
Разберем принципы NLP и научим компьютер понимать человеческий язык. Составим пайплайн для анализа текстов и реализуем его с библиотекой spaCy.
Компьютеры замечательно работают со структурированной информацией, например таблицами в базах данных. Но люди общаются друг с другом не таблицами, а словами. Для компьютеров это слишком сложно.
Большая часть информации в мире не структурирована – это просто тексты на английском или любом другом языке. Можно ли научить машины извлекать из них важные данные? Этой проблемой занимается особое направление искусственного интеллекта: обработка естественного языка, или NLP (Natural Language Processing). В статье мы разберемся, как это работает. А для примера напишем программу на языке Python для извлечения информации из неструктурированного текста.
Если вы не хотите углубляться в работу NLP, а просто ищете, откуда можно скопировать готовый код, то прокрутите статью вниз до раздела Пайплайн NLP на Python.

Могут ли компьютеры понимать язык?
С самого начала эпохи компьютеров разработчики стараются научить их понимать обычные языки, например, английский. В течение тысяч лет люди что-то писали, и было бы здорово поручить машинам чтение и разбор всех этих данных.
К сожалению, компьютеры не могут в полной мере понимать живой человеческий язык, однако они на многое способны. NLP может делать по-настоящему волшебные вещи и экономить огромное количество времени.
Совсем замечательно то, что последние разработки в области NLP доступны в открытых библиотеках Python, например, в spaCy, textacy и neuralcoref. То, что вы можете сделать с их помощью парой строчек кода, совершенно невероятно.
Извлечение смысла
Процесс чтения и понимания английского текста сам по себе очень сложен. Кроме того, люди часто не соблюдают логику и последовательность повествования. Например, что может значить вот этот заголовок новостей?
Environmental regulators grill business owner over illegal coal fires.
Регуляторы допрашивают владельца бизнеса о незаконном сжигании угля? А может быть, они в буквальном смысле готовят его на гриле? Вы догадались, а сможет ли компьютер?
Реализация какой-либо сложной комплексной задачи в машинном обучении обычно означает построение пайплайна (конвейера). Смысл этого подхода в том, чтобы разбить проблему на очень маленькие части и решать их отдельно. Соединив несколько таких моделей, поставляющих друг другу данные, вы можете получать замечательные результаты.
Именно эту стратегию мы будем использовать для примера. Cначала нужно разбить процесс языкового анализа на стадии и понять, как они работают.
NLP пайплайн шаг за шагом
Давайте взглянем на следующий отрывок, взятый из Википедии:
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.
В этом параграфе содержится несколько полезных фактов. Хотелось бы, чтобы компьютер смог понять, что Лондон – это город, что он расположен в Англии, был основан римлянами и т. д. Но прежде всего мы должны научить его самым базовым концепциям письменного языка.
Шаг 1. Выделение предложений
Первый этап пайплайна – разбить текст на отдельные предложения. В результате получим следующее:
- London is the capital and most populous city of England and the United Kingdom.
- Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.
- It was founded by the Romans, who named it Londinium.
Можно предположить, что каждое предложение – это самостоятельная мысль или идея. Проще научить программу понимать единственное предложение, а не целый параграф.
Можно было бы просто разделять текст по определенным знакам препинания. Но современные NLP пайплайны имеют в запасе более сложные методы, подходящие даже для работы с неформатированными фрагментами.
Шаг 2. Токенизация, или выделение слов
Теперь мы можем обрабатывать полученные предложения по одному. Начнем с первого:
London is the capital and most populous city of England and the United Kingdom.
Следующий шаг конвейера – выделение отдельных слов или токенов – токенизация. Результат на этом этапе выглядит так:
«London», «is», «the», «capital», «and», «most», «populous», «city», «of», «England», «and», «the», «United», «Kingdom», «.»
В английском языке это несложно. Мы просто отделяем фрагмент текста каждый раз, когда встречаем пробел. Знаки препинания тоже являются токенами, поскольку могут иметь важное значение.
Шаг 3. Определение частей речи
Теперь посмотрим на каждый токен и постараемся угадать, какой частью речи он является: существительным, глаголом, прилагательным или чем-то другим. Зная роль каждого слова в предложении, можно понять его общий смысл.
