

Думали ли вы когда-нибудь о важности стандартизации и сжатия текстовых данных? Добро пожаловать в мир агентов суммаризации!
Агенты суммаризации незаметно влились в нашу жизнь, сжимая информацию и предоставляя быстрый доступ к нужному контенту во множестве программ и платформ.
В этой статье мы узнаем о применении ChatGPT в качестве мощного агента суммаризации для наших приложений. Благодаря умению LLM обрабатывать и понимать текст, они могут помочь в чтении текстов, генерации верных аннотаций либо стандартизации информации. Тем не менее важно понимать, как воспользоваться их потенциалом и знать об их лимитах.
Каково главное ограничение суммаризации? LLM часто не справляются со следованием определённому лимиту символов или слов при написании аннотаций.
Давайте изучим лучшие практики генерации аннотаций с помощью ChatGPT для нашего приложения, а также узнаем, почему существуют эти ограничения и как их преодолеть.
Эффективная суммаризация с ChatGPT
Агенты суммаризации используются по всему интернету. Так, веб-сайты используют их для написания точных содержаний статей, позволяя пользователям получить краткую сводку новостей без прочтения всего текста. Это же делают соцсети и поисковые системы.
Начиная с RSS-агрегаторов и соцсетей и заканчивая сайтами электронной коммерции, агенты суммаризации прочно укрепились в нашем цифровом ландшафте. С продвижением LLM некоторые из этих агентов начали использовать ИИ, чтобы сделать суммаризацию более эффективной.
ChatGPT может здорово помочь во время создания приложения с использованием агентов суммаризации, ускоряя чтение и классификацию текстов. Представьте, что у нас есть бизнес в сфере электронной коммерции, и мы хотим обрабатывать все пользовательские отзывы. ChatGPT может помочь с суммаризацией любого отзыва в паре предложений, его приведением к одному формату, определением его тона и соответствующей классификацией.
Конечно, можно просто дать ChatGPT какой-либо отзыв, но существует список лучших практик — как и худших — для более эффективного его применения.
Пример: отзывы в электронной коммерции

Представьте вышеуказанный пример, где мы хотим обработать все отзывы на заданный продукт из нашего онлайн-магазина. Пусть это будет наш лучший товар: первый детский компьютер!
prod_review = """
I purchased this children's computer for my son, \
and he absolutely adores it. He spends hours exploring \
its various features and engaging with the educational games. \
The colorful design and intuitive interface make it easy for \
him to navigate. The computer is durable and built to \
withstand rough handling, which is perfect for active kids. \
My only minor gripe is that the volume could be a bit louder. \
Overall, it's an excellent educational toy that provides \
hours of fun and learning for my son. It arrived a day earlier\
than expected, so I got to play with it myself before I gave \
it to him.
"""
В этом случае мы бы хотели, чтобы ChatGPT:
- отнёс отзыв к положительным или отрицательным;
- дал аннотацию отзыва в 20 словах;
- дал ответ с определённой структурой, чтобы привести все отзывы к одному формату.
Примечания по реализации
Ниже представлена базовая структура кода, который можно использовать для дачи ChatGPT запроса из нашего приложения. Я также предоставляю ссылку на Jupyter Notebook со всеми используемыми в этой статье примерами.
import openai
import os
openai.api_key_path = "/path/to/key"
def get_completion(prompt, model="gpt-3.5-turbo"):
"""
Эта функция вызывает API ChatGPT с данным запросом
и возвращает ответ.
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0
)
return response.choices[0].message["content"]
user_text = f"""
<Любой текст>
"""
prompt = f"""
<Любой запрос с доп. текстом>
\"\"\"{user_text}\"\"\"
"""
# Простой вызов ChatGPT
response = get_completion(prompt)
Функция get_completion() вызывает API ChatGPT с помощью данного запроса. Если в запросе есть дополнительный пользовательский текст наподобие самого отзыва, он отделяется от остального кода тройными кавычками.
Используем функцию get_completion() для отправки запроса ChatGPT.
Приведём запрос, выполняющий вышеуказанные условия:
prompt = f"""
Your task is to generate a short summary of a product \
review from an e-commerce site. \
Summarize the review below, delimited by triple \
backticks, in exactly 20 words. Output a json with the \
sentiment of the review, the summary and original review as keys. \
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
Вот ответ от ChatGPT:
{
"sentiment": "positive",
"summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.",
"review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Как можно заметить из вывода, отзыв точен и хорошо структурирован, но в нём нет некоторой информации, в которой мы были бы заинтересованы, будучи владельцами онлайн-магазина, например, информации о доставке продукции.
