

Эта статья познакомит вас со всем необходимым для вхождения в мир генеративных состязательных сетей. Никакого предварительного знакомства с GANами не требуется. Мы предоставим пошаговое руководство по обучению GANов на наборах данных с большими изображениями и по их использованию для генерации новых лиц знаменитостей с помощью Keras.
Генеративная Состязательная Сеть – самая интересная идея в машинном обучении за последние десять лет.
Хотя генеративная состязательная сеть – это старая идея, происходящая из теории игр, они были введены в коммьюнити машинного обучения в 2014-м Йэном Гудфеллоу и соавторами в статье "Генеративные состязательные сети". Как же работают GAN и для чего они хороши?
GANы могут создавать изображения, выглядящие как фотографии человеческих лиц, несмотря на то, что эти лица не принадлежат ни одному реальному человеку.

В прошлой статье мы уже видели, как генерировать фотореалистичные изображения с помощью вариационного автоэнкодера. Наш VAE был обучен на хорошо известном наборе данных лиц знаменитостей.

VAE обычно генерируют размытые и не фотореалистичные изображения. Это и является стимулом к созданию генеративных состязательных сетей (GANов).
В этой статье мы увидим, как GANы предлагают совершенно иной подход к генерации данных, похожих на тренировочные данные.
Игра вероятностей
Генерация новых данных – это игра вероятностей. Когда мы наблюдаем мир вокруг себя и собираем данные, мы производим эксперимент. Простой пример – это фотографирование лиц знаменитостей.
Это можно считать вероятностным экспериментом с неизвестным результатом X, также называемого случайной переменной.
Если эксперимент повторяется несколько раз, мы обычно определяем вероятность того, что случайная переменная X примет значение x, как долю количества раз, в которых произошло x, по отношению к общему количеству экспериментов.
Например, мы можем определить вероятность того, что наше лицо будет лицом Тайриза, знаменитого певца.

Набор всех возможных результатов такого эксперимента образует так называемое пространство выборки, обозначаемое символом "омега" (в нашем случае – все возможные лица знаменитостей).

Таким образом, мы можем считать вероятность функцией, принимающей один из результатов (элемент из пространства выборки – в нашем случае фото знаменитости) и возвращающей неотрицательное действительное число, такое, чтобы сумма этих чисел для всех результатов была равна 1.
Мы также называем это функцией распределения вероятности P(X). Если мы знаем пространство выборки (все возможные лица знаменитостей) и распределение вероятности (вероятность появления каждого лица), у нас есть полное описание эксперимента, и мы можем делать выводы о его результатах.
Вы можете освежить свои знания о вероятностях, прочитав нашу статью.
Распределение вероятностей лиц знаменитостей
Генерацию новых лиц можно определить как задачу генерации случайной переменной. Лицо описывается случайными переменными, при этом значения RGB его пикселей "сплющиваются" в вектор из N чисел.
Наши лица знаменитостей имеют ширину 218 пикселей, высоту 178 пикселей и 3 цветовых канала. Таким образом, каждый вектор будет иметь 116412 измерений.
Если мы построим пространство со 116412 (N) измерениями, каждое лицо будет точкой в этом пространстве. Функция распределения вероятности лиц знаменитостей P(X) поставит каждому лицу в соответствие неотрицательное целое число, чтобы сумма этих чисел была равна 1.
Некоторые точки этого пространства, скорее всего, представляют лица знаменитостей, а многие другие, скорее всего, не представляют.