На этом шаге мы будем анализировать каждое слово вместе с его ближайшим окружением с помощью предварительно подготовленной классификационной модели:

Эта модель была обучена на миллионах английских предложений с уже обозначенными частями речи для каждого слова и теперь способна их распознавать.
Имейте в виду, что этот анализ основан на статистике – на самом деле модель не понимает смысла слов, вложенного в них человеком. Она просто знает, как угадать часть речи, основываясь на похожей структуре предложений и ранее изученных токенах.
После обработки получаем следующий результат:

С этой информацией уже можно начинать анализировать смысл. Например, мы видим существительные «London» и «capital», вероятно, в предложении говорится о Лондоне.
Шаг 4. Лемматизация
В английском и большинстве других языков слова могут иметь различные формы. Взгляните на следующий пример:
I had a pony.
I had two ponies.
Оба предложения содержат существительное «pony», но с разными окончаниями. Если тексты обрабатывает компьютер, он должен знать основную форму каждого слова, чтобы понимать, что речь идет об одной и той же концепции пони. Иначе токены «pony» и «ponies» будут восприняты как совершенно разные.
В NLP этот процесс называется лемматизацией – нахождением основной формы (леммы) каждого слова в предложении.
То же самое относится к глаголам. Мы можем привести их к неопределенной форме. Таким образом, предложение «I had two ponies» превращается в «I [have] two [pony]».
Лемматизация обычно выполняется простым поиском форм в таблице. Кроме того, можно добавить некоторые пользовательские правила для анализа слов.
Вот так выглядит наше предложение после обработки:

Единственное изменение – превращение «is» в «be».
Шаг 5. Определение стоп-слов
Теперь мы хотим определить важность каждого слова в предложении. В английском очень много вспомогательных слов, например, «and», «the», «a». При статистическом анализе текста эти токены создают много шума, так как появляются чаще, чем остальные. Некоторые NLP пайплайны отмечают их как стоп-слова и отсеивают перед подсчетом количества.
Теперь наше предложение выглядит следующим образом:

Для обнаружения стоп-слов обычно используются готовые таблицы. Однако нет единого стандартного списка, подходящего в любой ситуации. Игнорируемые токены могут меняться, все зависит от особенностей проекта.
Например, если вы решите создать движок для поиска рок-групп, вероятно, вы не станете игнорировать артикль «the». Он встречается в названии множества коллективов, а одна известная группа 80-х даже называется «The The!».
Шаг 6. Парсинг зависимостей
Теперь необходимо установить взаимосвязь между словами в предложении. Это называется парсингом зависимостей. Конечная цель этого шага – построение дерева, в котором каждый токен имеет единственного родителя. Корнем может быть главный глагол.
После первого подхода мы имеем следующую схему:
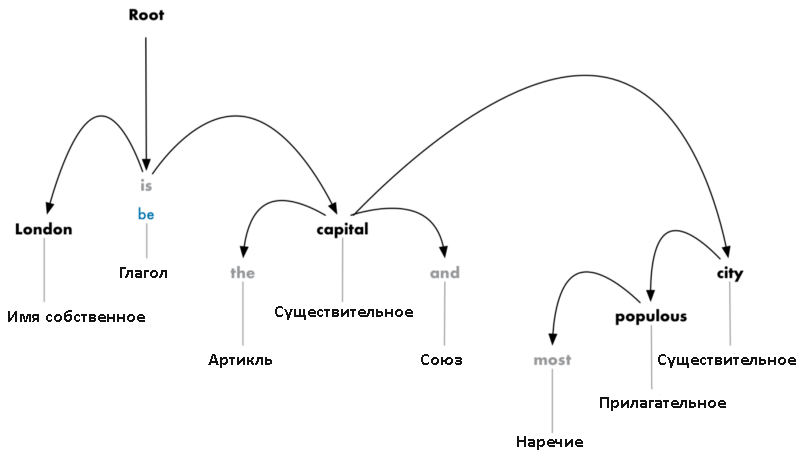
