
Эта статья познакомит вас со всем необходимым для начала работы с генеративными моделями. Мы предоставим пошаговое руководство по обучению условных VAE на наборах данных с большими изображениями и их применению для генерации новых размеченных изображений.
Мотивация
Зачем нужно генерировать новые данные, если в мире и так огромное количество данных? Согласно IDC, в мире более 18 зеттабайтов данных.
Как сгенерировать изображения, которых никто не видел?
Прочитав эту статью, вы узнаете, что такое Вариационный Автоэнкодер, и как создать ваш собственный для генерации новых изображений, которые никто никогда не видел. Мы объясним идеи и концепции, лежащие в его основе, без какой-либо математики.

Данные
Мы используем подмножество широко известного набора данных Знаменитостей, который поможет нам создать модель генерации лиц. Этот набор можно скачать с сайта CelebFacesA. Он предоставляет большой набор атрибутов лиц, содержащий более 200 тысяч изображений знаменитостей, для каждого из которых указано значение 40 атрибутов.
- 10.177 личностей;
- 202.599 изображений;
- 5 важнейших локаций;
- 40 бинарных атрибутов для каждого изображения.
import pandas as pd
df_celeb = pd.read_csv('list_attr_celeba.csv')
df_celeb.head()
Ниже мы выбираем случайные лица и выводим их метаданные (атрибуты). Изображения имеют высоту 218 пикселей, ширину 178 пикселей и 3 цветовых канала.
import matplotlib.pyplot as plt
import random
from skimage.io import imread
def show_sample_image(nb=3, df=df_celeb, verbose=True):
f, ax = plt.subplots(1, nb, figsize=(10,5))
for i in range(nb):
idx = random.randint(0, df.shape[0]-1)
img_id = df.loc[idx].image_id
img_uri = 'img_align_celeba/' + img_id
img = skimage.io.imread(img_uri)
if verbose:
label = img_id
for col in df.columns:
if df.loc[idx][col]==1:
label = label + '\n' + col
if nb > 1:
ax[i].imshow(img)
ax[i].set_title(label)
else:
ax.imshow(img)
ax.set_title(label)
return img, list(df.loc[idx][1:df.shape[1]])
sample_img, sample_img_meta = show_sample_image()

Что такое автоэнкодер (AE)?
Просмотрев лица тысяч знаменитостей, нейронная сеть может научиться генерировать лица людей, которых не существует.
Иногда этих меток у нас нет. Тем не менее, мы можем обучить две нейронные сети – одна будет усваивать представление, а вторая – восстанавливать исходное изображение из этого представления, минимизируя функцию потерь реконструкции. Это автоэнкодер (автокодировщик). Он так называется потому, что автоматически находит лучший способ закодировать данные так, чтобы декодированная версия была как можно ближе к исходной.
Автоэнкодер состоит из двух соединенных нейронных сетей: модели энкодера (кодировщика) и модели декодера (декодировщика). Его цель – нахождение метода кодирования лиц знаменитостей в сжатую форму (скрытое пространство) таким образом, чтобы восстановленная версия была как можно ближе к входной.
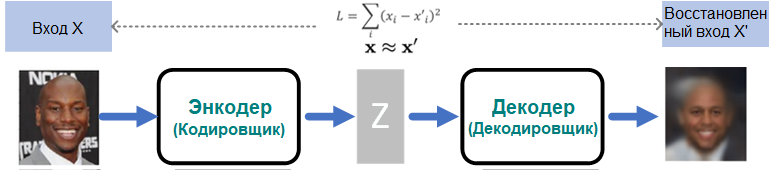
- Модель энкодера переводит входное значение X в маленькое плотное представление Z, примерно так же, как работает сверточная нейронная сеть, используя фильтры для усвоения представлений.
- Модель декодера можно считать генеративной моделью, способной генерировать специфические признаки X'.
- Энкодер и декодер обычно обучаются вместе. Функция потерь штрафует объединенную сеть за создание выходных лиц, отличающихся от входных лиц.
Таким образом, энкодер обучается сохранять как можно больше полезной информации в скрытом пространстве и разумно отбрасывать неважную информацию – например, шум. Декодер обучается превращать сжатую информацию в скрытом пространстве в целое лицо знаменитости.