GAN генерирует новое лицо знаменитости, генерируя новый вектор, следуя распределению вероятности лиц знаменитостей в векторном пространстве размерности N.
Проще говоря, GAN генерирует случайную переменную в соответствии с заданным распределением вероятности.
Как генерировать случайные переменные со сложными распределениями?
Распределение вероятности лиц знаменитостей в N-мерном векторном пространстве очень сложное, и мы не знаем, как напрямую генерировать сложные случайные переменные.
К счастью, мы можем представить нашу сложную случайную переменную в виде функции, примененной к равномерной случайной переменной. В этом заключается идея метода трансформации. Он сначала генерирует N независимых друг от друга равномерных случайных переменных, что просто. Затем она применяет е этой простой случайной переменной очень сложную функцию! Очень сложные функции естественно аппроксимируются нейронной сетью. После обучения нейронная сеть сможет принимать в качестве входа простую N-мерную равномерную случайную переменную и вернет другую N-мерную случайную переменную, имеющую наше распределение вероятности лиц знаменитостей. Это – основная идея, лежащая в основе генеративных состязательных сетей.
Почему "генеративные состязательные сети"?
На каждой итерации обучения нейронной сети трансформации мы могли бы сравнивать выборку лиц из тренировочного набора данных лиц знаменитостей с выборкой сгенерированных лиц.
Теоретически, мы могли бы использовать эти выборки для сравнения истинного распределения со сгенерированным распределением, используя подход максимального среднего расхождения (Maximum Mean Discrepancy, MMD). Он предоставил бы нам ошибку несоответствия распределения, которую можно было бы использовать для обновления весов методом обратного распространения ошибки (backpropagation). На практике этот прямой метод очень трудно реализовать.
Вместо прямого сравнения истинного и сгенерированного распределений, GANы решают не-дискриминационную задачу между истинной и сгенерированной выборками.
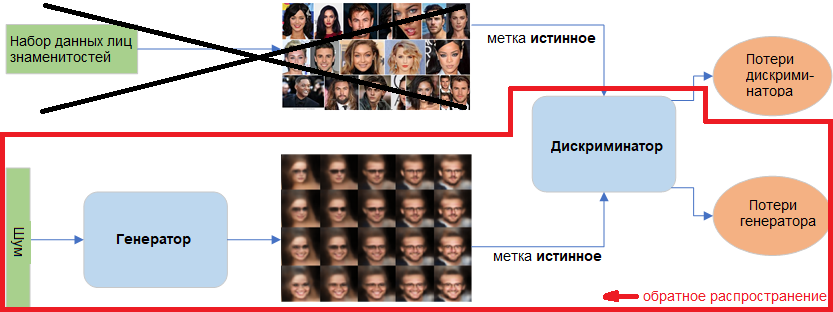
GAN имеет три основных компонента: модель генератора для генерации новых данных, модель дискриминатора для определения, являются ли сгенерированные данные реальными лицами, и состязательная сеть, которая сталкивает их друг против друга.
Генеративная часть отвечает за ввод N-мерных равномерно распределенных случайных чисел (шума) и генерацию ложных лиц. Генератор усваивает вероятность P(X), где X – это входные данные.
Дискриминационная часть – это простой классификатор, оценивающий и отделяющий сгенерированные лица от истинных лиц знаменитостей. Дискриминатор усваивает условную вероятность P(Y | X), где X – это входные данные, а Y – метка.

Обучение генеративных состязательных сетей
Генеративная сеть обучается с целью максимизации итоговой ошибки классификации (между истинными и сгенерированными данными), а дискриминационная сеть обучается с целью минимизации этой ошибки. Вот откуда происходит термин "состязательная сеть".
С точки зрения теории игр, равновесие достигается, когда генератор создает изображения, соответствующие распределению лиц знаменитостей с той же вероятностью, с которой дискриминатор предсказывает, истинное изображение или ложное, как если бы он просто бросал монетку.
Важно, чтобы обе сети в процессе обучения учились с одинаковой скоростью и сходились вместе. Часто происходит, что дискриминационная сеть слишком быстро обучается распознавать фейковые изображения, загоняя генеративную в тупик.
При обучении дискриминатора мы игнорируем потери генератора и используем только функцию потерь дискриминатора, которая штрафует дискриминатор за неверную классификацию сгенерированных лиц как истинных или истинных лиц как фейковых. Веса дискриминатора обновляются методом обратного распространения (backpropagation). Веса генератора не обновляются.
При обучении генератора мы используем функцию потерь генератора, штрафующую генератор за неудачный обман дискриминатора, то есть за генерацию лица, которое дискриминатор признал фейковым. В процессе обучения генератора дискриминатор заморожен, и только веса генератора обновляются методом обратного распространения.
Это и есть магия, синтезирующая лица знаменитостей с помощью GAN. Сходимость часто выглядит мимолетной, а не стабильной. Если вы все сделали правильно, GANы выдают невероятные результаты, как показано ниже.

