

28 мая 2020 г. на сайте arXiv.org была опубликована статья Language Models are Few-Shot Learners исследователей из американской компании OpenAI. На 75 страницах специалисты по анализу данных продемонстрировали, как их алгоритм GPT-3 генерирует эссе и стихи по паре вступительных предложений, ведет беседу, разгадывает анаграммы, выдает решение словесно описанных арифметических операций. Подходящие вводные фразы подстраивали результат под целевую аудиторию или решение определенной проблемы. Для введения новых слов в вокабуляр модели хватало единственного «прочтения».
Аналогично тому, как алгоритм автодополнения в клавиатуре смартфона подсказывает тройку возможных следующих слов, так GPT-3 создает по одной-двум вступительным фразам вереницу из десятков предложений. Мечта горе-копирайтера — набросал тему и подзаголовок, а программа вывела статью с вразумительным содержанием. Но как мы увидим далее, это не единственное применение алгоритма, и для такого его приложения есть ограничения.
GPT-3 относится к третьему поколению моделей-трансформеров, умеющих генерировать тексты (Generative Pre-trained Transformer). Стремительное улучшение способности к обобщению в первую очередь приписывают увеличению количества параметров модели, настраиваемых в результате обучения: от 100 млн для GPT (2018) и 1.5 млрд для GPT-2 (2019) до 175 млрд для новой GPT-3.
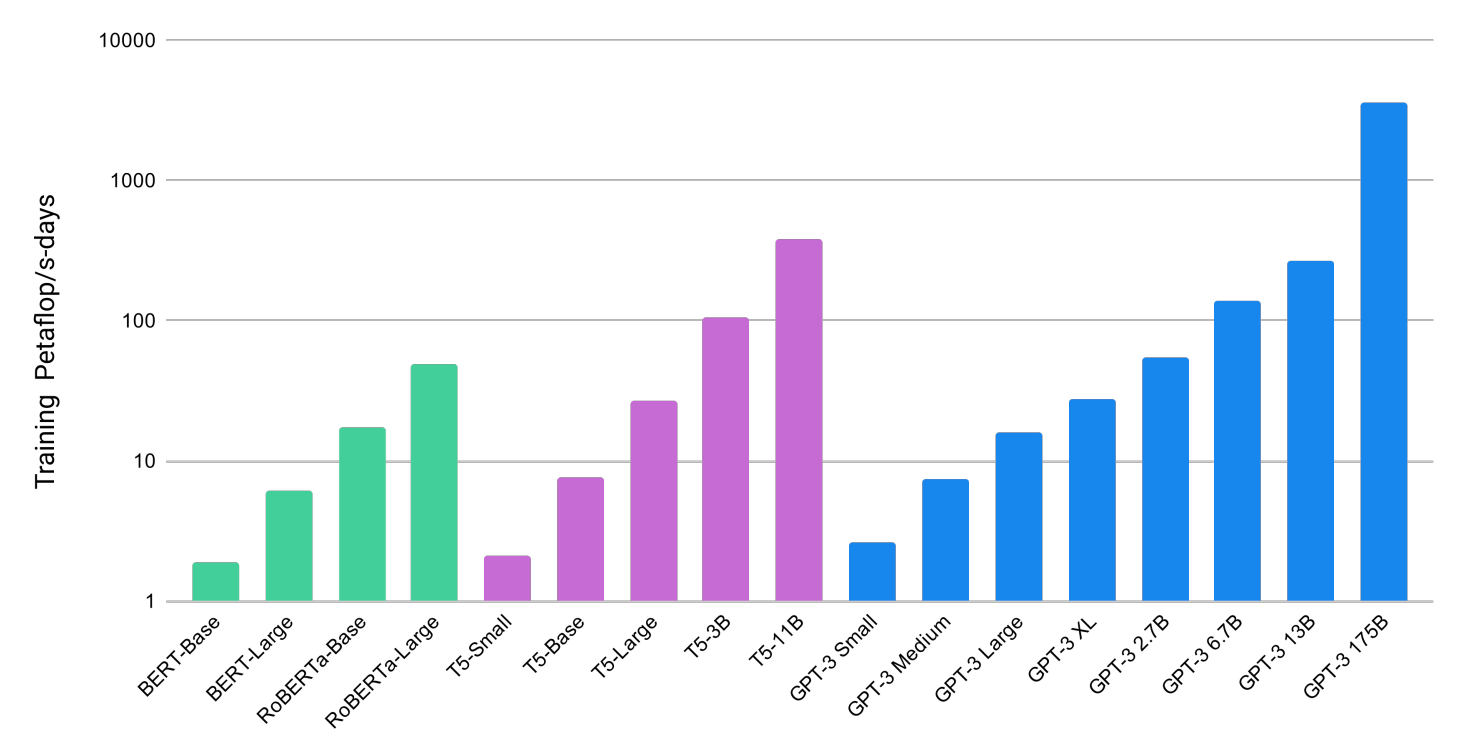
Вырос и набор обучающих данных: для первых двух моделей объем датасета составлял 5 и 40 Гб соответственно, а в GPT-3 это уже 570 Гб веб-страниц проектов Common Crawl и WebText2, двух подборок книг, а также английской Википедии. Рекламу и спам отбросили, включив в датасет только материалы сайтов с высокой оценкой на Reddit. Нейросеть обучалась на построенном специально для OpenAI суперкомпьютере Microsoft Azure AI c 285 тыс. CPU и 10 тыс. GPU.
💬🗯️ Почему о GPT-3 так много разговоров?
В обработке естественного языка в 2010-х гг. произошла смена парадигмы. В первой половине десятилетия главным образом использовались простые векторные или нейросетевые модели, каждая из которых требовала специфичного набора данных и своего метода настройки под решение конкретной задачи: сентимент-анализ, ведение диалога, извлечение сущностей и т. д. Нередко это давало хорошее качество в рамках кейса, но ограничивало способность модели к обобщению.
Title: United Methodists Agree to Historic Split
Subtitle: Those who oppose gay marriage will form their own denomination