Автоэнкодеры также могут быть полезными для сокращения размерности и удаления шумов, и могут очень успешно проводить машинный перевод без учителя.
Что такое вариационный автоэнкодер (VAE)?
Как правило, скрытое пространство Z, создаваемое энкодером, редко заселено, то есть трудно предсказать, распределение значений в этом пространстве. Значения разбросаны, и пространство обычно хорошо визуализируется в двухмерном представлении.
Это очень полезная особенность для систем сжатия (компрессии). Однако для генерации новых изображений знаменитостей эта разреженность – проблема, поскольку найти скрытое значение, для которого декодер будет знать, как произвести нормальное изображение, почти невозможно.
Более того, если в пространстве есть промежутки между кластерами, и декодер получит вариацию из такого промежутка, ему не хватит знаний, чтобы сгенерировать что-нибудь полезное.
Вариационный автоэнкодер делает внутреннее пространство более предсказуемым, более непрерывным и менее разреженным. Заставляя скрытые переменные соответствовать нормальному распределению, VAE получают контроль над скрытым пространством.
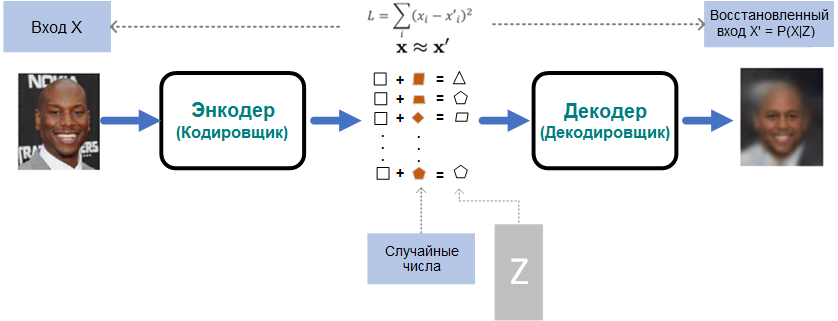
Вместо прямой передачи скрытых значений декодеру, VAE используют их для расчета средних значений и стандартных отклонений. Затем вход декодера собирается из соответствующего нормального распределения.
В процессе обучения VAE заставляет это нормальное распределение быть как можно более близким к стандартному нормальному распределению, включая в функцию потерь расстояние Кульбака-Лейблера. VAE будет изменять, или исследовать вариации на гранях, и не случайным образом, а в определенном, желаемом направлении.
Условные вариационные автоэнкодеры позволяют моделировать вход на основе не только скрытой переменной z, но и дополнительной информации вроде метаданных изображения (улыбка, очки, цвет кожи и т.п.)
Генератор данных изображений
Давайте создадим (условный) VAE, который сможет обучаться на лицах знаменитостей. Мы используем пользовательский эффективный по памяти генератор Keras, чтобы справиться с нашим большим набором данных (202599 изображений, примерно по 10Кб каждое). Его цель – получать пакеты изображений на лету в процессе обучения.
import numpy as np
class CustomCelebrityFaceGenerator(Sequence):
# инициализируем пользовательский генератор
def __init__(self, df, batch_size, target_height, target_width, conditioning_dim=0):
self.df = df
self.batch_size = batch_size
self.target_height = target_height
self.target_width = target_width
self.conditioning_dim = conditioning_dim
# перетасуем данные после каждой эпохи
def on_epoch_end(self):
self.df = self.df.sample(frac=1)
# выберем пакет в виде тензора
def __getitem__(self, index):
cur_files = self.df.iloc[index*self.batch_size:(index+1)*self.batch_size]
X, y = self.__data_generation(cur_files)
return X, y
#
def __data_generation(self, cur_files):
# инициализируем пустые тензоры для хранения изображений
X = np.empty(shape=(self.batch_size, self.target_height, self.target_width, 3))
Y = np.empty(shape=(self.batch_size, self.target_height, self.target_width, 3))
# инициализируем пустой тензор для хранения условных переменных
if self.conditioning_dim > 0:
C = np.empty(shape=(self.batch_size, self.conditioning_dim))
# проходим циклом по текущему пакету и создаем тензоры
for i in range(0, self.batch_size):
# читаем изображение
file = cur_files.iloc[i]
img_uri = 'img_align_celeba/' + file.image_id
img = skimage.io.imread(img_uri)
# изменяем размеры изображения
if img.shape[0] != self.target_height or img.shape[1] != self.target_width:
img = skimage.transform.resize(img, (self.target_height, self.target_width))
# сохраняем изображение в тензорах
img = img.astype(np.float32) / 255.
