
Статья освещает наиболее важные практики программирования на языке Python. Внимательно читайте каждый из пунктов, так как все они являются отличными советами!
Практики: производительность, память и удобство
Это обновленная версия моей предыдущей статьи с добавлением нескольких полезных практик, которые помогут оптимизировать ваш код на Python.
База исходного кода, которой соответствует лучшие современные практики, высоко ценится на сегодняшний день. Это отличный способ объединить крутых разработчиков при условии, что ваш проект имеет открытый исходный код. Как разработчику, вам бы хотелось писать эффективный и оптимизированный код, который:
Код, занимающий минимально возможное количество памяти, выполняется быстрее, выглядит более понятно, имеет качественную документацию, поддержку современных стандартов и такой код легок для понимания новым разработчикам.
Те практики, которые будут разобраны в данной статье, могут помочь вам: внести свой вклад в Open Source организацию, предоставить готовое решение на Online Judge, вести работу над большими задачами по обработке данных, используя машинное обучение, или вы сможете просто разрабатывать свой проект.
Практика 1: Старайтесь не расходовать память!
Простая программа на Python может не вызвать много проблем, но когда дело доходит до памяти, то её использование становится критической проблемой особенно для проектов с высоким потреблением памяти. Всегда рекомендуется запоминать любое использование памяти с самого начала работы над большим проектом.
В отличие от C/C++, за управление памятью в Python отвечает интерпретатор, вследствие этого пользователи не контролируют этот процесс (память). Управление памятью в Python включает в себя приватную кучу, которая состоит из всех Python-объектов и структур данных.
Менеджер памяти в Python предоставляет внутренний доступ к приватной куче. При создании объекта виртуальная машина Python (PVM) выделяет нужное количество памяти и решает, куда в памяти этот объект будет помещен.
Так или иначе, глубокое понимание того, как все устроено и знание того, какие существуют способы работы с памятью, помогут вам минимизировать затрачиваемое количество памяти в вашем приложении.
Используйте генераторы для вычисления большого количества результатов:
Генераторы дают возможность производить «ленивые» вычисления. Суть использования такого вычисления заключается в итерации: как с помощью явного использования “for”, так и неявного. For просто передает это вычисление любой функции или конструкции, которая и осуществляет итерацию.
Вы можете подумать, что генераторы возвращают любое количество элементов наподобие списка, однако вместо того, чтобы возвращать их все сразу они возвращаются один за другим. Функция генератора останавливается до тех пор, пока следующий элемент не будет запрошен. Здесь вы можете, более подробно, ознакомится с генераторами в Python.
- Для обработки большого объема чисел и/или данных вы можете использовать библиотеку наподобие Numpy, которая отлично управляет ресурсами памяти;
- Не используйте + для создания длинных строк. В Python строка является неизменяемой, поэтому строки слева и справа от исходной будут скопированы в новую строку для каждой подобной пары конкатенации. Если вы конкатенируете четыре строки каждая длинной 10, то у вас получится следующая сумма: (10+10) + ((10+10)+10) + (((10+10)+10)+10) = 90, и получается вместо 40 целых 90 символов. Объем квадратично увеличивается в зависимости от размера и количества строк. Например, Java оптимизировала эту задачу, трансформировав наборы конкатенаций, за счет использования StringBuilder, но Python нет. По этой причине, рекомендуется использовать .format или % для конкатенации строк, несмотря на то, что при конкатенации коротких строк + работает быстрее. Или даже лучше, если у вас уже есть содержимое в виде итеративного объекта, используйте «.join (iterable_object), который намного быстрее.
