
Интересное путешествие в теорию линейной регрессии с подходом Байеса вместе со студентом Йельского университета Tuan Doan Nguyen.

Оригинал: How Bayesian statistics convinced me to hit the gym.
Как следует из названия, Туан сделал научное исследование собственного тела. Что побудило его к этому?
Молодой человек приехал из Вьетнама, поступил в частную школу в Сингапуре, а затем в колледж в США. Его часто высмеивали за астеническое телосложение, все время советовали заняться спортом и набрать вес, чтобы выглядеть лучше. Не то чтобы Туана это очень волновало. При росте 169 см и весе 58 кг его индекс массы тела составлял 20.3, что близко к идеалу.

Но речь, конечно, шла не об ИМТ, а о конституции тела в целом.
Средний вьетнамский мужчина имеет рост 162 см при весе 58 кг. Туан чуть выше, но весит столько же. Естественно, что он выглядит более тощим. Простая логика: если растянуть что-то, сохранив его вес, оно станет заметно тоньше, чем было. Туан сформулировал следующий вопрос для дальнейшего обучения:
Насколько мало он весит для вьетнамского мужчины с ростом 169 см?
Подобное исследование требует хорошей методологии. Для начала полезно собрать как можно больше данных о параметрах других вьетнамцев.
Профиль населения Вьетнама
В интернете Туан нашел результаты исследования, собравшего демографическую информацию у 10 000 вьетнамцев. Он отобрал только мужчин в возрасте 18-29 лет. В результате получилась выборка размером 383 человека, вполне достаточная для анализа.
Сначала Туан решил определить, как он вписывается по весу в группу молодых вьетнамских мужчин.
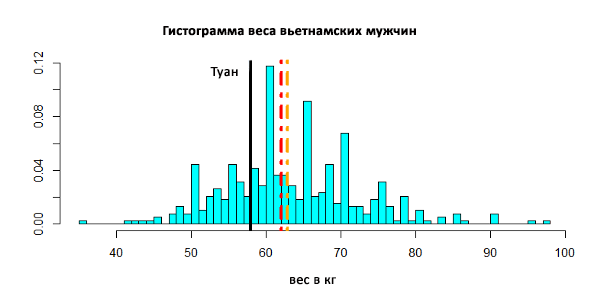
Красная линия на графике показывает медиану выборки, а оранжевая – среднее значение.
Очевидно, что вес молодого человека оказался немного ниже среднего. Но вопрос заключается не в простом сравнении. Важно сделать выводы относительно целой популяции, учитывая рост 168 см и предполагая, что все Вьетнамское мужское население представлено этими 383 людьми. Для этого Туану пришлось обратиться к регрессионному анализу.
Молодой человек построил двумерный график рассеяния высот и весов и отметил на нем себя:
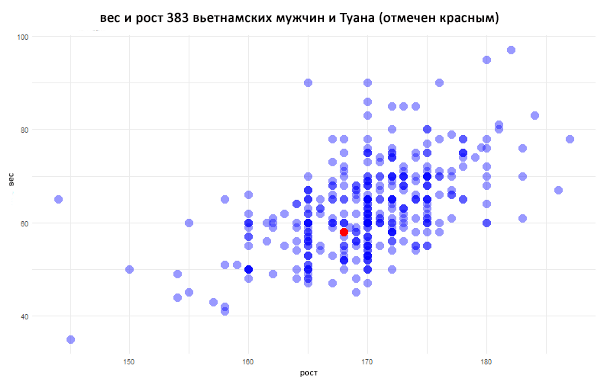
Он обнаружил, что находится где-то в центре. Если провести вертикальную линию через все точки, соответствующие 168 см роста, то красная окажется чуть ниже середины.
График выявил положительную линейную зависимость между высотой и весом вьетнамского мужчины. Чтобы разобраться в этом отношении, Туан решил провести количественный анализ. Сперва он добавил линию «наименьших квадратов». Подробнее об этом будет рассказано ниже.