X[i] = img
Y[i] = img
# сохраняем условные параметры в тензорах
if self.conditioning_dim > 0:
C[i] = list(file[1:file.shape[0]])
if self.conditioning_dim > 0:
return [X, C], Y
else:
return X, Y
# получить количество пакетов
def __len__(self):
return int(np.floor(self.df.shape[0] / self.batch_size))
Нейронная сеть VAE
Мы хотим, чтобы наш энкодер был сверточной нейронной сетью, принимающей изображение и выдающей параметры распределения Q(z | [x,c]), где x – входное изображение лица, c – условная переменная (атрибуты лица), а z – скрытая переменная. В этой статье мы используем простую архитектуру, состоящую из двух сверточных слоев и слоя группировки (pooling).
Декодер – это сверточная нейронная сеть, построенная по-другому. Это генеративная нейронная сеть, выдающая параметры распределения похожести P([x,z] | c).
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
def get_encoder_network(x, num_filters):
x = Conv2D(num_filters, 3, activation='relu', padding='same', kernel_initializer='he_normal')(x)
x = Conv2D(num_filters, 3, activation='relu', padding='same', kernel_initializer='he_normal')(x)
x = MaxPooling2D()(x)
return x
def get_decoder_network(x, num_filters):
x = UpSampling2D()(x)
x = Conv2D(num_filters, 3, activation='relu', padding = 'same', kernel_initializer = 'he_normal')(x)
x = Conv2D(num_filters, 3, activation='relu', padding = 'same', kernel_initializer = 'he_normal')(x)
return x
Вот так выглядит архитектура всей сети VAE:
from keras.layers import Input, Dense, Reshape, Concatenate, Flatten, Lambda, Reshape
from keras.models import Model
from keras import backend as K
from keras.optimizers import Adam
# функция для создания нейронной сети автоэнкодера
def get_vae(height, width, batch_size, latent_dim,
is_variational=True, conditioning_dim=0,
start_filters=8, nb_capacity=3,
optimizer=Adam(lr=0.001)):
# ВХОД ##
# создаем слой для входного изображения
# объединяем метаданные изображений
inputs = Input((height, width, 3))
if conditioning_dim > 0:
condition = Input([conditioning_dim])
condition_up = Dense(height * width)(condition)
condition_up = Reshape([height, width, 1])(condition_up)
inputs_new = Concatenate(axis=3)([inputs, condition_up])
else:
inputs_new = inputs
# ЭНКОДЕР ##
# создаем кодирующие слои
# дублируем кодирующие слои, увеличивая фильтры
eblock = get_encoder_network(inputs_new, start_filters)
for i in range(1, nb_capacity+1):
eblock = get_encoder_network(eblock, start_filters*(2**i))
# создаем слой скрытого пространства
_, *shape_spatial = eblock.get_shape().as_list()
eblock_flat = Flatten()(eblock)
if not is_variational:
z = Dense(latent_dim)(eblock_flat)
else:
# выборка скрытых значений из нормального распределения
def sampling(args):
z_mean, z_log_sigma = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.)