Article: After two days of intense debate, the United Methodist Church
has agreed to a historic split - one that is expected to end in the
creation of a new denomination, one that will be "theologically and
socially conservative," according to The Washington Post. The majority of
delegates attending the church's annual General Conference in May voted to
strengthen a ban on the ordination of LGBTQ clergy and to write new rules
that will "discipline" clergy who officiate at same-sex weddings. But
those who opposed these measures have a new plan: They say they will form a
separate denomination by 2020, calling their church the Christian Methodist
denomination.
The Post notes that the denomination, which claims 12.5 million members, was
in the early 20th century the "largest Protestant denomination in the U.S.,"
but that it has been shrinking in recent decades. The new split will be the
second in the church's history. The first occurred in 1968, when roughly
10 percent of the denomination left to form the Evangelical United Brethren
Church. The Post notes that the proposed split "comes at a critical time
for the church, which has been losing members for years," which has been
"pushed toward the brink of a schism over the role of LGBTQ people in the
church." Gay marriage is not the only issue that has divided the church. In
2016, the denomination was split over ordination of transgender clergy, with
the North Pacific regional conference voting to ban them from serving as
clergy, and the South Pacific regional conference voting to allow them.
Особую роль в поиске обобщающего решения сыграла вышедшая в 2017 г. статья специалистов Google об архитектуре Transformer и механизме внимания (аttention) — способе вычисления вероятности появления одного слова в цепочке других. Основанные на этом механизме модели-трансформеры BERT, RoBERTa, XLNet, T5 и семейство авторегрессионных моделей GPT добились качественного прогресса одновременно в генерации текста и обобщении результатов обучения.
При необходимости такие алгоритмы также позволяют провести тонкую настройку (fine tuning). Притом хватает крохотного набора характерных данных — тем меньшего, чем больше модель, предобученная на крупном корпусе текстов. Похоже на то, как ребенок постигает язык на мириадах примеров, пока не поднатореет настолько, что будет готов не только слушать, но и отвечать.
Собственно именно поразительная гибкость и высокая обобщающая способность отличают GPT-3 от предшествующих моделей глубокого обучения.
