

Эта публикация представляет собой незначительно сокращенный перевод статьи Кайла Стратиса Use Sentiment Analysis With Python to Classify Movie Reviews. Сначала в этой публикации рассматриваются ключевые этапы работы с текстом, скрытые внутри конвейера spaCy, потом на примере практической задачи анализа тональности отзывов на IMDB рассматривается процесс построения соответствующих функций для сентимент-анализа. Текст статьи также адаптирован в виде блокнота Jupyter.
Анализ тональности (сентимент-анализ) – инструмент компьютерной лингвистики, оценивающий такую субъективную составляющую текста, как отношение пишущего. Часто это составляет трудность даже для опытных читателей — что уж говорить о программах. Однако эмоциональную окраску текста все-таки можно проанализировать с помощью инструментов экосистемы Python.
Зачем это может быть нужно? Существует множество применений для анализа эмоциональной окраски текста. Простой практический пример – такие данные позволяют предсказать поведение биржевых трейдеров относительно конкретной компании по откликам в социальных сетях и другим отзывам.
В этом руководстве мы рассмотрим:
- в чем заключаются базовые методики обработки естественного языка (англ. natural language processing, NLP);
- как машинное обучение может помочь для определения тональности текста;
- как применить библиотеку spaCy для создания классификатора анализа настроений.
Данное руководство предназначено для начинающих практиков машинного обучения.
Предварительная обработка и очистка текстовых данных
Любой рабочий процесс анализа данных начинается с их загрузки. Далее мы должны пропустить их через конвейер (pipeline) предобработки:
- токенизировать текст – разбить текст на предложения, слова и другие единицы;
- удалить стоп-слова;
- привести слова к нормальной форме;
- векторизовать тексты – сделать числовые представления текстов для их дальнейшей обработки классификатором.
Все эти шаги служат для уменьшения шума, присущего любому обычному тексту, и повышения точности результатов классификатора. Для решения указанных задач есть несколько отличных библиотек, например, NLTK, TextBlob и spaCy. Последнюю мы и будем применять в этом руководстве.
Прежде чем идти дальше, установите библиотеку spaCy и модель для английского языка:
pip install spacy
python -m spacy download en_core_web_sm
Токенизация
Токенизация – это процесс разбиения текста на более мелкие части. В библиотеку spaCy уже встроен конвейер (pipeline), который начинает свою работу по обработке текста с токенизации. В этом руководстве мы разделим текст на отдельные слова. Загрузим пример и проведем разбиение:
import spacy
nlp = spacy.load("en_core_web_sm")
text = """
Dave watched as the forest burned up on the hill,
only a few miles from his house. The car had
been hastily packed and Marta was inside trying to round
up the last of the pets. "Where could she be?" he wondered
as he continued to wait for Marta to appear with the pets.
"""
doc = nlp(text)
token_list = [token for token in doc]
print(token_list)
[
, Dave, watched, as, the, forest, burned, up, on, the, hill, ,,
, only, a, few, miles, from, his, house, ., The, car, had,
, been, hastily, packed, and, Marta, was, inside, trying, to, round,
, up, the, last, of, the, pets, ., ", Where, could, she, be, ?, ", he, wondered,
, as, he, continued, to, wait, for, Marta, to, appear, with, the, pets, .,
]
Вы могли заметить, что захваченные токены включают знаки препинания и другие строки, не относящиеся к словам. Это нормальное поведение в случае использований конвейера по умолчанию.
Удаление стоп-слов
Стоп-слова – это слова, которые могут иметь важное значение в человеческом общении, но не имеют смысла для машин. Библиотека spaCy поставляется со списком стоп-слов по умолчанию (его можно настроить). Проведем фильтрацию полученного списка:
filtered_tokens = [token for token in doc if not token.is_stop]
print(filtered_tokens)
[
, Dave, watched, forest, burned, hill, ,,
, miles, house, ., car,
, hastily, packed, Marta, inside, trying, round,
, pets, ., ", ?, ", wondered,
, continued, wait, Marta, appear, pets, .,
]
Одной строкой Python-кода мы отфильтровали стоп-слова из токенизированного текста с помощью атрибута токенов .is_stop. После удаления стоп-слов список стал короче, исчезли местоимения и служебные слова: артикли, союзы, предлоги и послелоги.
Приведение к нормальной форме
В процессе нормализации все формы слова приводятся к единому представлению. Например, watched, watching и watches после нормализации превращаются в watch. Есть два основных подхода к нормализации: стемминг и лемматизация.
