модификацию системы.
- Надежность – если один из сервисов временно недоступен, он сможет обработать событие позднее, как только восстановится, и привести данные к актуальному состоянию.
Конечная согласованность с фоновой синхронизацией
В этом паттерне синхронизация данных происходит не в реальном времени, а через запланированные интервалы времени с помощью фонового процесса (или задачи), которая проверяет базы данных на наличие несогласованных данных и синхронизирует их. Этот подход полезен в тех случаях, когда:
- Добавление новых данных важнее, чем мгновенное обновление существующей информации.
- Основной сервис получает большое количество запросов, и нужно избежать перегрузки системы.
Поскольку данные синхронизируются через регулярные интервалы, возможны небольшие задержки между моментом внесения изменений и моментом, когда другие системы увидят эти изменения.
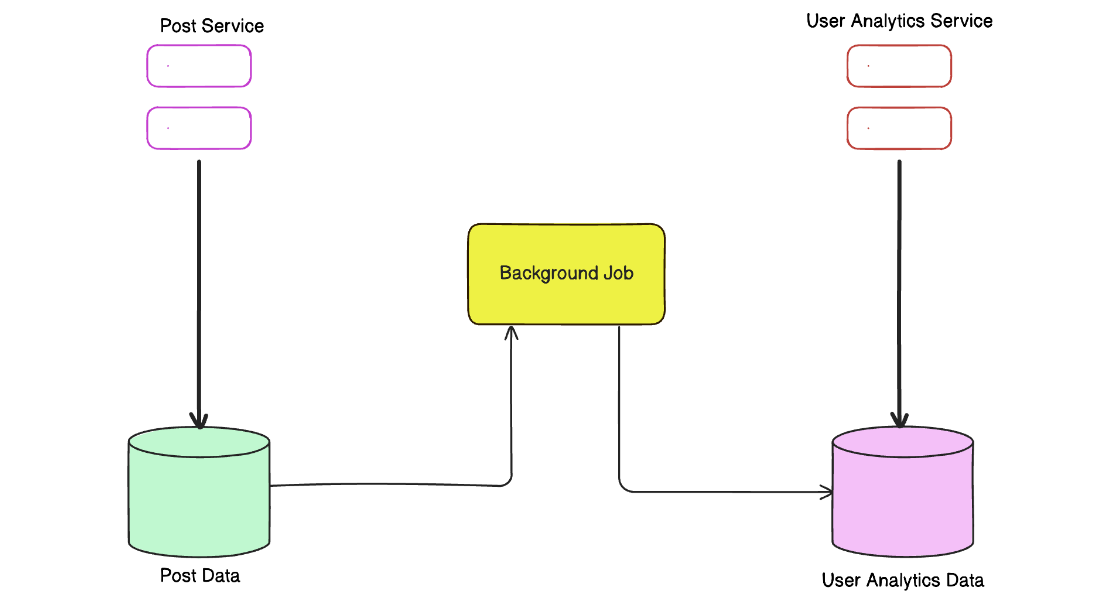
Пример: социальная сеть
- Посты пользователей и аналитика (например, количество постов, просмотров и т.п.) хранятся в разных базах данных.
- Когда пользователь публикует новый пост, информация о нем сразу сохраняется в базе данных постов, а аналитика остается временно несогласованной.
- Каждые несколько секунд (или минут) фоновая задача запускается и обновляет базу данных аналитики, добавляя информацию о новых постах.
Таким образом, пользователи могут увидеть, что новый пост появился мгновенно, но общее количество постов или данные аналитики обновятся лишь через несколько секунд/минут, когда запустится фоновый процесс синхронизации.
Плюсы фоновой синхронизации
- Высокая производительность – с точки зрения пользователей обновления данных выполняются быстро, так как нет необходимости сразу синхронизировать данные между всеми базами данных.
- Уменьшение нагрузки на систему – синхронизация с определенным интервалом позволяет разгрузить систему и не тратить ресурсы на мгновенное распространение обновлений.
- Простота реализации – фоновые задачи можно настраивать и планировать гибко, регулируя их частоту запуска в зависимости от требований к согласованности и производительности.
Фоновая синхронизация отлично подходит для приложений, где мгновенная синхронизация не является критически важной, и допускается небольшая задержка в актуализации данных.
Конечная согласованность на основе паттерна «Сага»
Этот паттерн помогает обеспечить согласованность данных в тех случаях, когда одна транзакция охватывает несколько сервисов. В отличие от классических транзакций, которые блокируют данные, пока не завершат все операции, «Сага» разбивает общую задачу на серию локальных транзакций. Каждая из них выполняется независимо и без блокировок. Если какая-то часть цепочки не выполняется, срабатывают компенсаторные действия, чтобы отменить изменения, уже внесенные на предыдущих шагах. В результате система достигает конечной согласованности, несмотря на возможные сбои.