Но следует сделать еще кое-что. Нужно не только определить родителя, но и установить тип связи между двумя словами:
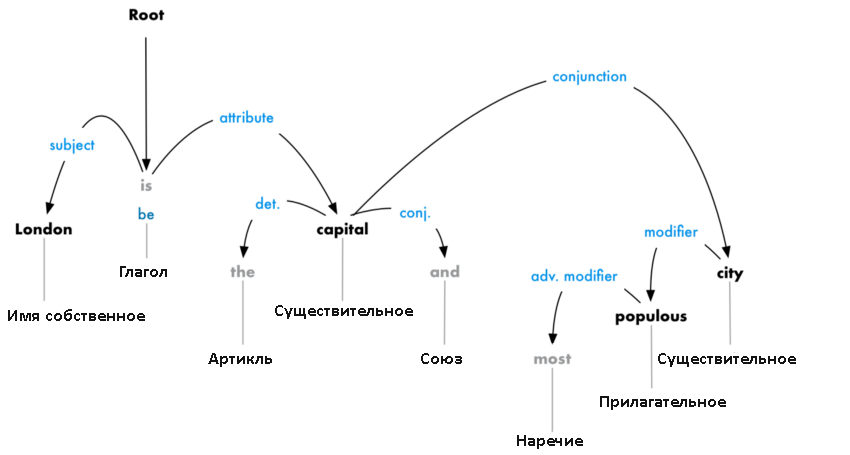
Это дерево парсинга демонстрирует, что главный субъект предложения – это существительное «London». Между ним и «capital» существует связь «be». Вот так мы узнаем, что Лондон – это столица! Если бы мы проследовали дальше по веткам дерева (уже за границами схемы), то могли бы узнать, что Лондон – это столица Соединенного Королевства.
Помните, как мы ранее определяли части речи с помощью модели машинного обучения? Парсинг зависимостей работает примерно так же. Модель получает слова и возвращает результат. Однако это более сложная задача. Чтобы объяснить все детали, потребовалась бы отдельная статья. Если вам действительно интересно, как это работает, взгляните на великолепный материал Parsing English in 500 Lines of Python от Matthew Honnibal.
Обратите внимание, несмотря на авторскую заметку от 2015 года, утверждающую, что описанный подход актуален, сейчас он уже устарел и не используется. В 2016 году компания Google выпустила парсер зависимостей Parsey McParseface. Он ушел далеко вперед от всех своих аналогов благодаря новым методам глубокого обучения и быстро распространился по всей отрасли. Год спустя появилась новая модель ParseySaurus, еще более продвинутая. Другими словами, технологии парсинга активно развиваются и постоянно улучшаются.
Также важно помнить, что многие английские предложения неоднозначны и сложны для анализа. В таких случаях модель делает предположение о наиболее вероятном значении, хотя это не всегда получается. В будущем наши NLP-модели будут совершенствоваться и более разумно обрабатывать тексты.
Хотите провести парсинг зависимостей для вашего собственного предложения? Взгляните на это чудесное интерактивное демо от команды spaCy.
Шаг 6б. Поиск групп существительных
Сейчас мы рассматриваем каждое слово в нашем предложении как отдельную сущность. Но иногда имеет смысл сгруппировать токены, которые относятся к одной и той же идее или вещи. Мы можем использовать полученное дерево парсинга, чтобы автоматически объединить такие слова.
Например, вместо этого:
Можно получить такой результат:

Это необязательный шаг. Группировку можно делать или не делать в зависимости от конечной цели проекта. Часто это быстрый и удобный способ упростить предложение, если вместо максимально подробной информации о словах мы стремимся извлечь законченные идеи.
Шаг 7. Распознавание именованных сущностей (Named Entity Recognition, NER)
Мы уже сделали всю сложную работу, наконец-то можно перейти от школьной грамматики к реально интересным задачам.
В нашем предложении присутствуют следующие существительные:
![]()
Некоторые из них обозначают реальные вещи. Например, «London», «England» и «United Kingdom» – это точки на карте. Было бы здорово определять их! При помощи NLP мы можем автоматически извлекать список реальных объектов, упомянутых в документе.