В случае стемминга выделяется основа слова, дополнив которую можно получить слова-потомки. Такой метод сработает на приведенном примере. Однако это наивный подход – стемминг просто обрезает строку, отбрасывая окончание. Такой метод не обнаружит связь между feel и felt.
Лемматизация стремится решить указанную проблему, используя структуру данных, в которой все формы слова связываются с его простейшей формой – леммой. Лемматизация обычно приносит больше пользы, чем стемминг, и потому является единственной стратегией нормализации, предлагаемой spaCy. В рамках NLP-конвейера лемматизация происходит автоматически. Лемма для каждого токена хранится в атрибуте .lemma_:
lemmas = [
f"Token: {token}, lemma: {token.lemma_}"
for token in filtered_tokens
]
print(lemmas)
['Token: \n, lemma: \n', 'Token: Dave, lemma: Dave',
'Token: watched, lemma: watch', 'Token: forest, lemma: forest',
'Token: burned, lemma: burn', 'Token: hill, lemma: hill',
'Token: ,, lemma: ,', 'Token: \n, lemma: \n',
'Token: miles, lemma: mile', 'Token: house, lemma: house',
'Token: ., lemma: .', 'Token: car, lemma: car',
'Token: \n, lemma: \n', 'Token: hastily, lemma: hastily',
'Token: packed, lemma: pack', 'Token: Marta, lemma: Marta',
'Token: inside, lemma: inside', 'Token: trying, lemma: try',
'Token: round, lemma: round', 'Token: \n, lemma: \n',
'Token: pets, lemma: pet', 'Token: ., lemma: .',
'Token: ", lemma: "', 'Token: ?, lemma: ?',
'Token: ", lemma: "', 'Token: wondered, lemma: wonder',
'Token: \n, lemma: \n', 'Token: continued, lemma: continue',
'Token: wait, lemma: wait', 'Token: Marta, lemma: Marta',
'Token: appear, lemma: appear', 'Token: pets, lemma: pet',
'Token: ., lemma: .', 'Token: \n, lemma: \n']
.lemma_. Это не опечатка, а результат соглашения по именованию в spaCy атрибутов, которые могут быть прочитаны человеком.Следующим шагом является представление каждого токена способом, понятным машине. Этот процесс называется векторизацией.
Векторизация текста
Векторизация – преобразование токена в числовой массив, который представляет его свойства. В контексте задачи вектор уникален для каждого токена. Векторные представления токенов используются для оценки сходства слов, классификации текстов и т. д. В spaCy токены векторизуются в виде плотных массивов, в которых для каждой позиции определены ненулевые значений. Это отличает используемый подход от ранних методов, в которых для тех же целей применялись разреженные массивы и большинство позиций были заполнены нулями.
Как и другие шаги, векторизация выполняется автоматически в результате вызова nlp(). Получим векторное представление одного из токенов:
filtered_tokens[1].vector
array([ 1.8371646 , 1.4529226 , -1.6147211 , 0.678362 , -0.6594443 ,
1.6417935 , 0.5796405 , 2.3021278 , -0.13260496, 0.5750932 ,
1.5654886 , -0.6938864 , -0.59607106, -1.5377437 , 1.9425622 ,
-2.4552505 , 1.2321601 , 1.0434952 , -1.5102385 , -0.5787632 ,
0.12055647, 3.6501784 , 2.6160972 , -0.5710199 , -1.5221789 ,
0.00629176, 0.22760668, -1.922073 , -1.6252862 , -4.226225 ,
-3.495663 , -3.312053 , 0.81387717, -0.00677544, -0.11603224,
1.4620426 , 3.0751472 , 0.35958546, -0.22527039, -2.743926 ,
1.269633 , 4.606786 , 0.34034157, -2.1272311 , 1.2619178 ,
-4.209798 , 5.452852 , 1.6940253 , -2.5972986 , 0.95049495,
-1.910578 , -2.374927 , -1.4227567 , -2.2528825 , -1.799806 ,
1.607501 , 2.9914255 , 2.8065152 , -1.2510269 , -0.54964066,
-0.49980402, -1.3882618 , -0.470479 , -2.9670253 , 1.7884955 ,
4.5282774 , -1.2602427 , -0.14885521, 1.0419178 , -0.08892632,
-1.138275 , 2.242618 , 1.5077229 , -1.5030195 , 2.528098 ,
-1.6761329 , 0.16694719, 2.123961 , 0.02546412, 0.38754445,
0.8911977 , -0.07678384, -2.0690763 , -1.1211847 , 1.4821006 ,
1.1989193 , 2.1933236 , 0.5296372 , 3.0646474 , -1.7223308 ,
-1.3634219 , -0.47471118, -1.7648507 , 3.565178 , -2.394205 ,
-1.3800384 ], dtype=float32)
Здесь мы используем атрибут .vector для второго токена в списке filter_tokens. В этом наборе это слово Dave.