return z_mean + K.exp(z_log_sigma) * epsilon
z_mean = Dense(latent_dim)(eblock_flat)
z_log_sigma = Dense(latent_dim)(eblock_flat)
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_sigma])
if conditioning_dim > 0:
z_ext = Concatenate()([z, condition])
## ДЕКОДЕР ##
# создаем декодирующие статьи
inputs_embedding = Input([latent_dim + conditioning_dim])
embedding = Dense(np.prod(shape_spatial), activation='relu')(inputs_embedding)
embedding = Reshape(eblock.shape.as_list()[1:])(embedding)
# дублируем кодирующие слои, увеличивая фильтры
dblock = get_decoder_network(embedding, start_filters*(2**nb_capacity))
for i in range(nb_capacity-1, -1, -1):
dblock = get_decoder_network(dblock, start_filters*(2**i))
output = Conv2D(3, 1, activation = 'tanh')(dblock)
## VAE ##
# объединяем энкодер с декодером
decoder = Model(input = inputs_embedding, output = output)
if conditioning_dim > 0:
encoder_with_sampling = Model(input = [inputs, condition], output = z)
encoder_with_sampling_ext = Model(input = [inputs, condition], output = z_ext)
vae_out = decoder(encoder_with_sampling_ext([inputs, condition]))
vae = Model(input = [inputs, condition], output = vae_out)
else:
encoder_with_sampling = Model(input = inputs, output = z)
vae_out = decoder(encoder_with_sampling(inputs))
vae = Model(input = inputs, output = vae_out)
# определяем потери VAE как сумму MSE and потерь расстояния Кульбака-Лейблера
def vae_loss(x, x_decoded_mean):
mse_loss = K.mean(mse(x, x_decoded_mean), axis=(1,2)) * height * width
kl_loss = - 0.5 * K.mean(1 + z_log_sigma - K.square(z_mean) - K.exp(z_log_sigma), axis=-1)
return mse_loss + kl_loss
if is_variational:
vae.compile(loss=vae_loss, optimizer=optimizer)
else:
vae.compile(loss='mse', optimizer=optimizer)
return vae, encoder_with_sampling, decoder
# гиперпараметры
VARIATIONAL = True
HEIGHT = 128
WIDTH = 128
BATCH_SIZE = 16
LATENT_DIM = 16
START_FILTERS = 32
CAPACITY = 3
CONDITIONING = True
OPTIMIZER = Adam(lr=0.01)
vae, encoder, decoder = get_vae(is_variational=VARIATIONAL,
height=HEIGHT,
width=WIDTH,
batch_size=BATCH_SIZE,
latent_dim=LATENT_DIM,
conditioning_dim=df_celeb.shape[1]-1,
start_filters=START_FILTERS,
nb_capacity=CAPACITY,
optimizer=OPTIMIZER)
Обучение
Ниже представлен процесс обучения моделей VAE на наборе данных celebA. Этот код выполнялся около 8 часов на инстансе AWS с использованием 1 GPU.
# делим изображения на тренировочный набор и набор валидации
msk = np.random.rand(len(df_celeb)) < 0.5
df_celeb_train = df_celeb[msk]
df_celeb_val = df_celeb[~msk]
# создаем генераторы изображений для обучения
gen = CustomCelebrityFaceGenerator(df_celeb_train,
batch_size=BATCH_SIZE,
target_height=HEIGHT,
target_width=WIDTH,
conditioning_dim=df_celeb.shape[1]-1)
# создаем генераторы изображений для валидации
gen_val = CustomCelebrityFaceGenerator(df_celeb_val,
batch_size=BATCH_SIZE,
target_height=HEIGHT,
target_width=WIDTH,
conditioning_dim=df_celeb.shape[1]-1)
# обучаем вариационный автоэнкодер
vae.fit_generator(gen, verbose=1, epochs=20, validation_data=gen_val)

Визуализируем скрытые представления
После обучения мы можем выбрать случайное изображение из нашего набора данных и использовать обученный энкодер для создания скрытого представления изображения.
# выбираем случайное изображение
sample_img, sample_img_meta = show_sample_image(nb=1)
# функция для кодирования одного изображения, возвращающая его скрытое представление
def encode_image(img, conditioning, encoder, height, width, batch_size):
# изменяем размеры изображения
if img.shape[0] != height or img.shape[1] != width:
img = skimage.transform.resize(img, (height, width))
# заполняем изображение, чтобы оно соответствовало размеру пакета
img_single = np.expand_dims(img, axis=0)
img_single = img_single.astype(np.float32)
img_single = np.repeat(img_single, batch_size, axis=0)
# используем энкодер для вычисления представления в скрытом пространстве
if conditioning is None:
z = encoder.predict(img_single)
else:
z = encoder.predict([img_single, np.repeat(np.expand_dims(conditioning, axis=0), batch_size, axis=0)])
return z
# выводим представление в скрытом пространстве, созданное энкодером
z = encode_image(sample_img.astype(np.float32) / 255.,
np.array(sample_img_meta),
encoder, HEIGHT, WIDTH, BATCH_SIZE)
print('latent sample:\n', z[0])


Используя это скрытое представление, вектор из 16 действительных чисел, мы можем визуализировать, как декодер восстановил исходное изображение.