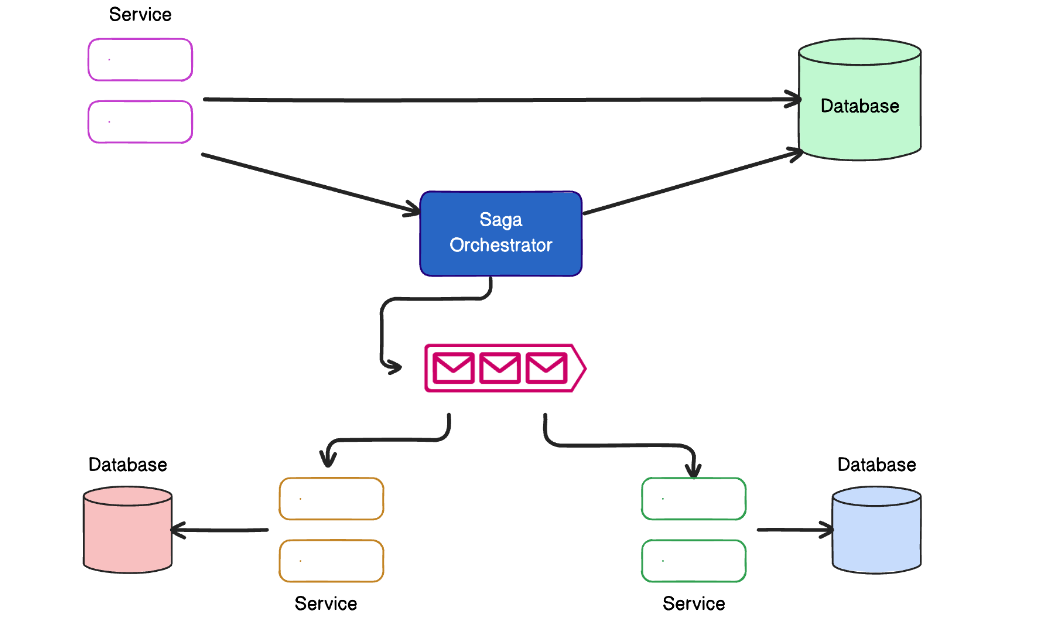
Пример: система бронирования поездки на концерт
Система бронирования поездки на концерт, в которой пользователь оформляет пакет услуг, включающий покупку билета на шоу, поездку на поезде или перелет на самолете, бронирование отеля и аренду автомобиля. Сервисы для каждой части бронирования независимы и не связаны прямыми транзакциями, но если один из пунктов не удается завершить (нет в наличии автомобилей представительского класса, например), весь пакет бронирований должен быть отменен:
- Бронирование начинается с оплаты билета на концерт и перелета, затем бронируется гостиница, и в конце – аренда автомобиля.
- Если бронирование автомобиля не удается, срабатывает компенсация – система отменяет бронирование билета на шоу, гостиницы и перелета, возвращая всю задачу в исходное состояние.
Преимущества подхода на основе «Саги»
- Масштабируемость – каждый сервис выполняет свою часть задачи независимо, что снижает нагрузку на систему.
- Поддержка сложных и долгосрочных задач – «Сага» отлично подходит для реализации многоэтапных и продолжительных бизнес-процессов, использующих множество сервисов.
- Отказоустойчивость – компенсаторные транзакции позволяют откатить всю операцию.
Паттерн разделения чтения и записи (CQRS)
CQRS – это архитектурный паттерн, который разделяет систему на две модели – одна отвечает за запись данных, а другая за чтение:
- Модель записи обрабатывает изменения в данных – создание, обновление или удаление записей. Эта часть системы оптимизирована для обеспечения целостности транзакций и точности внесения изменений.
- Модель чтения используется для быстрого доступа к данным без необходимости взаимодействовать с транзакциями. Эта модель оптимизирована для скоростной выдачи ответов, что особенно полезно, если данные часто читаются пользователями.
CQRS использует асинхронную синхронизацию – когда данные обновляются в модели записи, они не сразу отображаются в модели чтения. Вместо этого модель чтения обновляется асинхронно, с небольшой задержкой, что приводит к конечной согласованности.