.vector вы получили другой результат, не беспокойтесь. Это может быть связано с тем, что используется другая версия модели en_core_web_sm или самой библиотеки spaCy.Использование классификаторов машинного обучения для прогнозирования настроений
Теперь текст преобразован в форму, понятную компьютеру, так что мы можем начать работу над его классификацией. Мы рассмотрим три темы, которые дадут общее представление о классификации текстовых данных в результате машинного обучения:
- Инструменты машинного обучения для задач классификации.
- Как происходит классификация.
- Как использовать spaCy для классификации текста.
Инструменты машинного обучения
В мире Python есть ряд инструментов для решения задач классификации. Вот некоторые из наиболее популярных:
Этот список не является исчерпывающим, но это наиболее широко используемые фреймворки (библиотеки) машинного обучения, доступные для питонистов. Это мощные инструменты, на освоение и понимание которых уходит много времени.
TensorFlow разработан Google и является одним из самых популярных фреймворков машинного обучения. Он довольно низкоуровневый, что дает пользователю много возможностей. PyTorch – это ответ Facebook на TensorFlow, созданный с учетом незнакомых с машинным обучением Python-разработчиков. Библиотека scikit-learn отличается от TensorFlow и PyTorch, позволяя использовать готовые алгоритмы машинного обучения, не создавая собственных. Он прост в использовании и позволяет быстро обучать классификаторы всего несколькими строками кода.
К счастью, spaCy предоставляет довольно простой встроенный классификатор текста. Для начала важно понять общий рабочий процесс любого вида задач классификации:
- Разделяем данные на обучающую и тестовую выборки (наборы данных).
- Выбираем архитектуру модели.
- Используем обучающие данные для настройки параметров модели (этот процесс и называется обучением).
- Используем тестовые данные, чтобы оценить качество обучения модели.
- Используем обученную модель на новых, ранее не рассматривавшихся входных данных для создания прогнозов.
Cпециалисты по машинному обучению обычно разделяют набор данных на три составляющих:
- Данные для обучения (training).
- Данные для валидации (validation).
- Данные для теста (test).
Обучающий набор данных, как следует из названия, используется для обучения модели. Валидационные данные используются для настройки гиперпараметров модели и оценки модели непосредственно в процессе обучения. Гиперпараметры контролируют процесс обучения и структуру модели. Такими параметрами являются, например, скорость обучения и размер пакета данных (батчей). Набор гиперпараметров зависит от используемой модели. Тестовый набор данных – включает данные, позволяющие судить о конечном качестве работы модели.
Теперь, когда мы в общих чертах рассмотрели процесс классификации, пора применить его с помощью spaCy.
Как использовать spaCy для классификации текста
Мы уже знаем, что spaCy берет на свои плечи заботы о предварительной обработке текста с помощью конструктора nlp(). Конвейер по умолчанию определен в файле JSON, связанном с уже существующей моделью (en_core_web_sm в этом руководстве) или моделью, созданной пользвателем.
Один из встроенных компонентов конвейера называется textcat (сокр. TextCategorizer), который позволяет назначать текстовым данным категории и использовать их в качестве обучающих данных нейронной сети. Чтобы с помощью этого инструмента обучить модель, необходимо выполнить следующие действия:
- Добавить компонент
textcatв существующий конвейер. - Добавить в компонент
textcatвалидные метки (имена категорий). - Загрузить, перемешать и разделить на части данные, на которые проходит обучение.
- Обучить модель, оценивая каждую итерацию обучения.
- Использовать обученную модель, чтобы предсказать тональность настроений на текстах, не входивших в обучающую выборку.
- При желании: сохранить обученную модель.
Создаем собственный анализатор тональности текстов
В качестве набора данных, на которых будет происходить обучение и проверка модели мы будем использовать набор данных Large Movie Review, собранный Эндрю Маасом.
Вставка от переводчика. Использование базы данных IMDB является стандартным источником для сентимент-анализа. В рецензиях к фильмам сами пользователи уже соотнесли рецензию и оценку фильма – как бы разметили данные, сопоставив блок текста и его категорию.