Summarize с фокусом на <Shipping and Delivery>
Мы можем итеративно улучшить наш запрос, попросив ChatGPT сфокусироваться на конкретных вещах при написании аннотации. В этом случае нас интересуют любые детали перевозки и доставки:
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site. \
Summarize the review below, delimited by triple \
backticks, in exactly 20 words and focusing on any aspects \
that mention shipping and delivery of the product. \
Output a json with the sentiment of the review, \
the summary and original review as keys. \
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
Теперь ответ ChatGPT выглядит так:
{
"sentiment": "positive",
"summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.",
"review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Так отзыв более полон. Предоставление деталей о том, на чём стоит фокусироваться в оригинальном отзыве, очень важно, если мы хотим избежать потери важной для нас информации.
Заметили ли вы, что, хотя вторая попытка включает в себя информацию о доставке, в ней отсутствует один негативный аспект оригинального отзыва?
Исправим это!
Extract вместо Summarize
Изучая задачи по суммаризации, я узнала, что для LLM суммаризация может представлять трудности, если пользовательский запрос недостаточно точен.
При запросе от ChatGPT аннотации предложенного текста он может пропустить важную информацию — что с нами и случилось — или придавать одинаковое значение всем темам в тексте, давая обзор только основных моментов.
Эксперты в области LLM при решении подобных задач вместо summarize используют термин extract и дополнительную информацию о том, на чём фокусироваться.
Суммаризация нацелена на предоставление краткого обзора главных пунктов текста, включая темы, не связанные с тем, на чём фокусируется запрос. В то же время извлечение информации (information extraction) фокусируется на получении определённых деталей и может дать нам именно то, что нужно.
prompt = f"""
Your task is to extract relevant information from \
a product review from an ecommerce site to give \
feedback to the Shipping department. \
From the review below, delimited by triple quotes \
extract the information relevant to shipping and \
delivery. Use 100 characters. \
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
В этом случае, используя извлечение, мы получаем только информацию о нашей приоритетной теме: Shipping: Arrived a day earlier than expected.
Автоматизация
Эта система работает только для одного отзыва. Тем не менее при проектировании запроса для определённых нужд важно проводить тесты на наборе примеров, чтобы выловить в модели любые выбросы или аномалии.
В случае обработки нескольких отзывов посмотрим на примерную структуру кода на Python.
reviews = [
"The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!",
"I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.",
"The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.",
"I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.",
"The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
]
prompt = f"""
Your task is to generate a short summary of each product \
review from an e-commerce site.
Extract positive and negative information from each of the \
given reviews below, delimited by triple \
backticks in at most 20 words each. Extract information about \
the delivery, if included. \
Review: ```{reviews}```
"""
Вот аннотации для нашего набора отзывов:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
Это несоответствие в подсчёте слов происходит потому, что у LLM нет чёткого понимания подсчёта слов или символов. Причиной этого является один из главных компонентов их архитектуры: токенизатор.
Токенизатор
LLM наподобие ChatGPT предназначены для генерации текста на основе статистических моделей, извлечённых из огромного количества языковых данных. Они крайне эффективно генерируют беглый и связный текст, но у них нет чёткого контроля над количеством слов.
В примерах выше, когда мы давали инструкцию на очень чёткое количество слов, ChatGPT имел трудности с выполнением этого требования. Вместо этого он выдавал текст, который был короче заданного числа слов.
В других случаях он может генерировать более длинный текст, или просто текст слишком подробный или поверхностный. Кроме того, ChatGPT может отдавать предпочтение другим факторам, таким как связность и актуальность, вместо точного следования ограничению слов. Это может вылиться в текст, качественный с точки зрения содержания и связности, но не подходящий с точки зрения количества слов.
Токенизатор — это ключевой элемент архитектуры ChatGPT, который явно влияет на количество слов в сгенерированном выводе.

Архитектура токенизатора
Токенизатор — первый шаг в процессе генерации текста. Он отвечает за разделение текста, который мы даём ChatGPT, на отдельные элементы (токены), впоследствии обрабатываемые языковой моделью.
Когда токенизатор разделяет часть текста на токены, он руководствуется набором правил, предназначенных для определения значимых единиц заданного языка. Тем не менее эти правила не всегда идеальны, и могут быть случаи, когда токенизатор разделяет или соединяет токены так, что затрагивается общее число слов в тексте.
Например, посмотрите на предложение: «I want to eat a peanut butter sandwich». Если токенизатор настроен на разделение токенов на основе пробелов и пунктуации, он может разделить данное предложение на следующие токены с общим числом слов равным восьми, что совпадает с числом токенов.