Если вы все-таки не можете выбрать между .format и %, то обратите внимание на данное обсуждение на StackOverflow.
def add_string_with_plus(iters):
s = ""
for i in range(iters):
s += "xyz"
assert len(s) == 3*iters
def add_string_with_format(iters):
fs = "{}"*iters
s = fs.format(*(["xyz"]*iters))
assert len(s) == 3*iters
def add_string_with_join(iters):
l = []
for i in range(iters):
l.append("xyz")
s = "".join(l)
assert len(s) == 3*iters
def convert_list_to_string(l, iters):
s = "".join(l)
assert len(s) == 3*iters
Вывод:
>>> timeit(add_string_with_plus(10000)) 100 loops, best of 3: 9.73 ms per loop >>> timeit(add_string_with_format(10000)) 100 loops, best of 3: 5.47 ms per loop >>> timeit(add_string_with_join(10000)) 100 loops, best of 3: 10.1 ms per loop >>> l = ["xyz"]*10000 >>> timeit(convert_list_to_string(l, 10000)) 10000 loops, best of 3: 75.3 µs per loop
- Используйте slots для определения класса в Python. Вы можете “сказать” Python не использовать динамический словарь(dict), и вместо этого просто выделить место под ограниченное количество атрибутов, исключая использование для каждого объекта своего словаря, путем установления каждому классу __slots__ для ограничения списка имен атрибутов. Slots также предотвращают произвольное присвоение атрибута объекту, таким образом, форма объекта остается неизменной на всем протяжении жизни программы. Более подробно ознакомиться с slots можно здесь;
- Вы можете отслеживать использование памяти в вашей программе на уровне объектов при помощи встроенного модуля наподобие resource и objgraph;
- Управление утечками памяти в Python это может стать трудновыполнимой задачей, но к счастью есть инструменты наподобие heapyдля отладки утечек памяти. Heapy может использоваться совместно с objgraph для наблюдения за увеличением размера объектов с течением времени. Heapy может показывать, какие объекты занимают больше всего памяти. Objgraph может помочь найти обратные ссылки для того, чтобы лучше понять, почему мы не можем освободить память из-под них. Здесь вы можете, более подробно, ознакомится с диагностикой утечек памяти в Python.
Вы можете более подробно почитать об управлении памятью на ресурсе для разработчиков Theano.
Практика 2: Пишите красивый код, так как «Первое впечатление – Последнее впечатление».
Общедоступный код – это очень полезно. Вне зависимости от мотивации, ваши старания могут оказаться напрасными, если ваш код окажется сложным для понимания или использования другими. Практически каждая организация придерживается своих требований написания кода, которым разработчики должны следовать для сохранения ясности и структурированности проектов, и их легкой отладки в случае возникновения проблем. Zen of Python (Дзен Питона) – это что-то вроде мини-инструкции и краткого руководства по оформлению кода для Python. Популярные инструкции по оформлению кода включают в себя:
- PEP-8 инструкция по оформлению кода
- Идиомы и Эффективность в Python
- Инструкции по оформлению кода от Google для Python
В этих инструкциях идет обсуждение того, как использовать: пробелы, запятые, именование объектов и т.д. Несмотря на то, что возможны конфликты в некоторых ситуациях, цель у всего этого одна – «Чистые, читаемые и отлаживаемые стандарты оформления кода».
Применяйте одну из инструкций, или следуйте своей, но не отходите кардинально от общепринятых стандартов.
Использование инструментов статического анализа кода
Существует множество доступных инструментов с открытым исходным кодом, которые вы можете использовать для написания кода соответствующего общепринятым стандартам оформления и написания кода.
Pylint – это инструмент, предназначенный для проверки модулей в Python на соответствие стандартам оформления кода. Pylint может легко и быстро просматривать код на соответствие основным требованиям PEP-8 и, следовательно, ваш код будет дружественным по отношению к потенциальным пользователям.
Также этот инструмент представляет подробный отчет с метрикой и статистикой, которая может помочь вам более объективно оценить качество кода. Кроме того, вы можете персонализировать Pylint под себя путем создания собственного .pylintrc файла, и использовать его.
Pylint – это не единственный инструмент. Существуют и другие инструменты наподобие: PyChecker, PyFlakes и пакеты: pep8 и flakes8.
Лично я рекомендую использовать coala – единый фреймворк для статистического анализа кода, целью которого является обеспечение независимого анализа кода за счет использования одного фреймворка. Coala поддерживает все вышесказанные проверки соблюдения стандартов оформления кода, и кроме того, имеет обширные возможности персонализации.
Документируйте код должным образом
Данный аспект является наиболее критичным в вопросе удобства использования и читаемости вашей базы исходного кода. Зачастую рекомендуется документировать код настолько подробно, насколько это возможно (в адекватных пределах), таким образом сторонние разработчики не будут тратить время на то, чтобы разобраться в вашем коде.