Предлагаемый в пособии набор данных хранится в виде сжатого tar-архива, который можно извлечь на диск непосредственно из Python. Датасеты обычно хранятся отдельно от блокнотов Jupyter (чтобы не выгружать их на GitHub), поэтому для дальнейшей работы полезно сменить текущую рабочую директорию:
import os
import tarfile
# не забудьте изменить путь к директории с архивом
# на тот, что используется в вашей системе
os.chdir(os.path.relpath('../../../Datasets/'))
fname = 'aclImdb_v1.tar.gz'
with tarfile.open(fname, "r:gz") as tar:
tar.extractall()
tar.close()
Туда же впоследствии мы сохраним обученную модель классификации данных.
Загрузка и подготовка данных
Далее мы считаем, что вы уже извлекли директорию, содержащую набор данных. Разобьем этап загрузки на конкретные шаги:
- Загрузим текст и метки из структуры файлов и каталогов.
- Перемешаем данные.
- Разделим данные на обучающий и тестовый наборы.
- Вернём два набора данных.
Этот процесс самодостаточен, поэтому его логично «упаковать» в отдельную функцию:
def load_training_data(
data_directory: str = "aclImdb/train",
split: float = 0.8,
limit: int = 0
) -> tuple:
В сигнатуре функции мы используем аннотацию типов Python 3, чтобы было ясно, какие типы аргументов ожидает функция и какой тип она возвращает. Приведенные параметры позволяют определить каталог, в котором хранятся данные (data_directory), соотношение обучающих и тестовых данных (split) и количество отбираемых записей (limit). Далее нам нужно перебрать все файлы в наборе данных и загрузить их данные в список:
# одиночными символами решетки здесь и далее помечен код,
# добавленный или изменившийся в сравнении с предыдущим кодом
import os #
def load_training_data(
data_directory: str = "aclImdb/train",
split: float = 0.8,
limit: int = 0) -> tuple:
# Загрузка данных из файлов
reviews = [] #
for label in ["pos", "neg"]: #
labeled_directory = f"{data_directory}/{label}" #
for review in os.listdir(labeled_directory): #
if review.endswith(".txt"): #
with open(f"{labeled_directory}/{review}") as f:
text = f.read() #
text = text.replace("<br />", "\n\n") #
if text.strip(): #
spacy_label = { #
"cats": { #
"pos": "pos" == label, #
"neg": "neg" == label #
} #
} #
reviews.append((text, spacy_label)) #
Хотя это может показаться сложным, здесь мы просто создаем структуру каталогов данных, ищем и открываем текстовые файлы, а затем добавляем кортеж содержимого и словарь меток в список рецензий reviews. Оформление меток в виде словаря – это формат, используемый моделями spaCy во время обучения.
Поскольку на этом этапе мы открываем каждый обзор, здесь же полезно заменить HTML-теги <br /> символами новой строки и использовать строковый метод .strip () для удаления начальных и конечных пробелов.
В этом проекте мы не будем сразу удалять стоп-слова из обучающей выборки – это может изменить значение предложения или фразы и снизить предсказательную силу классификатора.
После загрузки файлов мы хотим их перетасовать, чтобы устранить любое влияние, обусловленное порядком загрузки обучающих данных:
import os
import random #
def load_training_data(
data_directory: str = "aclImdb/train",
split: float = 0.8,
limit: int = 0
) -> tuple:
# Загрузка данных из файлов
reviews = []
for label in ["pos", "neg"]:
labeled_directory = f"{data_directory}/{label}"
for review in os.listdir(labeled_directory):
if review.endswith(".txt"):
with open(f"{labeled_directory}/{review}") as f:
text = f.read()
text = text.replace("<br />", "\n\n")
if text.strip():
spacy_label = {
"cats": {
"pos": "pos" == label,
"neg": "neg" == label}
}
reviews.append((text, spacy_label))
random.shuffle(reviews) #
if limit: #
reviews = reviews[:limit] #
split = int(len(reviews) * split) #
return reviews[:split], reviews[split:] #
В добавленных строках кода мы перемешали записи из данных с помощью вызова random.shuffle(). Затем мы разбиваем и разделяем данные. Наконец, возвращаем два списка обзоров.
Выведем пример записи:
load_training_data(
data_directory = "aclImdb/train",
split = 0.8,
limit = 0)[0][0]
('HOLLOW MAN is one of the better horror films of the past decade.
The sub-plot is original and the main plot is even better.