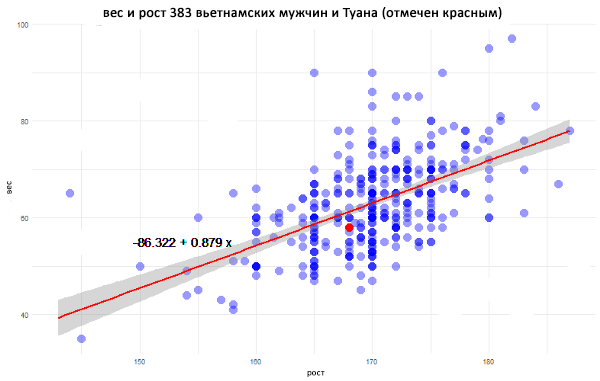
Линия соответствует формуле y = -86.32 + 0.879x и определяет зависимость веса среднего вьетнамского мужчины от его роста. При увеличении высоты на 1 см будет наблюдаться прибавка в весе 0.88 кг.
Однако это не отвечает на первоначальный вопрос. Считается ли вес 58 кг для человека с ростом 168 см слишком большим/слишком маленьким/примерно средним. Если есть распределение всех людей, имеющих рост 168 см, то какова вероятность того, что вес Туана попадет в 25, 50 или 75-й процентиль? Чтобы понять это, нужно немного углубиться в теорию регрессии.
Теория линейной регрессии
В линейной регрессионной модели ожидаемое значение переменной Y (вес человека) является линейной функцией от переменной x (рост). Назовем пересечение (свободный член) и наклон этой линейной зависимости β0 и β1 соответственно, то есть предположим, что E (Y | X = x) = β0 + β1*x. β0 и β1 здесь неизвестны.
В большинстве стандартных моделей линейной регрессии мы также предполагаем, что условное распределение Y при X = x является нормальным распределением.
Это означает, что простую модель линейной регрессии

можно переписать так:
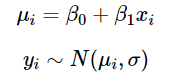
Обратите внимание, что во многих моделях параметр дисперсии σ можно заменить параметром точности τ, где τ = 1 / σ.
В итоге получается, что зависимая переменная Y имеет нормальное распределение, параметризованное средним значением μi и точностью τ. При этом μi – линейная функция X, параметризованная значениями β0 и β1.
Наконец, мы также предполагаем, что неизвестная дисперсия не зависит от x. Это называется гомоскедастичностью.
Все эти рассуждения довольно сложны. Возможно, график, составленный Joseph Chang из Йельского университета, поможет разобраться лучше.
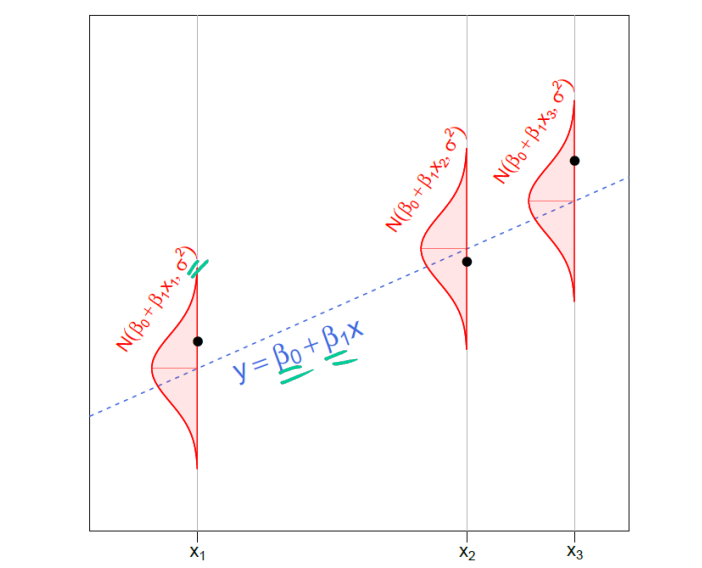
В реальности при анализе все, что мы имеем, – это черные точки данных на графике. Цель состоит в том, чтобы с их помощью сделать вывод о вещах, которые нам неизвестны, включая β0, β1 (таинственная синяя пунктирная линия) и σ (ширина красных нормальных плотностей). Обратите внимание, что нормальные распределения вокруг каждой точки идентичны. В этом суть гомоскедастичности.
Оценка параметров
Есть два способа оценить β0 и β1. Метод наименьших квадратов позволяет не беспокоиться о вероятностной формулировке. В этом случае оптимальные значения подбираются путем минимизации квадратичных погрешностей известных значений относительно прогнозируемых.