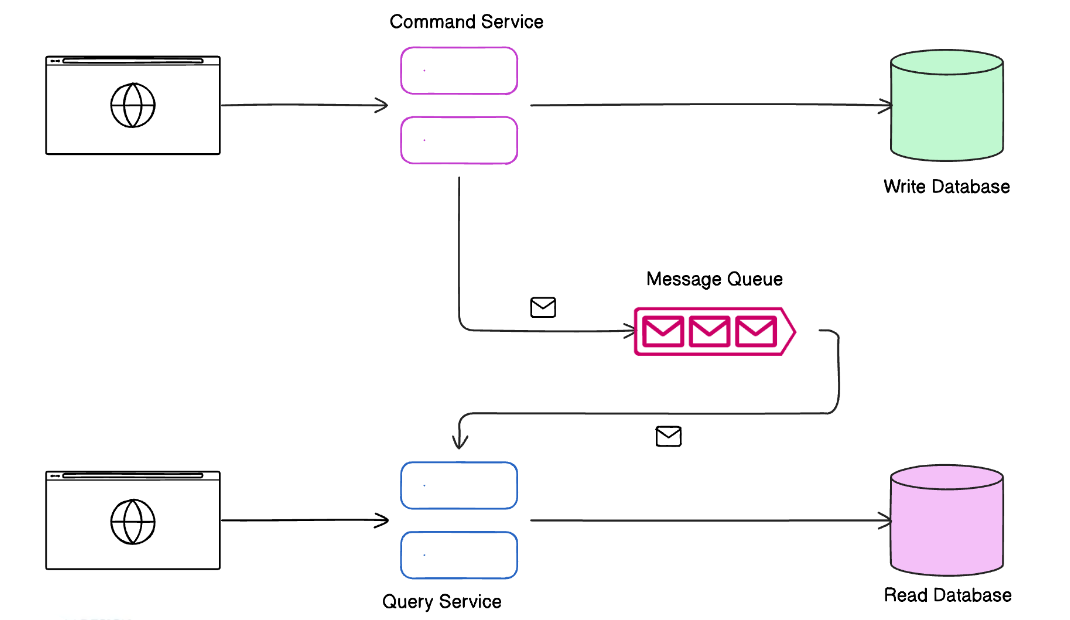
Пример: банковская система
Банковская система, где часто необходимо проверять баланс счета (операция чтения), а также выполнять операции пополнения и снятия (операции записи):
- Модель записи. Когда клиент совершает операцию, например, снимает деньги, система записи (оптимизированная для точности транзакций) мгновенно обновляет данные, уменьшая баланс на счету клиента.
- Модель чтения. В системе чтения баланс отображается только после того, как данные синхронизируются с моделью записи. Это позволяет клиенту быстро просмотреть информацию о счете, но может возникнуть небольшая задержка перед тем, как операция будет видна в разделе просмотра баланса.
Таким образом, пользователь видит данные почти в реальном времени, с небольшой задержкой, которая обеспечивает конечную согласованность между двумя моделями.
Плюсы CQRS
- Повышение производительности – каждая модель создается и оптимизируется с учетом специфики чтения или записи, в результате система быстрее обрабатывает запросы.
- Масштабируемость – можно разделить нагрузку на чтение и запись, обеспечивая более эффективное использование ресурсов.
Заключение
Выбор каждого из этих паттернов зависит от особенностей проекта, требований к производительности и скорости согласования данных:
- Событийная конечная согласованность позволяет добиться хорошей производительности: каждый сервис обновляет свои данные, когда получает событие, а не блокируется в ожидании завершения транзакции в другом сервисе. Подходит для построения слабосвязанных систем, где сервисы обмениваются событиями, а не общаются напрямую. Это делает архитектуру более гибкой и масштабируемой, так как добавление нового сервиса требует минимальных изменений в других частях системы.
- Фоновая синхронизация данных снижает нагрузку на систему и обеспечивает быстрое пользовательских запросов на обновление данных. Идеально подходит для систем, где не требуется мгновенная согласованность данных и достаточно регулярной синхронизации каждые несколько секунд (минут). Не подходит для синхронизации критически важных данных в системах, где даже кратковременная несогласованность может привести к ошибкам.
- Конечная согласованность на основе «Саги» отлично справляется со сложными бизнес-процессами, охватывающими несколько сервисов, и подходит для длительных операций (например, бронирование, доставка, покупка), где каждый этап требует независимой обработки и контроля ошибок. Единственный недостаток этого подхода – сложность реализации: компенсаторные действия требуют детальной проработки и тщательной настройки, что усложняет разработку и увеличивает ее стоимость.
- Паттерн разделения чтения и записи CQRS позволяет сделать систему максимально производительной. Однако реализация этого подхода отличается сложностью, поскольку поддержание асинхронной согласованности между моделями чтения и записи требует серьезных усилий.
Погружение в архитектуру ПО: от паттернов до практики
Месячный интенсив по архитектуре и паттернам проектирования от Proglib Academy раскрывает ключевые аспекты современной разработки. Интересные находки:
- Практический кейс: создание игры «Звёздные войны» для закрепления паттернов
- Язык не имеет значения: принципы работают на Python, Java, PHP, C++, JavaScript, C#
- Фокус на реальных сценариях: от абстрагирования до IoC-контейнеров
Ведущий курса – Евгений Тюменцев, экс-разработчик IBM Watson, сейчас возглавляет HWdTech.
Комментарии