🗣️ Можно ли самому запустить GPT-3?
11 июля 2020 г. OpenAI анонсировала закрытое API на базе GPT-3. В ответ на введенный пользователем текст API составляет продолжение. Доступны несколько сценариев: генерация текста определенного размера, чат, получение ответа на вопрос, парсинг неструктурированных данных, перефразирование сложных понятий и суждений простым языком. API можно «настроить», представив несколько образцов желаемого результата.
Компания пояснила, что есть три причины, почему они предлагают API, не выкладывая модель в открытый доступ (в архиве GitHub лишь часть датасета и пара примеров работы):
- Заработанные деньги позволят OpenAI продолжить исследования.
- Только крупные компании располагают инфраструктурой для запуска модели. Интерфейс же сделает технологию доступнее небольшим коллективам.
- Разработчики опасаются, что GPT-3 может использоваться для распространения спама, экстремистских текстов и дезинформации. Посредством интерфейса OpenAI будет контролировать применение технологии и ограничит злоупотребления.
Изначально API предоставлялось бесплатно, и авторы успели получить десятки тысяч заявок на подключение. Но 1 октября 2020 г. редким пользователям бета-версии уже пришлось выбирать между четырьмя тарифными планами.
| Тариф | Лимит | Стоимость |
| 1 | 100 тыс. | Трехмесячный бесплатный тест |
| 2 | 2 млн | $100 в месяц + 8 центов за каждые тыс. токенов свыше лимита |
| 3 | 10 млн | $400 в месяц + 6 центов за каждую тыс. токенов свыше лимита |
| 4 | > 10 млн | Оговаривается отдельно |
Таким образом, у любителей, неготовых платить за использование модели есть три месяца, чтобы поэкспериментировать с системой. 2 млн токенов наиболее демократичного тарифа эквивалентны примерно 3 тыс. страниц текста.
22 сентября 2020 г. Microsoft получила эксклюзивную лицензию на использование модели GPT-3 в своих продуктах и доступ к исходному коду технологии. Сделку раскритиковал сооснователь OpenAI Илон Маск — запуск OpenAI в 2015 г. подразумевал создание открытой компании, работающей на благо общества, а не государства или отдельной корпорации, в руках которой локализовалась бы власть, которую дают такие технологии.
22 октября 2020 г. разработчики из Сбера объявили о создании русскоязычного аналога GPT-3. Взяв исходный код GPT-2, аналитики внедрили в него идеи из статьи о GPT-3 и обучили модель на корпусе из 600 ГБ текстов, 90% из которых на русском языке. В датасет включили русскую и английскую версии Википедии, корпус русскоязычной литературы, некоторые сайты, материалы GitHub и Stack Overflow. Модель, названная ruGPT-3 Large, имеет 760 млн параметров, что приближает ее по этому показателю скорее ко второй версии GPT, чем к третьей. Поиграть с моделью можно на Colab. С 21 ноября также доступен Colab-блокнот, позволяющий проводить тонкую настройку.
🧰 Кто-то уже использует API? Есть результаты?
Хотя API не общедоступно, по сети разошлись разнообразные примеры использования GPT-3, в том числе и потенциально коммерческие.
📝 Генерация контента
Статьи для блогов. 20 июля 2020 г. магистрант Университета Беркли Лиам Порр опубликовал пост, рожденный при помощи OpenAI API. Лиам придумал заголовок и первые предложения — остальное дописал алгоритм. Читатели (кроме одного) не заметили подвоха и одобрительно отнеслись к публикации. Стоит отметить, что GPT-3 умеет решать и обратную задачу — выделять краткое содержание.
Написание эссе. 8 сентября 2020 г. британское издание The Guardian выпустило заметку, подготовленную при участии GPT-3. Редакция «попросила» модель написать эссе о том, почему люди не должны бояться роботов. Тот же Лиам Порр отправил редакции восемь сгенерированных GPT-3 вариантов эссе, из удачных кусков которых редакторы составили итоговый текст (Дамир Камалетдинов перевел ее на русский язык).