С другой стороны, можно оценить модель, используя метод максимального правдоподобия. В нем оптимальные значения параметров вычисляются путем максимизации функции правдоподобия:
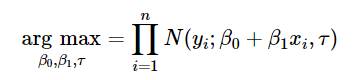
Есть еще один интересный результат, который здесь не продемонстрирован математически. Если предположить, что ошибки также имеют нормальное распределение, то оценки наименьших квадратов одновременно являются оценками максимального правдоподобия.
Линейная регрессия с подходом Байеса
В байесовском подходе используются предварительные (априорные) распределения и теорема Байеса:

Функция правдоподобия такая же, как и выше. Если включить в уравнение априорные распределения для параметров β0, β1, τо оно примет следующий вид:
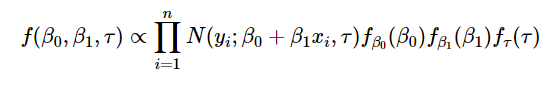
что это за априорная штука, и почему она делает формулу в 10 раз сложнее?
Априорные распределения кажутся странными, но на самом деле они интуитивно понятны. Существуют очень глубокие философские рассуждения о том, почему неизвестным параметрам (в данном случае β0, β1, τ) могут быть назначены, казалось бы, произвольные распределения. По сути, они предназначены для того, чтобы зафиксировать представления исследователя о ситуации до поступления данных. После ознакомления с новой информацией применяется правило Байеса. Оно позволяет получить апостериорное распределение, которое учитывает как априорное ожидание, так и поступившие данные. Это распределение, в свою очередь, может стать априорным для будущих наблюдений.
В подходе Байеса окончательная оценка зависит от информации, которая поступает из данных и предварительных предположений. Чем больше информации содержится в данных, тем менее влиятельными являются предположения.
Выбор априорного распределения
Значит, можно выбрать любое предварительное распределение?
Это хороший вопрос, так как существует неограниченное количество вариантов. Теоретически есть только одна правильная априорная вероятность. Однако на практике выбор предварительного распределения для формулы Байеса может быть довольно субъективным, а иногда и произвольным.
Можно просто выбрать нормальное распределение с большим стандартным отклонением и, следовательно, небольшой точностью. Например, предположим, что β0 и β1 исходят из нормального распределения со средним значением 0 и стандартным отклонением 10000 или что-то вроде этого. Такое априорное распределение называется неинформативным. По существу оно довольно плоское, то есть присваивает почти равное распределение любому значению в определенном диапазоне.
Если выбран этот тип, можно не беспокоиться о том, какое распределение лучше. Все они почти плоские в области большой вероятности, а области малой вероятности на апостериорное распределение не влияют.
Для точности τ известно, что она должна быть неотрицательной, поэтому имеет смысл выбрать распределение, ограниченное неотрицательными значениями. Например, можно использовать гамма-распределение с низкими параметрами формы и масштаба.
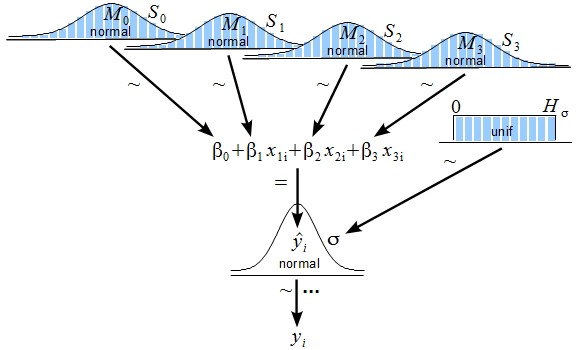
Другим полезным неинформативным выбором для формулы Байеса является равномерное распределение. Если выбрать его для σ или τ, можно получить модель, которая проиллюстрирована Джоном К. Крушке:
Моделирование с помощью R и JAGS
До сих пор все было хорошо в теории. Проблема в том, что решение уравнения, составленного по формуле Байеса является математически сложным. Нормальное и гамма-распределения сложны сами по себе, а для решения придется умножать их целыми сериями. В подавляющем большинстве случаев результат не будет доступен напрямую.
Для оценки параметров модели часто используются методы Монте-Карло по схеме Марковских цепей. Тут в дело вступает JAGS.
Неужели есть инструмент, который решает эти чудовищные уравнения?
Принцип работы JAGS состоит в том, что в процессе моделирования, основанном на Марковской цепочке Монте-Карло (MCMC), будет сгенерировано много итераций пространства параметров θ = (β0; β1; τ). Распределение для каждого образца будет аппроксимировать распределение для параметра в целом.