def decode_embedding(z, conditioning, decoder):
if z.ndim < 2:
z = np.expand_dims(z, axis=0)
if conditioning is not None:
z = np.concatenate((z, np.repeat(np.expand_dims(conditioning, axis=0), z.shape[0], axis=0)), axis=1)
return decoder.predict(z)
# восстановим исходное изображение, используя представление скрытого пространства
ret = decode_embedding(z, sample_img_meta, decoder)
plt.imshow(ret[0])
plt.show()
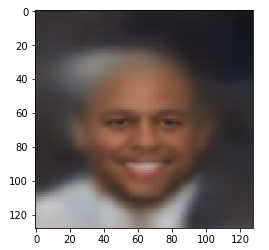
Хотя реконструированное изображение и размыто, мы можем заметить, что оно очень похоже на исходное изображение: пол, цвет одежды, волосы, улыбка, цвет кожи.
Генерируем новые лица
Условные VAE могут изменять скрытое пространство, чтобы генерировать новые данные. А это значит, что мы можем сгенерировать случайное количество новых изображений с помощью декодера, определяя разные значения заданных атрибутов.
def generate_new_images_vae(nb=16, smiling=None, male=None, no_beard=None, attractive=None,
bald=None, chubby=None, eyeglasses=None, young = None):
sample_training_img, sample_training_img_meta = show_sample_image(nb=1, verbose=False)
plt.clf();
f, ax = plt.subplots(2, nb//2, figsize=(20,7));
for i in range(nb):
meta=2*np.random.rand(meta_cols.shape[0])-1
meta[2] = attractive if attractive else meta[2]
meta[4] = bald if bald else meta[4]
meta[13] = chubby if chubby else meta[13]
meta[15] = eyeglasses if eyeglasses else meta[15]
meta[20] = male if male else meta[20]
meta[24] = no_beard if no_beard else meta[24]
meta[31] = smiling if smiling else meta[31]
meta[39] = young if young else meta[39]
z1 = np.random.rand(LATENT_DIM, LATENT_DIM)
ret = decode_embedding(z1, meta, decoder)
ax[i%2][i//2].imshow(ret[0])
ax[i%2][i//2].set_title('generated img {}'.format(i))
ax[0][0].imshow(sample_training_img)
ax[0][0].set_title('training img')
generate_new_images_vae()

Хотя наш вариационный автоэнкодер выдает размытые изображения, не похожие на реалистичные фотографии, мы можем распознать на этих изображениях пол, цвет кожи, улыбку, очки и цвет волос людей, которые никогда не существовали.
От улыбки станет мир светлей
Условные VAE могут проводить интерполяцию между атрибутами, то есть они способны заставить лицо улыбаться или добавить очки, если их не было прежде. Сейчас мы выберем лицо случайной знаменитости из нашего набора данных и воспользуемся преимуществом изменений скрытого представления, чтобы превратить женское лицо в мужское. Мы также изменим лица, добавив на них улыбку, которой прежде там не было.