Построение и обучение модели DCGAN
В этом разделе мы пройдем через все шаги, необходимые для создания, компиляции и обучения модели DCGAN (Deep Convolution GAN, то есть GAN с применением сверточных слоев).
Дискриминатор
Дискриминатором может быть любой классификатор изображений, даже дерево решений. Мы используем вместо него сверточную нейронную сеть с четырьмя блоками слоев. Каждый блок включает сверточный слой, слой нормализации пакета, еще один сверточный слой с шагом, чтобы уменьшить изображение в 2 раза, и еще один слой нормализации пакета. Результат проходит через группировку усреднения (average pooling), за которой следует полносвязный сигмоидный слой, возвращающий единственную выходную вероятность.
from keras.layers import Conv2D, BatchNormalization, Input, GlobalAveragePooling2D, Dense
from keras.models import Model
from keras.layers.advanced_activations import LeakyReLU
# функция для создания слоев дискриминатора
def build_discriminator(start_filters, spatial_dim, filter_size):
# функция создания блока CNN block для уменьшения размера изображения
def add_discriminator_block(x, filters, filter_size):
x = Conv2D(filters, filter_size, padding='same')(x)
x = BatchNormalization()(x)
x = Conv2D(filters, filter_size, padding='same', strides=2)(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.3)(x)
return x
# ввод - это изображение с размерами spatial_dim x spatial_dim и 3 каналами
inp = Input(shape=(spatial_dim, spatial_dim, 3))
# строим дискриминатор для уменьшения изображения в 4 раза
x = add_discriminator_block(inp, start_filters, filter_size)
x = add_discriminator_block(x, start_filters * 2, filter_size)
x = add_discriminator_block(x, start_filters * 4, filter_size)
x = add_discriminator_block(x, start_filters * 8, filter_size)
# усреднение и возврат бинарного вывода
x = GlobalAveragePooling2D()(x)
x = Dense(1, activation='sigmoid')(x)
return Model(inputs=inp, outputs=x)
Генератор
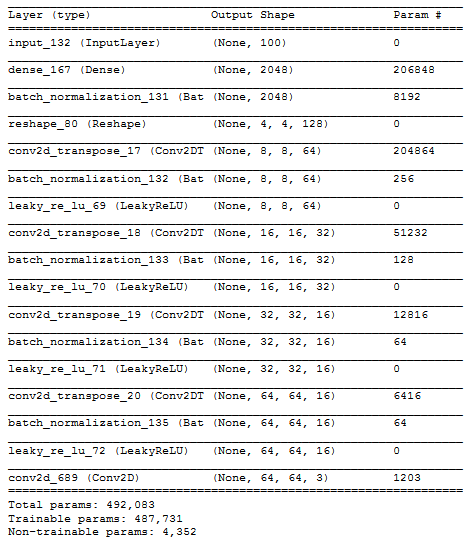
Генератор принимает вектор шума с размерностью скрытого пространства и генерирует изображение. Размеры этого изображения должны совпадать с размерами входа дискриминатора (spatial_dim * spatial_dim).
Сначала генератор размножает вектор шума с помощью полносвязного слоя, чтобы получить достаточно данных для преобразования в форму, необходимую для первого блока генератора. Цель этой проекции – получить такие же размеры, как в последнем блоке архитектуры дискриминатора. Как мы покажем ниже, это эквивалентно форме 4 * 4 * количество фильтров в последнем сверточном слое дискриминатора.
Каждый блок генератора применяет развертку (deconvolution) для увеличения изображения и нормализацию пакета. Мы используем 4 блока декодирования и финальный сверточный слой для получения 3-мерного тензора, представляющего фейковое изображение с 3 каналами.
from keras.layers import Deconvolution2D, Reshape
def build_generator(start_filters, filter_size, latent_dim):