Текстовая составляющая игр. Другой пример использования GPT-3, — внедрение алгоритма в игру AI Dungeon.
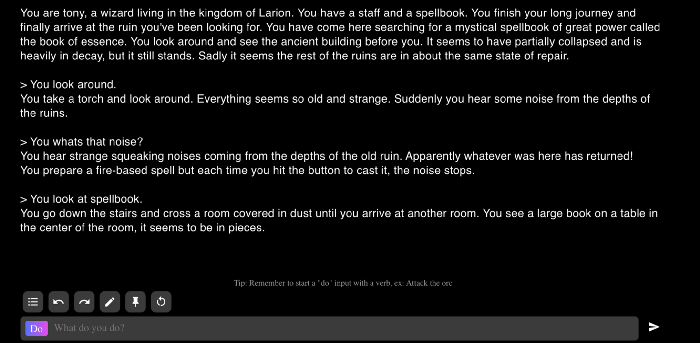
AI Dungeon представляет собой текстовый квест — многопользовательское подземелье, в котором игроки перемещаются с помощью текста. На приведенном скриншоте ввод словосочетания look around (осмотреться) приводит к генерации текста об окружении.
Показаны примеры сочинения стихов, интерпретации эмоджи, генерации бизнес-идей и текстов мемов, сеансы наивной психотерапии. Особого внимания заслуживает детальная работа Гверна Бранвена по генерации околохудожественных текстов: стихов, диалогов, литературных пародий и рассказов. Гверн подтверждает, что в сравнении с GPT-2 новая модель поддерживает высокий уровень абстракции — среди прочего эту мысль подтверждает возможность переноса стиля автора.
Нетекстовый контент. В скором времени оказалось, что алгоритм применим не только в задачах, связанных с текстом, но и для генерации изображений. Однако подобные исследования находятся в самом начале пути.
Ответы на e-mail. Компания OthersideAI использует GPT-3 для автоматизации написания развернутых ответов на электронные письма по затравке из ключевых слов.

👩🎓 Поисковые системы, личные помощники и образование
Ответы на вопросы по тексту и общие вопросы. В октябре 2020 г. в разделе сайта Reddit, где люди задают друг другу вопросы, появился пользователь, который в течение недели отправлял развёрнутые ответы спустя лишь несколько секунд после публикации вопроса. Позднее выяснилось, что это бот на основе GPT-3.
Поиск информации и источника. Разработчик Парас Чопра обнаружил, что GPT-3 выудила из обучающего набора не только текстуальную информацию, но и URL-адреса. Получился текстовый помощник, дополненный поисковой системой и интерактивными ссылками.
Выделение главной мысли. Нейросети можно доверить проблему изложения сути предмета, например, ключевых идей античных философов.
Чат-бот для изучения языков на основе GPT-3 может не только вести диалог на выбранном языке, но и корректировать собеседника, если тот допускает грамматическую ошибку или стилистический промах. Тексты на иностранных языках составляли лишь 7% обучающего набора данных, однако пользователи указывают на неожиданно высокое качество генерации материалов на немецком, русском и японском языках.
Обучение по аналогии. Настройка модели посредством передачи небольшого набора образцов позволяет обнаруживать новые закономерности, родственные предъявленному датасету. К примеру, система может корректно (иной раз и с ошибками) рассчитывать и уравнивать химические реакции, увидев несколько характерных примеров.
👨💻 NoCode-решения: описательная генерация разметки и программного кода
Подход с передачей дообучающего датасета позволяет модели писать код по одному лишь словесному описанию.
HTML и CSS-разметка. Веб-разработчик Шариф Шамим продемонстрировал, как модель по текстовым запросам генерирует HTML-разметку.