# интерполяция скрытого пространства, чтобы изменить исходное изображение
def display_manifold(decoder, height, width, base_vec,
bound_x=15, bound_y=15,
axis_x=0, axis_y=1, n=15,
desc_x = 'x', desc_y = 'y',
file_out=None):
figure = np.zeros((height * (n if bound_y > 0 else 1), width * (n if bound_x > 0 else 1), 3))
grid_x = np.linspace(-bound_x, bound_x, n) if bound_x > 0 else [0]
grid_y = np.linspace(-bound_y, bound_y, n) if bound_y > 0 else [0]
individual_outputs = []
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = base_vec.copy()
z_sample[axis_x] = xi
z_sample[axis_y] = yi
x_decoded = decoder.predict(np.expand_dims(z_sample, axis=0))
sample = np.clip(x_decoded[0], 0, 1)
figure[i * height: (i + 1) * height, j * width: (j + 1) * width] = sample
individual_outputs.append(sample)
plt.figure(figsize=(10, 10))
plt.imshow(figure)
plt.xlabel(desc_x)
plt.ylabel(desc_y)
if file_out is not None:
plt.savefig(file_out, dpi=200, bbox_inches='tight')
return figure, individual_outputs
# доступные атрибуты
meta_cols = df_celeb.columns[1:].values
# изменяемые атрибуты
dim1 = 'Male'
dim2 = 'Smiling'
# используемое скрытое пространство
base_vec = np.array(list(z[0]) + sample_img_meta)
# создаем изменения
rendering, _ = display_manifold(
decoder,
HEIGHT,
WIDTH,
base_vec,
bound_x=15,
bound_y=15,
axis_x=LATENT_DIM + np.where(meta_cols==dim1)[0][0],
axis_y=LATENT_DIM + np.where(meta_cols==dim2)[0][0],
n=10,
desc_x = dim1,
desc_y = dim2,
file_out = 'rendering_celeba_' + dim1.lower() + '_' + dim2.lower() + '.png'
)
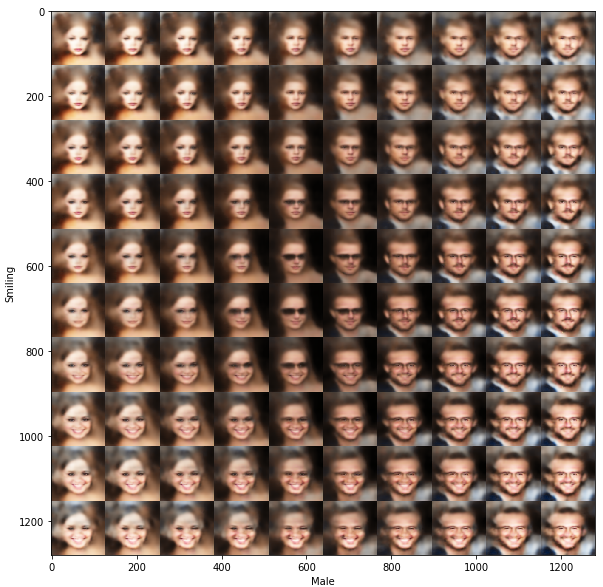
Заключение
В этой статье мы представили условные вариационные автоэнкодеры и продемонстрировали, как их можно обучить генерации новых размеченных данных. Мы предоставили код на Python для обучения VAE на больших наборах данных изображений знаменитостей. Этот подход и код можно использовать и для многих других задач.
Генеративные состязательные сети (GAN), как правило, выдают изображения, которые выглядят еще лучше, поскольку они обучаются распознавать, что люди считают фотореалистичным, а что нет.
Этический аспект использования технологий VAE/GAN для создания фейковых изображений, видео и новостей следует рассматривать серьезно, и они должны применяться ответственно.
Огромное спасибо Винсенту Кассеру (Vincent Casser) за его замечательный код, содержащий более продвинутый подход к реализации сверточных автоэнкодеров для обработки изображений, приведенный в его блоге. Винсент разрешил мне адаптировать его код VAE для этой статьи. Создание работающего VAE с нуля довольно сложно, так что за код следует благодарить Винсента.
Хочу освоить алгоритмы и структуры данных, но сложно разобраться самостоятельно. Что делать?
Алгоритмы и структуры данных действительно непростая тема для самостоятельного изучения: не у кого спросить и что-то уточнить. Поэтому мы запустили курс «Алгоритмы и структуры данных», на котором в формате еженедельных вебинаров вы:
- изучите сленг, на котором говорят все разработчики независимо от языка программирования: язык алгоритмов и структур данных;
- научитесь применять алгоритмы и структуры данных при разработке программ;
- подготовитесь к техническому собеседованию и продвинутой разработке.
Курс подходит как junior, так и middle-разработчикам.
Комментарии