# функция для создания блока CNN, увеличивающего размеры изображения
def add_generator_block(x, filters, filter_size):
x = Deconvolution2D(filters, filter_size, strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.3)(x)
return x
# вход - это вектор шума
inp = Input(shape=(latent_dim,))
# проекция вектора шума в тензор с такой же размерностью,
# как последний сверточный слой дискриминатора
x = Dense(4 * 4 * (start_filters * 8), input_dim=latent_dim)(inp)
x = BatchNormalization()(x)
x = Reshape(target_shape=(4, 4, start_filters * 8))(x)
# строим генератор для увеличения изображения в 4 раза
x = add_generator_block(x, start_filters * 4, filter_size)
x = add_generator_block(x, start_filters * 2, filter_size)
x = add_generator_block(x, start_filters, filter_size)
x = add_generator_block(x, start_filters, filter_size)
# превращаем вывод в трехмерный тензор, изображение с 3 каналами
x = Conv2D(3, kernel_size=5, padding='same', activation='tanh')(x)
return Model(inputs=inp, outputs=x)
Собственно GAN
Объединенная DCGAN создается добавлением дискриминатора над генератором.
Перед компиляцией полной модели мы должны установить, что модель дискриминатора не обучается. Это заморозит ее веса и сообщит, что единственная обучаемая часть общей сети – это генератор.
Хотя мы и компилируем дискриминатор, нам не нужно компилировать модель генератора, поскольку мы не используем генератор сам по себе.
Этот порядок обеспечивает, что дискриминатор будет обновляться в нужное время, а в остальное время будет заморожен. Таким образом, если мы обучаем всю модель, она обновляет только генератор, а когда мы обучаем дискриминатор, обновляется только дискриминатор.
import pandas as pd
import os
from keras.optimizers import Adam
# загружаем атрибуты изображений знаменитостей
df_celeb = pd.read_csv('list_attr_celeba.csv')
TOTAL_SAMPLES = df_celeb.shape[0]
# мы будем уменьшать изображения
SPATIAL_DIM = 64
# размер вектора шума
LATENT_DIM_GAN = 100
# размер фильтра в сверточных слоях
FILTER_SIZE = 5
# количество фильтров в сверточном слое
NET_CAPACITY = 16
# размер пакета
BATCH_SIZE_GAN = 32
# интервал для отображения сгенерированных изображений
PROGRESS_INTERVAL = 80
# директория для хранения сгенерированных изображений
ROOT_DIR = 'visualization'
if not os.path.isdir(ROOT_DIR):
os.mkdir(ROOT_DIR)
def construct_models(verbose=False):
### дискриминатор
discriminator = build_discriminator(NET_CAPACITY, SPATIAL_DIM, FILTER_SIZE)
# компилируем дискриминатор
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002), metrics=['mae'])
### генератор
# не компилируем генератор
generator = build_generator(NET_CAPACITY, FILTER_SIZE, LATENT_DIM_GAN)
### DCGAN
gan = Sequential()
gan.add(generator)
gan.add(discriminator)
discriminator.trainable = False
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002), metrics=['mae'])
if verbose:
generator.summary()
discriminator.summary()
gan.summary()
return generator, discriminator, gan
generator_celeb, discriminator_celeb, gan_celeb = construct_models(verbose=True)