Стандартный вид встроенной документации функции должен включать в себя:
- Одну строчку, содержащую краткое изложение работы функции;
- Интерактивные примеры, если они имеют место быть. Такие примеры помогут стороннему разработчику быстро обозреть работу функции и увидеть, что получается на выходе после её работы. В дополнение к этому используйте модуль doctest для проверки этих примеров на корректность (работает как тесты). Для примера посмотрите документацию модуля doctest;
- Документирование параметров функции (обычно это одна строчка, отвечающая за описание параметра и его роль в функции);
- Документирование возвращаемых типов (разве что ваша функция ничего не возвращает!).
Sphinx является общепринятым инструментом для создания и управления документацией вашего проекта. Он предлагает множество удобных фичей, которые уменьшат ваши усилия по написанию документации, соответствующую всем стандартам. Более того, вы можете бесплатно публиковать вашу документацию на портале Read the Docs, который является наиболее распространенным ресурсом по хранению документации.
Документация- путеводитель по Python Hitchiker's состоит из набора интересной информации, которая может быть полезной при документации вашего кода.
Практика 3: Увеличивайте производительность вашей программы
Многопроцессорная система, не многопоточная
При возникновении вопроса об улучшении времени выполнения вашего многозадачного кода вы, возможно, захотите использовать возможности многоядерности вашего CPU, чтобы выполнять несколько задач одновременно. Может показаться, что наиболее правильным будет создать несколько потоков и дать им возможность работать одновременно, но из-за Global Interpreter Lock (способ синхронизации потоков) в Python, все ваши потоки будут выполняться на одном ядре один за другим.
Для распараллеливания процессов в Python вы можете использовать мультипроцессорный модуль. Альтернативным решением может быть передача выполнения задач на:
- Операционную систему (путем многопроцессорной обработки);
- Некоторым внешним приложениям, которые обращаются к вашему Python коду (например, Spark или Hadoop);
- Коду, который обращается к вашему Python коду (к примеру, у вас есть ваш Python код, вызывающий функцию языка C, которая отвечает за выполнение всего объема многопоточных задач).
Кроме параллельного программирования, существуют и другие способы увеличения производительности вашей программы. Некоторые из них включают в себя следующие пункты:
- Используйте последнюю версию Python: Это самый просто способ, потому что обновления, зачастую, содержат расширения уже существующих функциональных возможностей, и обычно эти расширения связаны с увеличением производительности;
- Используйте встроенные функции языка везде, где это возможно: Такой подход соответствует принципу DRY – встроенные функции тщательно проработаны и проверены лучшим Python разработчиками в мире, поэтому их использование, чаще всего, является наиболее верным;
- Рассмотрите возможность использования Ctypes: Ctypes предоставляет интерфейс для вызова C-shared функций. C – это язык программирования близкий к машинному уровню, который значительно увеличивает производительность вашей программы, по сравнению с простым решениями в Python;
- Используйте Cython: Cython – это расширенная версия языка программирования Python, который позволяет вам вызывать функции языка C, иметь возможность объявления статических типов, что в конечном итоге приводит к более простому коду, который скорее всего будет выполняться намного быстрее;
- Используйте PyPy: PyPy – это еще одна Python реализация, имеющая JIT (just-in-time) компилятор, который поможет ускорить выполнение вашего кода. Хотя я лично никогда не использовал PyPy, разработчики PyPy утверждают, что их продукт снижает использование памяти вашей программой. Компании наподобие Quora используют PyPy в своих продуктах;
- Проектирование и структура данных: Данный пункт относится ко всем языкам. Убедитесь в том, что вы используете подходящие структуры данных для реализации ваших целей, объявляйте переменные в корректных местах, разумно используйте область видимости идентификаторов, и сохраняйте ваши результаты в кэше там, где это возможно и т.д.
Конкретный пример языка, который я бы мог дать: Python – это медленный язык с доступом к глобальным переменным и преобразованием адресов функции, поэтому быстрее будет назначить их локальной переменной в вашей области видимости и затем уже без проблем получить к ним доступ.