The special effects are brilliant and possibly the best I have ever
seen in a horror film. Kevin Bacon proves again that he can handle...',
{'cats': {'pos': True, 'neg': False}})
thinc (репозиторий GitHub), который, помимо других функций, включает упрощенный доступ к большим наборам данных, в том числе датасет обзоров IMDB, используемый в этом проекте.Обучение классификатора
Конвейер spaCy позволяет создать и обучить сверточную нейронную сеть (CNN) для классификации текстовых данных. Здесь этот подход используется для сентимент-анализа, но ничто не мешает распространить его и на другие задачи классификации текстов.
В этой части проекта мы выполним три шага:
- Измененим базовый конвейер spaCy для включения компонента
textcat. - Создадим цикл для обучения компонента
textcat. - Научимся оценивать прогресс обучения модели после заданного количества циклов обучения.
Изменение конвейера spaCy для включения textcat
Загрузим тот же конвейер, что и в примерах в начале руководства, далее добавим компонент textcat. После этого укажем textcat метки, которые используются в данных: pos для положительных отзывов и neg для негативных:
import os
import random
import spacy
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Строим конвейер
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
Если вы уже видели пример textcat из документации spaCy, то этот код будет вам знаком. Сначала мы загружаем встроенный конвейер en_core_web_sm, затем проверяем атрибут .pipe_names, чтобы узнать, доступен ли компонент textcat. Если это не так, создаем компонент с помощью метода .create_pipe(), передаем словарь с конфигурацией. Соответствующие инструкции описаны в документации TextCategorizer. Наконец, с помощью .add_pipe() добавляем компонент в конвейер, последний аргумент указывает, что этот компонент должен быть добавлен в конец конвейера.
Теперь нужно обработать случай, когда компонент textcat уже доступен. Добавляем метки:
import os
import random
import spacy
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Строим конвейер
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else: #
textcat = nlp.get_pipe("textcat") #
textcat.add_label("pos") #
textcat.add_label("neg") #
Пишем цикл обучения textcat
Чтобы начать цикл обучения, настраиваем конвейер на обучение компонента textcat, генерируем для него пакеты данных с помощью функций из пакета spacy.util – minibatch() и compounding(). Под пакетом данных, батчем (англ. batch) понимается просто та небольшая часть данных, которая участвует в обучении. Пакетная обработка данных позволяет сократить объем памяти, используемый во время обучения и быстрее обновлять гиперпараметры.
Реализуем описанный цикл обучения, добавив необходимые строки:
import os
import random
import spacy
from spacy.util import minibatch, compounding #
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Строим конвейер
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")
# Обучаем только textcat
training_excluded_pipes = [ #
pipe for pipe in nlp.pipe_names if pipe != "textcat" #
] #
with nlp.disable_pipes(training_excluded_pipes): #
optimizer = nlp.begin_training() #
# Итерация обучения
print("Начинаем обучение") #
batch_sizes = compounding( #
4.0, 32.0, 1.001 #
) # Генератор бесконечной последовательности входных чисел
В последних строчках функции создаем список компонентов в конвейере, которые не являются компонентами textcat. Далее используем диспетчер контекста nlp.disable(), чтобы отключить эти компоненты для всего кода в области действия диспетчера контекста.
Далее мы вызываем функцию nlp.begin_training(), которая возвращает начальную функцию оптимизатора. Это то, что nlp.update() будет впоследствии использовать для обновления весов базовой модели. Затем используем функцию compounding() для создания генератора, дающего последовательность значений batch_sizes, которые в дальнейшем будут приниматься функцией minibatch().
Теперь добавим обучение на батчах:
import os
import random
import spacy
from spacy.util import minibatch, compounding #
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Строим конвейер
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")
# Обучаем только textcat
training_excluded_pipes = [
pipe for pipe in nlp.pipe_names if pipe != "textcat"
]
with nlp.disable_pipes(training_excluded_pipes):
optimizer = nlp.begin_training()
print("Начинаем обучение")
batch_sizes = compounding(
4.0, 32.0, 1.001
) # Генератор бесконечной последовательности входных чисел
for i in range(iterations): #
loss = {} #
random.shuffle(training_data) #
batches = minibatch(training_data, size=batch_sizes)
for batch in batches: #
text, labels = zip(*batch) #
nlp.update( #
text, #
labels, #
drop=0.2, #
sgd=optimizer, #
losses=loss #
) #
Теперь для каждой итерации, указанной в сигнатуре train_model(), мы создаем пустой словарь с именем loss, который будет обновляться и использоваться функцией nlp.update(). Перетасовываем обучающие данные и разделяем их на пакеты разного размера с помощью функции minibatch().