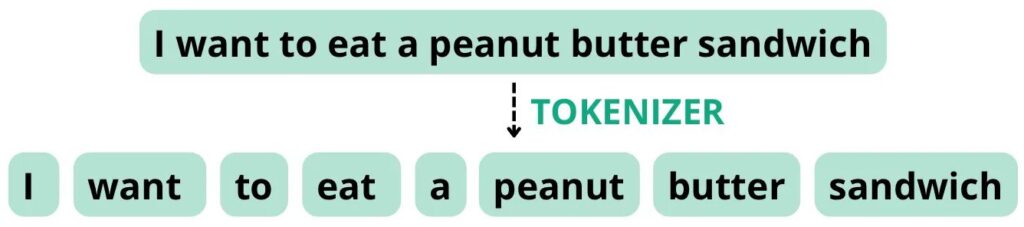
Однако, если токенизатор настроен на обращение с «peanut butter», как с составным словом, он может разбить предложение на следующие токены, где общее число слов равно восьми, а число токенов — семи.
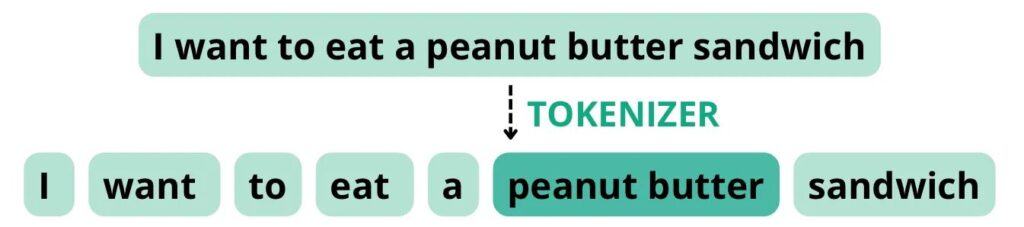
Таким образом, конфигурация токенизатора может повлиять на общее число слов в тексте, и это может отразиться на способности LLM следовать инструкциям по точному числу слов. Несмотря на то что некоторые токенизаторы позволяют кастомизировать то, как они токенизируют текст, этого не всегда достаточно для гарантии выполнения конкретных требований по количеству слов. В нашем случае мы не можем контролировать эту часть архитектуры ChatGPT.
Это делает ChatGPT не лучшим выбором для использования ограничений по символам либо словам, но можно попробовать ограничить число предложений, так как токенизатор влияет не на число предложений, а на их длину.
Понимание этих ограничений поможет создать наиболее подходящий для ваших нужд запрос. Учитывая всё вышесказанное, сделаем последнюю итерацию с нашим запросом.
В завершение: отзывы в электронной коммерции
Для лучшего вида запросим результаты в формате HTML:
from IPython.display import display, HTML
prompt = f"""
Your task is to extract relevant information from \
a product review from an ecommerce site to give \
feedback to the Shipping department and generic feedback from the product.
From the review below, delimited by triple quotes \
construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and \
delivery.
Review: ```{prod_review}```
"""
response = get_completion(prompt)
display(HTML(response))
Вот последний вывод от ChatGPT:

Итог
В этой статье мы обсудили лучшие практики использования ChatGPT в качестве агента суммаризации для нашего приложения.
Мы увидели, что во время проектирования приложения очень сложно с первого раза придумать запрос, который идеально подойдёт всем требованиям. Главное — думайте о создании запросов как об итеративном процессе, где вы улучшаете и моделируете свой запрос, пока не получите желаемый результат.
Итеративно совершенствуя ваш запрос и применяя его к набору примеров, прежде чем внедрять его, вы можете убедиться, что выводы согласуются между собой и покрывают выбросы. В нашем примере может случиться так, что кто-то даст случайный текст вместо отзыва. Можно дать ChatGPT распоряжение иметь стандартизированный вывод для исключения всех выбросов.
Кроме того, во время использования ChatGPT неплохо было бы изучить все плюсы и минусы использования LLM для выбранной цели. Так мы обнаружили, что извлечение лучше суммаризации в плане получения аннотации текста, похожей на человеческую речь. Мы также установили, что предоставление фокуса аннотации может разительно изменить генерируемый материал.
Наконец, хотя LLM крайне эффективны в генерации текста, они не идеальны в плане следования чётким инструкциям относительно количества слов или другим ограничениям формата. Для достижения этой цели возможно будет необходимо остановиться на количестве предложений или на других методах и инструментах, таких как ручное редактирование или более специализированное ПО.
Комментарии