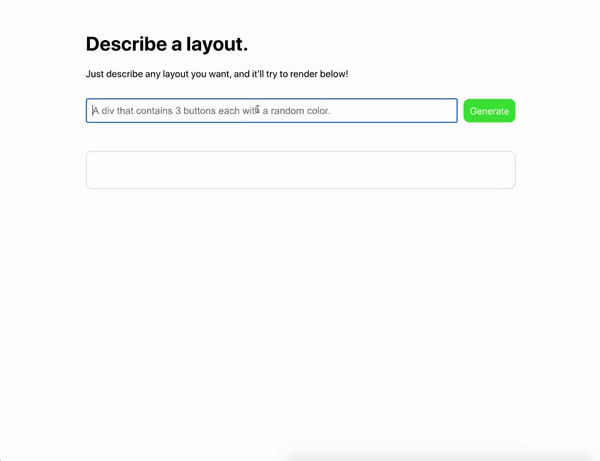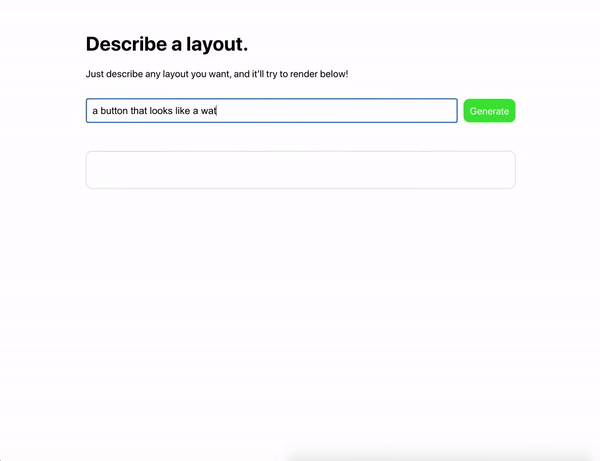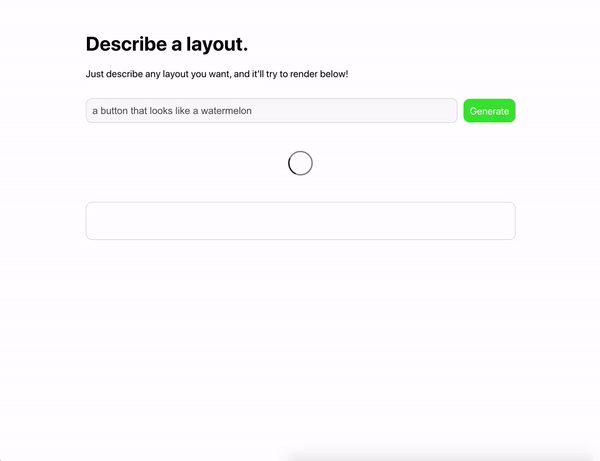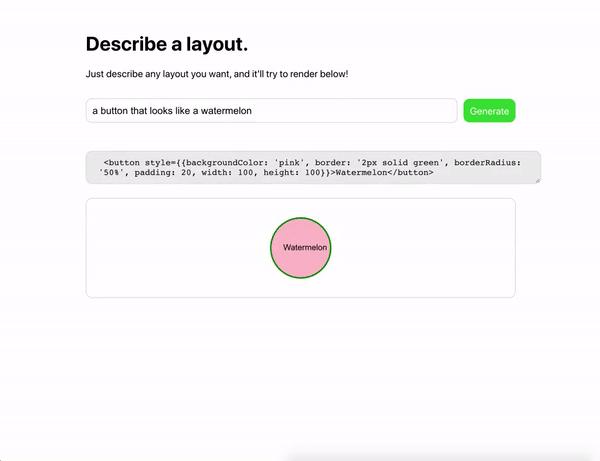
Румынский веб-разработчик Золтан Согьеньи сделал аналогичное решение-генератор для CSS.
Дизайн и код несложных веб-приложений. С помощью GPT-3 Шариф Шамим также создал генератор простых React-приложений. Достаточно написать, что должна делать программа, и алгоритм переводит запрос в программный код.
Разработчик интерфейсов Джордан Сингер двинулся в том же ключе дальше, и написал плагин для Figma, который создает по текстовым описаниям дизайн приложений.
Код на Python. Аналитики Microsoft вместе с OpenAI показали, что GPT-3 может писать код на Python, получая только комментарии на естественном языке.
Регулярные выражения. Парти Логанатан написал веб-приложение, в котором GPT-3 используется, чтобы простым языком описать, что должно делать регулярное выражение, и получить соответствующий regex-шаблон.