Почему так? Объяснение сложное и не поместится в рамки этой статьи. Очень упрощенно можно сказать, что MCMC строит Марковскую цепь, обладающую целевым апостериорным распределением. В результате получается выборка большого количества образцов из этого распределения.
Другими словами, вместо аналитически невозможного решения уравнения можно сделать некоторую интеллектуальную выборку с математическим доказательством того, что ее распределение является реальным распределением β0, β1, τ.
Магия JAGS
Чтобы запустить работу JAGS в R, сначала нужно описать модель в текстовом формате:
n <- nrow(data) #383 data points
mymodel <- "
model{
for(i in 1:n){
y[i] ~ dnorm(a + b*x[i], tau)
}
a ~ dnorm(0, 1e-6)
b ~ dnorm(0, 1e-6)
tau ~ dgamma(.01,.01)
sig <- 1/sqrt(tau)
}
"
Затем запускается моделирование. Например, здесь JAGs создает 10000 значений для пространства параметров θ.
jm <- jags.model(file = textConnection(mymodel), data=list(n=n, x=data$height, y=data$weight))
cs <- coda.samples(jm, c("a","b","sig"), 11000)
sample_data <- as.data.frame(cs[[1]][-(1:1000),])
В результате получается выборка данных для θ = (β0; β1; τ):
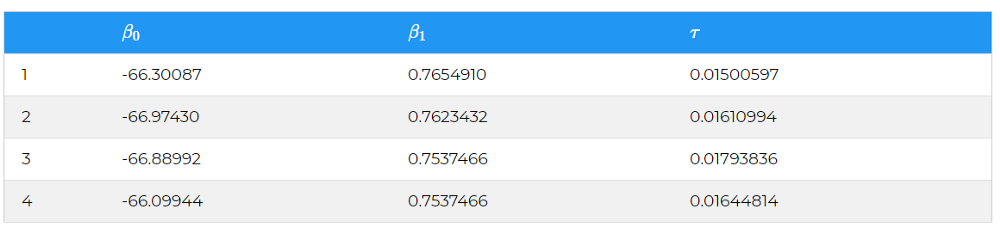
Отлично. И что теперь?
Теперь, когда у Туана появилось 10 000 итераций пространства параметров θ, он может применить формулу:
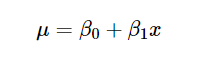
Если подставить x = 168 см в каждую итерацию, можно получить 10 000 значений веса и узнать, как распределяются веса для роста 168 см.
cmean <- sample_data$a + sample_data$b*m_height # "conditional mean"
Молодого человека интересовало распределение процентиля его веса.
m_perc <- pnorm(q = m_weight, mean = cmean, sd = sample_data$sig)
truehist(m_perc, main = "Posterior distribution for my weight percentile",
xlab = "percentile", ylab = "Frequency")
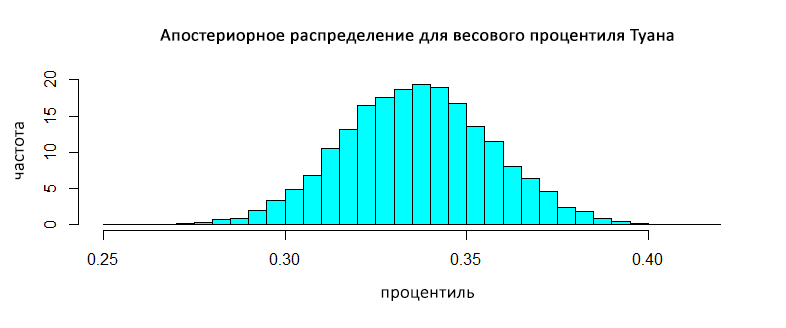
Таким образом, он узнал, что его вес (с учетом роста) находится примерно в 30-м процентиле вьетнамского населения.
Например, можно найти вероятность того, что вес Туана находится в 40-м процентиле или меньше:
mean(m_perc<=0.4) mean(m_perc)
Кажется, самое время пойти в спортзал и набрать немного веса. В конце концов, если нельзя доверять хорошему статистическому анализу по методу Байеса, то чему вообще можно доверять?
При желании вы можете провести такой же анализ для набора данных, в котором содержится рост и вес 8169 юношей и девушек в Америке (исследование 1997 года, National Longitudinal survey).
Весь R-скрипт, использованный в этой статье, можно найти на Github странице Туана.
Комментарии