Цель распознавания именованных сущностей – обнаружить такие существительные и связать их с реальными концепциями. После обработки каждого токена NER-моделью наше предложение будет выглядеть вот так:

NER-системы не просто просматривают словари. Они анализируют контекст токена в предложении и используют статистические модели, чтобы угадать какой объект он представляет. Хорошие NER-системы способны отличить актрису Brooklyn Decker от города Brooklyn.
Большинство NER-моделей распознают следующие типы объектов:
- имена людей;
- названия компаний;
- географические обозначения (и физические, и политические);
- продукты;
- даты и время;
- денежные суммы;
- события.
Так как эти модели позволяют легко извлекать из сплошного текста структурированные данные, они очень активно используются в разных областях. Это один из самых простых способов извлечения выгоды из NLP-конвейера.
Хотите сами поиграть с распознаванием именованных сущностей? Тогда вам сюда: в еще один замечательный интерактивный демо-зал от spaCy.
Шаг 8. Разрешение кореференции
У нас уже есть отличное и полезное представление анализируемого предложения. Мы знаем, как связаны друг с другом слова, к каким частям речи они относятся и какие именованные объекты обозначают.
И все-таки у нас большая проблема. В английском очень много местоимений – слов вроде he, she, it. Это сокращения, которыми мы заменяем на письме настоящие имена и названия. Человек может проследить взаимосвязь этих слов от предложения к предложению, основываясь на контексте. Но NLP-модель не знает о том, что означают местоимения, ведь она рассматривает всего одно предложение за раз.
Давайте посмотрим на третью фразу в нашем документе:
It was founded by the Romans, who named it Londinium.
Если мы пропустим ее через конвейер, то узнаем, что «это» было основано римлянами. Не очень полезное знание, правда?
Вы сами легко догадаетесь в процессе чтения, что «это» не что иное как Лондон. Разрешением кореференции называется отслеживание местоимений в предложениях с целью выбрать все слова, относящиеся к одной сущности.
Вот результат обработки документа для слова «London»:

Скомбинировав эту методику с деревом парсинга и информацией об именованных сущностях, мы получаем возможность извлечь из документа огромное количество полезных данных.
Разрешение кореференции – один из самых трудных шагов в нашем пайплайне, он даже сложнее парсинга предложений. В области глубокого обучения уже появились способы его реализации, они достаточно точны, но все еще не совершенны. Если вы хотите узнать больше о том, как это работает, загляните сюда.
А здесь вы найдете чудесную демо-игрушку от Hugging Face.
Пайплайн NLP на Python
Резюмирующая схема нашего конвейере выглядит так:
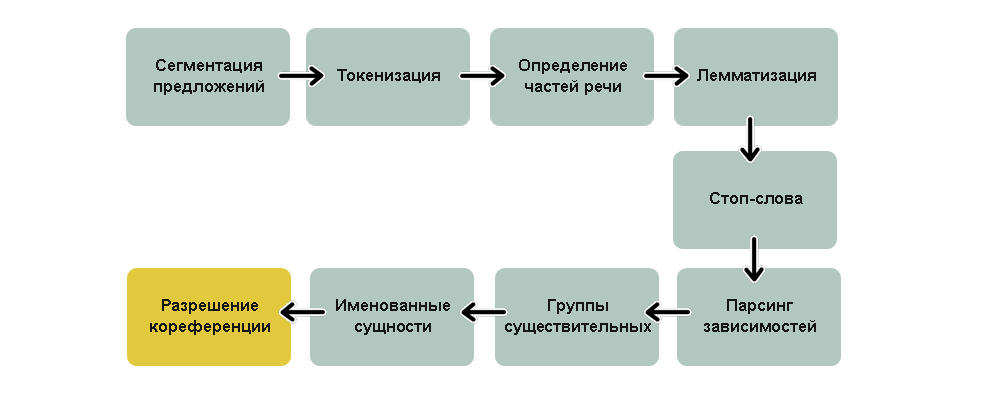
Ух, как много шагов!
Это стандартные этапы обычного NLP-конвейера, но в зависимости от конечной цели проекта и особенностей реализации модели, некоторые из них можно пропускать или менять местами. Например, spaCy производит сегментацию позже, используя для нее результаты парсинга зависимостей.