Практика 4: Выбирайте правильную версию!
Python2.x или Python3.x?
С одной стороны, Python третьей версии имеет ряд отличных новых возможностей. С другой стороны, вы можете хотеть использовать пакеты, которые имеют поддержку только во второй версии Python, наподобие пакета от Apple coremltools. Кроме того, Python3 не совместим с прежними версиями, то есть не является обратно совместимым. Это значит, что если вы запустите код проекта версии Python2 на интерпретаторе Python3.х, то это, скорее всего, приведет к появлению ошибок.
При старте нового проекта рекомендуется использовать последний релиз Python, однако, если по какой-то причине вы должны придерживаться Python 2.x, то в таком случае вам придется писать код, который будет работать как на интерпретаторах Python2, так и на Python3. Наиболее распространённым способом решение этой задачи является использование пакетов наподобие future, builtins, и six для поддержки единой понятной Python3.x совместимой кодовой базы, которая поддерживает как Python2, так и Python3 с минимальными издержками.
Python-future – это недостающий уровень совместимости между Python2 и Python3. Данный уровень обеспечивает поддержку future и past пакетов для применения более старых и новых патчей с поддержкой возможностей обеих версий Python3 и Python2. Также этот уровень распространяется совместно с futurize и pasteurize, которые нужны для преобразования скриптов второй версии в третью, что в дальнейшем помогает преобразовывать остальной код аналогичным образом модуль за модулем. В итоге получается единая и понятная база исходного кода на Python3.
Пожалуйста, ознакомьтесь с отличной Памяткой по написанию обратно совместимого кода от Ed Schofield. Если вы предпочитаете просмотр видео чтению статей, то вы можете найти его речь, с PyCon AU 2014, «Написание обратно совместимого кода Python2/3», полезной.
Выполнение требований вашего pip
Как правило, все pip зависимости проекта определены в специальном файле, названным requirements.txt, который располагается в корне вашего проекта. Любой другой человек, который хочет запустить ваш проект, может просто установить все требуемые зависимости, используя этот файл, с помощью команды pip install -r requirements.txt. Также хорошей практикой считается размещение всех необходимых зависимостей для проведения тестов в отдельный файл с названием test-requirements.txt.
Обратите внимание, что pip не использует requirements.txt, если ваш проект был установлен в качестве зависимости для других проектов. Обычно для этого, вам необходимо определить специальные зависимости в install_requires и tests_require аргументах функции setuptools.setup вашего setup.py файла. Если вы хотите поддерживать стандартный файл зависимостей для обоих пакетов и разработки, то вам необходимо сделать что-то подобное этому:
import os
from setuptools import setup
with open('requirements.txt') as f:
required = f.read().splitlines()
setup(...
install_requires=required,
...)
Кроме того, иногда, «свежие» обновления любой из зависимостей могут «сломать» ваш проект. По этой причине, из соображений безопасности, рекомендуется «замораживать» версии ваших зависимостей. Обратите внимание на этот пост от Kenneth Reitz, в котором ведется обсуждение простого и в тоже время отличного рабочего процесса, описывающего то, как управлять версиями зависимостей вашего проекта.
Используйте виртуальную среду
Для того чтобы избежать конфликта версий ваших зависимостей при разработке нескольких проектов рекомендуется использовать Виртуальные среды (легко устанавливаются и является автономными в Python). По тем же самым причинам я выше упомянул то, что изменение версий ваших зависимостей может привести к «поломке» отдельных частей проекта. Еще раз повторюсь, что их очень легко устанавливать! В путеводителе по Python Hitchiker's обсуждаются некоторые основы их использования. Ознакомиться с ними можно здесь.
Ведите контроль версий вашего проекта
Вы можете ознакомиться с семантическим контролем версий здесь. Посмотрите данный туториал, в котором описываются различные способы контроля версий вашего проекта в вашем пакете.
Практика 5: Анализ кода
Очень полезной привычкой является анализ собственного кода на предмет его приемлемости, качества и производительности. В Python есть встроенный модуль cProfile, который предназначен для оценки производительности. Результатом его оценки будет не только суммарное время работы, но и время работа каждой функции.