Для каждого пакета отделяем текст (text) от меток (labels) и передаем их в оптимизатор nlp.update(). Это фактически запускает обучение.
Параметр dropout сообщает nlp.update(), какую часть обучающих данных в этом пакете нужно пропустить. Это делается для того, чтобы модели было сложнее переобучиться – запомнить обучающие данные без создания обобщающей модели.
Оценка прогресса обучения модели
Поскольку мы будем выполнять множество оценок на большом количестве вычислений, имеет смысл написать отдельную функцию evaluate_model(). В этой функции мы будем классифицировать тексты из валидационного набора данных на недообученной модели и сравнивать результаты модели с метками исходных данных.
Используя эту информацию, мы вычислим следующие метрики:
- Истинно положительные (true positives, TP) – число отзывов, которые модель правильно предсказала как положительные.
- Ложноположительные (false positives, FP) – число отзывов, которые модель неверно предсказала как положительные, хотя на самом деле они были негативными.
- Истинно отрицательные (true negatives, TN) – число отзывов, которые модель правильно предсказала как негативные.
- Ложноотрицательные (false negatives, FN) – число отзывов, которые модель неверно предсказала как негативные, хотя на самом деле они были положительными.
Поскольку наша модель для каждой метки возвращает оценку от 0 до 1, мы определяем положительный или отрицательный результат на основе этой оценки. На основе четырех описанных статистических данных мы вычисляем две метрики: точность и полноту. Эти метрики являются показателями эффективности модели классификации:
- Точность (precision) – отношение истинно положительных результатов ко всем элементам, отмеченным моделью как положительные (истинные и ложные срабатывания). Точность 1.0 означает, что каждый отзыв, отмеченный нашей моделью как положительный, действительно относится к положительному классу.
- Полнота (recall) – это отношение истинно положительных отзывов ко всем фактическим положительным отзывам, то есть количество истинно положительных отзывов, деленных на суммарное количество истинно положительных и ложноотрицательных отзывов.
Ещё более популярной метрикой является F1-мера – среднее гармоническое точности и полноты. Максимизация F1-меры приводит к одновременной максимизации этих двух критериев:
В evaluate_model() необходимо передать токенизатор, textcat и тестовый набор данных.
def evaluate_model(tokenizer, textcat, test_data: list) -> dict:
reviews, labels = zip(*test_data)
reviews = (tokenizer(review) for review in reviews)
# Указываем TP как малое число, чтобы в знаменателе
# не оказался 0
TP, FP, TN, FN = 1e-8, 0, 0, 0
for i, review in enumerate(textcat.pipe(reviews)):
true_label = labels[i]['cats']
score_pos = review.cats['pos']
if true_label['pos']:
if score_pos >= 0.5:
TP += 1
else:
FN += 1
else:
if score_pos >= 0.5:
FP += 1
else:
TN += 1
precision = TP / (TP + FP)
recall = TP / (TP + FN)
f_score = 2 * precision * recall / (precision + recall)
return {"precision": precision, "recall": recall, "f-score": f_score}
В этой функции мы разделяем обзоры и их метки, затем используем выражение-генератор для токенизации каждого из обзоров, подготавливая их для передачи в textcat. Выражение-генератор позволяет перебирать токенизированные обзоры, не сохраняя каждый из них в памяти.
Затем мы используем score и true_label для определения ложных и истинных срабатываний модели, которые далее подставляем для расчета точности, полноты и F-меры.
Вызовем evaluate_model() из описанной ранее функции train_model():
import os
import random
import spacy
from spacy.util import minibatch, compounding
def train_model(
training_data: list,
test_data: list,
iterations: int = 20) -> None:
# Строим конвейер
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")
# Обучаем только textcat
training_excluded_pipes = [
pipe for pipe in nlp.pipe_names if pipe != "textcat"
]
with nlp.disable_pipes(training_excluded_pipes):
optimizer = nlp.begin_training()
# Training loop
print("Начинаем обучение")
print("Loss\t\tPrec.\tRec.\tF-score") #
batch_sizes = compounding(
4.0, 32.0, 1.001
) # Генератор бесконечной последовательности входных чисел
for i in range(iterations):
loss = {}
random.shuffle(training_data)
batches = minibatch(training_data, size=batch_sizes)
for batch in batches:
text, labels = zip(*batch)
nlp.update(
text,
labels,
drop=0.2,
sgd=optimizer,
losses=loss
)
with textcat.model.use_params(optimizer.averages):
evaluation_results = evaluate_model( #
tokenizer=nlp.tokenizer, #
textcat=textcat, #
test_data=test_data #
) #
print(f"{loss['textcat']:9.6f}\t\
{evaluation_results['precision']:.3f}\t\
{evaluation_results['recall']:.3f}\t\
{evaluation_results['f-score']:.3f}")
# Сохраняем модель #
with nlp.use_params(optimizer.averages): #
nlp.to_disk("model_artifacts") #
Здесь мы добавили несколько вызовов print(), чтобы помочь организовать вывод от функции evaluate_model(), которую вызываем в контекстном менеджере .use_param (), чтобы оценить модель в ее текущем состоянии.