Итак, как же запрограммировать этот пайплайн? К счастью, это уже сделано за нас в замечательных библиотеках языка Python! Все перечисленные шаги уже написаны и готовы к использованию.
Прежде всего, убедитесь, что у вас установлен Python 3, и подключите spaCy:
# Установка spaCy pip3 install -U spacy # Загрузка модели для анализа английского языка python3 -m spacy download en_core_web_lg # Установка textacy pip3 install -U textacy
А это код для запуска NLP-пайплайна для текстового фрагмента:
import spacy
# Загрузка английской NLP-модели
nlp = spacy.load('en_core_web_lg')
# Текст для анализа
text = """London is the capital and most populous city of England and
the United Kingdom. Standing on the River Thames in the south east
of the island of Great Britain, London has been a major settlement
for two millennia. It was founded by the Romans, who named it Londinium.
"""
# Парсинг текста с помощью spaCy. Эта команда запускает целый конвейер
doc = nlp(text)
# в переменной 'doc' теперь содержится обработанная версия текста
# мы можем делать с ней все что угодно!
# например, распечатать все обнаруженные именованные сущности
for entity in doc.ents:
print(f"{entity.text} ({entity.label_})")
Если вы его запустите, то получите список именованных сущностей с определенными типами:
London (GPE) England (GPE) the United Kingdom (GPE) the River Thames (FAC) Great Britain (GPE) London (GPE) two millennia (DATE) Romans (NORP) Londinium (PERSON)
Вот здесь вы можете узнать, что означают все эти сокращения.
Обратите внимание на ошибку в токене «Londinium». Модель подумала, что это человек, а не географическое место. Видимо, в тренировочных данных, на которых ее обучали, не было ничего похожего, и она просто попыталась угадать. Если вы анализируете текст с необычными или специализированными терминами, следует тонко настроить процесс обнаружения именованных сущностей.
Давайте попробуем создать инструмент для исправления ошибок. Предположим, вы стараетесь соблюдать новые правила конфиденциальности GDPR и обнаружили, что у вас есть множество документов, в которых фигурирует личная информация, например, имена. Вам необходимо все их удалить.
Просмотр тысяч документов и удаление из них всех имен вручную может занять долгие годы. Но с NLP это невероятно просто. Вот примитивный скраббер данных, удаляющий все обнаруженные имена:
import spacy
# Загрузка английской NLP-модели
nlp = spacy.load('en_core_web_lg')
# Если токен является именем, заменяем его словом "REDACTED"
def replace_name_with_placeholder(token):
if token.ent_iob != 0 and token.ent_type_ == "PERSON":
return "[REDACTED] "
else:
return token.string
# Проверка всех сущностей
def scrub(text):
doc = nlp(text)
for ent in doc.ents:
ent.merge()
tokens = map(replace_name_with_placeholder, doc)
return "".join(tokens)
s = """
In 1950, Alan Turing published his famous article "Computing Machinery and Intelligence". In 1957, Noam Chomsky’s
Syntactic Structures revolutionized Linguistics with 'universal grammar', a rule based system of syntactic structures.
"""
print(scrub(s))
Если вы его запустите, то получите ожидаемый результат:
In 1950, [REDACTED] published his famous article "Computing Machinery and Intelligence". In 1957, [REDACTED] Syntactic Structures revolutionized Linguistics with 'universal grammar', a rule based system of syntactic structures.
Извлечение фактов
Базовые возможности spaCy удивительны, но вы также можете использовать ее для подготовки данных, которые затем будут обрабатываться более сложными алгоритмами извлечения. Например, библиотекой textacy, которая отлично работает поверх spaCy.
Проанализировав дерево парсинга с помощью алгоритма извлечения полуструктурированных выражений, мы находим простые сочетания со словом Лондон и различными формами глагола “быть”. Так можно искать факты о Лондоне.
Пример кода:
import spacy
import textacy.extract
# Загрузка английской NLP-модели
nlp = spacy.load('en_core_web_lg')
# Текст для анализа
text = """London is the capital and most populous city of England and the United Kingdom.
Standing on the River Thames in the south east of the island of Great Britain,
London has been a major settlement for two millennia. It was founded by the Romans,
who named it Londinium.