Обучение GAN
Теперь мы приступаем к сложной и длительной части: обучению генеративной состязательной сети. Поскольку GAN состоит из двух раздельно обучаемых сетей, определить сходимость трудно.

Следующие шаги выполняются в прямом и обратном направлении, позволяя GAN справиться с проблемами генерации, которые иначе оказались бы неразрешимыми:
Шаг 1. Выбираем несколько реальных изображений из тренировочного набора
Шаг 2. Генерируем несколько фейковых изображений. Для этого мы создаем несколько случайных векторов шума и создаем из них изображения с помощью генератора.
Шаг 3. Обучаем дискриминатор на протяжении одной или большего количества эпох, используя как реальные, так и фейковые изображения. При этом будут обновляться только веса дискриминатора, поскольку мы пометим все реальные изображения как 1, а фейковые как 0.

Шаг 4. Создаем еще несколько фейковых изображений.
Шаг 5. Обучаем полную модель GAN на протяжении одной или большего количества эпох, используя только фейковые изображения. При этом будут обновляться только веса генератора, а всем фейковым изображениям будет назначена метка 1.
import cv2
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
from IPython.display import clear_output
# количество обновлений дискриминатора на каждую итерацию смены порядка обучения
DISC_UPDATES = 1
# количество обновлений генератора на каждую итерацию смены порядка обучения
GEN_UPDATES = 1
# функция для обучения GAN
def run_training(generator, discriminator, gan, df=df_celeb, start_it=0, num_epochs=1000,
get_real_images=get_real_celebrity):
# вспомогательная функция для выбора 'size' реальных изображений
# и их сжатия до меньшего размера SPATIAL_DIM
def get_real_celebrity(df, size, total):
cur_files = df.sample(frac=1).iloc[0:size]
X = np.empty(shape=(size, SPATIAL_DIM, SPATIAL_DIM, 3))
for i in range(0, size):
file = cur_files.iloc[i]
img_uri = 'img_align_celeba/' + file.image_id
img = cv2.imread(img_uri)
img = cv2.resize(img, (SPATIAL_DIM, SPATIAL_DIM))
img = np.flip(img, axis=2)
img = img.astype(np.float32) / 127.5 - 1.0
X[i] = img
return X
# список для хранения потерь
avg_loss_discriminator = []
avg_loss_generator = []
total_it = start_it
# основной цикл обучения
for epoch in range(num_epochs):
# поочередный цикл обучения
loss_discriminator = []
loss_generator = []
for it in range(200):
#### Цикл обучения дискриминатора ####
for i in range(DISC_UPDATES):
# выбираем случайный набор реальных изображений
imgs_real = get_real_images(df, BATCH_SIZE_GAN, TOTAL_SAMPLES)
# генерируем набор случайных векторов шума
noise = np.random.randn(BATCH_SIZE_GAN, LATENT_DIM_GAN)
# генерируем набор фейковых изображений с помощью нашего генератора
imgs_fake = generator.predict(noise)
# обучаем дискриминатор на реальных изображениях с меткой 1
d_loss_real = discriminator.train_on_batch(imgs_real, np.ones([BATCH_SIZE_GAN]))[1]
# обучаем дискриминатор на фейковых изображениях с меткой 0
d_loss_fake = discriminator.train_on_batch(imgs_fake, np.zeros([BATCH_SIZE_GAN]))[1]
# выводим несколько фейковых изображений для визуального контроля сходимости
if total_it % PROGRESS_INTERVAL == 0:
plt.figure(figsize=(5,2))
num_vis = min(BATCH_SIZE_GAN, 5)
imgs_real = get_real_images(df, num_vis, TOTAL_SAMPLES)
noise = np.random.randn(num_vis, LATENT_DIM_GAN)
imgs_fake = generator.predict(noise)
for obj_plot in [imgs_fake, imgs_real]:
plt.figure(figsize=(num_vis * 3, 3))
for b in range(num_vis):
disc_score = float(discriminator.predict(np.expand_dims(obj_plot[b], axis=0))[0])
plt.subplot(1, num_vis, b + 1)
plt.title(str(round(disc_score, 3)))
plt.imshow(obj_plot[b] * 0.5 + 0.5)
if obj_plot is imgs_fake:
plt.savefig(os.path.join(ROOT_DIR, str(total_it).zfill(10) + '.jpg'), format='jpg', bbox_inches='tight')
plt.show()
#### Цикл обучения генератора ####
loss = 0
y = np.ones([BATCH_SIZE_GAN, 1])
for j in range(GEN_UPDATES):
# создаем набор случайных векторов шума
noise = np.random.randn(BATCH_SIZE_GAN, LATENT_DIM_GAN)
# обучаем генератор на фейковых изображениях с меткой 1
loss += gan.train_on_batch(noise, y)[1]
# сохраняем потери
loss_discriminator.append((d_loss_real + d_loss_fake) / 2.)
loss_generator.append(loss / GEN_UPDATES)
total_it += 1
# визуализируем потери
clear_output(True)
print('Epoch', epoch)
avg_loss_discriminator.append(np.mean(loss_discriminator))
avg_loss_generator.append(np.mean(loss_generator))
plt.plot(range(len(avg_loss_discriminator)), avg_loss_discriminator)
plt.plot(range(len(avg_loss_generator)), avg_loss_generator)
plt.legend(['discriminator loss', 'generator loss'])
plt.show()
return generator, discriminator, gan
generator_celeb, discriminator_celeb, gan_celeb = run_training(generator_celeb,
discriminator_celeb,
gan_celeb,
num_epochs=500,
df=df_celeb)