После завершения процесса обучения сохраняем только что обученную модель в каталоге с именем model_artifacts:
Итак, мы получили функцию, которая обучает модель, отображает оценку обучения и позволяет сохранить результат. Произведем ее обучение:
train, test = load_training_data(limit=5000)
train_model(train, test, iterations=10)
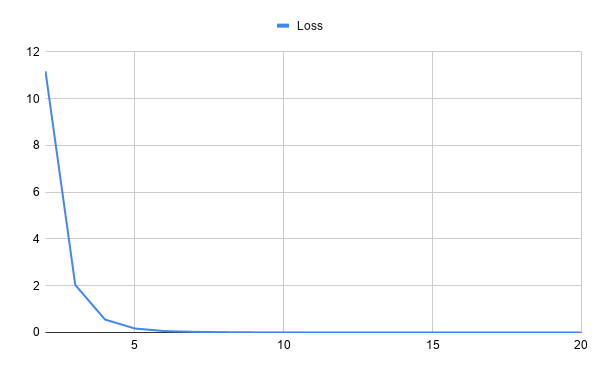
Начинаем обучение
Loss Prec. Rec. F-score
13.758302 0.809 0.776 0.792
1.080611 0.827 0.784 0.805
0.264118 0.833 0.776 0.804
...
0.005302 0.833 0.776 0.804
limit), однако в этом случае есть риск получить менее точную модель.По мере обучения модели вы будете видеть, как меняются показатели потерь, точности, полноты и F-меры для каждой итерации обучения. Значение функции потерь стремительно уменьшается с каждой итерацией. Остальные параметры также должны меняться, но не так значительно: обычно они растут на самых первых итерациях, а после этого держатся примерно на одном уровне.
Классифицируем обзоры
Теперь у нас есть обученная модель, пора протестировать ее на реальных обзорах – насколько успешно она справится с оценкой их эмоциональной окраски. Для целей этого проекта мы оценим лишь один обзор, вместо которого вы можете подставить любые иные строковые значения.
TEST_REVIEW = """
Transcendently beautiful in moments outside the office, it seems almost
sitcom-like in those scenes. When Toni Colette walks out and ponders
life silently, it's gorgeous.<br /><br />The movie doesn't seem to decide
whether it's slapstick, farce, magical realism, or drama, but the best of it
doesn't matter. (The worst is sort of tedious - like Office Space with less humor.)
"""
Передадим текст обзора модели, чтобы сгенерировать прогноз и отобразить его пользователю:
def test_model(input_data: str):
# Загружаем сохраненную модель
loaded_model = spacy.load("model_artifacts")
parsed_text = loaded_model(input_data)
# Определяем возвращаемое предсказание
if parsed_text.cats["pos"] > parsed_text.cats["neg"]:
prediction = "Положительный отзыв"
score = parsed_text.cats["pos"]
else:
prediction = "Негативный отзыв"
score = parsed_text.cats["neg"]
print(f"Текст обзора: {input_data}\n\
Предсказание: {prediction}\n\
Score: {score:.3f}")
В этом коде мы передаем входные данные в загруженную модель и генерируем предсказание в атрибуте cats переменной parsed_text. Затем проверяем оценки каждого настроения и сохраняем метки с более высоким прогнозом. Проверим, что модель корректно отрабатывает на отдельном примере.
test_model(input_data=TEST_REVIEW)
Текст обзора:
Transcendently beautiful in moments outside the office, it seems almost
sitcom-like in those scenes. When Toni Colette walks out and ponders
life silently, it's gorgeous.<br /><br />The movie doesn't seem to decide
whether it's slapstick, farce, magical realism, or drama, but the best of it
doesn't matter. (The worst is sort of tedious - like Office Space with less humor.)