"""
# Анализ
doc = nlp(text)
# Извлечение полуструктурированных выражений со словом London
statements = textacy.extract.semistructured_statements(doc, "London")
# Вывод результатов
print("Here are the things I know about London:")
for statement in statements:
subject, verb, fact = statement
print(f" - {fact}")
И вот что он выводит:
Here are the things I know about London: - the capital and most populous city of England and the United Kingdom. - a major settlement for two millennia.
Может быть, это не очень впечатляюще. Но попробуйте запустить этот код не для трех предложений, а для целой статьи про Лондон. Результаты будут гораздо внушительнее:
Here are the things I know about London: - the capital and most populous city of England and the United Kingdom - a major settlement for two millennia - the world's most populous city from around 1831 to 1925 - beyond all comparison the largest town in England - still very compact - the world's largest city from about 1831 to 1925 - the seat of the Government of the United Kingdom - vulnerable to flooding - "one of the World's Greenest Cities" with more than 40 percent green space or open water - the most populous city and metropolitan area of the European Union and the second most populous in Europe - the 19th largest city and the 18th largest metropolitan region in the world - Christian, and has a large number of churches, particularly in the City of London - also home to sizeable Muslim, Hindu, Sikh, and Jewish communities - also home to 42 Hindu temples - the world's most expensive office market for the last three years according to world property journal (2015) report - one of the pre-eminent financial centres of the world as the most important location for international finance - the world top city destination as ranked by TripAdvisor users - a major international air transport hub with the busiest city airspace in the world - the centre of the National Rail network, with 70 percent of rail journeys starting or ending in London - a major global centre of higher education teaching and research and has the largest concentration of higher education institutes in Europe - home to designers Vivienne Westwood, Galliano, Stella McCartney, Manolo Blahnik, and Jimmy Choo, among others - the setting for many works of literature - a major centre for television production, with studios including BBC Television Centre, The Fountain Studios and The London Studios - also a centre for urban music - the "greenest city" in Europe with 35,000 acres of public parks, woodlands and gardens - not the capital of England, as England does not have its own government
Вот так автоматически мы собрали очень много полезной информации.
Чтобы результат был еще лучше, установите библиотеку neuralcoref и добавьте в пайплайн процесс разрешения кореференции. Вы получите еще больше фактов, так как кроме прямого упоминания «Лондона», модель будет собирать предложения с относящимися к нему местоимениями.
Возможности NLP
Просмотрев документацию spaCy и textacy, вы найдете множество примеров работы с текстом. Все, что мы видели и делали до этого – это лишь крошечная часть всех возможностей.
Представьте, что вы разрабатываете вебсайт, который содержит информацию о каждом городе мира. Данные извлекаются уже рассмотренным нами способом. Если на вашем сайте есть поиск, было бы неплохо добавить в него автодополнение, как делает Google.
Но для этого нужен список возможных продолжений, чтобы предложить его пользователю. NLP поможет быстро их генерировать.
Вот один из способов извлечения часто упоминаемых фрагментов из документа:
import spacy
import textacy.extract
# Загрузка английской NLP-модели
nlp = spacy.load('en_core_web_lg')
# Текст для анализа
text = """London is [.. shortened for space ..]"""
# Анализ
doc = nlp(text)
# Извлечение фрагментов
noun_chunks = textacy.extract.noun_chunks(doc, min_freq=3)
# Перевод в нижний регистр
noun_chunks = map(str, noun_chunks)
noun_chunks = map(str.lower, noun_chunks)
# вывод всех фрагментов, состоящих из 2 слов и более
for noun_chunk in set(noun_chunks):
if len(noun_chunk.split(" ")) > 1:
print(noun_chunk)
Запустите его для статьи из Википедии о Лондоне, и вы увидите следующее:
westminster abbey natural history museum west end east end st paul's cathedral royal albert hall london underground great fire british museum london eye .... etc ....
Вот мы и попробовали на вкус обработку естественного языка. Прежде чем идти дальше и изучать более сложные концепции, установите spaCy или другую NLP библиотеку и немного поиграйте с текстами.
Оригинальная статья: Natural Language Processing is Fun! by Adam Geitgey
Комментарии