Как мы видим, наш генератор работает неплохо. Сгенерированные лица выглядят неплохо, хотя качество фото не такое хорошее, как в наборе данных CelebA. Это произошло потому, что мы обучили наш GAN на уменьшенных изображениях 64 * 64, которые гораздо более размыты, чем исходные изображения 218 * 178.
Разница между VAE и GAN
По сравнению с лицами, сгенерированными Вариационным АвтоЭнкодером из нашей прошлой статьи, лица, сгенерированные DCGAN, выглядят достаточно яркими, чтобы представлять лица, близкие к реальности.

GAN'ы, как правило, намного лучшие глубокие генеративные модели, чем VAE. Хотя VAE работают только в скрытом пространстве, их легче создавать и проще обучать. Можно считать, что VAE обучаются с частичным привлечением учителя (semi-supervised learning), поскольку они обучаются минимизировать потери при воспроизведении конкретных изображений. С другой стороны, GAN'ы – это уже задача обучения без учителя.
Заключение
В этой статье я рассказал, как генеративные состязательные сети могут аппроксимировать распределение вероятности большого набора изображений, и использовать эту аппроксимацию для генерации фотореалистичных изображений.
Я предоставил работающий код на Python, который позволит вам строить и обучать собственные GANы для решения ваших задач.
Вы можете больше узнать о GANах на Google Developers или из статьи Джозефа Рокка. Вариационные автоэнкодеры были рассмотрены в моей прошлой статье.
Хочу освоить алгоритмы и структуры данных, но сложно разобраться самостоятельно. Что делать?
Алгоритмы и структуры данных действительно непростая тема для самостоятельного изучения: не у кого спросить и что-то уточнить. Поэтому мы запустили курс «Алгоритмы и структуры данных», на котором в формате еженедельных вебинаров вы:
- изучите сленг, на котором говорят все разработчики независимо от языка программирования: язык алгоритмов и структур данных;
- научитесь применять алгоритмы и структуры данных при разработке программ;
- подготовитесь к техническому собеседованию и продвинутой разработке.
Курс подходит как junior, так и middle-разработчикам.
Комментарии