Предсказание: Положительный отзыв
Score: 0.612
Отзыв действительно несет положительную оценку. Параметр Score служит характеристикой уверенности модели. Проверьте поведение функции test_model() на других строковых значениях.
Итак, мы создали ряд независимых функций load_data(), train_model(), evaluate_model() и test_model(), которые, вместе взятые, будут загружать данные и обучать, оценивать, сохранять и тестировать классификатор анализа эмоциональной окраски текста в Python. Чтобы объединить их вместе в одном файле достаточно, использовать стандартную инструкцию if __name__ == "__main__":
if __name__ == "__main__":
train, test = load_training_data(limit=2500)
train_model(train, test)
print("Testing model")
test_model()
Заключение
Поздравляем! Вы обучили модель анализа настроений, используя методы обработки естественного языка.
В этом руководстве мы рассмотрели:
- базовые методики предобработки текста;
- инструменты создания классификаторов;
- процесс создания NLP-конвейера с помощью spaCy.
Оттолкнувшись от этого проекта, вы можете разработать другие решения. Вот несколько идей, с которых можно начать его расширение:
- Во время работы функции
load_data()текст каждого отзыва загружается в память. Можно ли сделать процесс более эффективным, используя вместо этого функции-генераторы? - Перепишите код, чтобы удалить стоп-слова во время предобработки или загрузки данных. Как меняется качество и производительность модели?
- Используйте библиотеку click, чтобы создать интерактивный интерфейс командной строки.
- Изучите конфигурационные параметры для компонента конвейера
textcatи поэкспериментируйте с различными настройками.
P.S. Оценка модели на рецензиях с Кинопоиска
Напоследок проверим модель на аналогичных отзывах на русском языке. Для этого можно было бы использовать русскоязычную модель spaCy (см. примечание выше) и заново обучить модель на приведенных далее примерах, но ради интереса мы воспользуемся моделью, уже обученной на рецензиях IMDB. Для этого протестируем модель на датасете из 3000 записей, собранных с Кинопоиска Денисом Кудрявцевым. Выборка сбалансирована: содержится примерно по одной тысяче положительных, негативных и нейтральных отзывов (в датасете IMDB присутствуют только положительные и негативные отзывы). Для удобства работы мы преобразовали набор текстовых файлов в единый csv-файл и перевели колонку рецензий с помощью машинного перевода.
import pandas as pd
import sklearn.metrics
df = pd.read_csv("kinopoisk.zip", index_col=0)
df.sample(frac=1)[:5]
Адаптируем функцию test_model для обновленной задачи.
def test_model(input_data):
loaded_model = spacy.load("model_artifacts")
parsed_text = loaded_model(input_data)
if parsed_text.cats["pos"] > parsed_text.cats["neg"]:
prediction = "good"
score = parsed_text.cats["pos"]
else:
prediction = "bad"
score = parsed_text.cats["neg"]
return prediction
pred = df.translation.apply(test_model)
df['pred'] = pred
yy = df.iloc[:1999]
y_true = yy['type']
y_pred = yy['pred']
y_true[y_true == 'good'] = 1
y_true[y_true == 'bad'] = 0
y_pred[y_pred == 'good'] = 1
y_pred[y_pred == 'bad'] = 0
accuracy = sklearn.metrics.accuracy_score(y_true.astype(int), y_pred.astype(int))
f_score = sklearn.metrics.f1_score(y_true.astype(int), y_pred.astype(int))
print(f"Метрика accuracy составила: {accuracy:.3f}.")
print(f"F1-мера модели равна {f_score:.3f}.")
Метрика accuracy составила: 0.693.
F1-мера модели равна 0.735.
Несмотря на то что часть смыслового содержания скрадывается в результате машинного перевода с русского на английский, модель всё равно достаточно хорошо определяет тональность текстов.
>>> df[df['type'] == 'neutral']['pred'].value_counts()
good 559
bad 441
Name: pred, dtype: int64
Для нейтральных записей мы действительно получили один порядок числа положительных и негативных предсказаний – модель сомневается в разделении, ведь в ней не происходило обучения на нейтральных записях.
Если вам понравился этот материал, не забудьте поставить лайк. На сайте есть ряд других пошаговых туториалов по тематике Data Science, например:
- Генеративно-состязательная нейросеть: ваша первая GAN-модель на PyTorch
- Пишем нейросеть на Python с нуля
- Ещё один наш текст о библиотеке spaCy
А если мозг уже достаточно напрягся, есть несложный тест на знание того, что умеют нейросети.
Комментарии