Это время показывает сколько раз функция была вызвана, что позволяет легко определять, где необходимо провести оптимизацию. Далее приведен простой пример того, как выглядит анализ модуля cProfile:
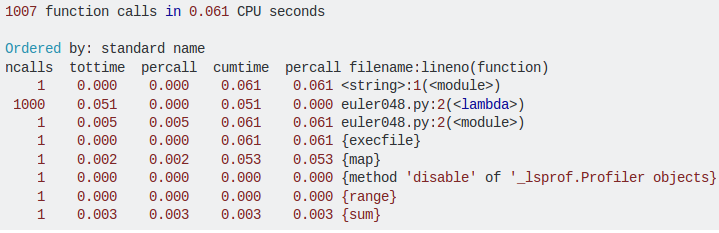
- memory_profiler – это Python модуль, который предназначен для мониторинга расхода памяти процессами, также модуль может производить анализ каждой строчки на предмет потребления памяти;
- objgraph – модуль, позволяющий просматривать наиболее ресурсоемкие объекты Python программ, какие объекты были добавлены/удалены и все ссылки на этот объект в вашем скрипте;
- resource– модуль, обеспечивающий основные механизмы для измерения и управления системными ресурсами, используемыми программой. Модуль имеет два основных применения: ограничение распределяемых ресурсов и получение информации о текущем распределении ресурсов.
Практика 6: Тестирование и дальнейшая интеграция
Тестирование:
Хорошей практикой является написание unit-тестов. Если вы считаете, что написание тестов не дает никакого эффекта, то обратите внимание на данное обсуждение на StackOverflow. Лучше всего написать тесты до или во время кодинга. В Python есть unittest модули, предназначенные для написания unit-тестов для ваших классов и функций. Также есть фреймворки наподобие:
- nose – может запускать unittest-тесты и не является шаблонным;
- pytest – также может запускать unittest-тесты, и не является шаблонным, более продвинутая система отчетов и множество крутых фич.
Для более наглядного сравнения среди них можете прочитать инструкцию здесь.
Также не забывайте модуль doctest, который можете тестировать ваш исходный код, используя интерактивные примеры, описанные во встроенной документации.
Измерение покрытия:
Coverage это инструмент для измерения покрытия программного кода Python. Coverage просматривает вашу программу и помечает какие фрагменты кода уже выполнились, после этого он анализирует исходный код, чтобы понять почему некоторые фрагменты кода не выполнились.
Измерение покрытия используется для того, чтобы проверить эффективность тестов. Она может выявить, какие фрагменты вашего кода используются тестами, а какие нет. Обычно рекомендуется, чтобы ваши тесты покрывали 100% ветвей. Это означает, что данный метод тестирования, позволяет гарантировать, что каждая ветвь программы будет пройдена хотя бы один раз.
Дальнейшая интеграция:
Наличие CI-системы на начале вашего проекта может быть очень полезно для дальнейшего его развития. Вы с легкостью можете протестировать различные аспекты вашей базы исходного кода, используя CI-сервис. Стандартная проверка CI включает в себя:
- Запуск тестов в реальной рабочей среде. Бывают ситуации, когда тесты успешно проходят на одной архитектуре, но не работают на других. CI-сервис дает возможность проводить тесты на различных архитектурах;
- Предоставляет возможность ограничивать покрытие вашей базы исходного кода;
- Построение и развертывание вашего кода в продакшн, кроме того, вы можете делать это на различных платформах.
На данный момент существует несколько CI-сервисов. Вот некоторые наиболее популярные из них: Travis, Circle (для OS X и Linux) и Appveyor (для Windows). Также можно обратить на недавно вышедший Semaphore CI, который, по моему личному использованию, выглядит надежным. Gitlab (еще одна платформа для управления git-репозиториями, наподобие GitHub) также имеет поддержку CI, для этого вам просто необходимо явно её настроить, также как и другие сервисы.
Уточнение: Данная статья была полностью основана на моем личном опыте, поэтому в ней может быть много чего упущено из виду (или просто я не обратил на это должного внимания). В данном обсуждении вы также можете найти для себя что-то полезное, чего не достает в моей статье.
Ссылка на оригинальную статью
Перевод: Александр Давыдов

Комментарии