AutoML. Мэтт Шумер адаптировал подход к ML — краткое описание модели машинного обучения переводится в код для Keras.
Аналогично решаются задачи для SQL-запросов, девопс-инстансов, LaTeX-разметки, bash-команд и рисования незамысловатых SVG-объектов. Нетрудно заметить общую тенденцию — GPT-3 дает хорошие результаты для генерации кода по текстовым описаниям.
На сайтах GPT-3 Examples и GPT-3 Hunt агрегируются примеры внедрения модели.
🦜 Чего GPT-3 не может? Какие есть ограничения?
Несмотря на яркие количественные и качественные улучшения GPT-3 в сравнении с GPT-2, модель обладает заметными ограничениями в составлении текстов и ряде задач обработки естественного языка. Порой GPT-3 теряет связность в длинных отрывках, противоречит себе и непоследовательно развивает идею мысль. Как отметил исследователь искусственного интеллекта Джулиан Тогелиус, «местами GPT-3 ведёт себя как студент, который не подготовился к экзамену заранее и теперь несёт всякую чушь в надежде, что ему повезёт».
Всякий ответ GPT-3 является вероятностным, у нее нет памяти. Модель действует в рамках контекста в 500-1000 слов — начало крупного текста вскоре исчезает за горизонтом. Это не так проблематично для диалога, но критично для длинных текстов и последовательного обучения. Другая неприятная особенность, характерная для авторегресионных моделей — тенденция рано или поздно скатываться в повторение фрагмента текста.
Алгоритм может промахиваться в простых вопросах, не отличать факты от вымысла, принимать всё, что сообщает собеседник, за чистую монету — например, отвечать на вымышленные факты о китах. Однако, как пишет Гвен Бранвен, «наивность» алгоритма можно настроить, подсказав GPT-3 быть менее категоричной. Неудивительно и то, что GPT-3 временами выдает существующие в обществе — а значит, и в текстах — сексистские и расистские предубеждения.
Искусственный интеллект изменит мир, но GPT-3 это лишь очень ранний проблеск. Нам ещё многое нужно понять.
Выше мы упоминали аналогию обучения модели и ребенка. Есть и значимое различие. «Знания» модели основаны только на текстах о процессах, явлениях, событиях и предметах. Дети же сопоставляют слова с понятиями, которые получили не только при чтении текста, но и через чувственное исследование мира. Задачки вроде «растает ли сыр, если я положу его в холодильник?» обычно вызывают у модели недоумение.
🍬 Заключение
Нейронная сеть GPT-3 — это настолько большая модель с точки зрения мощности и набора данных, что она демонстрирует качественно новое поведение. Мы не переучиваем алгоритм специально для каждой задачи, а выражаем саму задачу через примеры на естественном языке. Настраиваем подсказку так, чтобы модель восприняла проблему через высокоуровневые абстракции, извлеченные в ходе предобучения. Такой способ применения модели глубокого обучения подразумевает новый вид программирования, где «программой» теперь оказывается подсказка, которая настраивает модель для выполнения нужной задачи.
GPT-3 — это не разум, не сознание, но и не совсем машина. Это кое-что другое: статистическое абстрактное представление содержания миллионов умов, выраженное в их письменной речи.
Другими словами, в случае классического программного обеспечения было нужно продумать, как шаг за шагом получить результат; на этапе классических моделей глубокого обучения нужно понять, как составить набор данных, который в скрытом виде содержит требуемый ответ. А в случае с GPT-3 и родственными моделями мы решаем, как правильно описать то, что мы хотим получить.

Самое удивительное, что бывает достаточно попросить выполнить то или иное действие. В других случаях достаточно подумать: «Если бы человек уже написал то, что я хотел, что бы содержали первые предложения? Как бы звучало введение? Если бы я сам рассказывал историю, с чего бы она начиналась?».
Конечно, не менее любопытно, чем эта история закончится.
А какие у вас надежды относительно моделей подобных GPT-3? Как бы вы предложили использовать их на практике? Было бы интересно прочитать ваши идеи.